
阅读量:2
你好,我是大壮。08 讲我们介绍了深度推荐算法中的范式方法,并简单讲解了组合范式推荐方法,其中还提到了多层感知器(MLP)。因此,这一讲我们就以 MLP 组件为基础,讲解深度学习范式的其他组合推荐方法。
MLP 是一种非常简单、原汁原味的神经网络(DNN),它能够逼近任何可测函数并得到任何期望的精确度,简洁又有效。在推荐领域,MLP 由于能有效地建模高阶交互特征,所以成了深度推荐算法中最通用的组件。
下面我们看看在推荐系统中,如何使用 MLP 进行隐向量表征学习和推荐模型建立。
深度矩阵分解(DMF)模型(双塔结构)
深度矩阵分解模型(Deep Matrix Factorization Model,DMF)是以传统的矩阵分解(MF)模型为基础,再与 MLP 网络组合而成的一种模型。
DMF 模型的框架图如下所示:该模型的输入层为交互矩阵 Y,其行、列分别对应为对用户和对物品的打分,并采用 multi-hot 形式分别表征用户和物品。
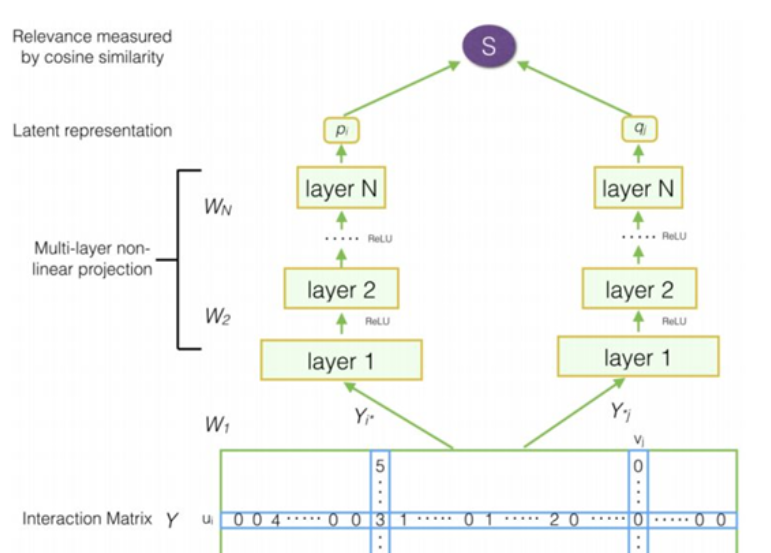
Relevance measured by cosine similarity:余弦相似度计算
Latent representation:隐向量表征
Multi-layer non-linear projection:多层非线性投影
Interaction Matrix:交互矩阵
Layer1~N:层1~N
图片来自论文《Deep Matrix Factorization Models for Recommender Systems》(IJCAI 2017)
Yi* 指的是交互矩阵 Y 中的第 i 行,表示用户 i 对所有物品的评分,即用户 i 的表征;
Y*j指的是交互矩阵 Y 中的第 j 列,表示所有用户对物品 j 的评分,即物品 j 的表征。
然后,我们将用户表征 Yi* 和物品表征 Y*j 分别送入 MLP 双塔结构,生成用户隐向量表征 Pi 和物品隐向量表征 qj;
最后,对二者使用余弦点积匹配分数。
Tips:实际上,DMF 模型是由 MF+MLP 双塔串联而成的一种模型,其中 MF 主要负责线性部分,MLP 主要负责非线性部分。它主要以学习用户和物品的高阶表征向量为目标。
下面我们有必要简单说明下什么是双塔结构。
【双塔结构】
双塔结构是一种被广泛使用的采用深度模型进行表征学习的范式组合方式,因为这样的模型画出来像一个“塔”,所以称之为“双塔”。
关于双塔结构中所谓的“塔”指的是 DNN 结构,通过在模型中加入 DNN 结构实现“降维”。在双塔结构中,靠进输入侧的参数越多,靠近输出侧的参数越少。
我们主要使用“双塔”结构,各自构建两种类型的隐向量表征,例如用户和物品的隐向量表征、Query 和 Doc 的隐向量表征等,然后通过一定的计算方式(如点积)计算二者的匹配得分。
Tips:因为最后我们需要通过相对简单的计算方式,衡量两个向量之间的距离,所以两个塔输出的向量维度必须相同。而且因为双塔结构讲究两个塔之间的平衡性,所以两个塔的参数配置通常也需要保持相同。
双塔结构为什么只通过相对简单的计算方式衡量两个向量之间的距离呢?
这是因为复杂的神经网络计算一般使用离线的方式进行计算,再将双方的隐向量表征进行存储,而线上服务只计算向量之间的距离,这样就可以缩短线上服务的响应时间,从而减少线上服务的计算量。但这也不能一概而论,例如 Query 和 Doc 的匹配计算遇到长尾 Query 时,我们就需要实时计算 Query 的隐向量。
对于算法工程师而言,算法模型可谓是他们手中的一件强有力兵器。在十八般兵器中,有人使用双枪左右开弓,必然会有人使用单枪破双枪法。
在双塔模型大行其道之时,单塔同样不输双塔,这不有人总结出了“双枪发,单枪扎;双枪不发,单枪拉”的要义。
所以,接下来我们来看看单塔结构的相关模型。
神经网络协同过滤(NFC)模型(单塔结构)
神经网络协同过滤 (Neural Collaborative Filtering, NFC) 是一个端到端的模型。为了方便你理解这部分知识,我们先来看一下传统的矩阵分解模型(MF)。
传统的矩阵分解模型(MF)将用户物品交互矩阵分解为两个低秩稠密的矩阵p和q计算公式如下:
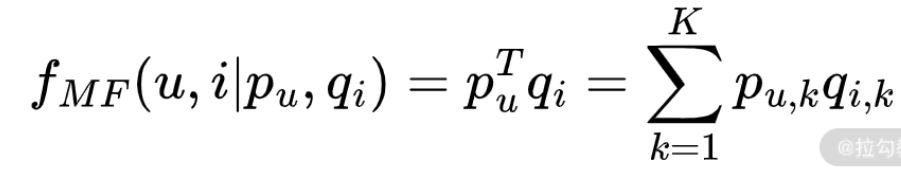
传统 MF 模型相当于把稀疏的用户和物品 ID 向量转化为了稠密的隐向量表征,模拟了浅层神经网络的作用。其中,p 代表用户的隐因子矩阵,q 代表物品的隐因子矩阵。通过这两个矩阵,我们就可以预测用户对物品的评分。
了解了传统的 MF 模型后,下面我们再来看看 NCF 模型,框架如下图所示:
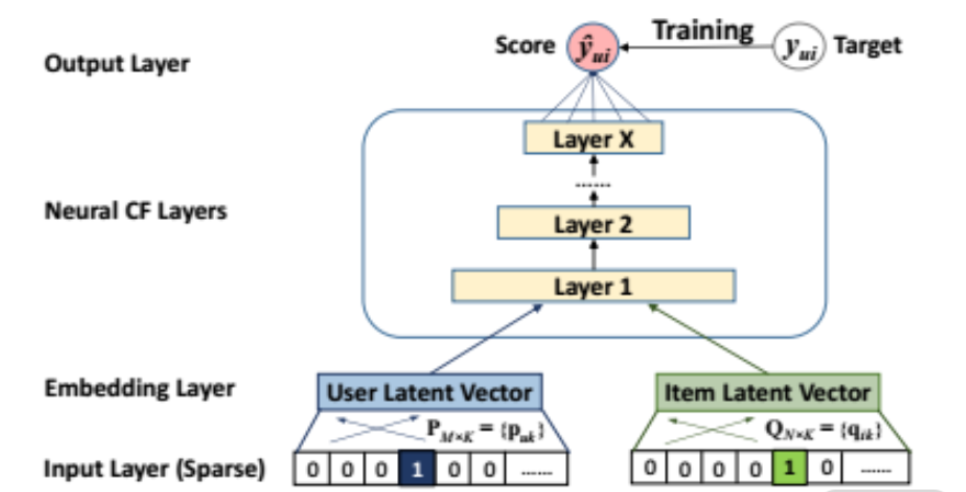
Output Layer:输出层
Neural CF Layer:神经协同过滤层
mbedding Layer:表征层
Input Layer(Sparse):稀疏输入层
Training:训练
Target:目标
Score:分数
Layer1~X:层1~X
User:用户
Item:物品
User Latent Vector:用户隐向量
Item Latent Vector:物品隐向量
从图中可知,模型输入端利用类 MF 的浅层神经网络将稀疏的用户和物品 ID(one-hot)转化为用户隐向量和物品隐向量。
NCF 模型整体操作过程:首先,利用类 MF 的结构获得用户和物品交互关系的隐向量表征,并加上用户画像和物品画像特征的向量表征,二者连接后作为 MLP 的输入;然后,我们利用 MLP 拟合用户和物品间的非线性关系。
对比双塔结构使用 MLP 对用户和物品的特征进行了隐向量提取,NCF 模型对 MLP 的使用有了本质变化。
NCF 模型由 MF+MLP 单塔串联组合而成,并以精确拟合匹配分数为目标。其中,MF 之后添加辅助信息(side information),MLP 用来拟合打分。
相比于 DMF 模型的双塔结构而言,NCF 模型主要使用 MLP 单塔拟合效用函数,然后产出端到端的预测结果。虽然该模型丧失了一些表征学习的灵活性,却获得了精确拟合匹配分数的能力。
在刺击类武器中,最早出现的长矛能够在较远的距离杀伤敌人保护自己。而在砍击类武器中,最早大规模使用的戈能够钩开敌人的盾牌阵。后来又出现了一种结合了两者优势的武器——戟,它集刺、砍、钩能力于一身。
那么,有没有一种将单塔和双塔优势结合为一体的模型呢?
有的,在 NCF 模型的同一篇论文中,我就找到了这样一个混合模型——神经矩阵分解(NeuMF)模型,下面一起来看看。
说明:从严格意义上说,它不能算是单塔和双塔的结合,但是管他呢~道德经中说“是以圣人为腹不为目,故去彼取此”,实用才是目的。
神经矩阵分解(NeuMF)模型(混合结构)
神经矩阵分解 (Neural Matrix Factorization, NeuMF)模型在 NCF 模型的基础上增加了通用矩阵分解 GMF(General Matrix Factorization)部分。
关于 NeuMF 模型框架如下图所示:
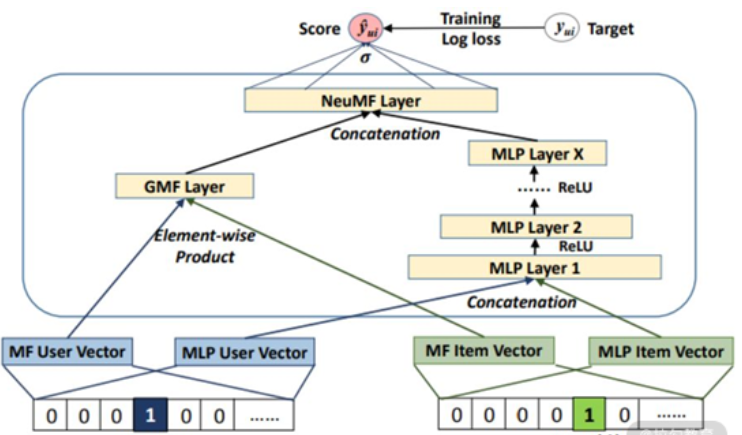
NeuMF Layer:神经矩阵分解层
Concatenation:拼接
GMF Layer:通用矩阵分解层
Element-wise Product:点积
Training:训练
Target:目标
Score:分数
MLP Layer1~X:MLP层1~X
User:用户
Item:物品
MF User Vector:矩阵分解用户向量
MLP User Vector:MLP用户向量
MF Item Vector:矩阵分解物品向量
MLP Item Vector:MLP物品向量
图中左边为 GMF 部分,它是以用户 ID 和物品 ID 的 one-hot 形式进行输入,然后利用一层网络生成用户和物品的低阶隐向量表征,再通过向量点积和一层网络输出线性交互特征。
图中右边为多层感知器,它同样是以用户 ID 和物品 ID 的 one-hot 形式进行输入,然后经过多层网络输出非线性交互特征。最后,它将 GMF 和 MLP 的输出进行连接,并经过最后一个激活函数为 Sigmoid 的全连接层,输出推荐分数。
NeuMF 模型是在 MF 通过接入 GMF+MLP 模型并联而成,再接 FC 层进行输出。该模型
采用 GMF+MLP 的并联结构,使得模型同时具备低阶和高阶特征提取的双重能力,并以精确拟合匹配分数为目标。虽然这种并联结构不平衡,但是也有一定的好处。
说到不平衡的结构模型,其中影响最为深远的要数广深(Wide&Deep)模型了。
广深(Wide&Deep)模型(不平衡结构模型)
广深(Wide&Deep)模型最早由 Google 提出,自工业界诞生后,便为在范式组合方式基础上产生模型打开了一扇大门。因此,我们与其说广深(Wide&Deep)模型是一种模型,倒不如说是一套通用的范式框架。
通过名字我们就知道,Wide&Deep 模型是由 Wide 和 Deep 两大部分组成,它的框架图如下所示:
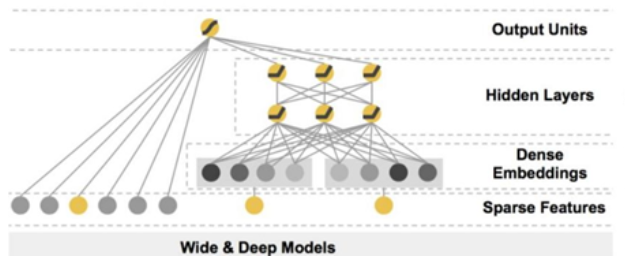
Output Units:输出单元
Hidden Layers:隐藏层
Dense Embeddings:稠密表征
Sparse Features:稀疏特征
Wide
属于广义线性部分,它对用户或者物品 ID 这类高频低阶特征使用少量参数即可学习,故记忆能力好;但是对没有见过的 ID 学习能力较差,故泛化能力差。这是因为特征从输入到输出比较通透,保留了大量的原始信息,因此模型捕捉的特征更加具体。
例如 58 同城 App 本地服务推荐业务中,如果训练数据中望京和酒仙桥的家政帖子共现频率较高,模型一旦记住了望京和酒仙桥这两个商圈 ID 的关联关系,那么就会在用户点击酒仙桥的家政帖子时,同时赋予望京的家政帖子更高的排序权重。而这种直接从历史数据挖掘的特征相关性,属于低层特征信息。当用户复现某个历史行为,模型能够拟合用户兴趣,这是对特征的良好记忆能力的一种体现。
Deep
属于神经网络 MLP 部分,它主要用于学习样本中的长尾部分,因为它对出现较少或者没有出现过的特征组合都能够做出预测,所以需要的人工参与较少,且泛化能力强。
例如App本地服务推荐业务中,家政的帖子信息进入 MLP 经过多层信息抽取后,模型挖掘到的用户兴趣会偏向高层特征信息抽象表征。如果用户产生的历史数据没有出现过新的行为,模型能够做到非零预测,这就是对特征的良好泛化能力的一种体现。
由此可见,Wide&Deep 模型同时具备记忆能力(Memorization)和泛化能力(Generalization)。
总结:Wide&Deep 模型由 LR+MLP 两部分并联组成,综合了传统机器学习和深度学习的长处。
Wide 部分根据历史行为数据推荐与用户已有行为直接相关的物品;
Deep 部分负责捕捉新的特征组合,从而提高推荐的多样性。
接下来,让我们一起看看出现的一种新模型。
1.深度因子分解机(DeepFM)模型
深度因子分解机(Deep Factorization Machine,DeepFM)模型是从广深(Wide&Deep)框架中演化出来的一种模型。
因为 Wide&Deep 模型的广义线性部分,挖掘到的用户兴趣对交叉信息仍然需要人工特征工程来人为构建特征和特征间的组合,所以过程相当繁琐且需要依赖人工经验。
那么,有没有一种办法可以避免人工特征工程呢?
答案是有的,在传统机器学习部分我们已经讲述了其解法,这就是 DeepFM 模型。它使用 FM 模型替换掉了 LR 部分,从而形成了 FM&Deep 结构。
DeepFM 模型框架如下图所示:
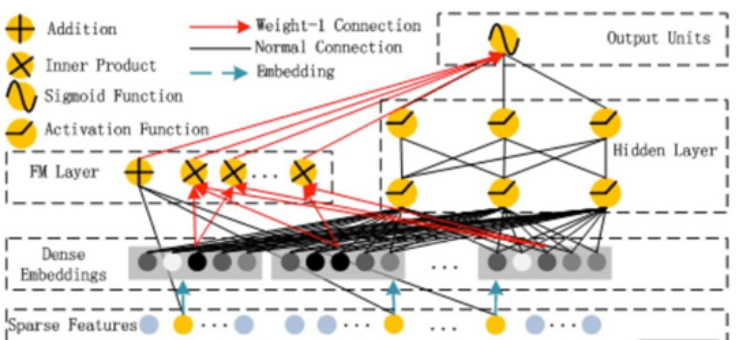
Output Units:输出单元
FM Layer:因子分解机层
Hidden Layer:隐藏层
Dense Embeddings:稠密表征
Sparse Features:稀疏特征
Addition:加
Inner Product:内积
Sigmoid Function:Sigmoid函数
Activation Function:激活函数
Weight-1 Connection:权重1连接
Normal Connection:正常连接
Embedding:隐向量
Field i~m:域 i~m
与 Wide&Deep 模型异曲同工,DeepFM 模型分为 FM 部分和 Deep 部分。
FM 部分:它可以自动提取特征交叉信息,其中包含了加权求和的一阶信息和向量内积的二阶信息。相比 Wide&Deep 模型而言,它在低层特征的使用上更合理。
Deep 部分:DeepFM 模型与 Wide&Deep 模型的 Deep 部分本质上并无区别,然而,Wide&Deep 模型中的 Embedding 层是为 Deep 部分专门设计的,而 DeepFM 模型中的Embedding 层由 Deep 部分与 FM 部分共享输出。
讲到使用 FM 替换了 LR,我们感觉传统机器学习算法那一套又来了一遍?是不是又要打 FM 模型只能进行二阶特征交叉这个缺点的主意了?
没错,接下来我们看看可以学习高于二阶特征交叉的推荐模型。
2.深度和交叉网络(DCN)模型
深度和交叉网络(Deep & Cross Network,DCN)模型是从广深(Wide&Deep)框架中演化出来的一个模型。
通过前面的学习,我们知道 Wide&Deep 在低层特征使用时,无法提供更高阶的特征,必须需要依赖人工构建交叉信息。而 DeepFM 模型中的 FM 部分虽然可以自动组合特征,但是仅限于二阶特征交叉,那么如何自动学习高于二阶特征交叉的特征组合呢?
DCN 模型将 Wide 部分替换为由特殊网络结构实现的特征交叉网络,它的框架如下图所示:左侧的交叉层除了接收前一层的输出外,还会同步接收原始输入层的特征,从而实现特征信息的高阶交叉。
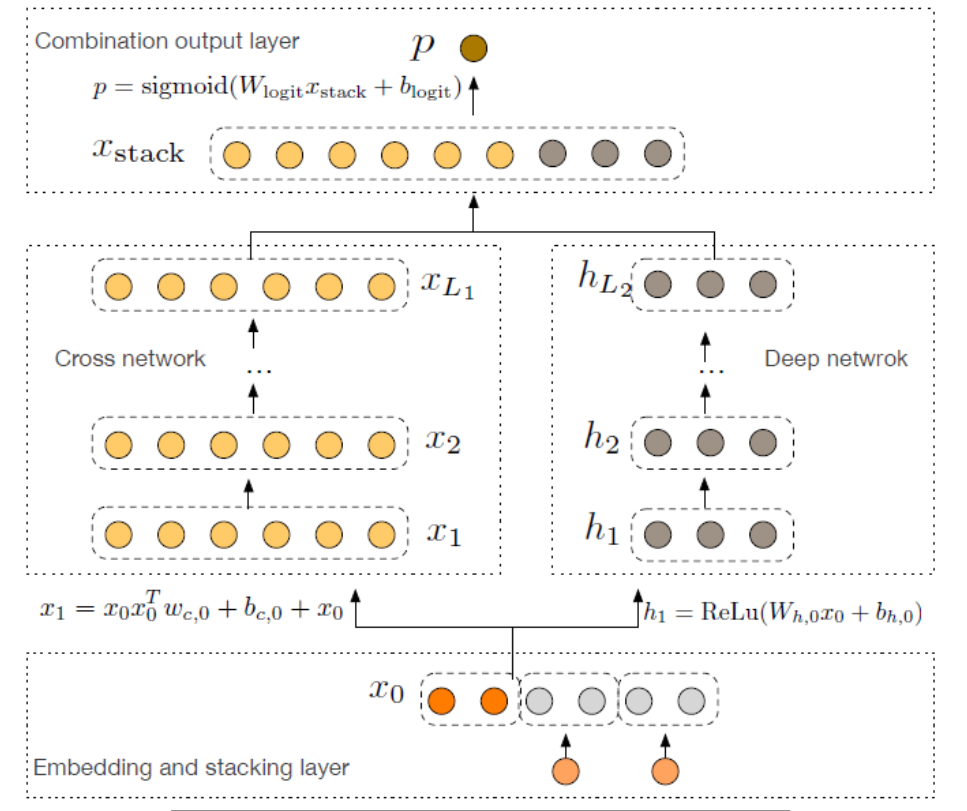

Combination output layer:组合输出层Cross network:交叉网络
Deep network:深度网络
Embedding and stacking layer:表征和堆叠层
Dense feature:稠密特征
Sparse feature:稀疏特征
Embedding vec:表征向量
Cross Layer:交叉层
Deep Layer:深度层
Output:输出
对比 DeepFM 模型,DCN 模型在低层特征的信息提取上,不仅能够挖掘特征中更高阶的交叉信息,而且计算效率更有优势。
以上两个模型主要是对 Wide 部分进行改进,因此我们会很自然地想到是不是也可以对 Deep 部分进行改进?
没错,当然可以,接下来我们一起看看又演化了什么模型。
3.神经因子分解机(NFM)模型
神经因子分解机(Neural Factorization Machine)模型也是 Wide&Deep 框架中的一种。
NFM 模型把 Wide 部分放到一边不碰,Deep 部分在 FM 的基础上结合了 MLP 部分。其中,FM 部分能够提取二阶线性特征,MLP 部分能够提取高阶非线性特征,从而使模型具备捕捉高阶非线性特征的能力。
NFM 模型框架的 Deep 部分如下图所示,NFM 模型是在 Embedding 层后将 FM 的输出进行 Bi-Interaction Pooling 操作(将表征向量的两两元素相乘后,再将所有组合的结果进行求和),然后在后面接上 MLP。
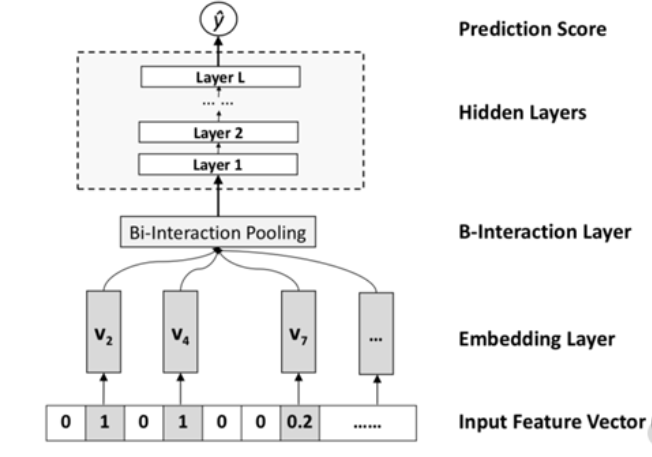
Prediction Score:预测分数
Hidden Layers:隐藏层
B-Interaction Layer:双交互层
Embedding Layer:表征层
Input Feature Vector(sparse):稀疏输入特征向量
Layer 1~L:层 1~L
相比 DeepFM 的拼接操作而言,Bi-Interaction Pooling 操作使得特征之间可以强行交互。因此,我们可以说 NFM 模型的核心是在 Deep 部分中引入了 Bi-Interaction Pooling 操作,使得 Deep 部分通过浅层网络可以学习到包含更多信息的组合特征,而且性能更好、训练和调整参数更容易。
小结与预告
道德经中“天之道,其犹张弓与!高者抑之,下者举之”。也就是说,万物都是在平衡和不平衡之中循环和轮回,算法模型的演化亦如此。
这一讲介绍了深度推荐范式的基于平衡与不平衡的组合规律,下一课时我们将继续介绍深度推荐模型的其他演化路径。
这里留一道思考题:你还能想到哪些模型符合深度推荐模型的平衡与不平衡演化路径?请在评论区与我交流。
最后,如果你觉得本专栏有价值,欢迎分享给更多好友~

