
阅读量:1
1.Rust 语法总结
数值类型
- 有符号整数:
i8,i16,i32,i64 - 无符号整数:
u8,u16,u32,u64
变量声明
- 声明变量:
let i = 0; // 类型推断 let n: i32 = 1; // 显式类型声明 - 可变变量:
let mut n =0; n = n + 1;
字符串
注意,let s: str = "Hello world"; 是不正确的,因为 str 类型不能单独使用。它必须通过引用(&str)来使用。
集合
- 动态数组(向量):
let mut v: Vec<i32> = Vec::new(); v.push(1); v.push(0); - 固定大小数组:
在 Rust 中,所有变量在使用之前必须初始化。这是为了防止未初始化变量引起的未定义行为。因此,您不能声明一个未初始化的数组或变量。
-
// 创建一个可变数组 `arr`,包含4个 `i32` 类型的元素,将所有元素初始化为0 let mut arr: [i32; 4] = [0; 4]; // 或者,可以逐个初始化每个元素 let mut arr: [i32; 4] = [0, 0, 0, 0]; // 修改数组的元素 arr[0] = 0; arr[1] = 1; arr[2] = 2; arr[3] = 3;
循环
- 迭代器循环:
// 使用 for 循环迭代向量中的元素 for i in v.iter() { println!("{}", i); // 打印每个元素 } while循环:while i < 9 { i += 1; println!("i = {}", i); // 打印每次递增后的值 }- 无限循环:
fn main() { let mut i = 0; // 初始化一个可变变量 i,初始值为 0 loop { i += 1; // 每次循环迭代将 i 的值增加 1 if i > 10 { // 检查 i 是否大于 10 break; // 如果 i 大于 10,则退出循环 } } println!("Final value of i: {}", i); // 打印 i 的最终值 }
函数
fn sum(a: i32, b: i32) -> i32 { a + b }- 声明函数:
fn sum(a: i32, b: i32) -> i32 { a + b }
表达式
- 三元表达式:
let x = if someBool { 2 } else { 4 }
输入输出
(1)确保所有缓冲区中的数据都被写入到标准输出(通常是终端或控制台)中
io::stdout().flush().unwrap();(2)read_line 方法从标准输入读取用户输入并将其存储到 guess 中。如果读取失败,程序会崩溃并显示错误信息 "读取输入失败."。
let mut guess = String::new(); io::stdin().read_line(&mut guess).expect("读取输入失败."); 操作符
(1)? 操作符
当一个函数返回 Result 或 Option 类型时,可以使用 ? 操作符来自动处理这些结果。如果结果是 Ok,则返回其中的值;如果是 Err,则返回错误并退出当前函数。
fn read_file_lines(filename: &str) -> Result<Vec<String>, io::Error> { // 尝试打开文件 let file = File::open(filename)?; // 如果成功打开文件,继续执行;如果失败,返回错误并退出函数 }定义结构体
在 Rust 中,定义结构体类型时,我们声明了结构体的字段及其类型,而不是创建具体的实例。因此,不需要使用let或let mut这样的关键字。let和let mut关键字用于创建变量,而不是定义类型。
在这段代码中,我们定义了一个名为 Node 的泛型结构体类型,它包含三个字段:
elem:类型为T,表示节点存储的值。next:类型为Link<T>,表示下一个节点的引用。prev:类型为Link<T>,表示前一个节点的引用。
这个定义仅仅是声明了 Node 结构体的形状,并没有创建任何实际的 Node 实例。
impl 块
Rust 中的 impl 块类似于其他编程语言中的 class 定义,但有一些关键的不同之处。
类似点
方法定义:
- 在
impl块中定义的方法类似于在类中定义的方法。 - 你可以定义实例方法和静态方法(Rust 中称为关联函数)。
- 在
封装:
- Rust 的
impl块可以用于封装数据和行为,类似于类。
- Rust 的
不同点
数据和行为的分离:
- 在 Rust 中,数据(通过结构体或枚举)和行为(通过
impl块)是分开的。 - 在类中,数据和行为通常是在一个定义中。
- 在 Rust 中,数据(通过结构体或枚举)和行为(通过
没有继承:
- Rust 没有类的继承。相反,它使用特性(traits)来实现多态性。
- 类系统通常有继承和多态性机制。
所有权和借用:
- Rust 强调所有权和借用,确保内存安全。
- 类系统通常使用垃圾回收(如 Java)或手动内存管理(如 C++)。
struct Rectangle { width: u32, height: u32, } impl Rectangle { fn new(width: u32, height: u32) -> Rectangle { Rectangle { width, height } } fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect = Rectangle::new(30, 50); println!("The area of the rectangle is {} square pixels.", rect.area()); } 2.进阶用法
闭包
闭包是一种匿名函数,它允许捕获调用者作用域中的值,可以赋值给变量,也可以作为参数传递给其他函数。闭包在许多现代编程语言中作为核心特性被广泛使用。
示例代码:
fn main() { let x = 1; let sum = |y| x + y; assert_eq!(3, sum(2)); } 闭包 sum 捕获了变量 x 并对其进行了操作。
使用闭包简化代码
传统函数实现:
fn muuuuu(intensity: u32) -> u32 { println!("muuuu....."); thread::sleep(Duration::from_secs(2)); intensity } fn workout(intensity: u32, random_number: u32) { // 根据 intensity 调整健身动作 } 函数变量实现:
fn muuuuu(intensity: u32) -> u32 { println!("muuuu....."); thread::sleep(Duration::from_secs(2)); intensity } fn workout(intensity: u32, random_number: u32) { let action = muuuuu; // 根据 intensity 调整健身动作 } 闭包实现:
fn workout(intensity: u32, random_number: u32) { let action = || { println!("muuuu....."); thread::sleep(Duration::from_secs(2)); intensity }; // 根据 intensity 调整健身动作 } 通过闭包可以简化代码,并捕获外部变量,使得代码更具灵活性。
闭包的语法和类型推导
闭包的定义形式如下:
|param1, param2| { 语句1; 语句2; 返回表达式 } 类型推导示例:
let sum = |x: i32, y: i32| -> i32 { x + y }; 不标注类型的闭包声明更简洁:
let sum = |x, y| x + y;
结构体中的闭包
在 Rust 中,实现一个简易缓存的设计可以通过使用结构体和闭包来实现。(闭包应该作为一个变量传递,并且使用泛型和特征约束来指定它的类型。
struct Cacher<T> where T: Fn(u32) -> u32, { query: T, value: Option<u32>, } 核心概念
闭包与特征约束:
T: Fn(u32) -> u32表示T是一个实现了Fn(u32) -> u32特征的类型,这意味着query是一个闭包或函数,接受一个u32类型的参数并返回一个u32类型的值。- 每个闭包都有其唯一的类型,即使它们的签名相同。
结构体设计:
query字段是一个闭包,用于获取值。value字段用于存储缓存的值,初始为None。
实现方法
为 Cacher 结构体实现方法:
impl<T> Cacher<T> where T: Fn(u32) -> u32, { fn new(query: T) -> Cacher<T> { Cacher { query, value: None, } } fn value(&mut self, arg: u32) -> u32 { match self.value { Some(v) => v, None => { let v = (self.query)(arg); self.value = Some(v); v } } } } 主要步骤
创建缓存实例:
- 使用
Cacher::new创建新的缓存实例,传入一个闭包或函数作为query。
- 使用
查询缓存值:
value方法首先检查self.value是否已有缓存值。- 如果没有,调用
query获取新值,并将其存储在self.value中。
泛型扩展
为了支持其他类型(如 &str),可以将 u32 替换为泛型类型 E。
struct Cacher<T, E> where T: Fn(E) -> E, { query: T, value: Option<E>, } impl<T, E> Cacher<T, E> where T: Fn(E) -> E, E: Copy, { fn new(query: T) -> Cacher<T, E> { Cacher { query, value: None, } } fn value(&mut self, arg: E) -> E { match self.value { Some(v) => v, None => { let v = (self.query)(arg); self.value = Some(v); v } } } } 闭包的特征(Traits)
闭包捕获变量有三种途径,分别对应三种特征:
- FnOnce:转移所有权,闭包只能执行一次。
- FnMut:可变借用,允许修改捕获的值。
- Fn:不可变借用,仅仅访问值。
示例代码:
fn fn_once<F>(func: F) where F: FnOnce(usize) -> bool, { println!("{}", func(3)); } let x = vec![1, 2, 3]; fn_once(|z| z == x.len()); 闭包的应用场景
闭包可以用于多种场景,包括缓存、异步操作、事件处理等。
缓存实现示例:
rust
Copy code
struct Cacher<T> where T: Fn(u32) -> u32, { query: T, value: Option<u32>, } impl<T> Cacher<T> where T: Fn(u32) -> u32, { fn new(query: T) -> Cacher<T> { Cacher { query, value: None } } fn value(&mut self, arg: u32) -> u32 { match self.value { Some(v) => v, None => { let v = (self.query)(arg); self.value = Some(v); v } } } }
闭包的生命周期
闭包的生命周期与其捕获的变量的生命周期相关。通常,闭包的生命周期应不超过其捕获变量的生命周期。
示例代码:
rust
Copy code
fn main() { let x = 4; let equal_to_x = |z| z == x; let y = 4; assert!(equal_to_x(y)); }
总结
闭包在 Rust 中是强大且灵活的工具,允许捕获外部变量,简化代码逻辑,且在多种场景下表现出色。通过熟练使用闭包,可以提高代码的可读性和维护性。
(2)all 方法
fn all<F>(&mut self, f: F) -> bool where F: FnMut(Self::Item) -> bool, 它接受一个闭包 f 作为参数,并对迭代器中的每个元素应用这个闭包。all 方法会返回一个布尔值:
- 如果所有元素都满足闭包
f的条件,则返回true。 - 如果任何一个元素不满足闭包
f的条件,则返回false。
(3)迭代器
let chars_left = vec![false, true, false, true]; 原理:
创建迭代器:
let iter = chars_left.iter(); 迭代示例:
let first = iter.next(); // Some(&false) let second = iter.next(); // Some(&true) let third = iter.next(); // Some(&false) let fourth = iter.next(); // Some(&true) let none = iter.next(); // None用法:
- 创建迭代器:通过调用集合的
iter、iter_mut或into_iter方法创建迭代器。- 遍历:使用
for循环或while let语句。- 常用方法:
- 转换:
map、filter、enumerate、zip- 收集:
collect、fold- 检查:
all、any- 链式调用:将多个迭代器方法链式调用以实现复杂的数据处理。
(1)转换:
map():对每个元素应用一个函数,返回一个新的迭代器。filter():过滤符合条件的元素,返回一个新的迭代器。enumerate():为迭代器中的每个元素生成一个索引,返回(索引, 元素)对。zip():将两个迭代器合并为一个新的迭代器,生成(元素1, 元素2)对。
(2)收集:
collect():将迭代器的所有元素收集到一个集合类型中,通常是一个向量(Vec<T>)。fold():将迭代器的所有元素通过一个累积函数聚合为一个值。
(3)检查:
all():检查是否所有元素都满足一个条件。any():检查是否有任意元素满足一个条件。
(4)链式调用:
将多个迭代器方法链式调用,以实现复杂的数据处理。例如:过滤、映射和收集的组合。
例子:
fn main() { let vec = vec![1, 2, 3, 4, 5]; // 使用迭代器遍历元素 for val in vec.iter() { println!("{}", val); } // 使用链式调用过滤和映射元素,然后收集结果 let processed: Vec<i32> = vec.iter() .filter(|&&x| x % 2 == 0) // 过滤出偶数 .map(|&x| x * 2) // 将每个偶数乘以 2 .collect(); // 收集结果到一个向量 println!("{:?}", processed); // 输出: [4, 8] } (4)枚举类型
(1)Option类型
在 Rust 中,Option 类型是一种枚举,用于表示一个值可能存在(Some)或者不存在(None)
fn main() { let numbers = vec![1, 2, 3]; let empty: Vec<i32> = Vec::new(); match get_first_element(&numbers) { Some(value) => println!("第一个元素是: {}", value), None => println!("数组为空"), } match get_first_element(&empty) { Some(value) => println!("第一个元素是: {}", value), None => println!("数组为空"), } }(2)Result类型
Result<T, E>:
- 用于表示一个操作的成功或失败。
在 Rust 中,
Result枚举类型需要两个类型参数:Result<T, E>:表示操作的结果。Ok(T):表示操作成功,包含类型T的值。Err(E):表示操作失败,包含类型E的错误信息。
-
fn read_file_lines(filename: &str) -> Result<Vec<String>, io::Error> { let file = File::open(filename)?; let reader = BufReader::new(file); let mut lines = Vec::new(); for line in reader.lines() { let line = line?; lines.push(line); } Ok(lines) }
使用 Ok 包装一个值时,你实际上是在创建一个 Result 类型的实例,表示操作成功,并返回该值作为 Result 的成功变体。
(5)match 表达式
match 表达式是 Rust 中用于模式匹配的强大工具。它可以根据不同的模式执行不同的代码分支。
match value { pattern1 => expr1, pattern2 => expr2, _ => expr3, // 通配模式,匹配所有其他情况 } (6)读取文件
在 Rust 中读取文件的流程通常包括以下步骤:
- 导入必要的模块:包括文件系统和 I/O 操作的模块。
- 打开文件:使用
std::fs::File::open方法打开文件,并处理可能的错误。 - 创建缓冲读取器(可选):如果逐行读取文件内容,可以使用
std::io::BufReader创建一个缓冲读取器。 - 读取文件内容:根据需要选择读取文件内容的方法,例如逐行读取、一次性读取到字符串、一次性读取到字节数组等。
- 处理文件内容:对读取到的文件内容进行处理。
- 错误处理:在读取和处理文件内容的过程中,处理可能的错误。
方法一:逐行读取文件内容
关键点:使用 BufReader 和 lines 方法逐行读取文件
use std::fs::File; use std::io::{self, BufRead, BufReader}; fn read_file_lines(filename: &str) -> Result<Vec<String>, io::Error> { let file = File::open(filename)?; // 打开文件 let reader = BufReader::new(file); // 创建缓冲读取器 reader.lines().collect() // 逐行读取并收集结果 } fn main() { match read_file_lines("example.txt") { Ok(lines) => lines.iter().for_each(|line| println!("{}", line)), Err(e) => eprintln!("Error reading file: {}", e), } } 方法二:一次性读取整个文件内容到字符串
关键点:使用 read_to_string 方法一次性读取整个文件内容
use std::fs::File; use std::io::{self, Read}; fn read_file_to_string(filename: &str) -> Result<String, io::Error> { let mut file = File::open(filename)?; // 打开文件 let mut contents = String::new(); file.read_to_string(&mut contents)?; // 读取文件内容到字符串 Ok(contents) } fn main() { match read_file_to_string("example.txt") { Ok(contents) => println!("{}", contents), Err(e) => eprintln!("Error reading file: {}", e), } } 方法三:一次性读取整个文件内容到字节数组
关键点:使用 read_to_end 方法一次性读取整个文件内容到字节数组
use std::fs::File; use std::io::{self, Read}; fn read_file_to_bytes(filename: &str) -> Result<Vec<u8>, io::Error> { let mut file = File::open(filename)?; // 打开文件 let mut contents = Vec::new(); file.read_to_end(&mut contents)?; // 读取文件内容到字节数组 Ok(contents) } fn main() { match read_file_to_bytes("example.txt") { Ok(contents) => println!("{:?}", contents), Err(e) => eprintln!("Error reading file: {}", e), } } 方法四:使用 std::fs::read_to_string 直接读取整个文件到字符串
关键点:使用 fs::read_to_string 直接读取文件内容到字符串
use std::fs; fn read_file_to_string(filename: &str) -> Result<String, std::io::Error> { fs::read_to_string(filename) // 直接读取文件内容到字符串 } fn main() { match read_file_to_string("example.txt") { Ok(contents) => println!("{}", contents), Err(e) => eprintln!("Error reading file: {}", e), } } 方法五:使用 std::fs::read 直接读取整个文件到字节数组
关键点:使用 fs::read 直接读取文件内容到字节数组
use std::fs; fn read_file_to_bytes(filename: &str) -> Result<Vec<u8>, std::io::Error> { fs::read(filename) // 直接读取文件内容到字节数组 } fn main() { match read_file_to_bytes("example.txt") { Ok(contents) => println!("{:?}", contents), Err(e) => eprintln!("Error reading file: {}", e), } } 总结
- 逐行读取文件内容:使用
BufReader和lines方法。 - 一次性读取整个文件内容到字符串:使用
read_to_string方法。 - 一次性读取整个文件内容到字节数组:使用
read_to_end方法。 - 直接读取整个文件到字符串:使用
fs::read_to_string方法。 - 直接读取整个文件到字节数组:使用
fs::read方法。
RefCell 概括
RefCell 是 Rust 提供的一种类型,用于在不可变的上下文中实现内部可变性。它允许你在运行时执行借用检查,以确保安全地修改数据。这在某些数据结构(如链表)和特定场景(如闭包或异步编程)中非常有用。
核心特点
内部可变性:
- 允许在不可变的上下文中修改数据。
- 使用
borrow()获取不可变引用。 - 使用
borrow_mut()获取可变引用。
运行时借用检查:
- 在借用时进行运行时检查,确保借用规则不被违反。
- 如果在借用过程中违反规则,会导致运行时错误。
典型用法:
- 适用于实现复杂数据结构,如链表、图等需要相互引用的结构。
- 适用于跨越函数的借用,尤其在闭包和异步编程中。
示例代码
use std::cell::RefCell; let x = RefCell::new(5); { let y = x.borrow(); println!("y: {}", *y); // 输出: y: 5 } { let mut z = x.borrow_mut(); *z = 10; println!("x: {}", x.borrow()); // 输出: x: 10 } Rc 的核心作用概括
Rc(Reference Counted)是 Rust 提供的一种智能指针,允许多个所有者共享同一个数据。
核心特点
共享所有权:
- 允许多个变量同时拥有同一个数据。
- 适用于需要在多个地方访问和使用同一个数据的场景。
自动管理内存:
- 通过引用计数管理数据的生命周期。
- 当最后一个引用被删除时,数据会自动释放。
单线程环境:
- 只能在单线程环境中使用。
- 如果需要在多线程环境中共享数据,使用
Arc(Atomic Reference Counted)。
使用场景
数据共享:
- 例如,在树或图数据结构中,多个节点可以共享同一个子节点。
不可变数据:
- 通常用于共享不可变数据,因为
Rc默认不允许多个可变引用。 - 如果需要修改数据,可以结合
RefCell使用。
- 通常用于共享不可变数据,因为
示例代码
use std::rc::Rc; fn main() { let data = Rc::new(5); // 创建一个 Rc 指针,包含数据 5 let data1 = Rc::clone(&data); // 创建 data 的克隆引用 let data2 = Rc::clone(&data); // 创建 data 的另一个克隆引用 println!("Reference count: {}", Rc::strong_count(&data)); // 输出: 3 println!("data: {}", data); println!("data1: {}", data1); println!("data2: {}", data2); } Rc 的销毁时机
对于 Rc(Reference Counted)智能指针,当一个 Rc 实例超出其作用域时,引用计数会自动减少。如果引用计数减少到零,Rc 管理的数据将被释放。
use std::cell::RefCell; use std::rc::Rc; fn main() { { let data = Rc::new(RefCell::new(5)); // 创建一个包含 RefCell 的 Rc 指针 println!("Initial reference count: {}", Rc::strong_count(&data)); // 输出: 1 { let data1 = Rc::clone(&data); // 克隆 Rc 指针,引用计数增加到 2 println!("Reference count after creating data1: {}", Rc::strong_count(&data)); // 输出: 2 { let data2 = Rc::clone(&data); // 再次克隆 Rc 指针,引用计数增加到 3 println!("Reference count after creating data2: {}", Rc::strong_count(&data)); // 输出: 3 *data2.borrow_mut() = 10; // 修改数据 println!("Modified data through data2: {}", data.borrow()); // 输出: 10 } // data2 超出作用域,引用计数减少到 2 println!("Reference count after data2 goes out of scope: {}", Rc::strong_count(&data)); // 输出: 2 } // data1 超出作用域,引用计数减少到 1 println!("Reference count after data1 goes out of scope: {}", Rc::strong_count(&data)); // 输出: 1 } // data 超出作用域,引用计数减少到 0,数据被释放 // 由于 data 已经被释放,不能再访问它 } 字符串操作
字符串替换
1. replace
- 适用类型:
String和&str - 参数:
- 第一个参数是要被替换的字符串。
- 第二个参数是新的字符串。
- 功能: 替换所有匹配的字符串,返回一个新的字符串。
示例代码:
fn main() { let string_replace = String::from("I like rust. Learning rust is my favorite!"); let new_string_replace = string_replace.replace("rust", "RUST"); dbg!(new_string_replace); } 运行结果:
new_string_replace = "I like RUST. Learning RUST is my favorite!" 2. replacen
- 适用类型:
String和&str - 参数:
- 前两个参数与
replace方法相同。 - 第三个参数表示替换的次数。
- 前两个参数与
- 功能: 替换指定次数的匹配字符串,返回一个新的字符串。
示例代码:
fn main() { let string_replace = "I like rust. Learning rust is my favorite!"; let new_string_replacen = string_replace.replacen("rust", "RUST", 1); dbg!(new_string_replacen); } 运行结果:
new_string_replacen = "I like RUST. Learning rust is my favorite!" 3. replace_range
- 适用类型: 仅适用于
String - 参数:
- 第一个参数是要替换的字符串范围(
Range)。 - 第二个参数是新的字符串。
- 第一个参数是要替换的字符串范围(
- 功能: 直接在原字符串上替换指定范围内的内容,不返回新的字符串。
示例代码:
fn main() { let mut string_replace_range = String::from("I like rust!"); string_replace_range.replace_range(7..8, "R"); dbg!(string_replace_range); } 运行结果:
string_replace_range = "I like Rust!" 字符串删除方法
1. truncate
- 功能: 从指定位置开始删除字符串中从该位置到结尾的全部字符。
- 特性: 直接操作原字符串,无返回值。如果指定位置不在字符边界上,则会发生错误。
示例代码:
fn main() { let mut string_truncate = String::from("测试truncate"); string_truncate.truncate(3); dbg!(string_truncate); } 运行结果:
string_truncate = "测" 2. clear
- 功能: 清空字符串,删除字符串中的所有字符。
- 特性: 直接操作原字符串,相当于
truncate()方法参数为 0。
示例代码:
fn main() { let mut string_clear = String::from("string clear"); string_clear.clear(); dbg!(string_clear); } 运行结果:
string_clear = "" 字符串连接
1. 使用 + 或 += 操作符
要求:
- 右边的参数必须为字符串切片引用(
&str)。 - 调用
+操作符相当于调用了标准库中的add方法。
- 右边的参数必须为字符串切片引用(
特性:
- 返回一个新的字符串。
- 变量声明可以不需要
mut关键字修饰。 - 左边的字符串所有权会被转移。
示例代码:
fn main() { let string_append = String::from("hello "); let string_rust = String::from("rust"); let result = string_append + &string_rust; // string_append 的所有权被转移 let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的 result += "!!!"; println!("连接字符串 + -> {}", result); } 运行结果:
连接字符串 + -> hello rust!!!! 所有权转移示例:
fn main() { let s1 = String::from("hello,"); let s2 = String::from("world!"); let s3 = s1 + &s2; // s1 的所有权被转移 assert_eq!(s3, "hello,world!"); // println!("{}", s1); // 这行代码会报错,因为 s1 的所有权已被转移 }连续连接示例:
let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); // String = String + &str + &str + &str + &str let s = s1 + "-" + &s2 + "-" + &s3;
s1 这个变量通过调用 add() 方法后,所有权被转移到 add() 方法里面, add() 方法调用后就被释放了,同时 s1 也被释放了。再使用 s1 就会发生错误。
2. 使用 format! 宏
- 适用:
String和&str - 特性: 类似于
print!的用法,生成一个新的字符串。
示例代码:
fn main() { let s1 = "hello"; let s2 = String::from("rust"); let s = format!("{} {}!", s1, s2); println!("{}", s); } 运行结果:
hello rust! 3.Rust特性
(1)所有权
所有权机制是Rust用来管理内存的一种系统,它确保了内存安全性并防止了许多常见的编程错误。以下是所有权机制的核心概念和规则:
1. 所有权规则
每个值在Rust中都有一个所有者:
- 所有者是一个变量,只有一个变量可以是某个值的所有者。
值在任一时刻只能有一个所有者:
- 当所有者变量超出作用域时,该值将被自动清理。
当所有者离开作用域时,该值将被丢弃:
- Rust在所有者超出作用域时自动调用
drop函数来释放内存。
- Rust在所有者超出作用域时自动调用
2. 所有权转移(Move)
(1)非
Copytrait 的类型赋值let s = String::from("hello"); let s1 = s;- 在这个例子中,
s的栈上的数据所有权被转移给s1(堆上数据仍然不变,移动语义),因此在之后使用s1会导致编译错误。
- 在这个例子中,
(2)self 作为参数:
方法或函数以 self 作为参数时,会获取调用者的所有权,调用后原变量失效。
(3) 非引用参数:
类似地,函数以非引用类型参数接收变量时,也会获取其所有权。
(4)克隆
let s = String::from("hello"); let s1 = s.clone();在Rust中,使用clone方法可以进行深拷贝。深拷贝会复制堆上的数据,并在栈上创建一个新的所有权指向这块堆内存。结果是栈上和堆上都有独立的拷贝,因此两个变量互不影响。
(5)
Copytrait 的类型- 整数类型 (
i32,u32, 等) - 浮点数类型 (
f32,f64) - 布尔类型 (
bool) - 字符类型 (
char) - 元组(如果元组内的所有元素都实现了
Copytrait) (6)无法copy的类型
非Copy类型:
- 复杂类型如
String不实现Copy特性,因为它们涉及更复杂的内存管理。 - 不能对不实现
Copy的类型进行直接赋值拷贝。
- 复杂类型如
解决方案:
- 使用引用:对于无法实现
Copy的类型,可以通过引用来解决所有权冲突。 -
fn main() { let x = (1, 2, (), "hello".to_string()); let y = (&x.0, &x.1, &x.2, &x.3); println!("{:?}, {:?}", x, y); }
- 使用引用:对于无法实现
3. 借用(Borrowing)
引用的可变性决定了你是否可以通过引用来修改所引用的值。
(1)不可变借用:
- 可以有多个不可变引用,但不能同时有可变引用。
let s = String::from("hello"); let r1 = &s; // 不可变引用 r1 let r2 = &s; // 不可变引用 r2 println!("r1: {}, r2: {}", r1, r2); // 可以同时使用多个不可变引用(2)可变借用:
- 同一时间只能有一个可变引用,且不能同时存在不可变引用。
let mut s = String::from("hello"); let r1 = &mut s; // 可变引用 r1 r1.push_str(", world"); println!("{}", r1); // r1 修改了 s 的内容
- 唯一的可变引用:在任何给定的时间点,一个变量只能有一个可变引用(
&mut)。 - 不可变引用与可变引用互斥:在有可变引用存在时,不允许同时存在不可变引用(
&)。反之,在存在不可变引用时,不允许存在可变引用。
这些规则确保了在访问和修改数据时不会出现竞争条件。
(3)注意:
1.不允许在存在不可变引用时修改原始变量
fn main() { let mut s = String::from("hello"); // 可变变量 `s` 被创建 let ref1 = &s; // 创建对 `s` 的不可变引用 `ref1` s = String::from("goodbye"); // 尝试修改 `s` 的值 println!("{}", ref3.to_uppercase()); // 使用 `ref3` 打印 `s` 的值 } 一种修复方法是将 println! 语句移动到修改 s 之前,确保在修改 s 之前,所有的不可变引用都已经被使用完毕。例如:
fn main() { let mut s = String::from("hello"); let ref1 = &s; let ref2 = &ref1; let ref3 = &ref2; println!("{}", ref3.to_uppercase()); // 在修改 `s` 之前使用 `ref3` s = String::from("goodbye"); // 现在可以安全地修改 `s` } 2. 悬垂引用
返回的是一个局部变量的引用,函数作用域结束后,变量销毁
fn drip_drop() -> &String { let s = String::from("hello world!"); return &s; } 修改方法:直接返回所有权
fn drip_drop() -> String { let s = String::from("hello world!"); return s; } 3.借用检查器错误
v[0]返回一个引用,试图将向量中元素的引用赋值给一个所有权变量
fn main() { let s1 = String::from("hello"); let mut v = Vec::new(); v.push(s1); let s2: String = v[0]; // 试图移动元素的所有权 println!("{}", s2); } 解决方法:(仅读取)
fn main() { let s1 = String::from("hello"); let mut v = Vec::new(); v.push(s1); let s2: &String = &v[0]; println!("{}", s2); } 4.切片
切片(slice)是Rust中对数组、字符串等集合部分数据的引用。它具有以下核心特性:
- 引用类型:不拥有数据所有权,只是借用数据的一部分。
- 不可变和可变:支持不可变切片(
&[T])和可变切片(&mut [T])。 - 高效:避免数据拷贝,直接引用原数据。
- 安全:编译时和运行时边界检查,防止越界访问和数据竞争。
(1)不可变切片
fn main() { let arr = [1, 2, 3, 4, 5]; let slice = &arr[1..4]; // 引用数组的部分数据 println!("{:?}", slice); // 输出 [2, 3, 4] } (2)可变切片
fn main() { let mut arr = [1, 2, 3, 4, 5]; let slice = &mut arr[1..3]; // 可变切片,引用数组的部分数据 slice[0] = 10; println!("{:?}", arr); // 输出 [1, 10, 3, 4, 5] } (3)字符串切片
fn main() { let s = String::from("hello, world"); let hello = &s[0..5]; // 引用字符串的部分数据 println!("{}", hello); // 输出 "hello" } (4)切片操作
fn main() { let arr = [1, 2, 3, 4, 5]; let slice = &arr[1..4]; println!("Length: {}", slice.len()); // 输出 "Length: 3" println!("First element: {:?}", slice.first()); // 输出 "First element: Some(2)" } 5. 数据竞争的避免
- Rust的借用检查器在编译时强制执行借用规则,以确保在任何给定时间只有一个可变引用或多个不可变引用,从而避免数据竞争。
5. 生命周期
- Rust通过生命周期标注来确保引用的有效性,防止悬空引用。
(2)显式使用引用操作符
常见情况
创建引用:
- 当你需要创建一个变量的引用时,需要显式地使用
&。
let x = 5; let y = &x; // 创建对 x 的不可变引用 let z = &mut x; // 创建对 x 的可变引用(需要 x 是可变的)- 当你需要创建一个变量的引用时,需要显式地使用
函数参数传递引用:
- 当你定义一个函数,并希望它接收一个引用作为参数时,需要显式地使用
&。
fn print_value(value: &i32) { println!("{}", value); } let x = 10; print_value(&x); // 传递 x 的引用- 当你定义一个函数,并希望它接收一个引用作为参数时,需要显式地使用
解引用:
- 当你需要从一个引用中获取实际值时,需要显式地使用
*。
let x = 5; let y = &x; println!("{}", *y); // 解引用 y 获取 x 的值- 当你需要从一个引用中获取实际值时,需要显式地使用
注意和习惯
基本类型
为什么要手动设置变量可变性
- Rust支持可变和不可变变量,提供了灵活性和安全性,性能优化
- 将无需改变的变量声明为不可变,可以提升运行性能,避免多余的运行时检查。
变量命名
- 使用下划线开头的变量名,可以忽略未使用变量的警告。
let表达式可以用于变量解构,从复杂变量中匹配出部分内容。
整形溢出处理
- Rust提供了多种方法显式处理整型溢出,如
wrapping_*、checked_*、overflowing_*和saturating_*。 wrapping_*方法:- 描述:当发生溢出时,值会按照二进制补码环绕(wrap around)。这意味着溢出后的结果将从最低有效位开始重新计算。
- 用法:
wrapping_add、wrapping_sub、wrapping_mul等。 - 示例:
let x: u8 = 255; let y = x.wrapping_add(1); // y == 0 - 核心:溢出后环绕,继续计算,不会引发程序错误。
checked_*方法:- 描述:当发生溢出时,返回一个
None,否则返回Some(结果)。适合需要检测并处理溢出的情况。 - 用法:
checked_add、checked_sub、checked_mul等。 - 示例:
let x: u8 = 255; if let Some(y) = x.checked_add(1) { // 不会执行 } else { println!("溢出检测到"); } - 核心:通过返回
Option类型来检测和处理溢出。
- 描述:当发生溢出时,返回一个
overflowing_*方法:- 描述:返回一个包含计算结果和布尔值的元组,布尔值指示是否发生溢出。
- 用法:
overflowing_add、overflowing_sub、overflowing_mul等。 - 示例:
let x: u8 = 255; let (y, overflowed) = x.overflowing_add(1); // y == 0, overflowed == true - 核心:提供溢出后的结果,并显式指示溢出是否发生。
saturating_*方法:- 描述:当发生溢出时,值会被夹紧到类型的最大或最小值。适合需要确保结果在一定范围内的情况。
- 用法:
saturating_add、saturating_sub、saturating_mul等。 - 示例:
let x: u8 = 255; let y = x.saturating_add(1); // y == 255 - 核心:溢出后结果被限制在合法范围内(最大或最小值)。
数字字面量下划线
在Rust中,数字字面量中的下划线(_)可以用于增加可读性,它们不会影响数值的实际值。
示例:1_000.000_1 表示 1000.0001。
Rust字符
Rust 的字符不仅仅是 ASCII,所有的 Unicode 值都可以作为 Rust 字符,包括单个的中文、日文、韩文、emoji 表情符号等等,都是合法的字符类型。Unicode 值的范围从 U+0000 ~ U+D7FF 和 U+E000 ~ U+10FFFF。
由于 Unicode 都是 4 个字节编码,因此字符类型也是占用 4 个字节:
单元类型()
在Rust中,单元类型 () 表示空值或空元组,通常用于函数不返回任何值的情况。尽管逻辑上是空的,但它在内存中占用的大小为0字节。使用 std::mem::size_of_val 可以确认这一点,例如 assert!(size_of_val(&unit) == 0);,这保证了 unit 的内存占用为0,体现了Rust中零大小类型(ZST)的概念和用途。
所有权
永远不会返回的函数(发散函数)
- 发散函数:返回类型为
!,表示函数永远不会正常返回控制权。 - 实现方法:
- 无限循环:使用
loop {}创建一个永不退出的循环。 panic!:触发一个恐慌,使程序中止。std::process::exit:立即终止程序并返回指定的状态码。
- 无限循环:使用
// 方法一:使用无限循环 fn never_return_fn() -> ! { loop { // 无限循环,永远不会返回 } } // 方法二:调用panic! fn never_return_fn() -> ! { panic!("This function never returns!"); } // 方法三:使用std::process::exit use std::process; fn never_return_fn() -> ! { process::exit(1); // 退出程序并返回状态码1 }当所有权转移时,可变性也可以随之改变。
let x = 5; // 不可变变量 let mut y = x; // 所有权转移,y 变为可变 y += 1; // 修改 y 的值 部分移动
部分移动:
- 解构时可以同时移动变量的一部分,并借用另一部分。
- 被移动部分的所有权转移,原变量不能再使用该部分。
- 被借用部分仍然可以通过引用使用。
原变量状态:
- 整体不能再使用,因为部分所有权已转移。
- 未转移所有权的部分仍可通过引用使用。
fn main() { let t = (String::from("hello"), String::from("world")); let _s = t.0; // 仅修改下面这行代码,且不要使用 `_s` println!("{:?}", t.1); }Ref和&的区别
使用场景
&是直接引用,用于创建一个指向某个值的引用,适用于任何需要引用的地方。ref主要在模式匹配中使用,用于方便地在模式匹配过程中获取某个值的引用。
代码简洁性和可读性
- 使用
&创建引用时,代码逻辑清晰,直接指向某个值,易于理解。 - 使用
ref在模式匹配中创建引用,可以使模式匹配的代码更加简洁和直观,避免了在模式匹配外部手动创建引用的繁琐。
- 使用
当你在模式匹配中需要创建多个嵌套值的引用时,ref 可以大大简化代码的编写和阅读。例如:
struct Point { x: i32, y: i32, } let p = Point { x: 10, y: 20 }; match p { Point { ref x, ref y } => { // 在这里 x 和 y 都是引用 println!("x: {}, y: {}", x, y); } } 在这个例子中,使用 ref 可以直接在模式匹配中创建 x 和 y 的引用。如果不使用 ref,你需要手动创建引用,这样会使代码变得更复杂:
struct Point { x: i32, y: i32, } let p = Point { x: 10, y: 20 }; let Point { x, y } = p; let x_ref = &x; let y_ref = &y; println!("x: {}, y: {}", x_ref, y_ref); 借用规则
- 不可变引用与可变引用:Rust 不允许同时存在不可变引用和可变引用,以确保内存安全。
- 生命周期管理:在可变借用之前,必须完成所有对数据的不可变引用。
错误原因
- 调用
s.clear()时存在对s的不可变引用ch,违反借用规则。
修正代码
确保在修改原数据前处理完所有对数据的引用:
fn main() { let mut s = String::from("hello world"); // 获取第一个字符的不可变引用 let ch = first_character(&s); println!("the first character is: {}", ch); // 清空字符串,在使用完不可变引用之后 s.clear(); } fn first_character(s: &str) -> &str { &s[..1] } 字符串
进行切片时需要注意字符边界
UTF-8 编码的字符可能占用多个字节,切片操作必须在字符边界上进行,否则程序会崩溃。
核心要点:
- UTF-8 编码:字符可能占用1至4个字节,汉字通常占3个字节。
- 字符边界:切片索引必须对齐到字符边界。
- 避免崩溃:切片时需确保索引在字符边界,否则会导致程序崩溃。
- 使用工具:可以使用
.char_indices()方法获取字符边界,确保切片安全。
示例:
let s = "中国人"; let a = &s[0..3]; // 正确的切片,取第一个汉字 "中" println!("{}", a); // 输出 "中" String 与 &str 的转换
从 &str 到 String:
String::from("hello, world")"hello, world".to_string()
从 String 到 &str:
&s&s[..]s.as_str()
这背后的原理是 Rust 的 Deref 隐式强制转换。
不允许直接通过索引访问字符串中的字符
- 底层存储:Rust 字符串底层是字节数组
[u8]。 - UTF-8 编码:字符占用不同字节数,索引必须对齐字符边界。
- 多种表示方式:Rust 提供多种字符串表示方式,适合不同需求。
- 索引限制:为了安全和性能考虑,Rust 不允许直接索引字符串。
- 遍历字符串:使用
chars和bytes方法遍历字符串,确保正确处理字符和字节。
字符串转义与原样字符串
Rust 提供了多种方法来处理字符串中的转义字符和原样字符串。以下是详细说明及核心概括。
1. 转义字符
- ASCII 转义: 使用
\x后跟两个十六进制数来表示 ASCII 字符。 - Unicode 转义: 使用
\u后跟花括号中的 Unicode 码点来表示 Unicode 字符。
示例代码:
fn main() { // 通过 \ + 字符的十六进制表示,转义输出一个字符 let byte_escape = "I'm writing \x52\x75\x73\x74!"; println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape); // \u 可以输出一个 unicode 字符 let unicode_codepoint = "\u{211D}"; let character_name = "\"DOUBLE-STRUCK CAPITAL R\""; println!( "Unicode character {} (U+211D) is called {}", unicode_codepoint, character_name ); // 换行了也会保持之前的字符串格式 // 使用\忽略换行符 let long_string = "String literals can span multiple lines. The linebreak and indentation here ->\ <- can be escaped too!"; println!("{}", long_string); } 运行结果:
What are you doing? (\x3F means ?) I'm writing Rust! Unicode character ℝ (U+211D) is called "DOUBLE-STRUCK CAPITAL R" String literals can span multiple lines. The linebreak and indentation here -><- can be escaped too! 2. 原样字符串
- 原样字符串: 使用
r#和#包围字符串,忽略转义字符。 - 带有双引号的字符串: 使用多个
#包围字符串,以处理双引号和其他复杂情况。
示例代码:
fn main() { // 保持字符串的原样输出 println!("{}", "hello \\x52\\x75\\x73\\x74"); // 原样字符串 let raw_str = r"Escapes don't work here: \x3F \u{211D}"; println!("{}", raw_str); // 包含双引号的原样字符串 let quotes = r#"And then I said: "There is no escape!""#; println!("{}", quotes); // 使用多个 # 处理复杂情况 let longer_delimiter = r###"A string with "# in it. And even "##!"###; println!("{}", longer_delimiter); } 运行结果:
hello \x52\x75\x73\x74 Escapes don't work here: \x3F \u{211D} And then I said: "There is no escape!" A string with "# in it. And even "##! 操作 UTF-8 字符串
1. 遍历字符
如果你想以 Unicode 字符的方式遍历字符串,可以使用 chars 方法:
示例代码:
fn main() { for c in "中国人".chars() { println!("{}", c); } } 输出:
中 国 人 2. 遍历字节
如果你想查看字符串的底层字节数组,可以使用 bytes 方法:
示例代码:
fn main() { for b in "中国人".bytes() { println!("{}", b); } } 输出:
228 184 173 229 155 189 228 186 186 3. 获取子串
由于 UTF-8 字符串的变长特性,从中获取子串相对复杂。Rust 标准库无法直接支持按字符边界提取子串。需要使用第三方库(如 utf8_slice)来实现。
示例代码:
fn main() { let s = "holla中国人नमस्ते"; // 使用第三方库 utf8_slice 提取子串 let sub = utf8_slice::slice(s, 5, 8); println!("{}", sub); // 输出: 中国 } str和&str
字符串字面量类型:
- 字符串字面量的类型是
&str。
- 字符串字面量的类型是
str类型的使用:str类型表示字符串的不可变视图,通常无法直接使用。- 可以使用
&str来处理字符串的引用。
Box<str>和&str的转换:- 使用
Box将str类型存储在堆上,通过引用&将Box<str>转换为&str。
- 使用
数组和元组
元组过长错误
问题:Rust 默认只支持最多12个元素的元组,超过会导致编译错误。
解决方案:
- 使用数组:适用于元素类型相同的情况。
- 使用结构体:适用于元素类型不同的情况。
- 分解元组:将长元组分解成多个短元组。
非基础类型数组的所有权问题
基础类型与复杂类型区别:
- 基础类型(如
i32)支持Copy特性,可以通过[value; n]语法初始化。 - 复杂类型(如
String)不支持Copy特性,需要逐个创建元素。
- 基础类型(如
解决方法:使用
std::array::from_fn函数,通过闭包生成每个元素,避免所有权问题。
切片大小
- 切片:是对数组部分的引用,包含一个指针和长度。
- 64 位系统:指针和长度各占 8 字节,因此切片总大小为 16 字节。
错误示例修正
原代码错误是将切片大小误认为 8 字节。应将 assert! 中的值修改为 16。
修正代码
fn main() { let arr: [char; 3] = ['中', '国', '人']; let slice = &arr[..2]; // 修改数字 `8` 让代码工作 assert!(std::mem::size_of_val(&slice) == 16); } 结构体
结构体更新语法
- 结构体更新语法:允许基于现有结构体实例创建新实例,只需指定改变的字段,其余字段自动从现有实例中获取。
- 所有权转移:结构体更新语法会转移所有权,涉及
Copy特征的字段会被拷贝,不涉及Copy特征的字段会发生所有权转移。
示例代码
传统方式:
let user2 = User { active: user1.active, username: user1.username, email: String::from("another@example.com"), sign_in_count: user1.sign_in_count, }; 结构体更新语法:
let user2 = User { email: String::from("another@example.com"), ..user1 }; 所有权转移与 Copy 特征
Copy特征:bool和u64等实现了Copy特征的类型在赋值时会被拷贝,不会转移所有权。- 非
Copy类型:如String等在赋值时会转移所有权,导致原结构体实例中的对应字段不能再被使用。
例子
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { email: String::from("another@example.com"), ..user1 }; // 使用了 Copy 特征的字段可以继续使用 println!("{}", user1.active); // 依然有效 // 使用了所有权转移的字段将导致错误 // println!("{:?}", user1); // 错误:user1 的 username 字段所有权已被转移 } 结构体内存布局
struct File { name: String, data: Vec<u8>, }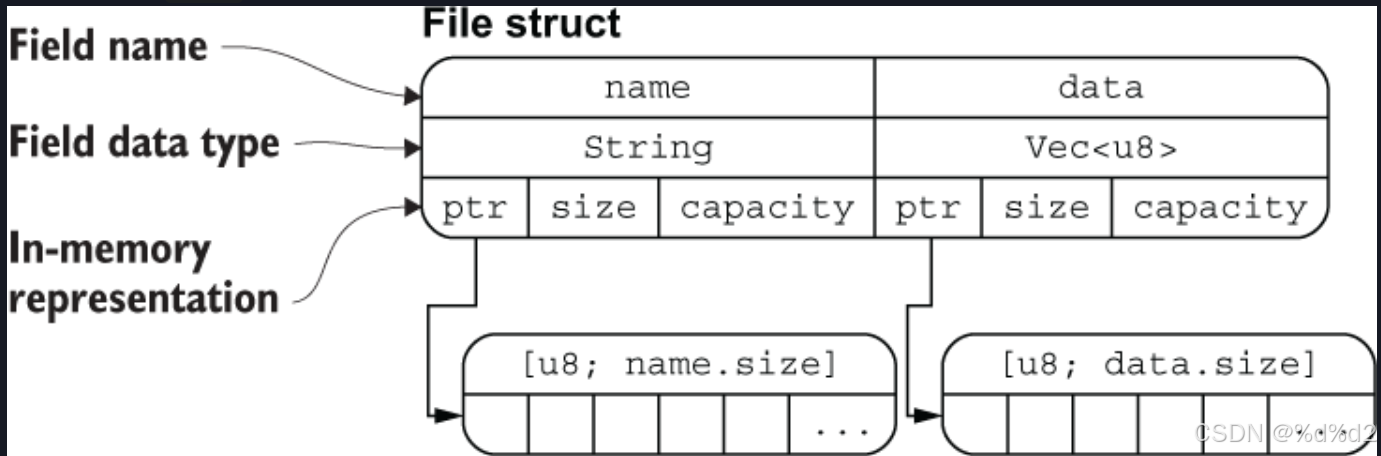
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
Rust 元组结构体
定义
- 语法:
示例:struct 结构体名(字段类型1, 字段类型2, ...);struct Color(i32, i32, i32); struct Point(i32, i32, i32);
使用场景
- 当需要一个整体名称,但不关心内部字段的名称时。
- 适用于明确且简单的字段组合,如 3D 坐标点 (x, y, z)。
#[derive(Debug)] 打印结构体
核心概念
#[derive(Debug)]注解: 使结构体或枚举自动实现Debug特征,从而能够使用调试格式进行打印。
实现步骤
为结构体派生
Debug特征:#[derive(Debug)] struct Rectangle { width: u32, height: u32, }调试打印:
- 使用
dbg!宏打印调试信息到标准错误输出stderr:let rect1 = Rectangle { width: dbg!(30 * scale), height: 50, }; dbg!(&rect1); - 使用
println!宏在标准输出stdout中打印调试信息:println!("{:?}", rect1);
- 使用
高级
函数式编程
捕获作用域中的值
- 闭包特性:闭包可以捕获并使用定义时作用域中的变量,而函数则不能。
- 使用场景:在需要访问定义时作用域内的变量时,闭包比函数更灵活。
- 编译器提示:Rust 编译器会友好地提示将函数替换为闭包,以便捕获动态环境中的值。
