
阅读量:2
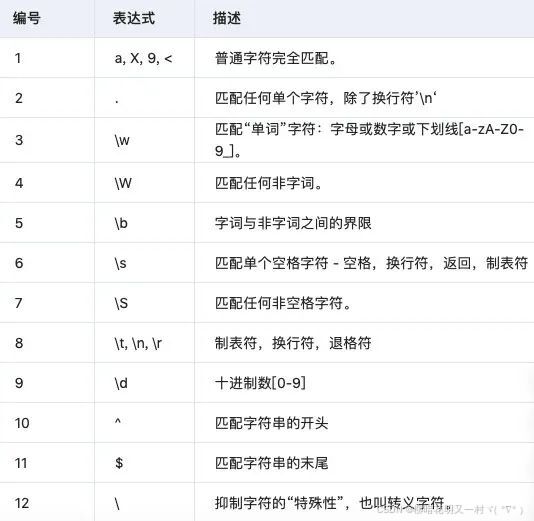
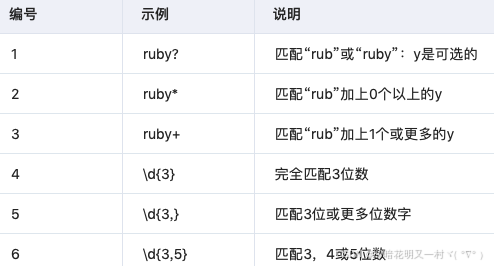
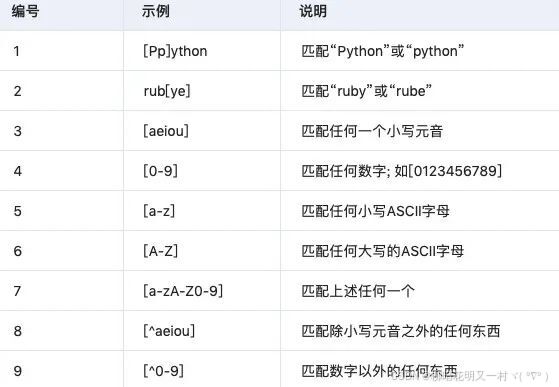

>>>input = '自然语言处理很重要, 123abc456' >>>import re >>>pattern = re.compile('.') >>>re.findall(pattern,input) ['自', '然', '语', '言', '处', '理', '很', '重', '要', ',', ' ', '1', '2', '3', 'a', 'b', 'c', '4', '5', '6'] >>>pattern = re.compile(r'[abc]') >>>re.findall(pattern,input) ['a', 'b', 'c'] >>>pattern = re.compile(r'[a-zA-Z]') >>>re.findall(pattern,input) ['a', 'b', 'c'] >>>pattern = re.compile(r'[^abc]') >>>re.findall(pattern,input) ['自', '然', '语', '言', '处', '理', '很', '重', '要', ',', ' ', '1', '2', '3', '4', '5', '6'] >>>pattern = re.compile(r'[abc]|[0-9]') >>>re.findall(pattern,input) ['1', '2', '3', 'a', 'b', 'c', '4', '5', '6'] >>>pattern = re.compile(r'\d') >>>re.findall(pattern,input) ['1', '2', '3', '4', '5', '6'] >>>pattern = re.compile(r'\D') >>>re.findall(pattern,input) ['自', '然', '语', '言', '处', '理', '很', '重', '要', ',', ' ', 'a', 'b', 'c'] >>>pattern = re.compile(r'\w') >>>re.findall(pattern,input) ['自', '然', '语', '言', '处', '理', '很', '重', '要', '1', '2', '3', 'a', 'b', 'c', '4', '5', '6'] >>>pattern = re.compile(r'\W') >>>re.findall(pattern,input) [',', ' '] >>>pattern = re.compile(r'\d{3}') >>>re.findall(pattern,input) ['123', '456'] >>>pattern = re.compile(r'\d{2}') >>>re.findall(pattern,input) ['12', '45'] >>>pattern = re.compile(r'\d{2,3}') >>>re.findall(pattern,input) ['123', '456'] match与search
match从字符串开头匹配,如果开头位置没有匹配成功就算失败;而search会跳过开头,继续向后寻找是否有匹配的字符串。
>>>input2 = '123自然语言处理66' >>>pattern = re.compile(r'\d') >>>match =re.search(pattern,input2) >>>match.group() '1' >>>pattern = re.compile(r'\d{3}') >>>match =re.search(pattern,input2) >>>match.group() '123' 字符串的替换与修改
sub(rule,replace,target[,count])
subn(rule,replace,target[,count])
count匹配次数
sub返回一个被替换的字符串
subn返回一个元组
>>>input2 = '123自然语言处理66' >>>pattern = re.compile(r'\d') >>>re.sub(pattern,'数字',input2) '数字数字数字自然语言处理数字数字' >>>pattern = re.compile(r'\d{2,3}') >>>re.sub(pattern,'数字',input2) '数字自然语言处理数字' >>>re.sub(pattern,'数字',input2,1) '数字自然语言处理66' >>>re.subn(pattern,'数字',input2,1) ('数字自然语言处理66', 1) >>>re.subn(pattern,'数字',input2) ('数字自然语言处理数字', 2) **split切片函数,**使用指定的正则规则在目标字符串中查找匹配的字符串,用他们作为分界,返回一个被切完的字符串列表
>>>input3 = '自然语言123自然语言23自然语言65' >>>pattern = re.compile(r'\d+') >>>re.split(pattern,input3) ['自然语言', '自然语言', '自然语言', ''] ‘(?P<…>)’命名组
>>>input3 = '自然语言123自然语言23自然语言65' >>>pattern = re.compile(r'(?P<data>\d+)(?P<cont>\D+)') >>>re.search(pattern,input3) >>>re.Match object; span=(4, 11), match='123自然语言'> >>>gr = re.search(pattern,input3) >>>gr.groups() ('123', '自然语言') >>>gr.group('data') '123' 中文匹配 [\u4e00-\u9fff]
>>>text = '这是一段包含english和中文的文本' >>>pattern = re.compile(r'[\u4e00-\u9fff]+') >>>pattern.findall(text) ['这是一段包含', '和中文的文本'] 