
阅读量:3
一、分布式存储系统Megastore
1.概述
(1)设计目标:设计一种介于传统的关系型数据库和NoSQL之间的存储技术,尽可能达到高可用性和高可扩展性的统一。
a.针对可用性的要求,实现了一个同步的、容错的、适合远距离传输的复制机制,最后实现的就是Paxos。
b.针对可扩展性的要求,将整个大的数据分割成很多小的数据分区,每个数据分区连同它自身的日志存放在NoSQL数据库中,具体来说就是存放在Bigtable中。
(2)Megastore中事务间的消息传递通过队列(Queue)实现。
(3)在单个实体组上执行的事务除了更新它自己的实体外,还能够发送或收到多个信息。
(4)每个消息都有一个发送和接收的实体组。
(5)Megastore 支持跨实体组的事务的两阶段提交:请求阶段和提交阶段。
(6)协调者出现故障:为了处理请求,一个协调者必须持有多数锁,一旦因为出现问题导致它丢失了大部分锁,协调者就会恢复到一个默认保守状态——认为所有它能看到的实体组都是失效的。
2.实体组集
(1)在Megastore中,这些小的数据分区被称为实体组集(Entity Groups)。
(2)每个实体组集包含若干的实体组(Entity Group),实体组相当于表的概念。
(3)多数情况下每个实体组仅有一个子表,分布在一台Bigtable的子表服务器上,若实体组比较大,导致子表分裂,会分布到多台子表服务器上。
(4)一个实体组中包含很多的实体(Entity,相当于表中记录的概念)。
(5)Megastore中,所有的表要么是实体组根表(Entity Group Root Table),要么是子表(Child Table)。
3.Megastore索引
(1)局部索引:定义在单个实体组中,作用域仅限于单个实体组。
(2)全局索引:可以横跨多个实体组集进行数据读取操作。
4.Megastore提供的三种读
current | (1)总是在单个实体组中完成。 (2)在开始某次current读之前,需要确保已提交的写操作已经全部生效,然后应用程序再从最后一个成功提交的事务时间戳位置读数据。 |
snapshot | (1)总是在单个实体组中完成。 (2)系统取出已知的最后一个完整提交的事务的时间戳,接着从这个位置读数据。就是这个一半了不行,至少得是一个整的,但此时允许有写操作。 (3)读的时候可能还有部分事务提交了但还未生效。 |
inconsistent | (1)忽略日志的状态直接读取最新的值。就是这个数据哪怕就一半,我也从这。 (2)适用于要求低延迟并能忍受数据过期或不完整的读操作。 |
5.Megastore的写操作——预写式日志:
(1)只有当所有的操作都在日志中记录下后,写操作才会对数据执行修改。
(2)一个写事务总是开始于一个current读,以便确认下一个可用的日志位置.
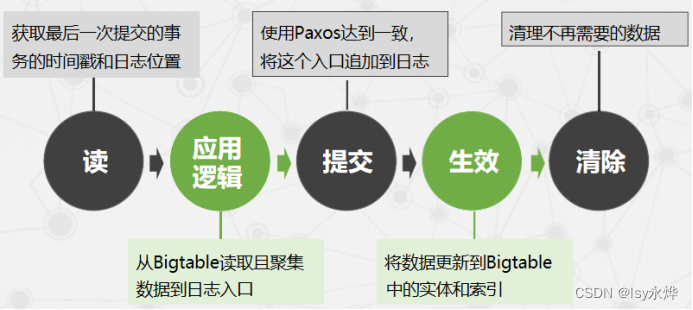
6.在Mega sto re 中共有 三种副本
(1)完整副本:可投票,存储数据和日志。
(2)见证者副本:可投票,只存储日志。
(3)只读副本:不可投票,读取最近过去某个时间点的一致性数据,数据不是最新的。
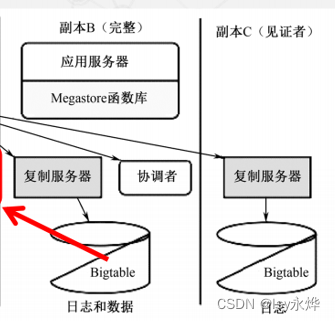
7.快速读与快速写
(1)快速读:由于写操作基本上能在所有副本上成功, 一旦成功认为该副本上的数据都是相同的且是最新的,就能利用本地读取实现快速读。
(2)快速写:如果一次写成功 ,那么下一次写的时候就跳过准备阶段,直接进入提交阶段。
8.核心技术——复制
(1)通过复制,保证所有最新的数据都保存有一定数量的副本,能很好地提高系统的可用性。
(2)即使这些数据记录正从一个之前的故障中恢复数据,副本也要保证其能够参与到写操作中的Paxos算法。
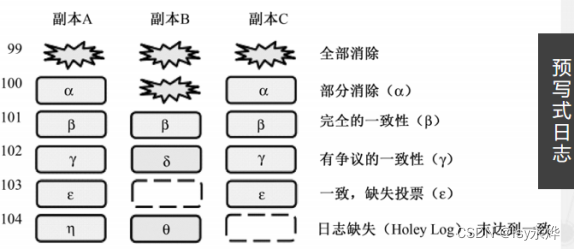
9.数据读取
(1)本地查询:查询本地副本的协调者来确认这个实体组上的数据是否是最新的。
(2)发现位置:获取已提交的最大的日志位置,而后基于该日志位置选择最合适的副本。
【本地读取】如果是最新的,则直接读取Local Replica中已接收的最大的Log Position以及Timestamp信息;
【多数派读取】如果不是最新的,则从大多数副本中获取已被接收的最大的Log Position信息以及Timestamp信息,然后选择一个通常能快速响应的Replica或者是数据最新的Replica。
(3)追赶:进行数据追赶,需要补齐所有的缺失的数据,在一次Current读之前,要保证至少有一个副本上的数据是最新的,所有之前提交到日志中的更新必须复制到该副本上并确保在该副本上生效。
(4)验证:如果Local Replica被选中了且不是最新的,这个时候需要给协调者发送验证信息来确认要读取的Entity Group在该Replica中的数据是完整的。
(5)查询数据:基于Timestamp信息开始读取数据。如果读取过程中,所选择的Replica变得不可用了,则需要重新更换一个Replica,然后同样需要执行数据追赶操作。
二、大规模分布式系统的监控基础架构Dapper
1.两个基本要求:
(1)广泛可部署性:设计出的监控系统应当能够对尽可能多的Google服务进行监控。
(2)不间断的监控:Google的服务是全天候的,如果不能对Google的后台同样进行全天候的监控很可能会错过某些无法再现的关键性故障。
2.三个基本设计目标:低开销,对应用层透明,可扩展。
3.概述
(1)使用小规模库:实现“对应用层透明”的目标。
(2)利用二次抽样技术:解决低开销及广泛可部署性的问题。
第一次抽样:实践中,设计人员发现当抽样率低至1/1024时也能够产生足够多的有效监控数据,即在1024个请求中抽取1个进行监控也是可行的,从而可以捕获有效数据。
第二次抽样:发生在数据写入Bigtable前。具体方法是将监控id变成hash值,然后跟一个实现定好的值z作比较,小于则保留。
4.Dapper监控系统的三个基本概念:
(1)监控树(Trace Tree):一个同特定事件相关的所有消息,按照一定的规律以树的形式组织起来。
(2)区间(Span):树里面的节点,实际上就是一条记录,所有的记录联系在一起就构成了对某个事件的完整监控。
(3)注释(Annotation)注释主要用来辅助推断区间关系,也可以包含一些自定义的内容。
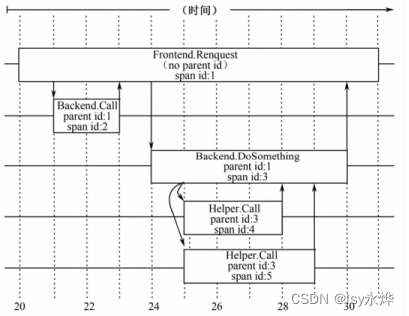
5.区间:
(1)区间名(Span Name):类似人的小名,好记。
(2)区间id(Span id)
(3)父id(Parent id)
(4)监控id(Trace id):一棵监控树中所有区间的监控id是相同的,这个id 是随机分配的,并且在整个Dapper中是唯一的。 监控id是用来在区分整个Dapper监控系统中不同的监控。
6.选择Bigtable的原因:
(1)支持松散结构。
(2)单独的一行表示一个记录 ,而一列则相当于一 个区间。
7.Dapper的“存储API”简称为 DAPI
(1)提供了对分散在区域Dapper存储库的监控记录的直接访问。
一般有以下三种方式访问这些记录。
(2)通过监控id访问:利用全局唯一的监控id直接访问所需的监控数据。
(3)块访问:借助MapReduce对数以十亿计的Dapper监控数据的并行访问。
(4)索引访问:Dapper存储库支持单索引(SingleIndex)。
三、习题
第13题 1分
Megastore的基本架构中,最底层的数据存储在( )中。
A GFS
B Bigtable
C Chubby
D Dapper答案:B
第8题 1分
Megastore有三种读,其中需要确保已提交的写操作已经全部生效的读操作是( )。
A current
B snapshot
C inconsistent
D read答案:A
第10题 1分
Megastore中,在一次Current读之前,要保证至少有一个副本上的数据是最新的,所有之前提交到日志中的更新必须复制到该副本上并确保在该副本上生效,这个操作称为( )。
A 预写式日志
B 追赶
C 合并
D 多数派读取答案:B
第13题 1分
Google的监控基础架构中,为了尽可能地减少开销,采用的方案是( )。
A 三次抽样
B 三次压缩
C 二次抽样
D 二次压缩答案:C
第24题 2分
Megastore中,所有的子表必须有一个通过[填空1]声明的、参照根表的[填空2]。答案:Entity Group Key、索引
结合了关系数据库和NoSQL数据库的优点。
第25题 3分
Google云计算的监控系统有三个设计目标,分别是[填空1]、[填空2]和[填空3]。答案:低开销,对应用层透明,可扩展
第29题 3分
Megastore中,每个实体有三种属性,分别是[填空1]、[填空2]、[填空3]。答案:必须的,可选的,可重复的
required,optional,repeated
第34题 1分
在Megastore中共有[填空1]、见证者副本和只读副本等三种副本。答案:完整副本
第3题 1分
Megastore有三种读,其中允许读的时候还有部分事务提交了但还未生效的是()。A. current
B. snapshot
C. inconsistentD read
答案:B
第24题 1分
Megastore事务中的写操作采用了[填空1],只有当所有的操作都在日志中记录下后,写操作才会对数据执行修改。答案:预写式日志
10.Megastore中的[填空1] 类似于关系数据库中的二维表。
表
14.在 Megastore 中,所有的表可以分为两类:
[填空1] 主表:主表通常包含基本的数据存储和索引信息,是整个数据模型的核心。
[填空2] 二级索引表:二级索引表用于支持根据非主键列进行快速查询和检索。
