
阅读量:2
作者:来自 Elastic Aurélien Foucret

从 Elasticsearch 8.13 开始,我们提供了原生集成到 Elasticsearch 中的学习排名 (learning to rank - LTR) 实现。LTR 使用经过训练的机器学习 (ML) 模型为你的搜索引擎构建排名功能。通常,该模型用作第二阶段重新排名器,以提高由更简单的第一阶段检索算法返回的搜索结果的相关性。
这篇博文将解释此新功能如何帮助提高文本搜索中的文档排名以及如何在 Elasticsearch 中实现它。
无论你是尝试优化电子商务搜索、为检索增强生成 (RAG) 应用程序构建最佳上下文,还是基于数百万篇学术论文制作基于问答的搜索,你可能已经意识到准确优化搜索引擎中的文档排名是多么困难。这就是学习排名的作用所在。
了解相关性特征以及如何构建评分函数
相关性特征是确定文档与用户查询或兴趣的匹配程度的信号,所有这些都会影响搜索相关性。这些特征可能会因上下文而异,但它们通常分为几类。让我们来看看不同领域中使用的一些常见相关性特征:
- 文本相关性分数(例如 BM25、TF-IDF):从文本匹配算法得出的分数,用于衡量文档内容与搜索查询的相似性。这些分数可以从 Elasticsearch 中获得。
- 文档属性(例如产品价格、发布日期):可以直接从存储的文档中提取的特征。
- 流行度指标(例如点击率、浏览量):文档的流行度或访问频率的指标。流行度指标可以通过搜索分析工具获得,Elasticsearch 提供了开箱即用的搜索分析工具。
评分函数结合了这些特征,为每个文档生成最终的相关性分数。得分较高的文档在搜索结果中的排名较高。
使用 Elasticsearch Query DSL 时,你会隐式编写一个评分函数,该函数对相关性特征进行加权,并最终定义你的搜索相关性。
Elasticsearch 查询 DSL 中的评分
考虑以下示例查询:
{ "query": { "function_score": { "query": { "multi_match": { "query": "the quick brown fox", "fields": ["title^10", "content"] } }, "field_value_factor": { "field": "monthly_views", "modifier": "log1p" } } } } 该查询转换为以下评分函数:
score = 10 x title_bm25_score + content_bm25_score + log(1+ monthly_views)虽然这种方法效果很好,但它有一些局限性:
- 权重是估算的:分配给每个特征的权重通常基于启发式或直觉。这些猜测可能无法准确反映每个特征在确定相关性方面的真正重要性。
- 文档之间的统一权重:手动分配的权重统一应用于所有文档,忽略特征之间的潜在相互作用以及它们的重要性在不同查询或文档类型之间的变化。例如,新近度的相关性对于新闻文章可能更重要,但对于学术论文则不那么重要。
随着特征和文档数量的增加,这些限制变得更加明显,使得确定准确的权重变得越来越具有挑战性。最终,所选权重成为一种折衷方案,可能导致许多情况下排名不理想。
一个引人注目的替代方案是用基于 ML 的模型替换使用手动权重的评分函数,该模型使用相关性特征计算分数。
你好,学习排名 (LTR)!
LambdaMART 是一种流行且有效的 LTR 技术,它使用梯度提升决策树 (GBDT) 从判断列表中学习最佳评分函数。
判断列表是一个数据集,其中包含查询和文档对以及它们相应的相关性标签或等级。相关性标签通常是二进制的(例如相关/不相关)或分级的(例如,0 表示完全不相关,4 表示高度相关)。判断列表可以由人工手动创建,也可以从用户参与度数据(例如点击次数或转化次数)生成。
下面的示例使用分级相关性判断。
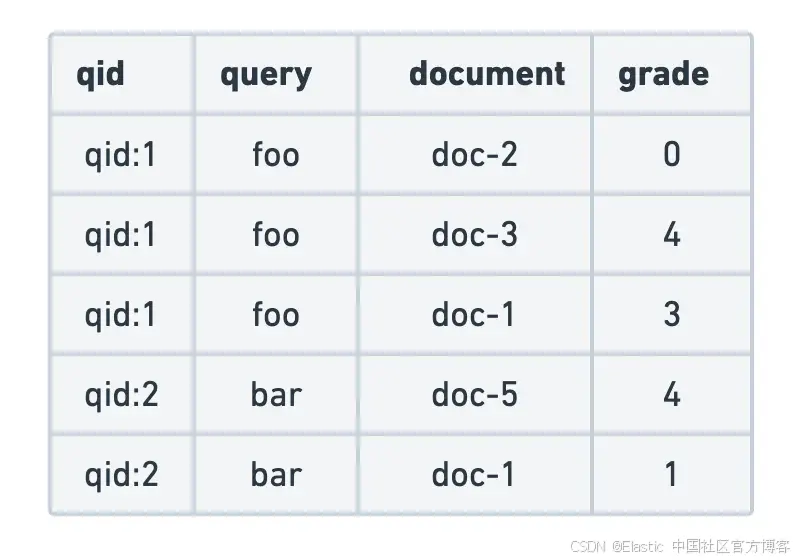
LambdaMART 使用决策树将排名问题视为回归任务,其中树的内部节点是相关性特征的条件,而叶子是预测分数。
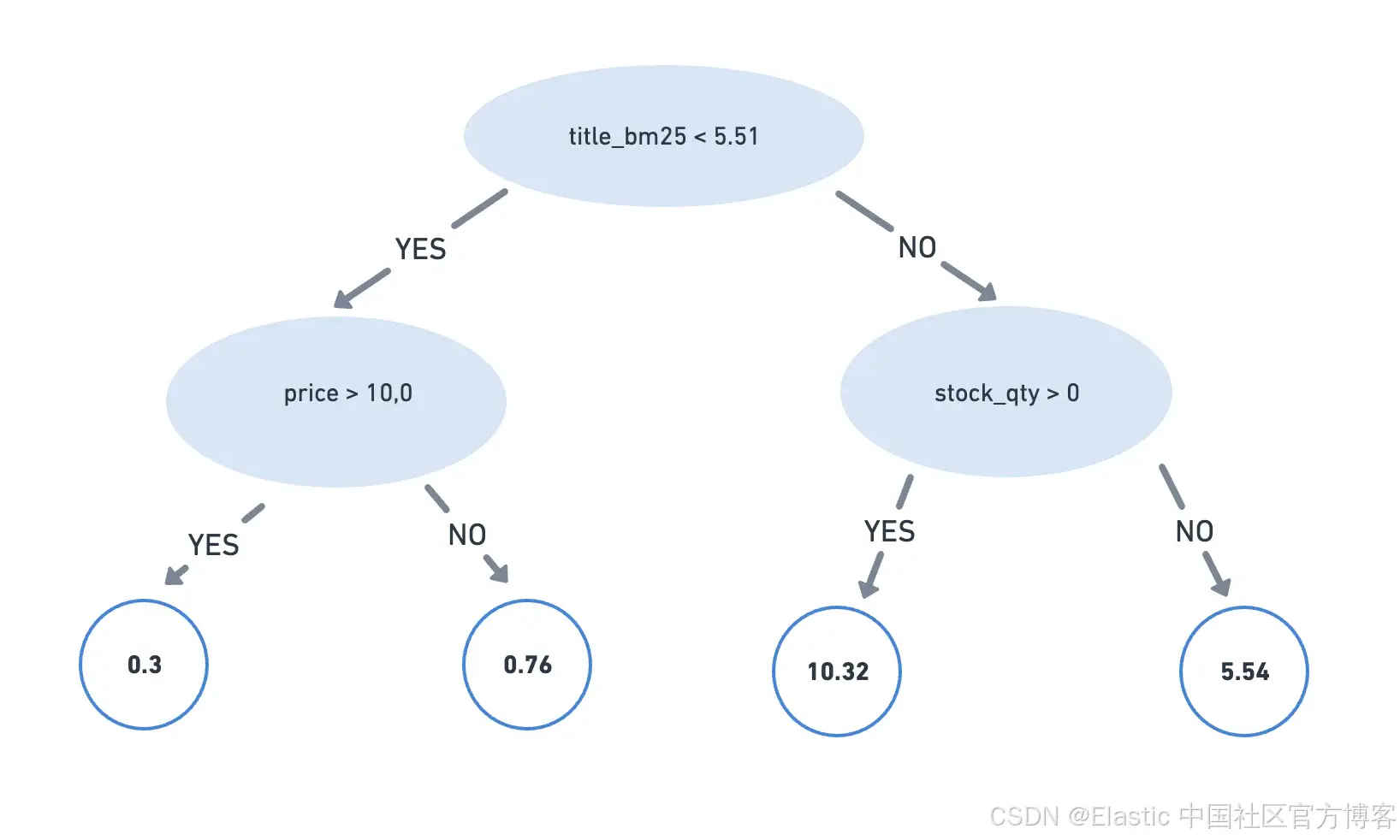
LambdaMART 使用梯度提升树方法,在训练过程中,它会构建多个决策树,其中每棵树都会纠正其前辈的错误。此过程旨在根据判断列表中的示例优化 NDCG 等排名指标。最终模型是各个树的加权和。
XGBoost 是一个著名的库,它提供了 LambdaMART 的实现,使其成为基于梯度提升决策树实现排名的热门选择。
在 Elasticsearch 中开始使用 LTR
从 8.13 版开始,Learning To Rank 直接集成到 Elasticsearch 和相关工具中,作为技术预览功能。
训练并将 LTR 模型部署到 Elasticsearch
Eland 是我们用于 Elasticsearch 中的 DataFrames 和机器学习的 Python 客户端和工具包。Eland 与大多数标准 Python 数据科学工具兼容,例如 Pandas、scikit-learn 和 XGBoost。
我们强烈建议使用它来训练和部署你的 LTR XGBoost 模型,因为它提供了简化此过程的功能:
1)训练过程的第一步是定义 LTR 模型的相关特征。使用下面的 Python 代码,你可以使用 Elasticsearch Query DSL 指定相关功能。
from eland.ml.ltr import LTRModelConfig, QueryFeatureExtractor feature_extractors=[ # We want to use the score of the match query for the fields title and content as a feature: QueryFeatureExtractor( feature_name="title_bm25_score", query={"match": {"title": "{{query_text}}"}} ), QueryFeatureExtractor( feature_name="content_bm25_score", query={"match": {"content": "{{query_text}}"}} ), # We can use a script_score query to get the value # of the field popularity directly as a feature QueryFeatureExtractor( feature_name="popularity", query={ "script_score": { "query": {"exists": {"field": "popularity"}}, "script": {"source": "return doc['popularity'].value;"}, } }, ) ] ltr_config = LTRModelConfig(feature_extractors) 2)该过程的第二步是构建训练数据集。在此步骤中,你将计算并添加判断列表每一行的相关性特征:
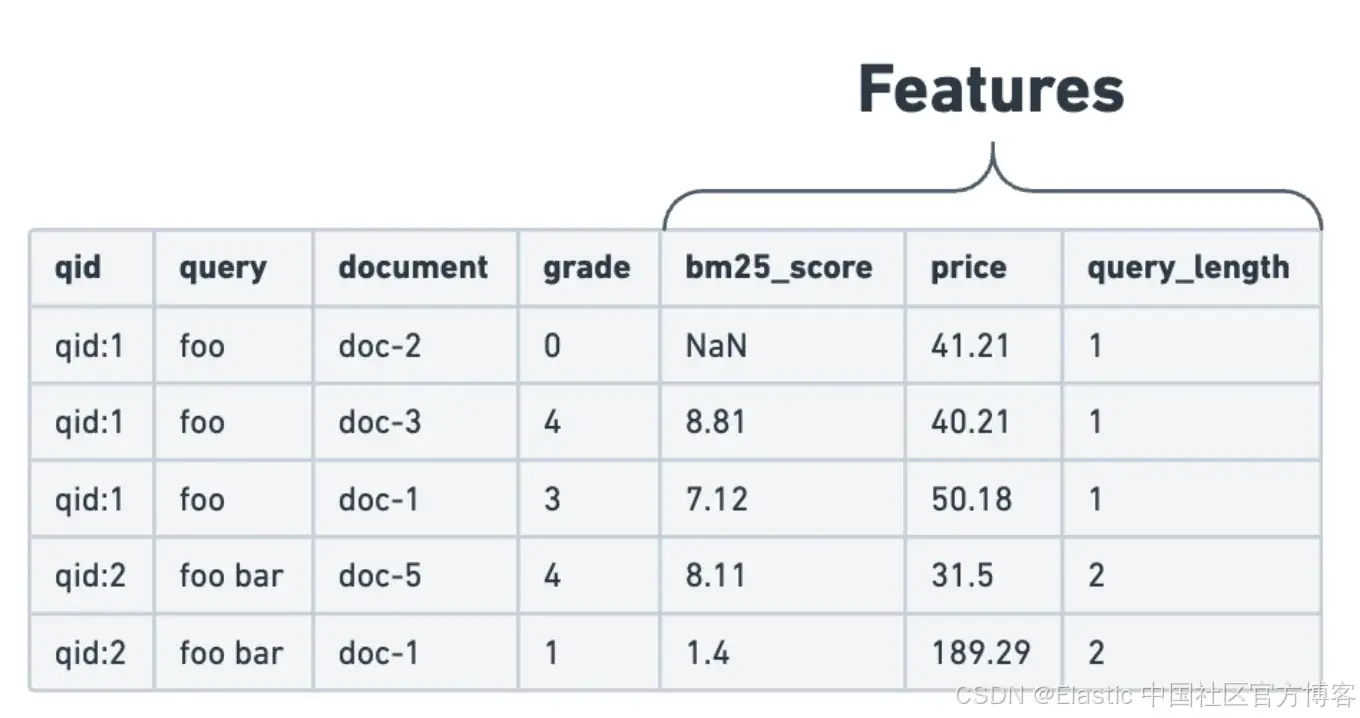
为了帮助你完成此任务,Eland 提供了 FeatureLogger 类:
from eland.ml.ltr import FeatureLogger feature_logger = FeatureLogger(es_client, MOVIE_INDEX, ltr_config) feature_logger.extract_features( query_params={"query": "foo"}, doc_ids=["doc-1", "doc-2"] ) 3)当训练数据集建立后,模型训练起来非常容易(如 notebook 中所示):
from xgboost import XGBRanker from sklearn.model_selection import GroupShuffleSplit # Create the ranker model: ranker = XGBRanker( objective="rank:ndcg", eval_metric=["ndcg@10"], early_stopping_rounds=20, ) # Shaping training and eval data in the expected format. X = judgments_with_features[ltr_config.feature_names] y = judgments_with_features["grade"] groups = judgments_with_features["query_id"] # Split the dataset in two parts respectively used for training and evaluation of the model. group_preserving_splitter = GroupShuffleSplit(n_splits=1, train_size=0.7).split( X, y, groups ) train_idx, eval_idx = next(group_preserving_splitter) train_features, eval_features = X.loc[train_idx], X.loc[eval_idx] train_target, eval_target = y.loc[train_idx], y.loc[eval_idx] train_query_groups, eval_query_groups = groups.loc[train_idx], groups.loc[eval_idx] # Training the model ranker.fit( X=train_features, y=train_target, group=train_query_groups.value_counts().sort_index().values, eval_set=[(eval_features, eval_target)], eval_group=[eval_query_groups.value_counts().sort_index().values], verbose=True, ) 4)训练过程完成后,将模型部署到 Elasticsearch:
from eland.ml import MLModel LEARNING_TO_RANK_MODEL_ID = "ltr-model-xgboost" MLModel.import_ltr_model( es_client=es_client, model=trained_model, model_id=LEARNING_TO_RANK_MODEL_ID, ltr_model_config=ltr_config, es_if_exists="replace", ) 要了解有关我们的工具如何帮助你训练和部署模型的更多信息,请查看此端到端 notebook。
在 Elasticsearch 中使用 LTR 模型作为重新评分器
在 Elasticsearch 中部署模型后,你可以通过 rescorer 增强搜索结果。重新评分器允许你使用 LTR 模型提供的更复杂的评分来优化搜索结果的首次排名:
GET my-index/_search { "query": { "multi_match": { "fields": ["title", "content"], "query": "the quick brown fox" } }, "rescore": { "learning_to_rank": { "model_id": "ltr-model-xgboost", "params": { "query_text": "the quick brown fox" } }, "window_size": 100 } }在此示例中:
- 首次查询:multi_match 查询检索在标题和内容字段中与查询 "the quick brown fox" 匹配的文档。此查询旨在快速捕获大量潜在相关文档。
- 重新评分阶段:learning_to_rank 重新评分器使用 LTR 模型细化首次查询中的顶级结果。
- model_id:指定已部署的 LTR 模型的 ID(在我们的示例中为 ltr-model-xgboost)。
- params:提供 LTR 模型提取与查询相关的特征所需的任何参数。此处 query_text 允许你指定我们的某些特征提取器期望的用户发出的查询。
- window_size:定义首次查询发出的搜索结果中要重新评分的顶级文档(top documents)数量。在此示例中,将对前 100 个文档进行重新评分。
通过将 LTR 集成为两阶段检索过程,你可以通过结合以下方式优化检索过程的性能和准确性:
- 传统搜索的速度:首次查询可以非常快速地检索大量具有广泛匹配的文档,从而确保快速响应时间。
- 机器学习模型的精度:LTR 模型仅应用于顶部结果(top results),优化其排名以确保最佳相关性。这种有针对性的模型应用可以提高精度,而不会影响整体性能。
自己尝试一下!?
无论你是在努力为电子商务平台配置搜索相关性,旨在提高 RAG 应用程序的上下文相关性,还是只是想提高现有搜索引擎的性能,你都应该认真考虑 LTR。
要开始实施 LTR,请务必访问我们的 notebook,其中详细介绍了如何在 Elasticsearch 中训练、部署和使用 LTR 模型,并阅读我们的文档。如果你根据这篇博文构建了任何内容,或者你对我们的讨论论坛和社区 Slack 频道有疑问,请告诉我们。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一次 Elasticsearch 工程师培训何时开始!
原文:Elasticsearch Learning to Rank: How to Improve Search Ranking — Search Labs
