阅读量:2
论文阅读【时空+大模型】ST-LLM(MDM2024)
论文链接:Spatial-Temporal Large Language Model for Traffic Prediction
代码仓库:https://github.com/ChenxiLiu-HNU/ST-LLM
发表于MDM2024(Mobile Data Management)
本文主要面向交通流量数据。
符号定义
| 符号 | 含义 |
|---|---|
| N | 交通站点数 |
| C | 特征数量 |
| P | 历史序列长度 |
| S | 预测序列长度 |
Spatial-Temporal Embedding and Fusion
注: X P ∈ R P ∗ N ∗ C X_P \isin R^{P*N*C} XP∈RP∗N∗C,但在本文实验中C=1(原文“C = 1 represents the traffic pick-up or drop-off flow”),因而有 X P ∈ R P ∗ N X_P \isin R^{P*N} XP∈RP∗N
一般而言,spatial-temporal embedding分为:
- Token Embedding: E P = P o i n t w i s e C o n v ( X P ) ∈ R N ∗ D E_P = PointwiseConv(X_P) \isin R^{N * D} EP=PointwiseConv(XP)∈RN∗D
- Temporal Embedding: E T = E T d + E T w = W d a y ( X d a y ) + W w e e k ( X w e e k ) ∈ R N ∗ D E_T = E_T^d+E_T^w = W_{day}(X_{day}) + W_{week}(X_{week})\isin R^{N *D} ET=ETd+ETw=Wday(Xday)+Wweek(Xweek)∈RN∗D
- Spatial Embedding: E S = σ ( W S ∗ X P + b S ) ∈ R N ∗ D E_S = \sigma (W_S * X_P + b_S) \isin R^{N * D} ES=σ(WS∗XP+bS)∈RN∗D
然后将三种embedding合并:
H F = F u s i o n C o n v ( E P ∣ ∣ E S ∣ ∣ E T ) ∈ R N ∗ 3 D H_F = FusionConv(E_P||E_S||E_T) \isin R^{N*3D} HF=FusionConv(EP∣∣ES∣∣ET)∈RN∗3D
其中’||'是拼接符号。
Partially Frozen Attention (PFA) LLM
这部分使用GPT2捕获时空依赖。Transformer Block中训练时空开销最大的是注意力(Attention)模块。本文使用了F+U个Transformer层:
- 在前F层中,Attention参数冷冻,只训练Layer Norm
- 在后U层中,Attention参数也用于训练
经过F+U个Transformer层后,得到的 H F + U H^{F+U} HF+U后,使用一个Regression Conv获得最终结果:
Y S = R e g r e s s i o n C o n v ( H F + U ) ∈ R S ∗ N . Y_S = RegressionConv(H^{F+U}) \isin R^{S*N}. YS=RegressionConv(HF+U)∈RS∗N.
实验
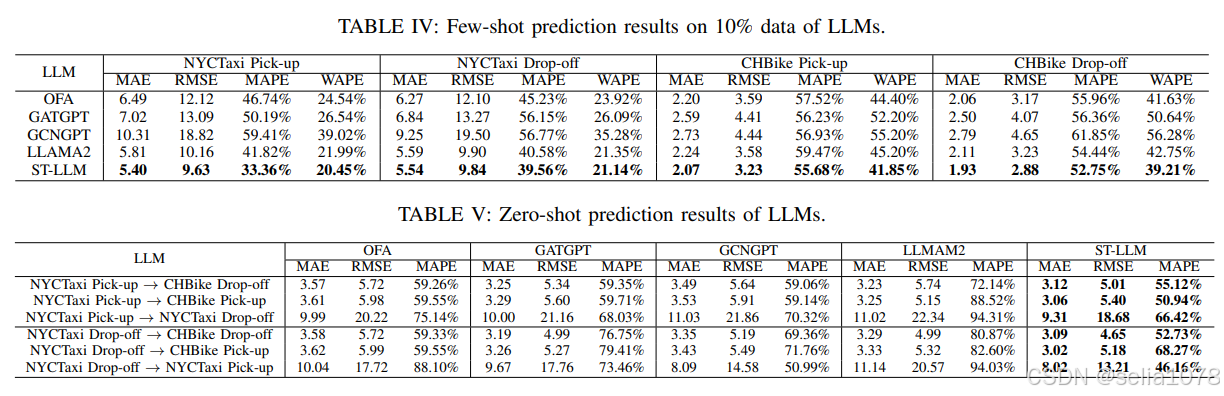
交通预测
从这个实验结果来看,看起来很多后来的方法都比不上DCRNN???
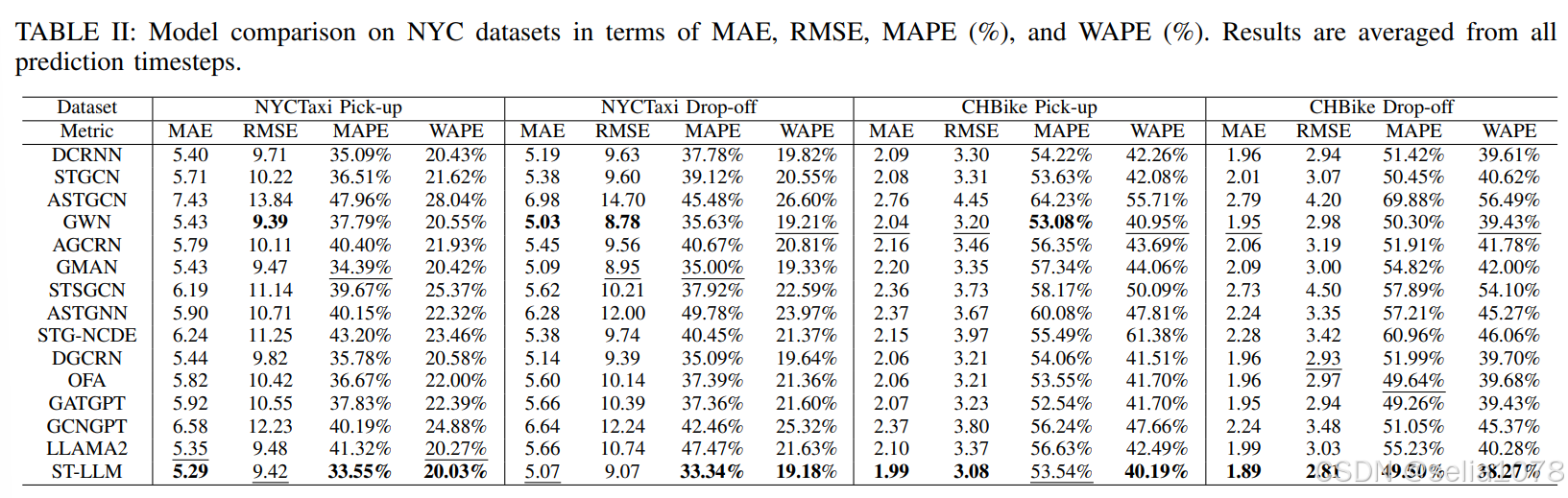
效率
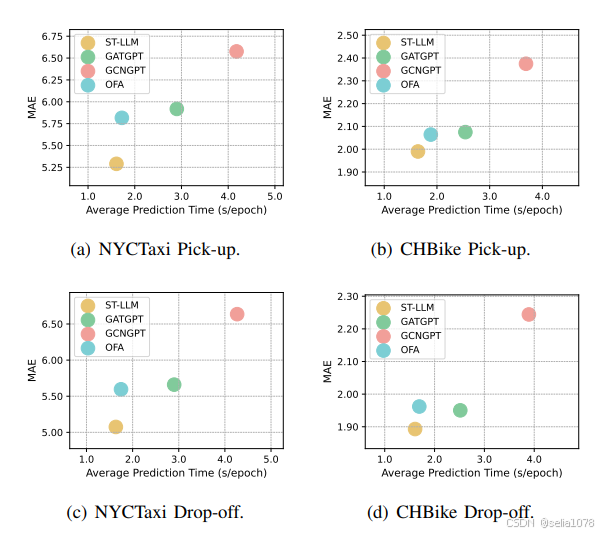
小样本/零样本(大模型必备)