阅读量:3
文章目录
from: https://www.youtube.com/watch?v=JbfcAaBT66U&list=PLJV_el3uVTsNi7PgekEUFsyVllAJXRsP-&index=5
简介:
84,841次观看 2023年3月25日 【機器學習 2023】(生成式 AI)
感謝黃敬峰先生提供字幕Stable Diffusion
https://arxiv.org/abs/2112.10752DALL-E series
https://arxiv.org/abs/2204.06125
https://arxiv.org/abs/2102.12092Imagen
https://arxiv.org/abs/2205.11487
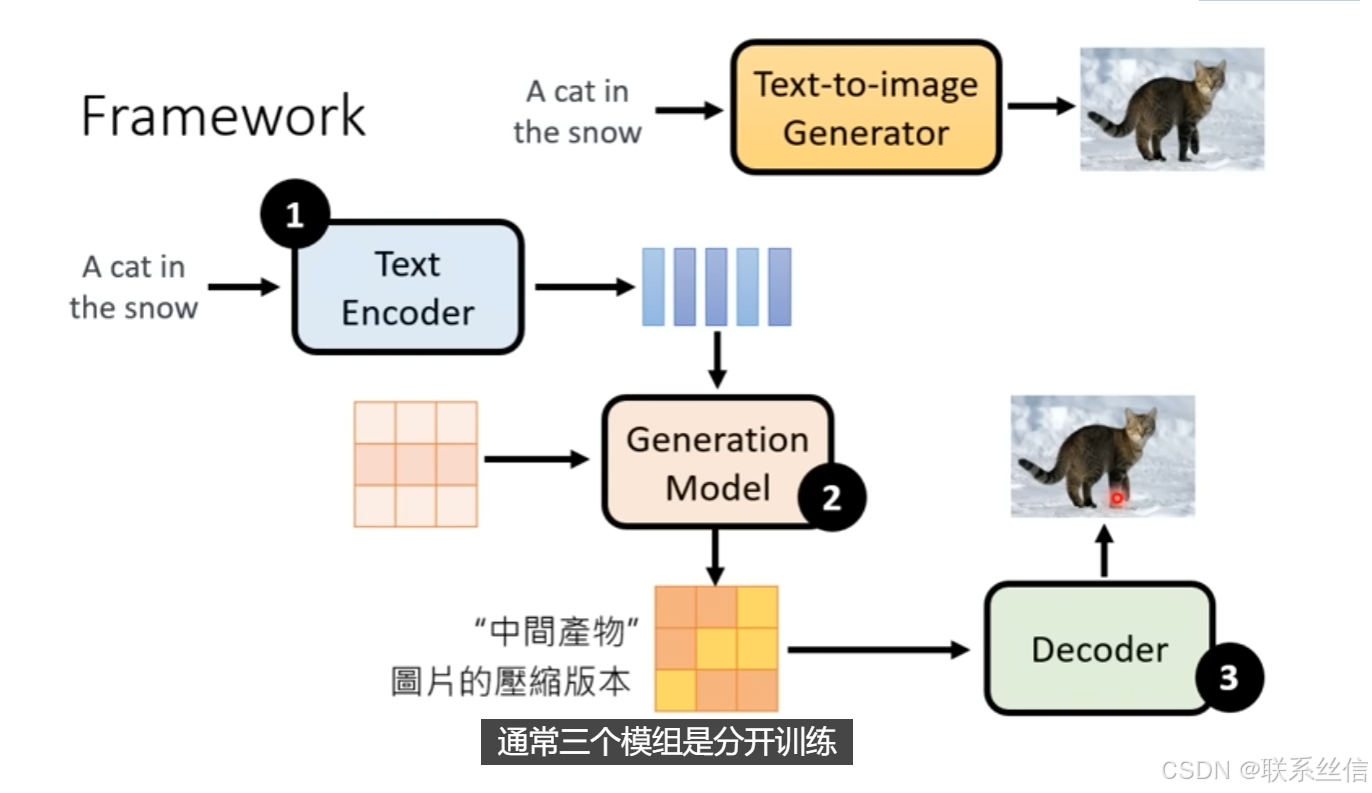
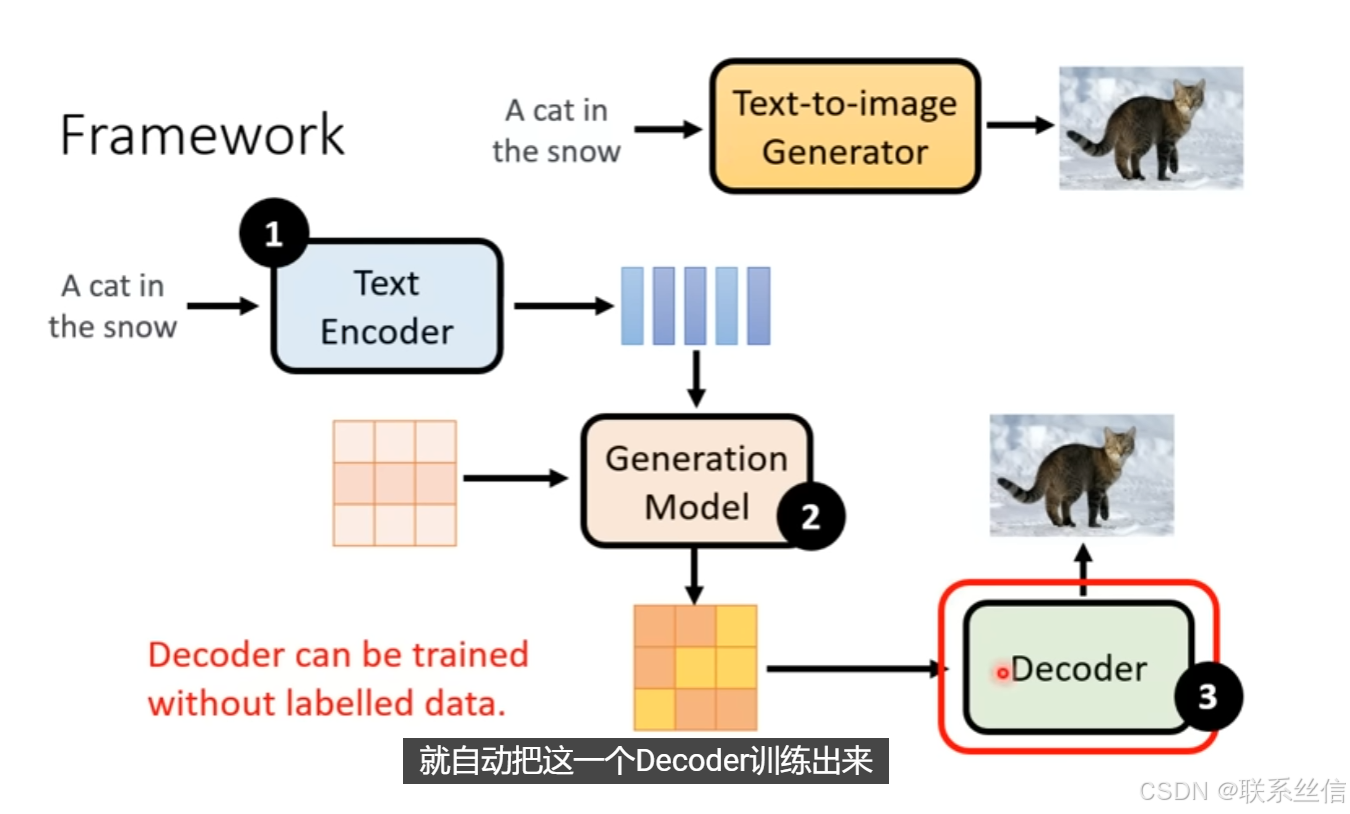
图片生成Framework 需要3个组件:
- Text Encoder
- Generation Model
- Decoder
相关论文【Stable Diffusion,DALL-E,Imagen】
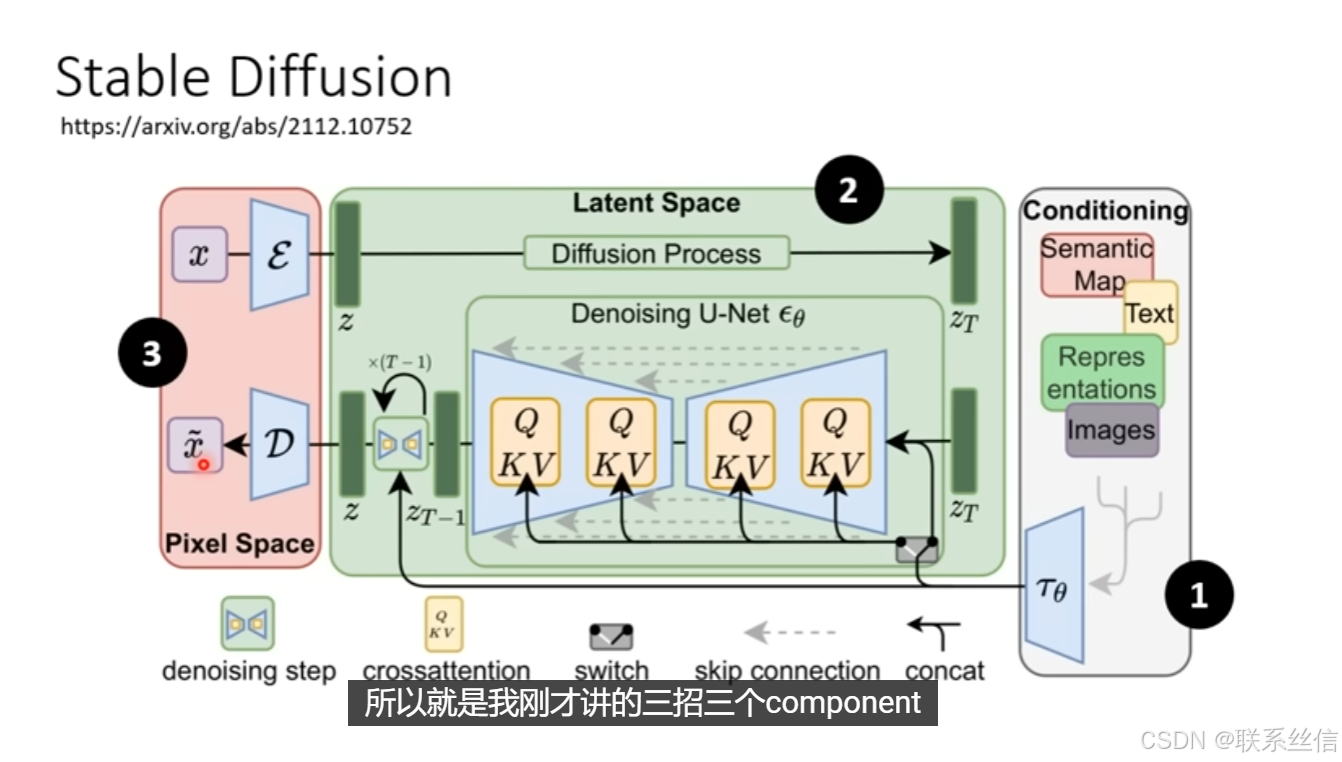
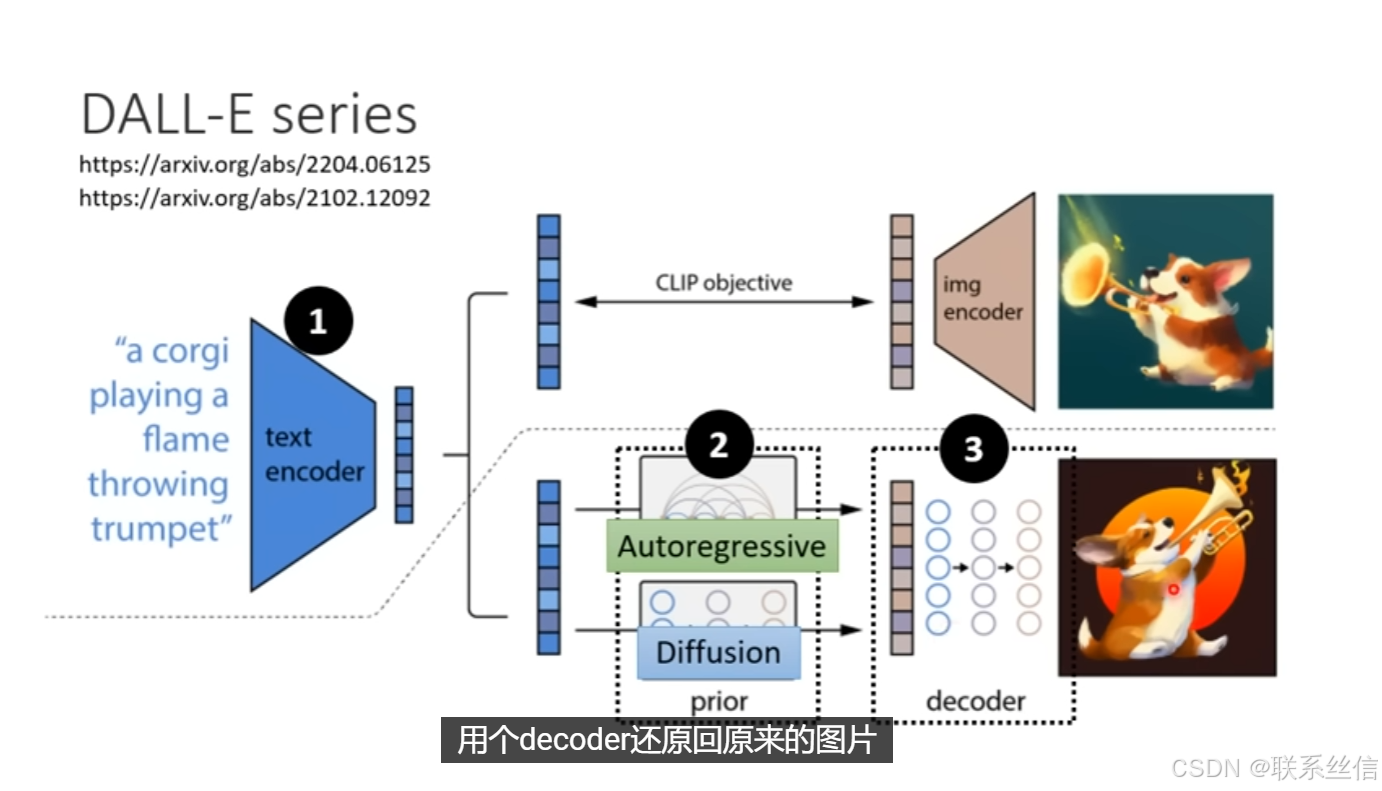
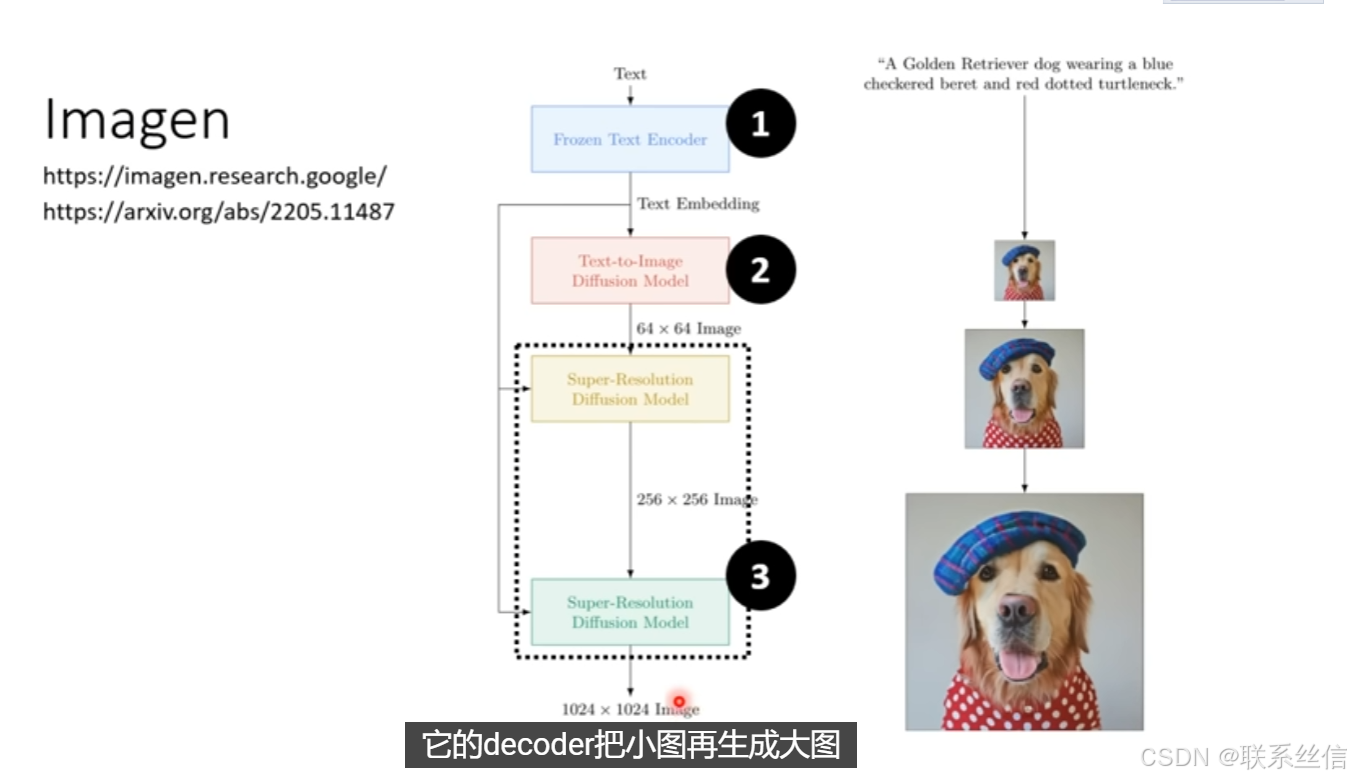
具体介绍三个组件
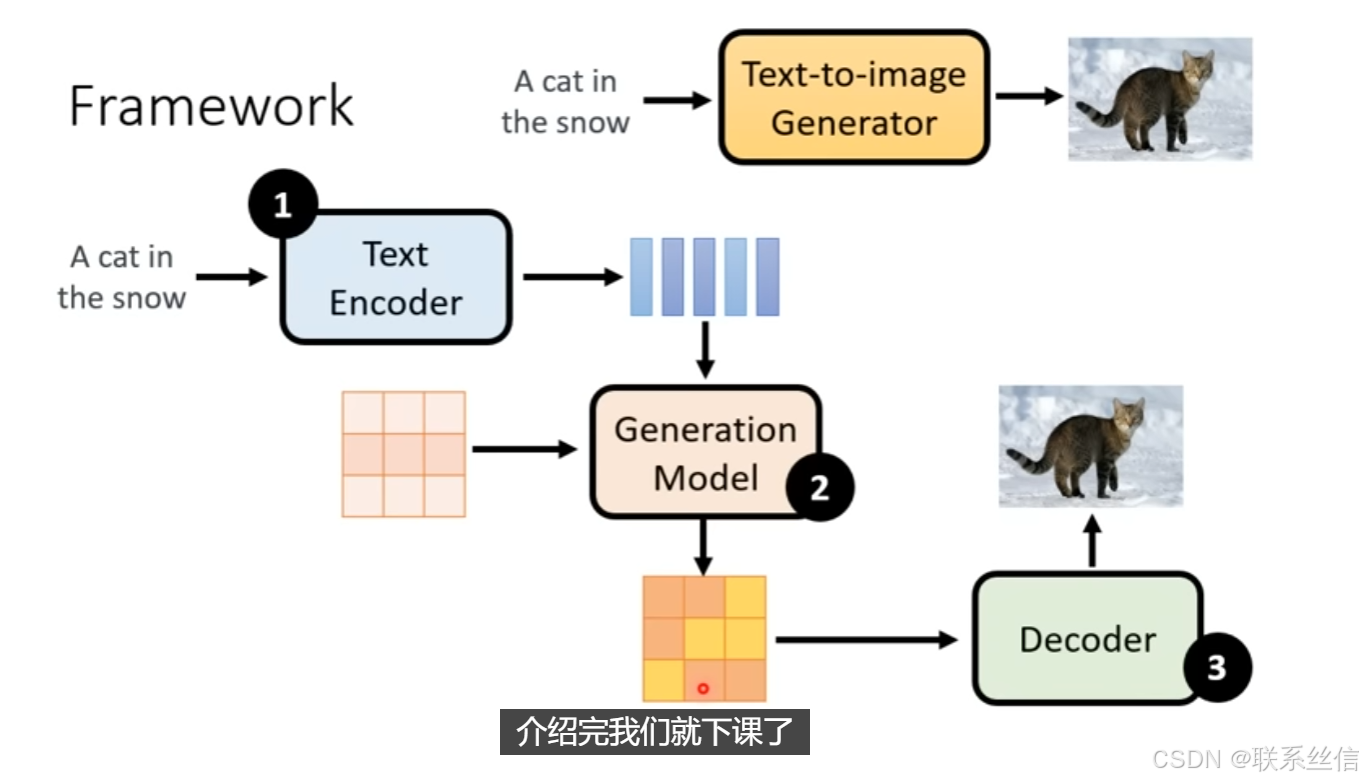
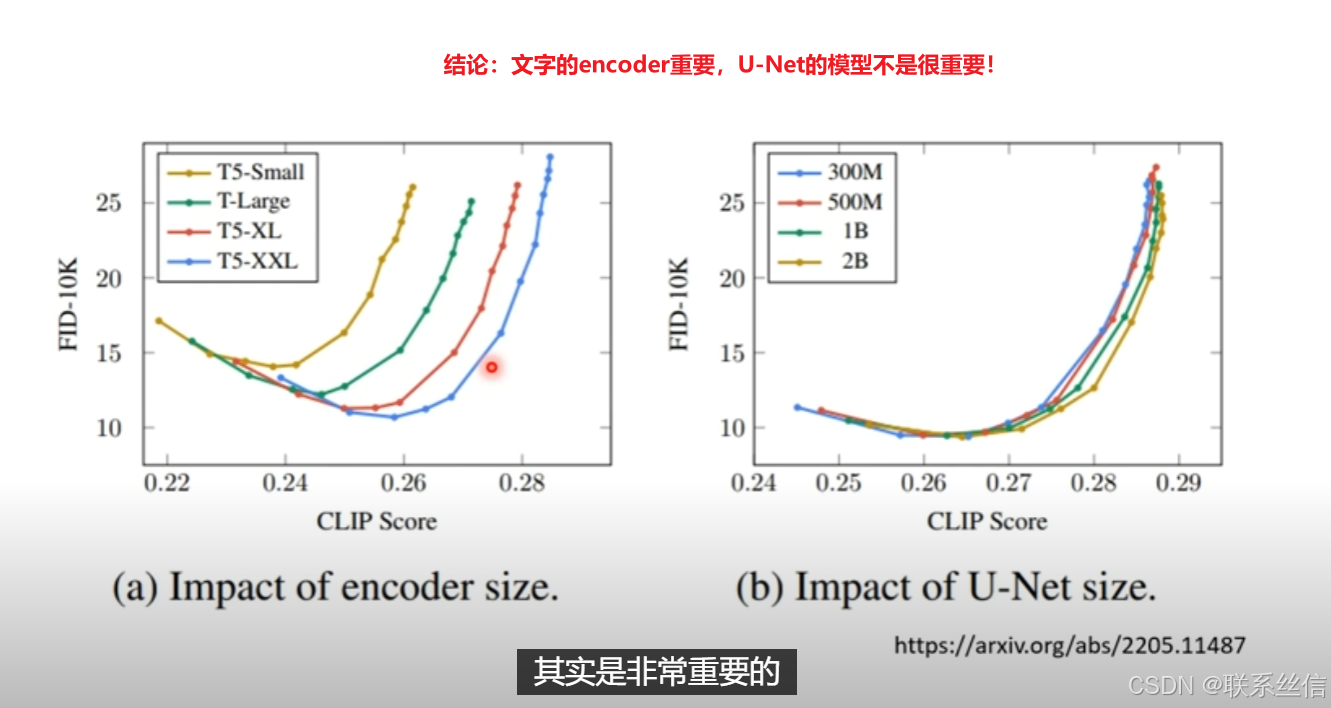
1. Text encoder介绍【结论:文字的encoder重要,Diffusion的模型不是很重要!】
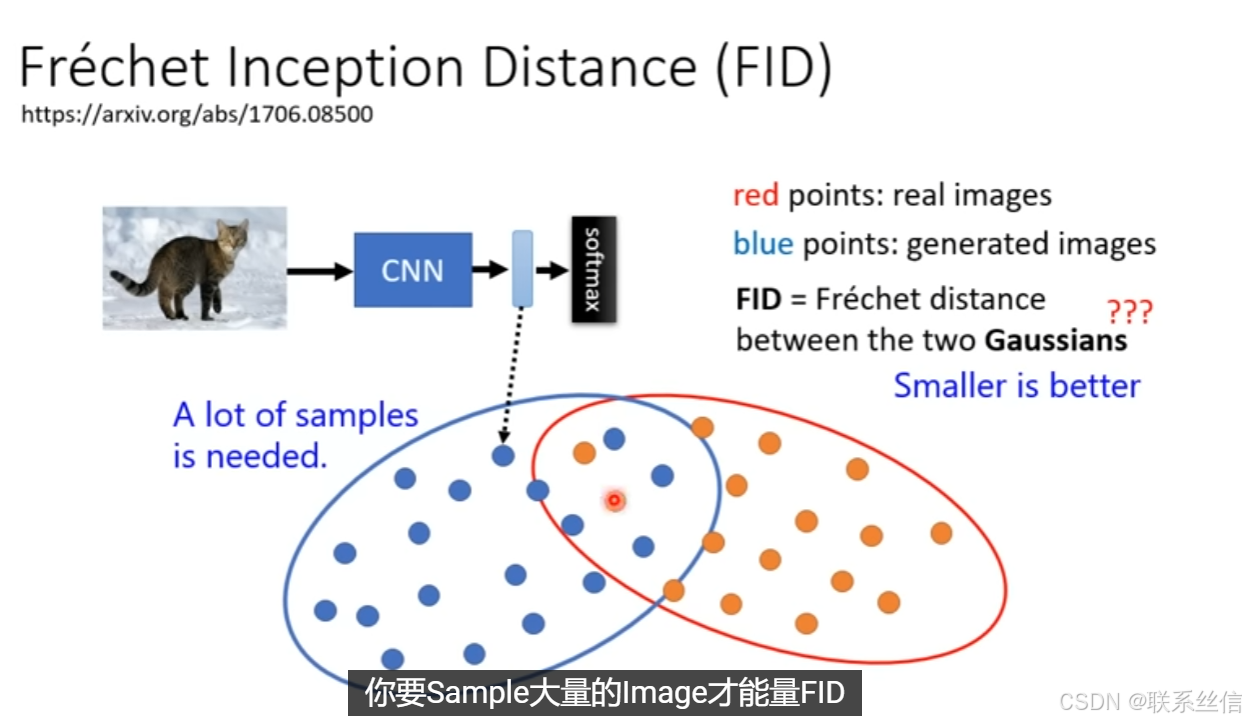
评估指标:FID计算
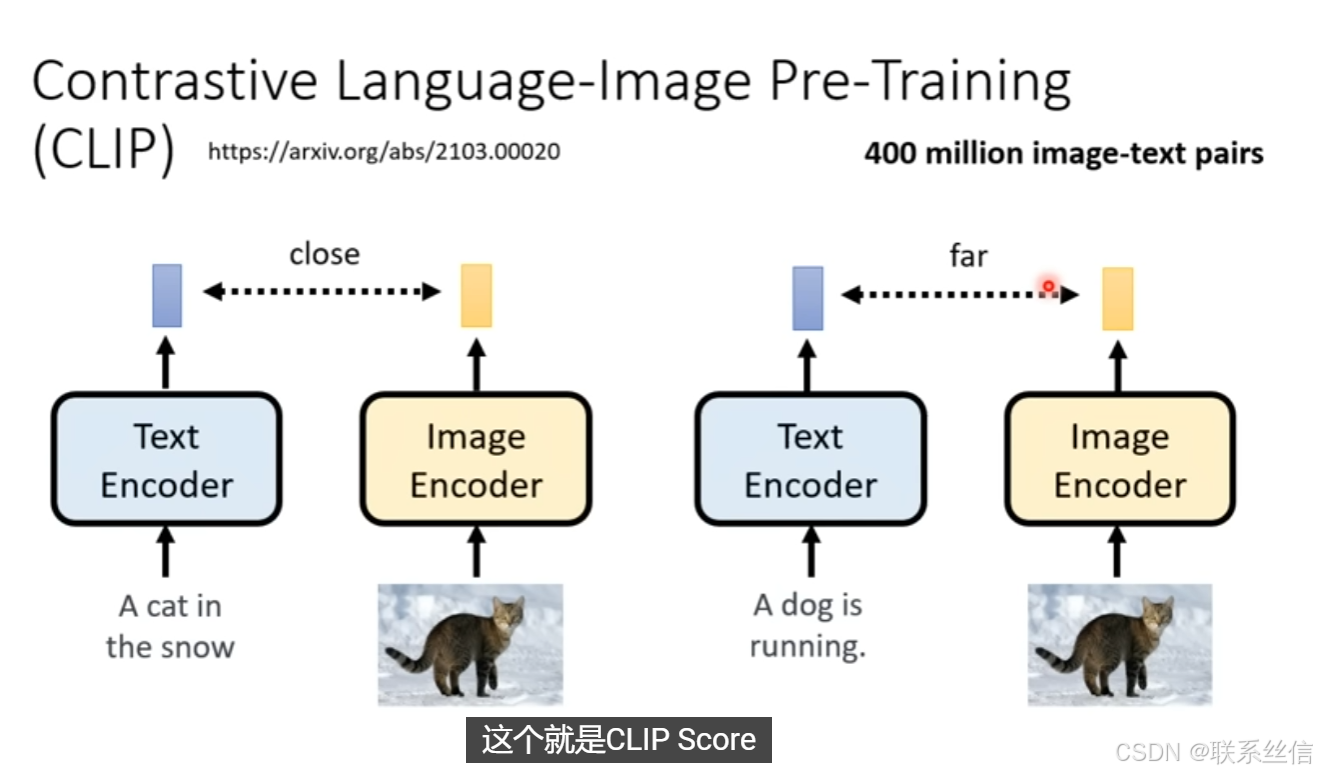
CLIP Score 计算
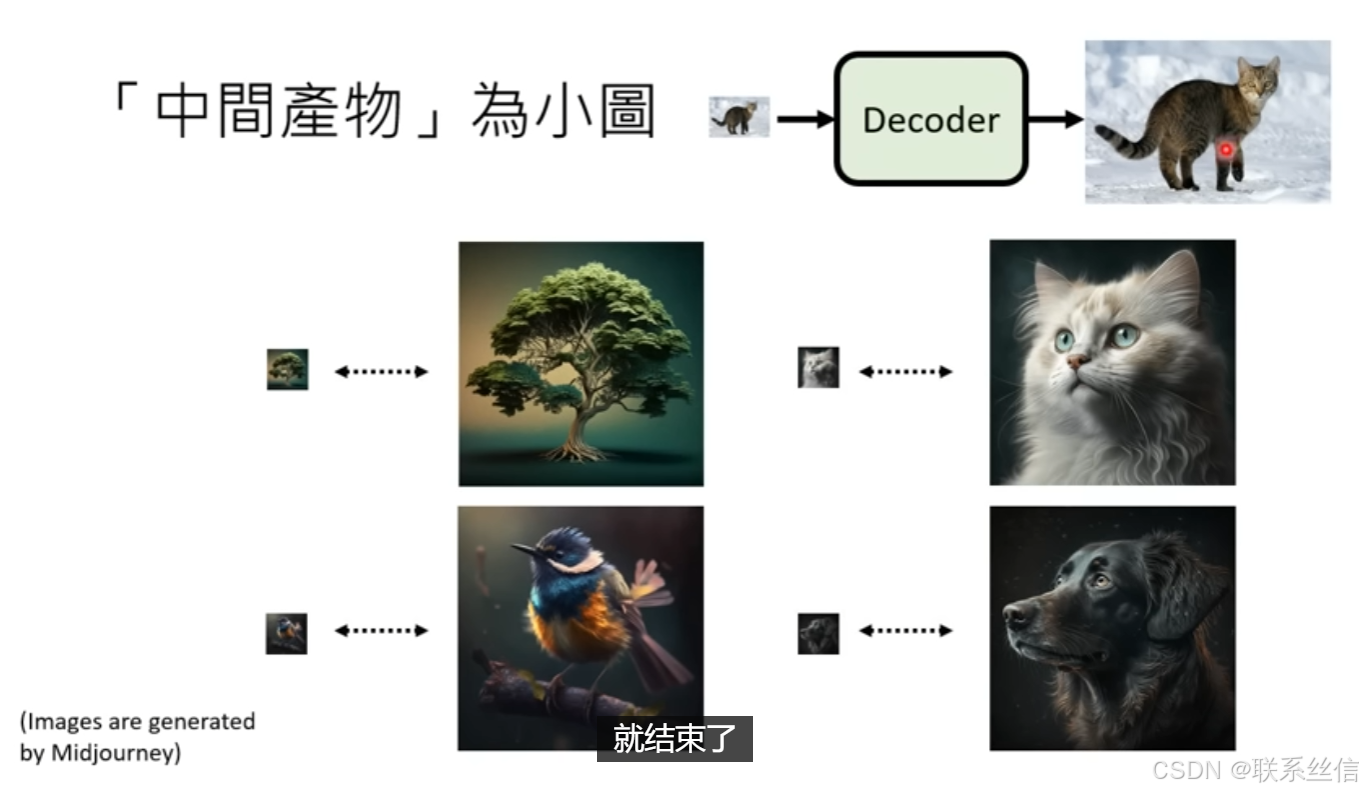
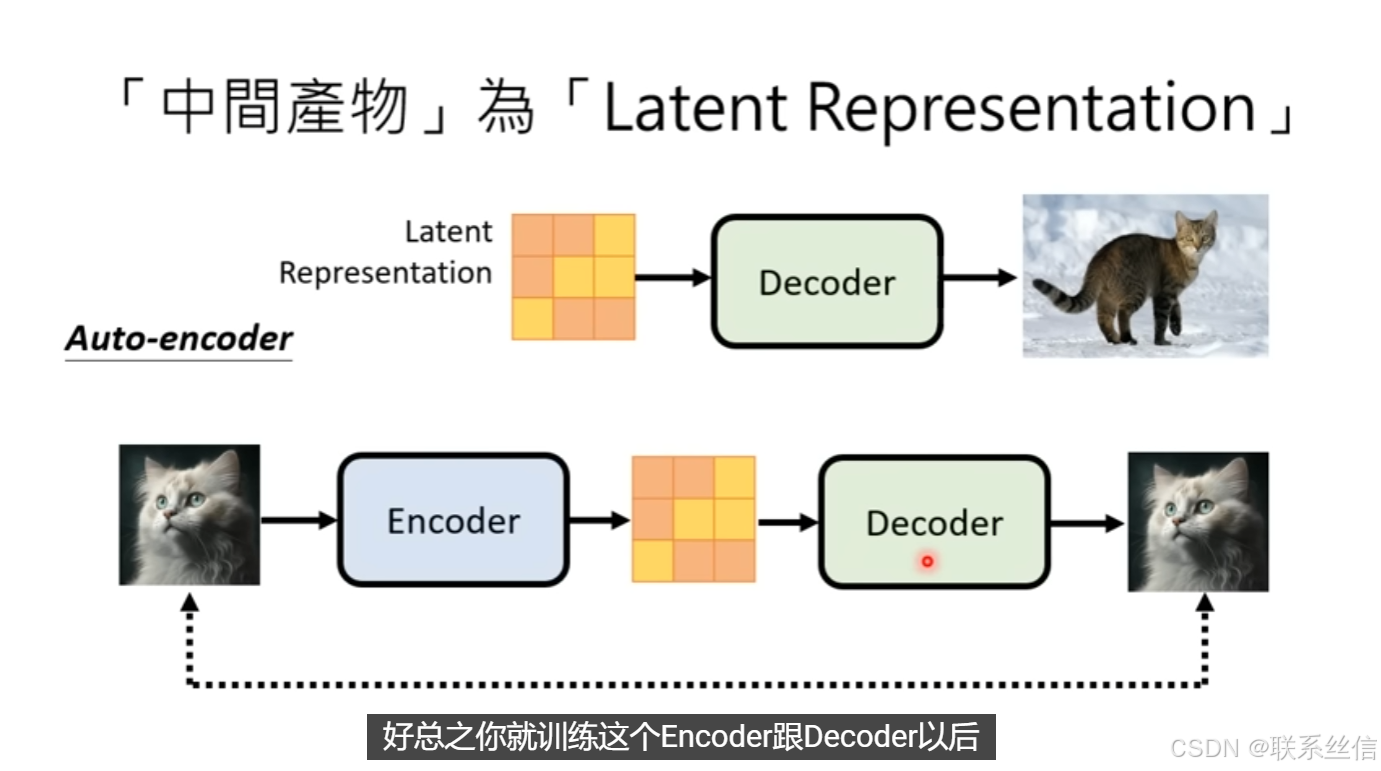
3. Decoder介绍【不需要成对的训练资料】
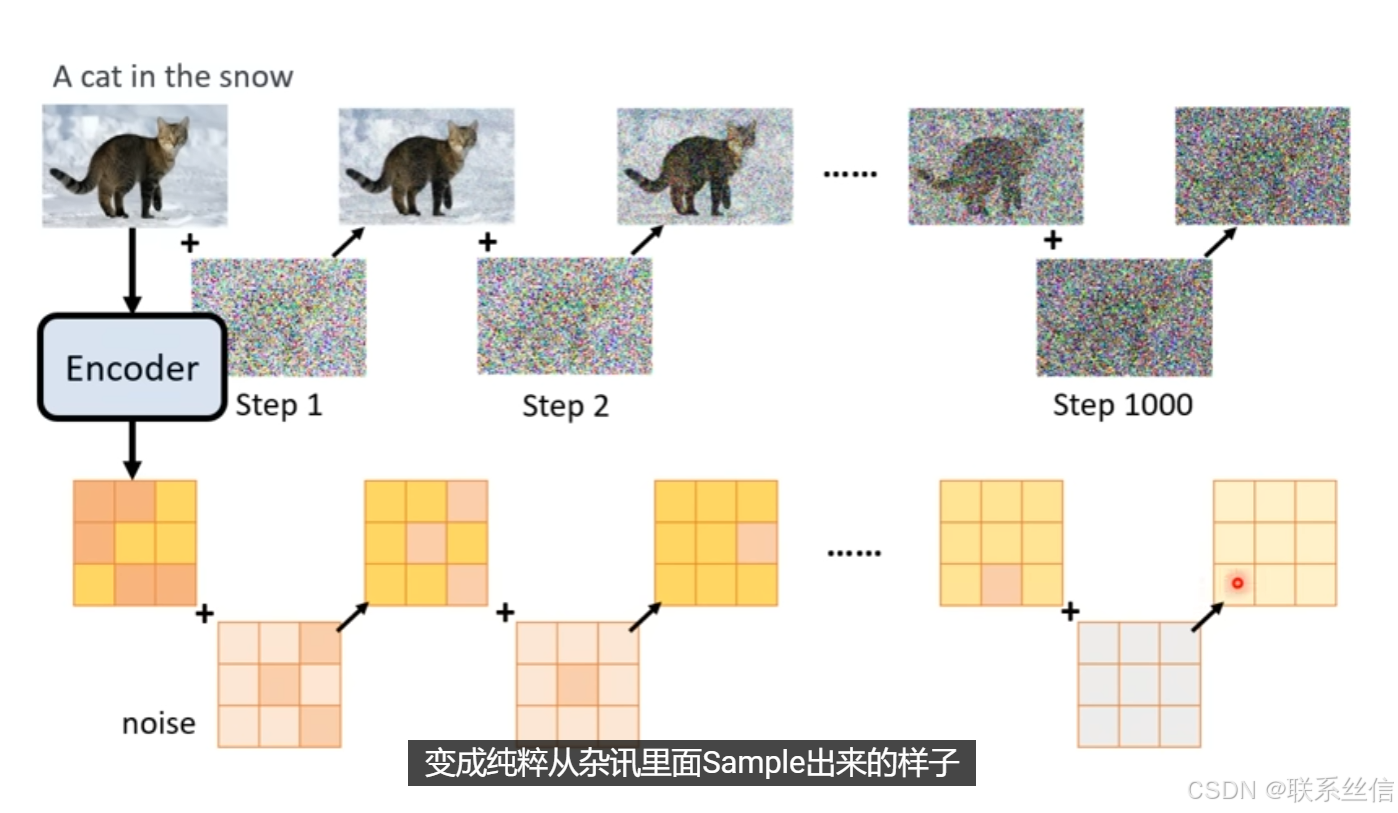
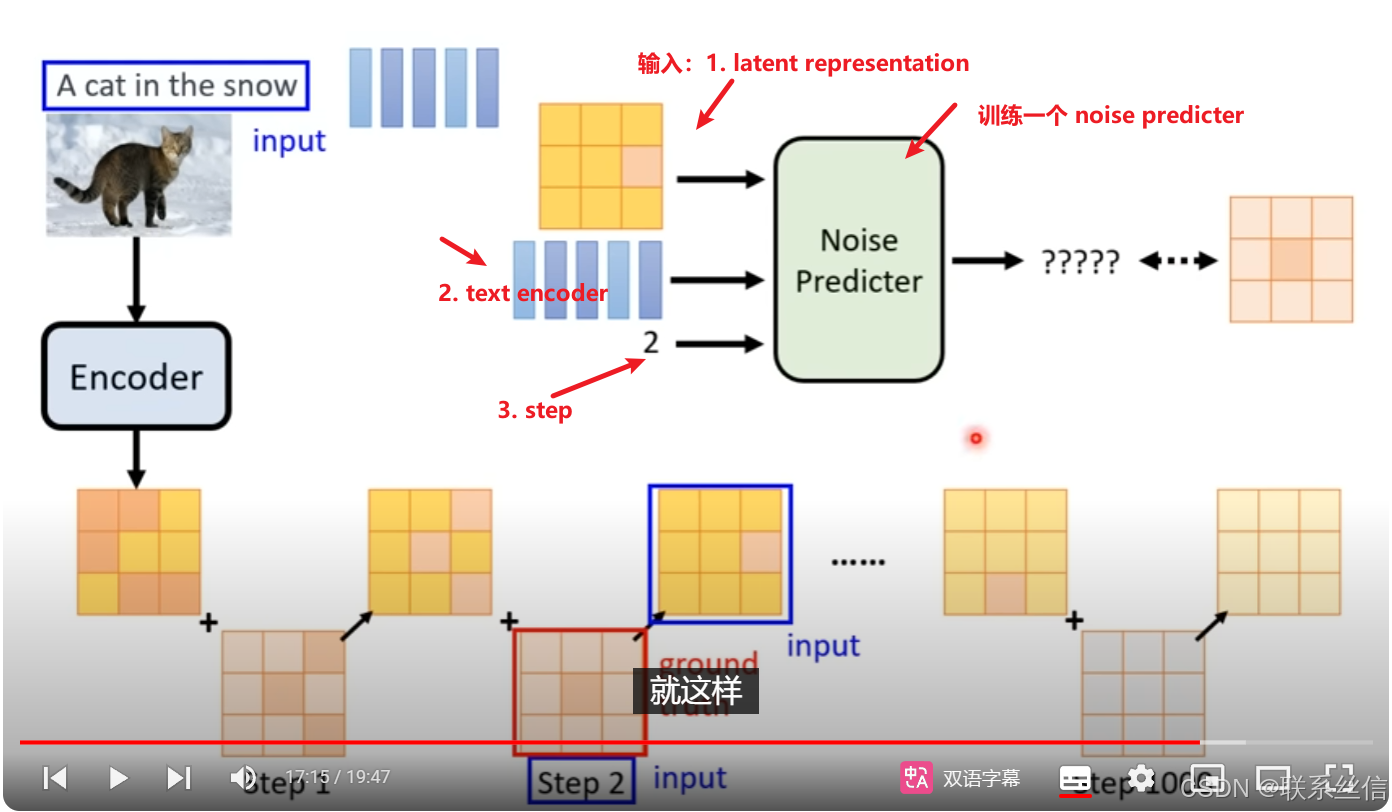
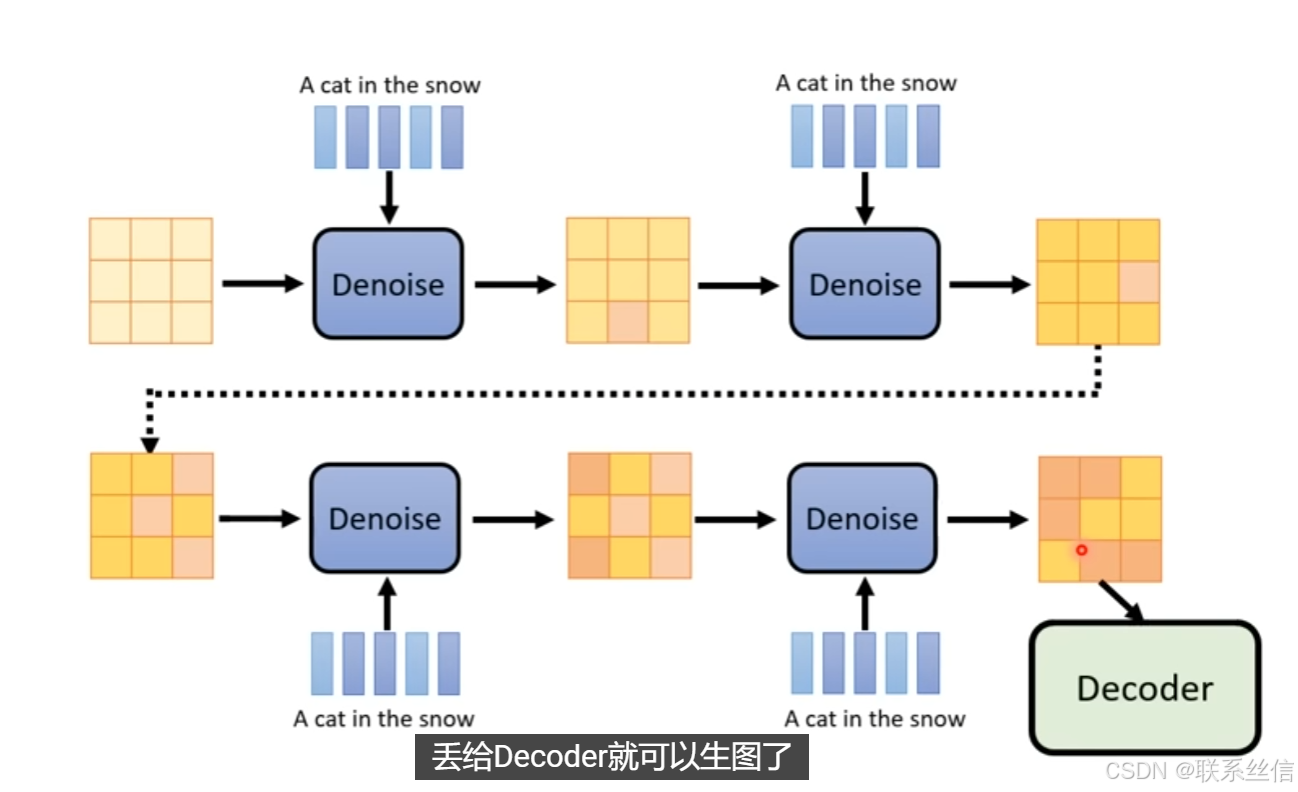
2. Diffusion Model介绍【训练一个noise predicter】
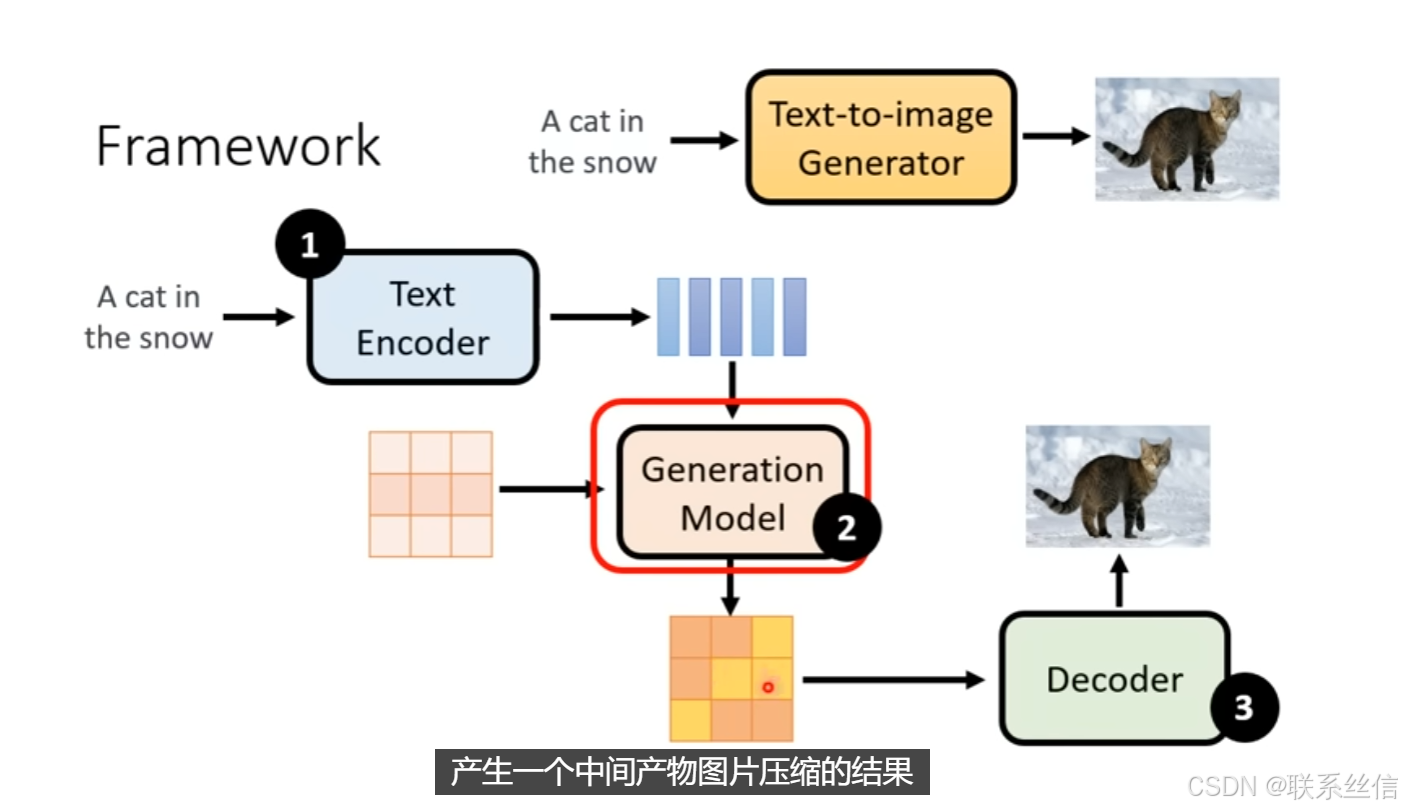
noise 加在 latent representation上