
阅读量:11
目录

一、云数据中心的特征
云计算基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。将云计算与数据中心有效结合实现了优势互补。 云数据中心应具备以下几个特征。
- 高设备利用率:采用虚拟化技术进行系统和数据中心整合,优化资源利用率、简化管理。
- 绿色节能:通过先进的供电和散热技术,降低数据中心的能耗。
- 高可用性:当网络扩展或升级时,网络能够正常运行,对网络的性能影响不大。
- 自动化管理:云数据中心应是24×7小时无人值守并可远程管理的。
二、云数据中心网络部署
为了适应新型应用的需求,数据中心网络需要在低成本的前提下满足高扩展性、低配置开销、健壮性和节能的要求。对目前的数据中心网络体系结构做了对比,见下表:
| 网络拓扑 | 规模 | 带宽 | 容错性 | 扩展性 | 布线复杂性 | 成本 | 兼容性 | 配置开销 | 流量隔离 | 灵活性 |
|---|---|---|---|---|---|---|---|---|---|---|
| FatTree | 中 | 中 | 中 | 中 | 较高 | 较高 | 高 | 较高 | 无 | 低 |
| VL2 | 大 | 大 | 中 | 中 | 较高 | 较高 | 中 | 较高 | 无 | 中 |
| OSA | 小 | 大 | 差 | 中 | 较低 | 较高 | 低 | 中 | 无 | 高 |
| WDCN | 小 | 大 | 较好 | 中 | 较低 | 中 | 中 | 中 | 无 | 高 |
| DCell | 大 | 较大 | 较好 | 较好 | 高 | 较高 | 中 | 较高 | 无 | 较高 |
| FiConn | 大 | 较大 | 较好 | 较好 | 较高 | 中 | 中 | 较高 | 无 | 较高 |
| BCube | 小 | 大 | 好 | 较好 | 高 | 较高 | 中 | 较高 | 无 | 较高 |
| MDCube | 大 | 大 | 较好 | 较好 | 高 | 高 | 中 | 较高 | 无 | 较高 |
(一)改进型树结构
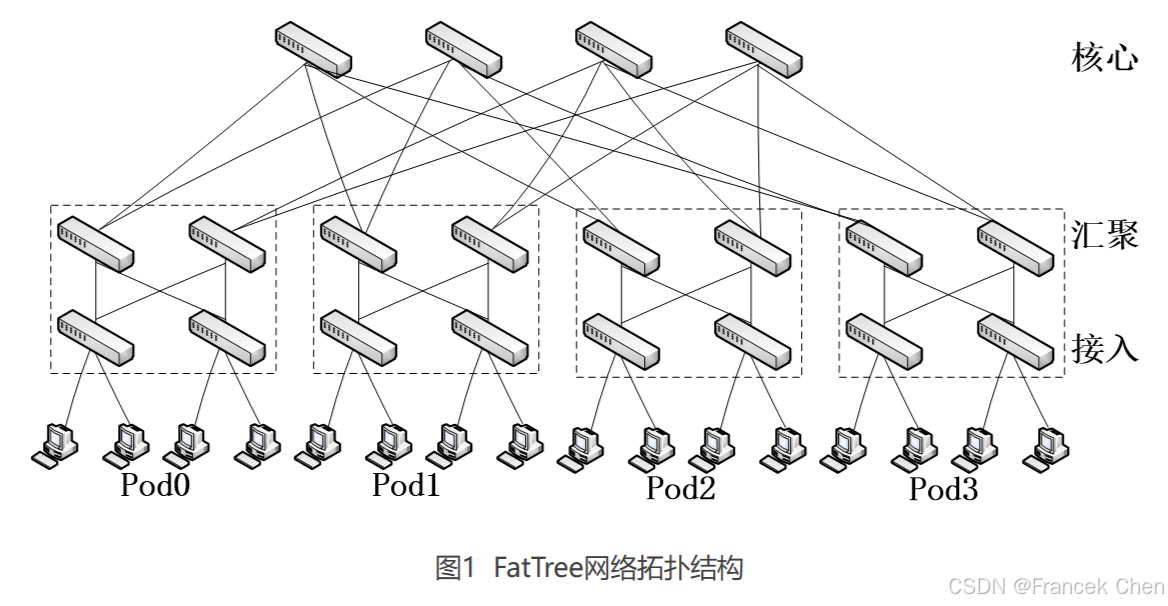
与传统层次结构相比, FatTree结构有如下特点:消除了树形结构上层链路对吞吐量的限制;为内部节点间通信提供多条并行链路;横向扩展的尝试降低了构建数据中心网络的成本;与现有数据中心网络使用的以太网结构和IP 配置的服务器兼容。
但是,FatTree的扩展性受限于核心交换机端口数量,目前比较常用的是48端口10G核心交换机,在3层树结构中能够支持27648台主机。
微软数据中心采用了VL2架构,VL2是一套可扩展并十分灵活的网络架构。
(1)扁平寻址,这可以允许服务实例被放置到网络覆盖的任何地方。
(2)负载均衡将流量统一的分配到网络路径。
(3)终端系统的地址解析拓展到巨大的服务器池,并不需要将网络复杂度传递给网络控制平台。
VL2的核心思想是使用CLOS拓扑结构建立扁平的第二层网络。在VL2的体系结构中,应用程序使用服务地址通信而底层网络使用位置信息地址进行转发,这使得虚拟机能在网络中任意迁移而影响服务质量。
VL2仍然采用三层拓扑结构进行交换机级联。但不同的是,VL2中的各级交换机之间都采用10Gbps端口以减小布线开销。
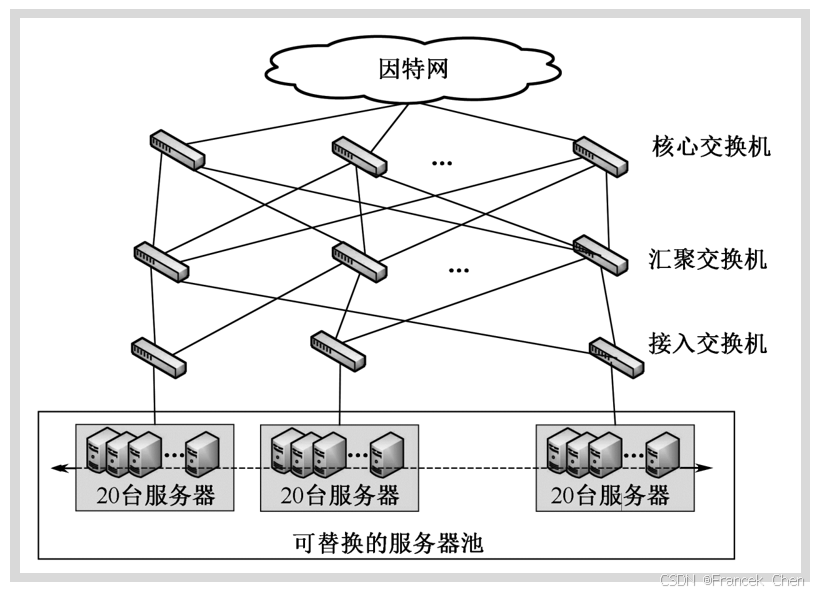
在VL2中,IP地址仅仅作为名字使用,没有拓扑含义。VL2的寻址机制将服务器的名字与其位置分开。VL2使用可扩展、可靠的目录系统来维持名字和位置间的映射。当服务器发送分组时,服务器上的VL2代理开启目录系统以得到实际的目的位置,然后将分组发送到目的地。VL2是目前最易用于对现有数据中心网络改造的结构,但VL2依赖于中心化的基础设施来实现2层语义和资源整合,面临单点失效和扩展性问题。
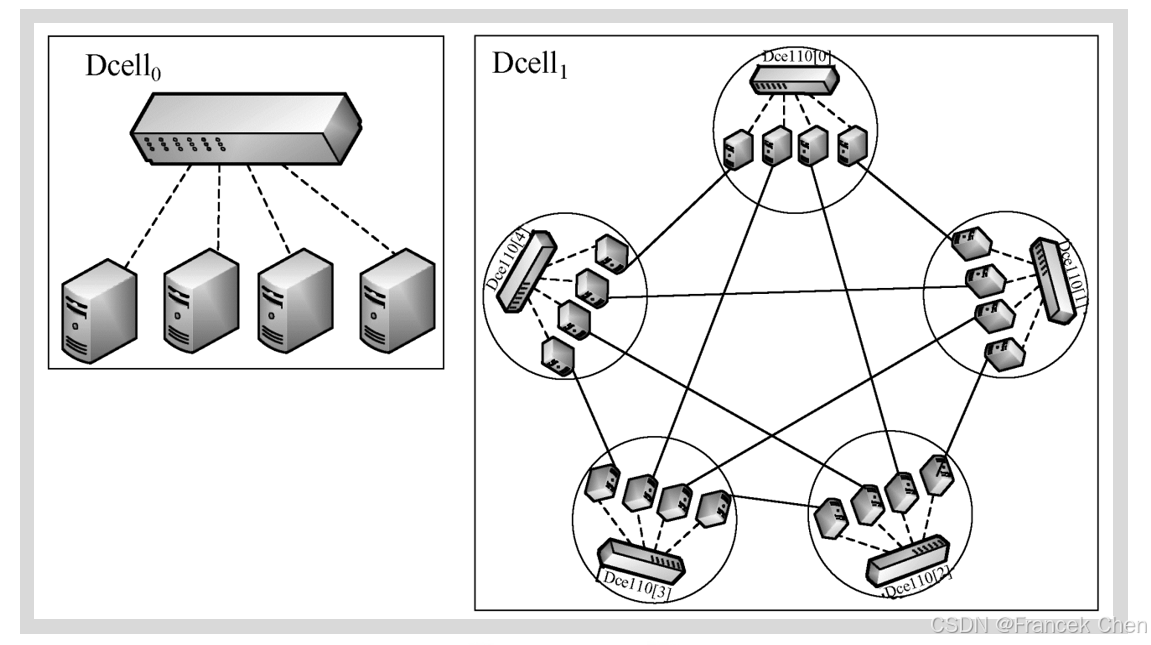
(二)递归层次结构
在DCell网络的构建过程中,低层网络是基本的构建单元, n n n个服务器来连接一个具有 n n n个端口的交换机,每个DCell中的服务器有1个端口连接到交换机,称为0层端口,连接到0层端口和交换机的链路称为0层链路。每个低层网络中的每台服务器分别与其他每个低层网络中的某台服务器相连,因此,构建高层次网络时,需要的低层网络的个数等于每个低层网络中的服务器个数加1,其拓扑结构如图所示。如果将每个低层网络看成一个虚节点,则高层DCell网络是由若干个低层DCell网络构成的完全图。DCell拓扑的优势是网络可扩展性好,但其拓扑的层数受限于服务器的端口数。
FiConn的网络构建方式与DCell网络相似,其拓扑结构如图所示。但与DCell不同的是,FiConn中的服务器使用两个网卡端口(一个主用端口,一个备用端口),其中主用端口用于连接低层(第0层)网络,备用端口用于连接高层网络。
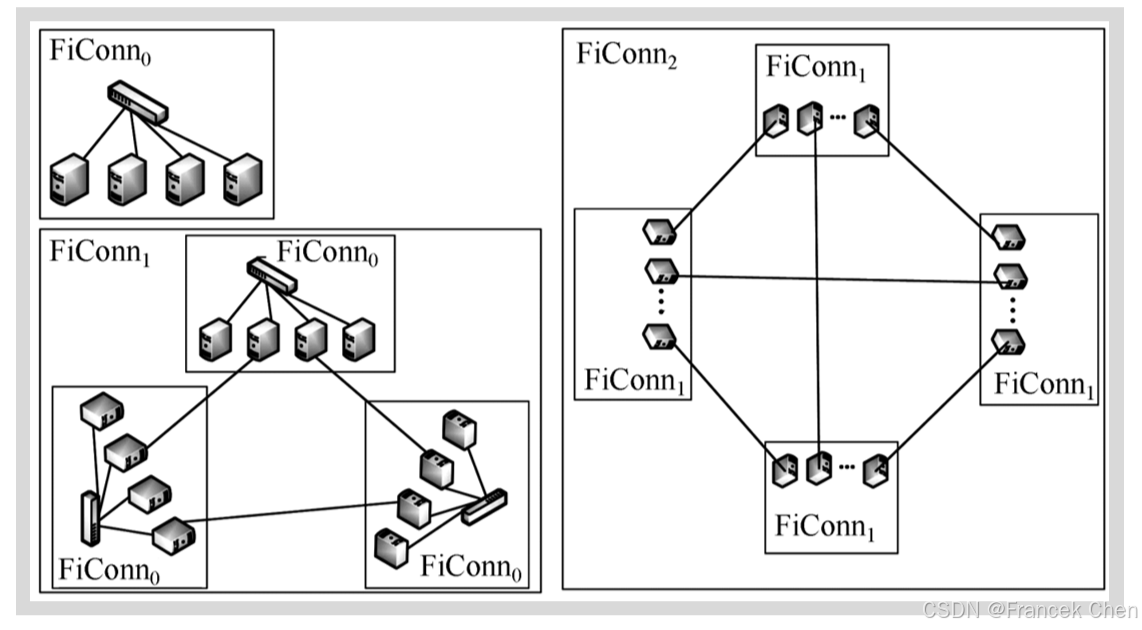
FiConn是一个递归定义的结构,高层FiConn由一些低层FiConn构建,Li等人将 k k k层FiConn标识为FiConn k _k k。第0层是基本的构建单元, n n n个服务器连接一个具有 n n n个端口的交换机,每个FiConn中的服务器有1个端口连接到第0层,如果服务器的备用端口没有连接到其他服务器,则称其为备用端口。
在进行层次化网络互连的过程中,每个低层FiConn网络中备用端口空闲的一半服务器会与其他相同层次的FiConn网络中备用端口空闲的服务器连接,构建高层次的FiConn网络。即如果一个FiConn k _k k中共有 b b b个服务器拥有可用备用端口,那么在每个FiConn k _k k中, b b b个服务器中的 b b b/2个拥有备用端口的服务器使用其备用端口连接到其他FiConn k _k k,这 b b b/2个被选择的服务器称为 k k k层服务器, k k k层服务器上被选择的端口称为 k k k层端口,连接 k k k层端口的链路称为 k k k层链路。与Dcell类似,如果将FiConn看成一个虚拟服务器,那么高层次的FiConn网络是由若于个低层次的FiConn网络构成的一个完全图。该拓扑方案的优点是不需要对服务器和交换机的硬件做任何修改,但每个FiConn对外连接的链路仍然有限,这使用FiConn的容错性较弱,且其路径长度较大,路由效率不高。
BCube使用交换机构建层次化网络,网络中主要包括服务器和交换机两种组件。BCube采用了递归的构建方法,拓扑结构如图所示。BCube第0层就是将 n n n个服务器连接到一个 n n n端口的交换机,然后通过若干台交换机将多个低层BCube网络互连起来,其中每个高层交换机与每个低层BCube网络都相连。 n n n=4,BCube第1层由4个BCube 0 _0 0和4个4端口交换机构成。更一般的情况是,BCube k _k k由 n n n个BCube k − 1 _{k-1} k−1和 n k n^k nk个 n n n端口交换机组成。每个BCube k _k k中的服务器有 k k k+1个端口,标记为level0到levelk。因此,一个BCube k _k k有 N = n k + 1 N=n^{k+1} N=nk+1个服务器和 k k k+1层交换机,每一层有 n k n^k nk个 n n n端口交换机。
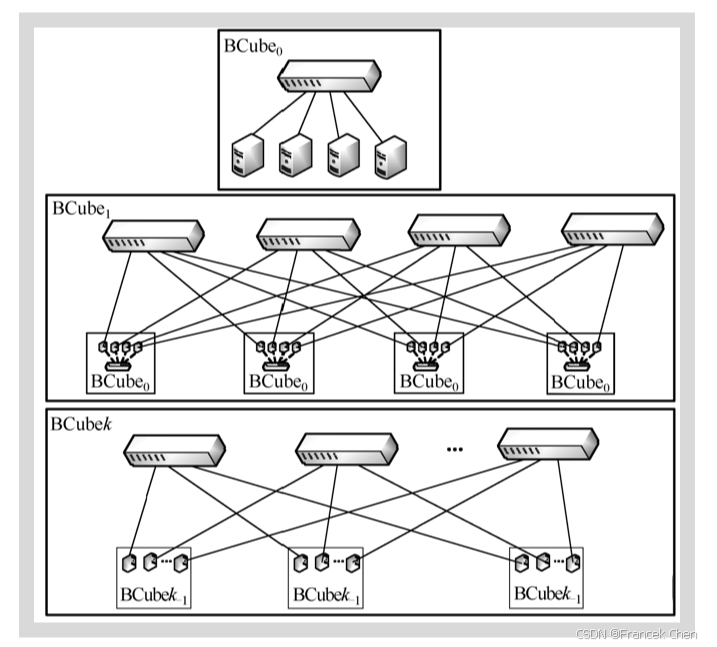
BCube主要为集装箱规模的数据中心设计,采用的服务器为中心的体系结构充分利用了服务器和普通交换机的转发功能,在支持大量服务器的同时降低了构建成本,成为了数据中心网络的重要研究方向。其最大优势是链路资源非常丰富,提供了负载均衡, 不会出现明显的瓶颈链路,当发生服务器或者交换机失效时,BCube可以做到性能的优雅下降,从而维持了服务的可用性。但BCube服务器间存在 k k k+1条路径,在探测过程会造成较大的通信和计算开销,同时BCube要求每个服务器都要有 k k k+1个端口,这使得目前的很多现有服务器难以符合其要求,需要进行升级改造。
MDCube使用BCube中交换机的高速接口来互连多个BCube集装箱。为了支持数百个集装箱,它使用光纤作为高速链路,每个交换机将其高速接口作为其BCube集装箱的虚拟接口。因此,如果将每个BCube集装箱都当做一个虚拟节点,它将拥有多个虚拟接口。MDCube是一个多维的拓扑结构,它可以互连的数据中心集装箱的个数是所有维度上可容纳的数据中心个数的乘积。
(三)光交换网络
以前的数据中心,大多数网络数据流量在服务器和用户之间来回传输,但现在,随着Facebook、谷歌和亚马逊等越来越庞大和复杂的业务出现,数据中心内部和服务器间的数据流量快速增加,传统网络设备无法处理这么多的流量,这些变化使这些网络巨头开始考虑采用可光速传播数据的设备,重新修改网络拓扑。
Helios是谷歌、Facebook和其他技术巨头资助研发的混合电/光结构网络,它是一个两层的多根树结构,主要应用于集装箱规模的数据中心网络,其拓扑如图所示。 Helios将所有的服务器划分为若干集群,每个集群中的服务器连接到接入交换机,每个接入交换机与一个电交换网络和一个光网络连接。电网络是一个2层或3层的具有特定超额认购比例的树;在光部分,每个接入交换机仅有1个连接到其他机架交换机的光链路。该拓扑保证了服务器之间的通信可使用分组链路,也可使用光纤链路。
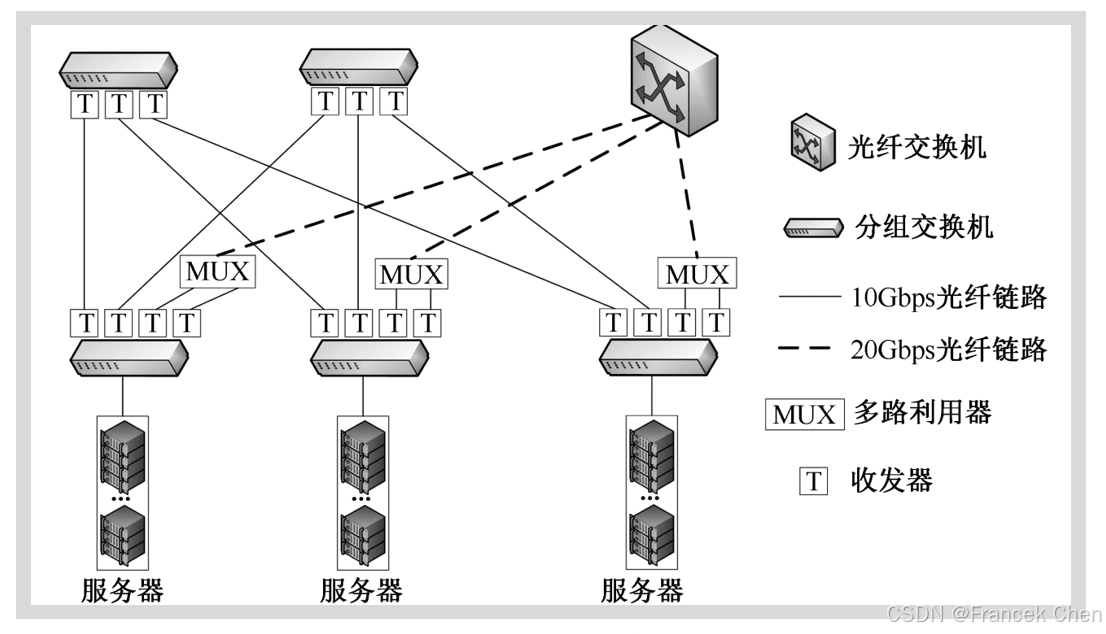
一个集中式的拓扑管理程序实时地对网络中各个服务器之间的流量进行监测,并对未来流量需求进行估算。拓扑管理程序会根据估算结果对网络资源进行动态配置,使流量大的数据流使用光纤链路进行传输,流量小的数据流仍然使用分组链路传输,从而实现网络资源的最佳利用。
OSA (optical Switching Architecture) 是Chen等人提出的基于光交换的数据中心网络体系结构,其体系结构如图所示。OSA的应用场景是集装箱规模的数据中心网络。OSA中主要引入了光交换矩阵(Optical Switching Matrix, OSM)和波长选择交换机(Wavelength Selective Switch, WSS)作为技术基础。
大部分光交换模块是双向N×N矩阵,任意输入端口可以连接到任意的输出端口。 目前流行的OSM技术使用MEMS (Micro-Electro-Mechanical Switch) 实现,它可以在10ms以内通过机械地调整镜子的微排列来更改输入和输出端口的连接。
一个波长选择交换机WSS是一个1×N交换机,由一个通用和N个波长端口组成。它将通用端口进入的波长集合分开在N个波长端口,这个过程可以在运行时以毫秒级进行配置。
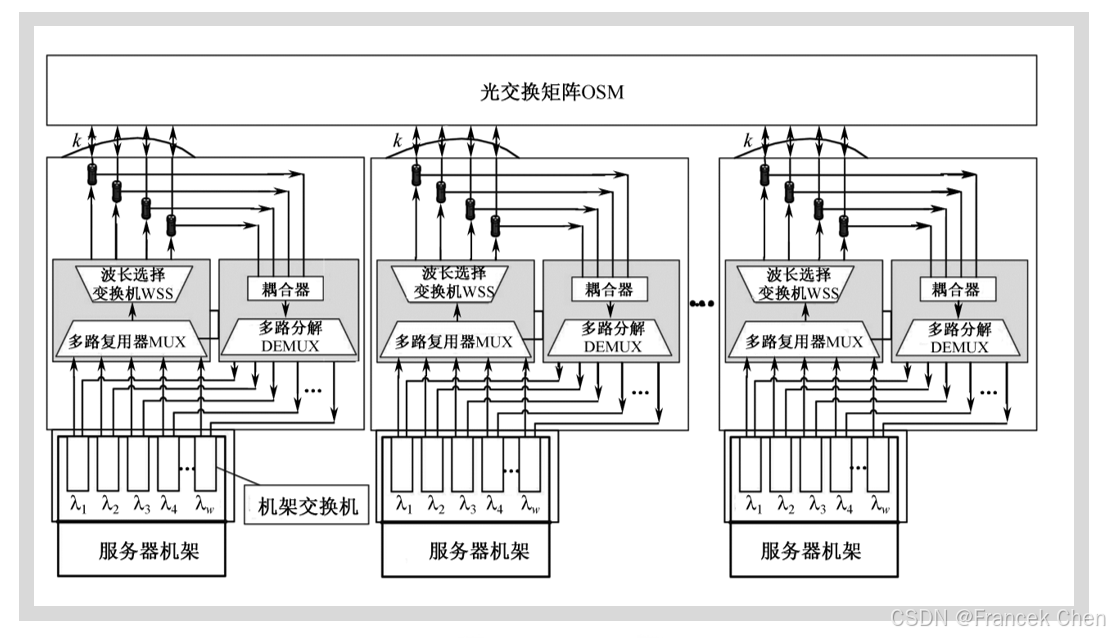
OSA在网络内部采用了全光信号传输,仅在服务器与机架交换机之间使用电信号传输。OSA通过光交换机将所有机架交换机连接起来。由于服务器发出的都是电信号,因此OSA在机架交换机中放置光收发器 (Optical Transceiver),用于光电转换;然后利用波长选择交换机WSS将接收到的不同波长映射到不同的出端口;再通过光交换矩阵OSM在不同端口之间按需实现光交换。为了更有效地利用光交换机的端口,通过使用光环流器 (Optical Circulator) 实现在同一条光纤上双向传输数据。
OSA实现了多跳光信号传输,它使用逐跳交换来达到网络范围的连通性,不过在中间每一跳,都需要进行“光一电一光”的转换,在机架交换机进行交换。OSA的最大特点是利用光网络配置灵活的特点,能够根据实际需求动态调整拓扑,大大提高了应用的灵活性。
光交换比点交换方式具有潜在的更高的传输速率、更灵活的拓扑结构,并且其制冷成本更低,因而是数据中心网络很重要的研究方向。但由于光交换网络是面向连接的网络,将不可避免引入时延,这将对搜索等对时延要求较高的应用带来影响。另外,目前光交换网络的设计针对集装箱规模的数据中心,其规模有限,如何从体系结构和管理的角度设计和构建大规模数据中心网络是一项很有挑战性的工作。
(四)无线数据中心网络
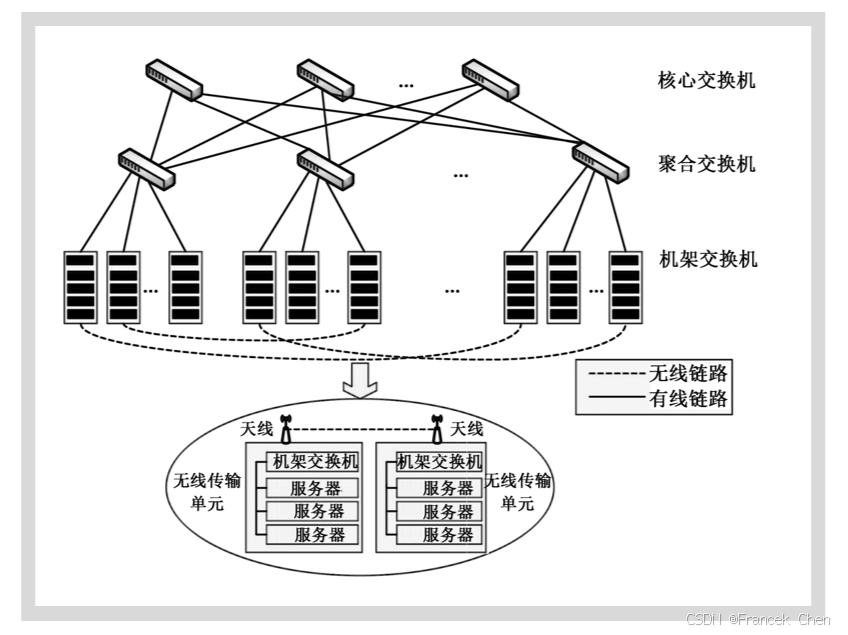
无线技术可以在不必进行重新布线的情况下灵活调整拓扑,省去了复杂的布线工作,但无线技术在提供足够带宽的前提下,其传输距离是有限的,因而限制了其在大规模数据中心的部署。
(五)软件定义网络
软件定义网络(Software Defined Networking,SDN)作为新的网络架构成为最近学术界关注的热点,美国GENI、Internet2、欧洲OFELIA和日本的JGN2plus先后展开对SDN的研究和部署。
SDN相关的工作主要在三个相关组织开展,包括开放网络基金会ONF (Open Networking Foundation) 定义的OpenFlow架构;IETF的Software DrivenNetwork架构;ETSI的Network FunctionVirtualization架构。
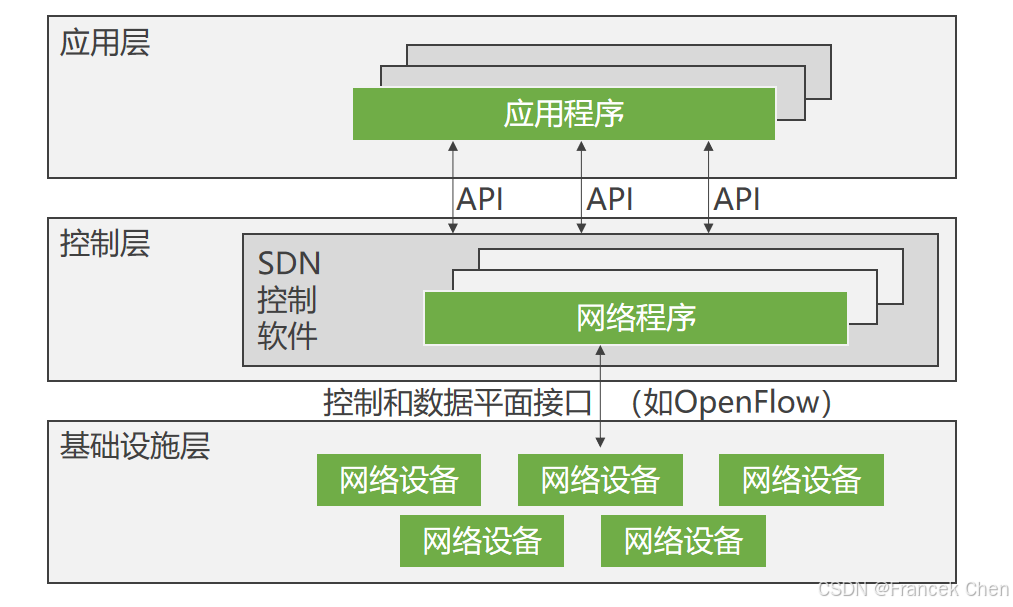
OpenFlow是第一个针对SDN实现的标准接口,包括数据层与控制层之间的传输协议、控制上的API等。OpenFlow的基本思想是将路由器的控制平面和数据平面相分离,将控制功能从网络设备中分离出来,在网络设备上维护流表结构,数据分组按照流表进行转发,而流表的生成、维护、配置则由中央控制器来管理。OpenFlow的流表结构将网络处理层次扁平化,使得网络数据的处理满足细粒度的处理要求。在这种控制转发分离架构下,网络的逻辑控制功能和高层策略可以通过中央控制器灵活地进行动态管理和配置,可在不影响传统网络正常流量的情况下,在现有的网络中实现和部署新型网络架构。
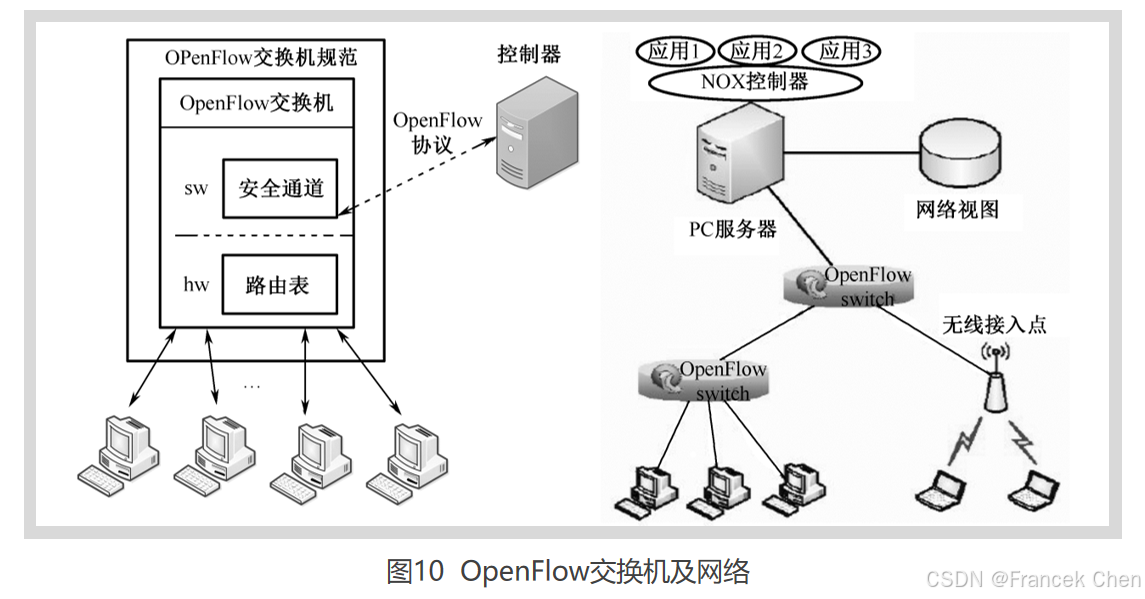
OpenFlow主要由OpenFlow交换机、控制器两部分组成。OpenFlow交换机负责数据转发功能,主要技术细节由三部分组成:流表 (Flow Table)、安全信道 (Secure Channel) 和OpenFlow协议 (OpenFlow Protocol),如图所示。每个OpenFlow交换机的处理单元由流表构成,每个流表由许多流表项组成,流表项则代表转发规则。进入交换机的数据包通过查询流表来取得对应的操作。安全通道是连接OpenFlow交换机和控制器的接口,控制器通过这个接口,按照OpenFlow协议规定的格式来配置和管理OpenFlow交换机。在控制器中,网络操作系统 (Network Operating System, NOS) 实现控制逻辑功能,实际上,这里的NOS指的是SDN概念中的控制软件,通过在NOS上运行不同的应用程序能够实现不同的逻辑管控功能。目前NOX控制器成为OpenFlow网络控制器平台实现的基础和模板。NOX通过维护网络视图 (Network View) 来维护整个网络的基本信息,如拓扑、网络单元和提供的服务,运行在NOX之上的应用程序通过调用网络视图中的全局数据,进而操作OpenFlow交换机来对整个网络进行管理和控制。
Google在其广域网数据中心已经大规模使用基于OpenFlow的SDN技术,通过10G网络链接分布全球的12个数据中心,实现了数据中心的流量工程和实时管控功能,使其数据中心的核心网络带宽利用率提高到了100%,谷歌将自己的SDN网络命名为为B4,其网络结构图如图所示。
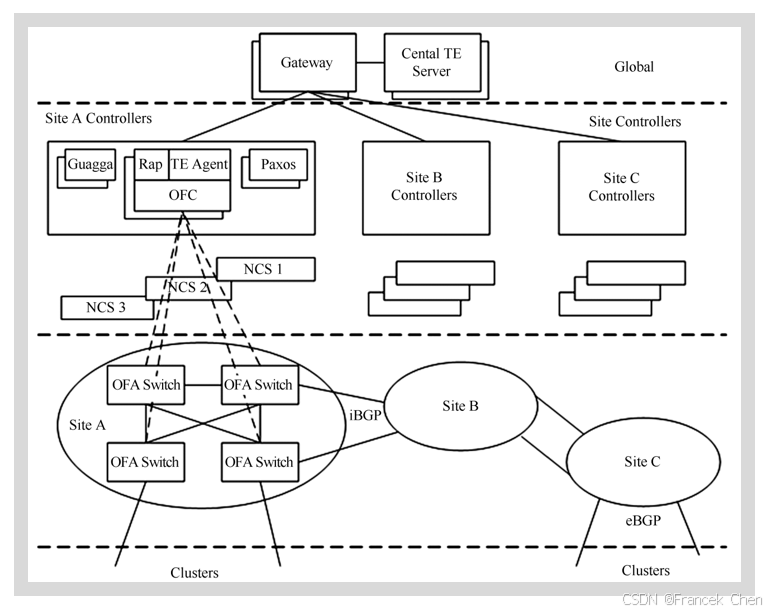
网络共分为三层:物理设备层 (Switch Hardware)、局部网络控制层 (Site Controllers) 和全局控制层 (Global)。一个Site就是一个数据中心。第一层的物理交换机是Google自行设计的,交换机里运行了OpenFlow协议,向上提供OpenFlow接口, 交换机把BGP/IS-IS协议报文送到Controller供其处理。OSFP、BGP、ISIS路由协议来自于开源的Quagga协议栈。第二层部署了几套网络控制器服务器 (NCS),每个服务器上都运行了一个Controller,一台交换机可以连接到多个Controller,但其中只有一个处于工作状态。一个Controller可以控制多台交换机,一个名叫Paxos的程序用来选出工作状态的Controller。在Controller上运行了两上应用,一个是RAP (Routing Application Proxy) 作为SDN应用与Quagga通信,另一个是TE Agent与全局的SDN网关 (Gateway) 通信。第三层中全局的TE Server通过SDN网关从各个数据中心的控制器收集链路信息,从而掌握路径信息。
经过上述改造之后,链路带宽利用率提高了3倍以上,接近100%,链路成本大大降低,而且网络更稳定,对路径失效的反应更快,大大简化了管理,也不再需要交换机使用大的包缓存,降低了对交换机的要求。Google这个基于SDN的网络改造项目影响非常大,对SDN的推广有着良好的示范作用。
