
阅读量:1

------->更多内容,请移步“鲁班秘笈”!!<------
大型预训练语言模型的规模不断扩大,在许多自然语言处理 (NLP) 基准测试中取得了最先进的结果。自GPT和BERT开发以来,标准做法一直是在下游任务上微调模型,这涉及调整网络中的每个权重(即模型调优)。但是,随着模型变得越来越大,为每个下游任务存储和提供模型的优化副本变得不切实际。
一个有吸引力的替代方案是在所有下游任务中共享一个冻结的预训练语言模型,其中所有权重都是固定的。冻结模型可以通过“上下文”学习来执行不同的任务。通过这种方法,用户通过提示设计为给定任务启动模型,即手工制作带有手头任务描述或示例的文本提示。例如,为了给模型进行情感分析,可以在输入序列之前附加提示“下面的电影评论是正面的还是负面的?”,“这部电影太棒了!”。
在任务之间共享相同的冻结模型大大简化了服务,并允许高效的混合任务推理,但不幸的是,文本提示需要手动设计,即使是精心设计的提示,也会影响精确性,而本文带来的技术将破解手动的难题。

微调与转移学习
Prompt Tuning是通过训练一组提示参数来适应LLMs新任务的过程。这些提示被附加到输入文本之前,以指导生成LLM所需的输出。它在每个样本之前加入了一些虚拟的Token,这些Token用于不同任务的Embedding。
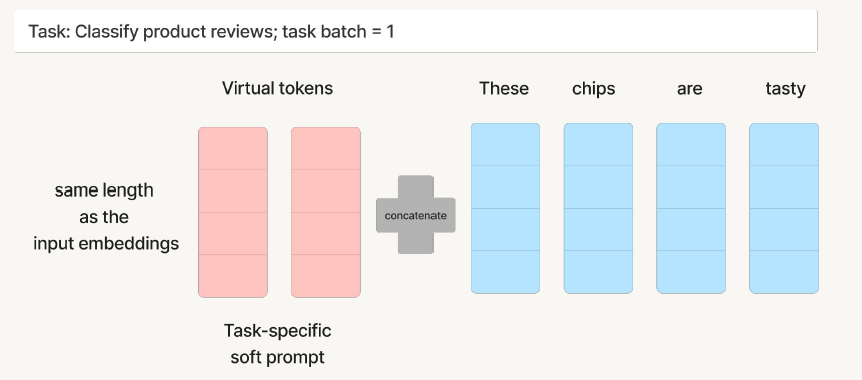
为了更加直观的简述Prompt Tuning。之前先看下面的两张图,第一张图是全微调,也就是说准备好的样本数据,然后继续二次微调模型的参数。
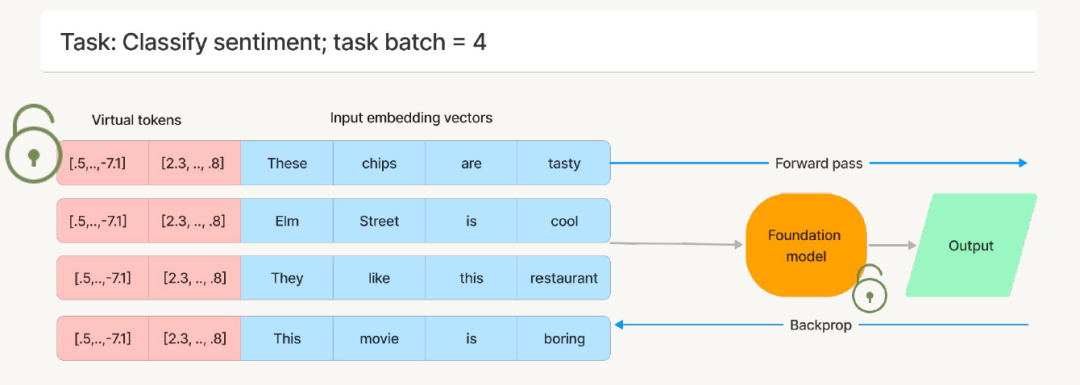
全微调
第二张图是将大模型的参数冻结,然后针对不同的任务训练前缀(粉红色的部分)。下面的训练一个批次是4条样本。
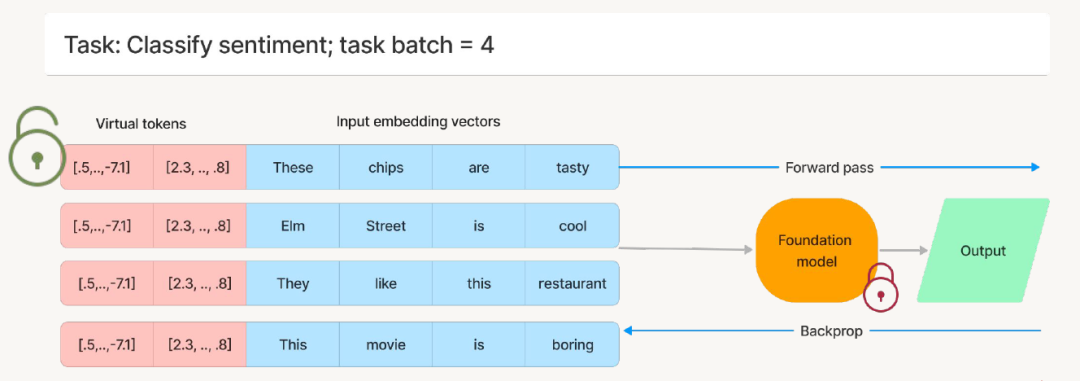
Prompt Tuning

Prompt Tuning的超参数们
那么在样本之前要填充多少的虚拟Token才是最为合适的呢?以T5为例,针对不同任务的标准模型微调实现了强大的性能,但需要为每个特定的任务准备分支副本。
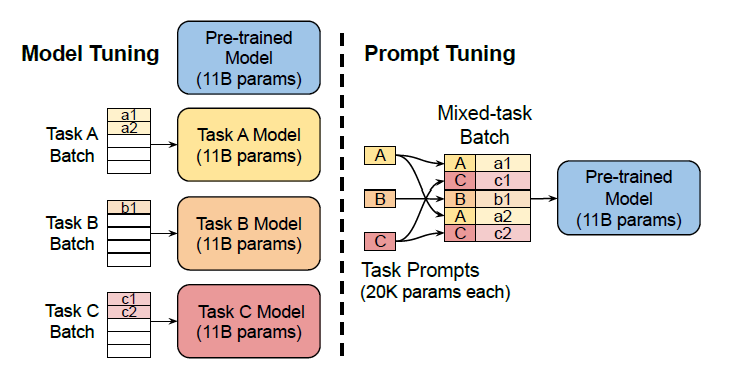
假定使用T5系列的模型,每个调整后的模型副本需要11B参数。相比之下,采用Prompt Tuning技术之后,若填充的虚拟Token为5,那么每个任务只需要20480个参数,减少了5个数量级以上。
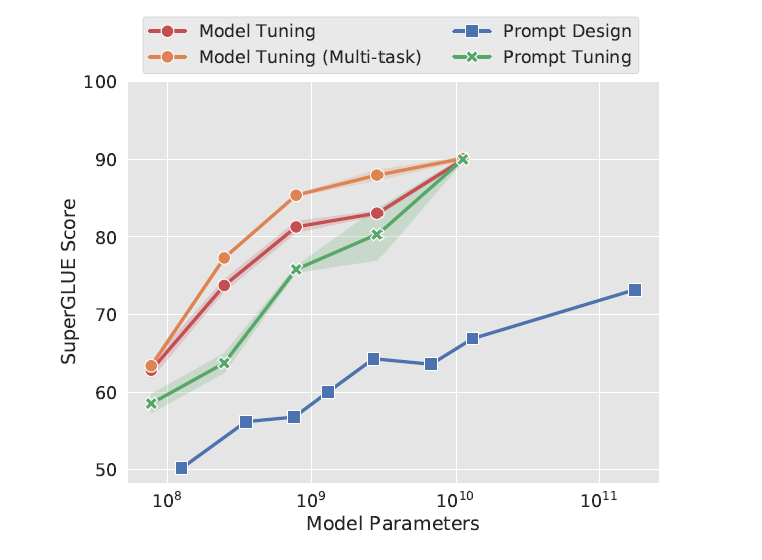
回头看看采用Prompt Tuning技术的T5,随着大模型规模的增加,表现不断地提升,而且这个过程中基座模型是冻结的,只有一份。仔细观察下图会发现,其实这种技术在大参数模型还是比较合适的,而在小参数模型中的表现一般,注意黄色(模型微调)和绿色(Prompt Tuning)在不同参数规模的模型的间隙。
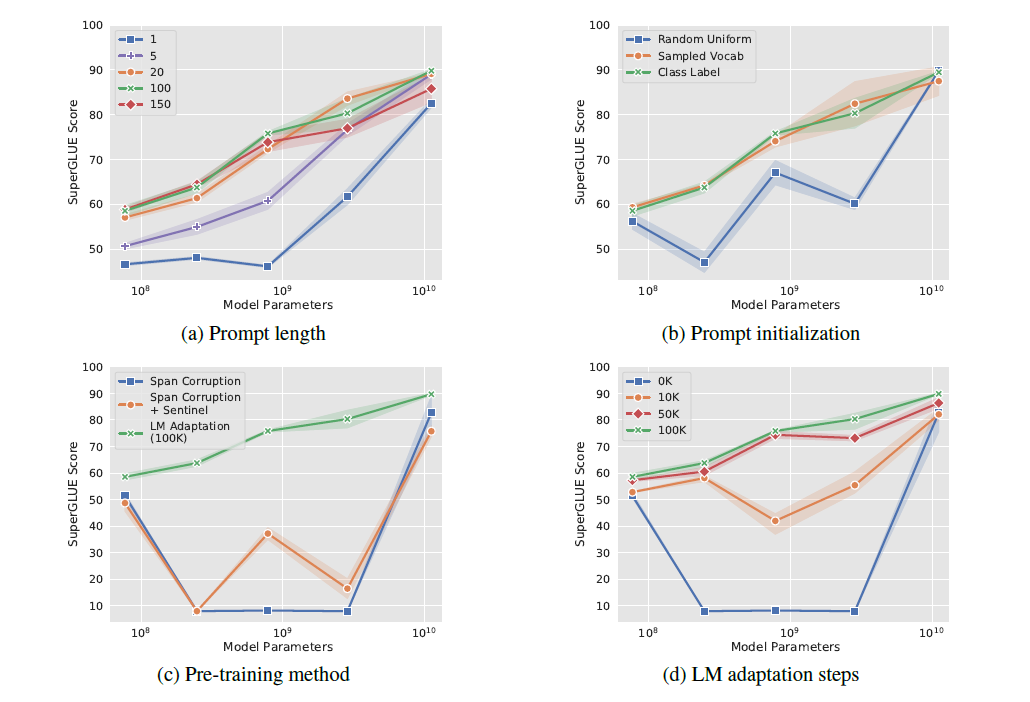
上面这幅图是在各种不同的情况下研究一些超参数对这种技术的性能影响。值得注意的是,这种技术的质量随着模型大小的增加而稳定提高。在所有研究中,特大号参数的模型对超参数选择最为稳健。
a图说明增加到 20多个虚拟Token通常会带来很大的提升,但是对于特大号的模型而言,增加一个虚拟的Token就足够了。是不是很神奇!
b表明随机均匀初始化参数数值落后于使用采样词汇或类标签嵌入的更“高级”初始化,但这种差异在特大号模型下消失。
c表明LM Adaptation在跨领域的表现优越,即使在下游任务目标中添加了标记
d展示较长的适应步伐(Step)通常会带来更大的收益

Prompt Tuning的优点
采用prompt tuning技术的好处在于它可以自动从一个新的模型中学习最佳的Prompt,就是如何引导大模型能够根据新的任务,给出针对性的回答。之前网上有很多教程,教读者如何学会写高效的Prompt,采用这种技术将自动化的训练对应任务的虚拟Token,然后自动的找出最佳的引导方法。
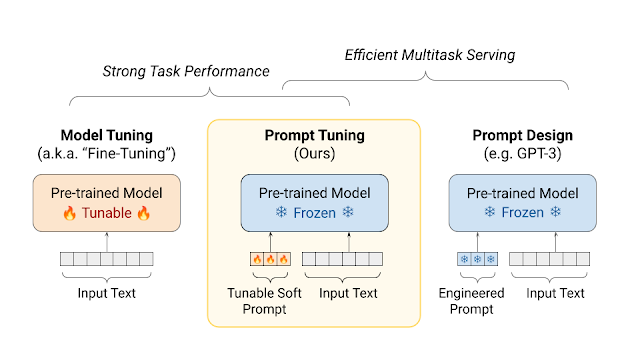
Prompt 调优保留了模型调优的强大任务性能,同时保持预训练模型的冻结状态,从而实现高效的多任务服务。
大白话说,就是你和蚂蚁沟通,你可以采用很多方式,但是你也可以“烘烘哈衣,@@#¥……”,结果蚂蚁听懂了。“烘烘哈衣,@@#¥……” 就是那些训练出来的虚拟Token,人很难听懂。这么说,有点和禅宗的大喝一声,用力一棒异曲同工。最重要的是,采用这种技术,只需要一个基座模型,对于模型迁移具有很强的弹性。
