阅读量:1
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、算法项目落地经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
《大模型面试宝典》(2024版) 发布!
彻底火了!《AIGC 面试宝典》圈粉无数!
随着大型语言模型和多模态对齐技术的发展,视频理解模型在一般开放领域也取得了显著进展。
然而,大多数当前的视频理解模型使用帧平均和视频标记压缩方法,导致时间信息的丢失,无法准确回答与时间相关的问题。
另一方面,一些专注于时间问答数据集的模型过于局限于特定格式和适用领域,使得模型失去了更广泛的问答能力。
我们提出了一种基于视觉模型的自动时间定位数据构建方法,生成了3万条与时间相关的视频问答数据。然后,基于这个新数据集和现有的开放领域问答数据,我们引入了多帧视频图像和时间戳作为编码器输入,训练了一种新的视频理解模型—CogVLM2-Video。
CogVLM2-Video 不仅在公共视频理解基准上达到了最新的性能,还在视频字幕生成和时间定位方面表现出色,为视频生成和视频摘要等后续任务提供了强有力的工具。
代码:https://github.com/THUDM/CogVLM2
项目网站:https://cogvlm2-video.github.io
在线试用:http://36.103.203.44:7868/
模型介绍
目前,视频理解的主流方法涉及使用图像编码器从视频中提取帧,对其进行编码,然后设计编码压缩模块(如时间池化或Q-Former模块)来压缩视频编码信息,再将其输入大型语言模型(LLM)以便与文本输入进行联合理解。
尽管这种方法有效地压缩了视频信息,但它使模型失去了时间感知能力,无法准确地将视频帧与精确的时间戳关联起来。因此,模型缺乏时间定位、时间戳检测和总结关键时刻的能力。
为了解决这些问题,我们提出了CogVLM2-Video,这是基于CogVLM2图像理解模型的扩展视频模型。该模型不仅在开放域问答中实现了最先进的性能,还能感知视频中的时间戳信息,从而实现时间定位和相关问答。
具体来说,我们从输入视频片段中提取帧,并为其注释时间戳信息,使后续的语言模型能够准确知道每一帧在原视频中对应的确切时间。
图1展示了CogVLM2-Video的模型结构。
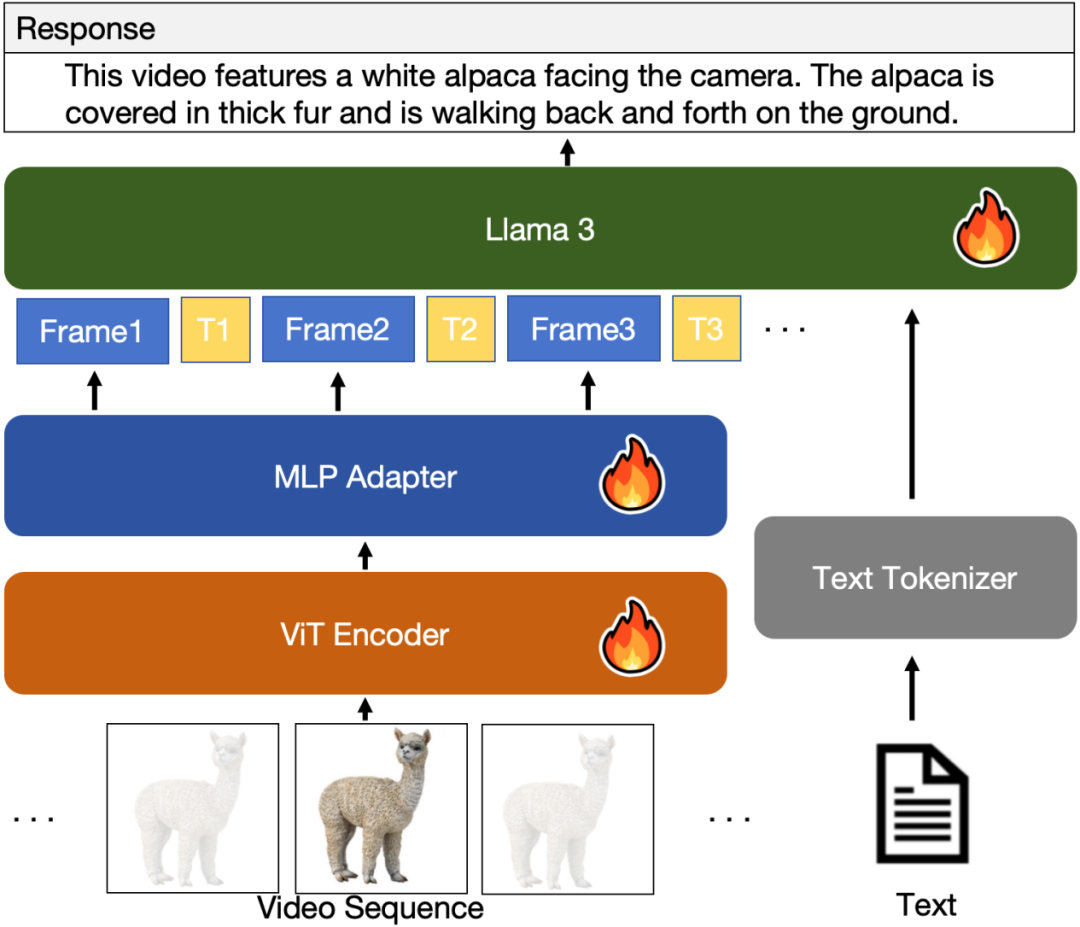
图1 CogVLM2-Video模型结构
数据集
此外,使用现有的时间定位标注数据训练的视频理解模型受到数据范围和问答固定格式的限制,缺乏开放域问答和处理能力。相比于用于训练LLM的纯文本数据和用于训练VLM的图像理解数据,高质量视频问答和时间定位数据的标注成本极高。仅靠手工标注无法满足大规模训练的需求。
为了准备适合大规模训练的时间定位数据,我们开发了一个完全自动化的视频问答数据生成过程。我们利用最新的图像理解模型从视频数据中提取帧级理解,然后使用大型语言模型进行数据过滤和生成。通过这种自动化数据处理工作流和大规模训练,CogVLM2-Video不仅在公共基准上表现出色,还具备了大多数以往视频模型所缺乏的时间敏感问答能力。
通过图2展示的构造流程,我们最终构造了3万条Temporal Grounding Question and Answer (TQA)数据。
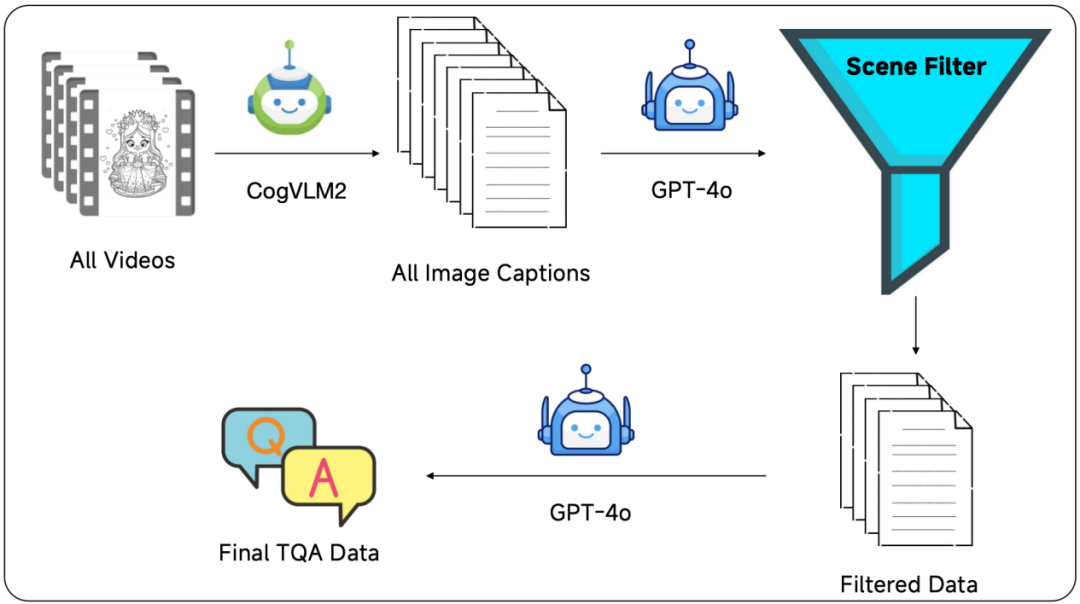
图2 TQA数据构造流程
评测
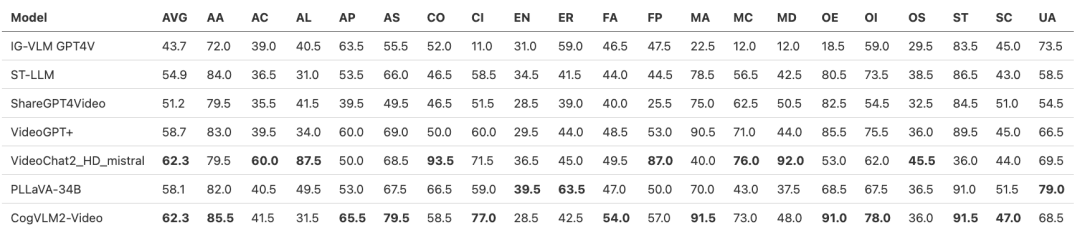
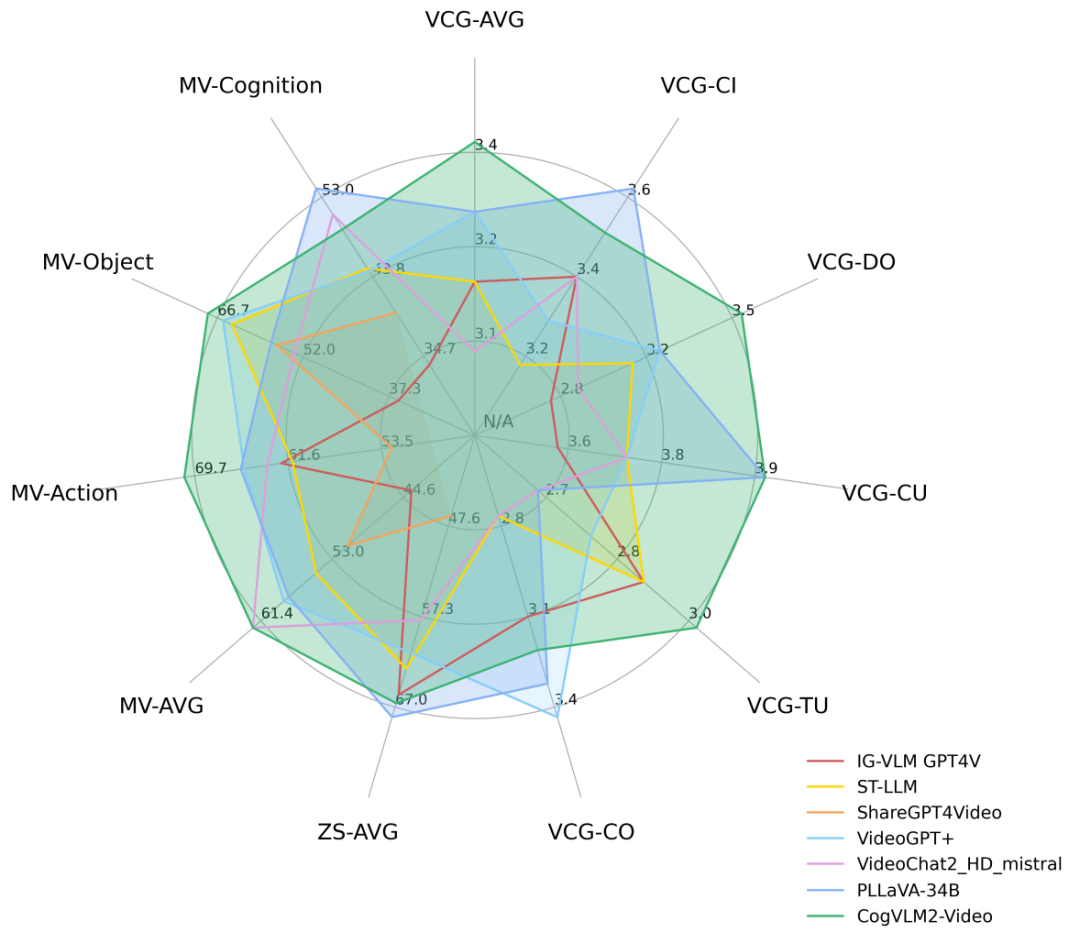
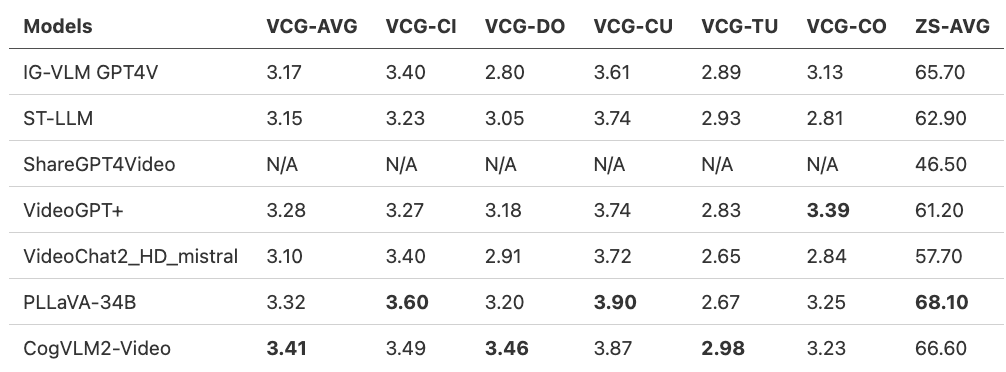
CogVLM2-Video在多个公开评测集上达到最好的性能,下面是一些评测结果。
- 量化评估指标(VideoChatGPT-Bench + Zero-shot QA)
- 量化评估指标(MVBench)