
阅读量:1
本文中我们将通过一个小练习的方式利用urllib和bs4来实操获取豆瓣 Top250 的电影信息,但在实际动手之前,我们需要先了解一些关于Http 请求和响应以及请求头作用的一些知识。
1. Http 请求与响应
HTTP(超文本传输协议)是互联网上应用最为广泛的协议之一,它定义了客户端(通常是浏览器)和服务器之间交换数据的格式和规则。以下是HTTP请求与响应结合实际情况的介绍:
1.1 Http 请求(Request)
1.1.1 请求的组成
一个HTTP请求通常包含以下几个部分:
- 请求行:包括请求方法、URL和HTTP版本。
- 请求头:包含关于客户端环境和请求本身的信息,如用户代理(User-Agent)、接受的内容类型(Accept)等。
- 空行:用于分隔请求头和请求体。
- 请求体(可选):包含要发送给服务器的数据,如表单数据或JSON数据。
1.1.2 请求方法
- GET:请求获取服务器上的资源。
- POST:向服务器提交数据,通常用于提交表单或上传文件。
- PUT:更新服务器上的资源。
- DELETE:请求删除服务器上的资源。
1.1.3 实际应用
例如,当用户在浏览器中输入一个网址并按下回车时,浏览器会构造一个GET请求发送给服务器,请求头可能包含如下信息:
GET /index.html HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 这个请求意味着客户端请求获取服务器上名为www.example.com的网站根目录下的index.html文件。
1.2 Http 响应(Response)
1.2.1 响应的组成
一个HTTP响应通常包含以下几个部分:
- 状态行:包括HTTP版本、状态码和状态消息。
- 响应头:包含服务器信息和资源信息,如内容类型(Content-Type)、内容长度(Content-Length)等。
- 空行:用于分隔响应头和响应体。
- 响应体:包含从服务器返回的资源内容。
1.2.2 状态码
- 1xx:信息性状态码,如100 Continue。
- 2xx:成功状态码,如200 OK。
- 3xx:重定向状态码,如302 Found。
- 4xx:客户端错误状态码,如404 Not Found。
- 5xx:服务器错误状态码,如500 Internal Server Error。
1.2.3 实际应用
例如,当服务器收到上述GET请求后,可能会返回以下响应:
HTTP/1.1 200 OK Content-Type: text/html; charset=UTF-8 Content-Length: 1250 <!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <h1>Welcome to Example.com</h1> <p>This is an example HTML page.</p> </body> </html> 这个响应意味着服务器成功找到了请求的资源,并在响应体中返回了该HTML页面的内容。
HTTP请求与响应是客户端和服务器间通信的基础,它们通过请求方法、状态码、头部字段等机制确保了信息的有效传递。在实际应用中,无论是网页浏览、API调用还是文件上传,都离不开HTTP协议的这些基本原理。
2. GET、POST与请求头
下面是使用Python的requests库发送GET请求和POST请求的简单示例。首先,确保你已经安装了requests库。如果没有安装,可以通过以下命令安装:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple 2.1 GET请求示例
2.1.1 不带请求头的 GET 请求
import requests # 发送不带请求头的GET请求 response = requests.get('http://httpbin.org/get') print(response.text) 2.1.2 带请求头的 GET 请求
import requests # 定义请求头 headers = { 'User-Agent': 'My Custom User Agent', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8' } # 发送带请求头的GET请求 response = requests.get('http://httpbin.org/get', headers=headers) print(response.text) 2.2 POST请求示例
2.2.1 不带请求头的 POST 请求
import requests # 发送不带请求头的POST请求 response = requests.post('http://httpbin.org/post', data={'key': 'value'}) print(response.text) 2.2.2 带请求头的 POST 请求
import requests # 定义请求头 headers = { 'User-Agent': 'My Custom User Agent', 'Content-Type': 'application/x-www-form-urlencoded' } # 发送带请求头的POST请求 response = requests.post('http://httpbin.org/post', headers=headers, data={'key': 'value'}) print(response.text) 2.3 带请求头与不带请求头的区别
- 身份识别:请求头中的
User-Agent字段可以帮助服务器识别发起请求的客户端类型(如浏览器、爬虫或其他应用程序)。如果不带请求头,服务器可能无法正确处理请求,或者将请求视为不合法的访问。 - 内容协商:请求头中的
Accept字段告诉服务器客户端可以接收的内容类型。如果服务器支持多种内容类型,它将根据这个字段选择最合适的内容类型来响应。 - 数据格式:对于POST请求,请求头中的
Content-Type字段指定了发送到服务器的数据格式。例如,如果发送的是JSON数据,通常需要将Content-Type设置为application/json。 - 安全性:一些API可能要求特定的请求头来进行认证或授权。如果不带这些请求头,API可能拒绝服务。(如豆瓣)
- 自定义行为:开发者可能需要发送自定义的请求头以触发服务器端特定的行为,如缓存策略、压缩格式等。
不带请求头的请求在某些简单情况下可能仍然有效,但为了更好地控制请求行为和确保与服务器正确交互,通常建议在请求中包含适当的请求头。
3. 分析网页结构
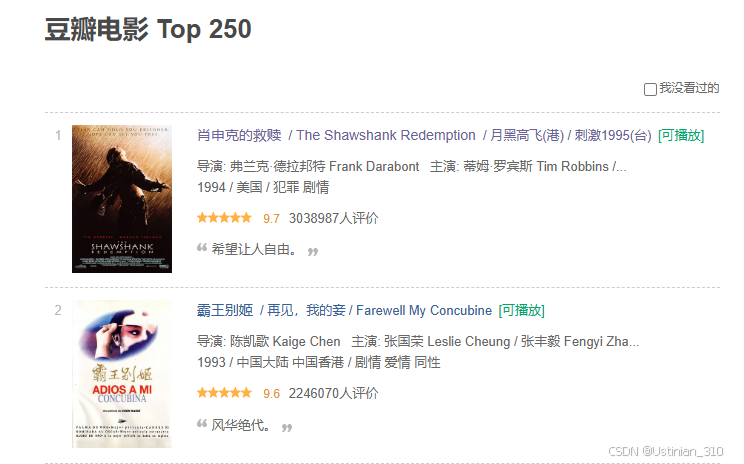
- 进入豆瓣排行榜网页后,我们右击 --> 检查 --> 元素 一栏中可以找到我们想要的信息
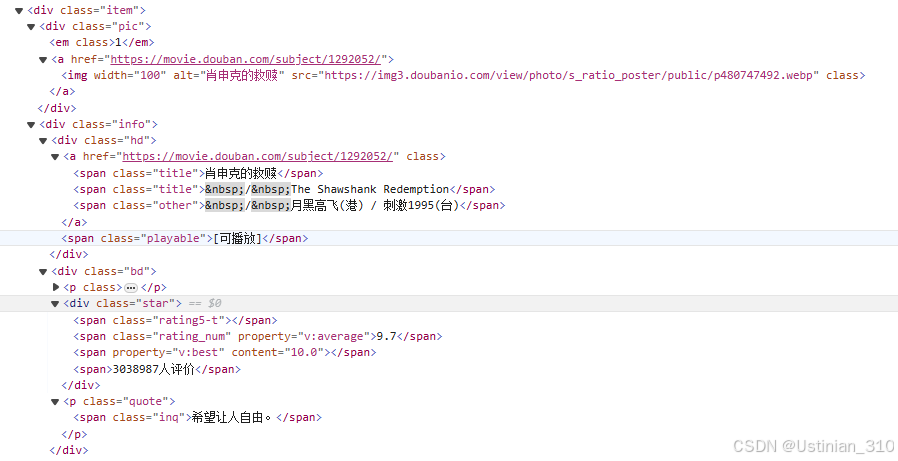
- 在这里我们可以看到,我们需要的数据都是静态数据,直接嵌入在网页源代码里,我们只需对照相应的属性名进行获取即可,在找到我们想要的数据后,就可以着手写代码了。
4. 代码实现
话不多说,我们直接上代码
import random import urllib.request from bs4 import BeautifulSoup import codecs from time import sleep """ # 爬取豆瓣 TOP250 电影名称、链接、评分及影评 """ def GetContent(url, headers): # 发送请求 page = urllib.request.Request(url, headers=headers) page = urllib.request.urlopen(page) contents = page.read() # 用BeautifulSoup解析网页 soup = BeautifulSoup(contents, "html.parser") infofile.write("") print('爬取豆瓣电影250: \n') for tag in soup.find_all(attrs={"class": "item"}): # 爬取序号 num = tag.find('em').get_text() print(num) infofile.write(num + "\r\n") # 电影名称 name = tag.find_all(attrs={"class": "title"}) zwname = name[0].get_text() print('[中文名称]', zwname) infofile.write("[中文名称]" + zwname + "\r\n") # 网页链接 url_movie = tag.find(attrs={"class": "hd"}).a urls = url_movie.attrs['href'] print('[网页链接]', urls) infofile.write("[网页链接]" + urls + "\r\n") # 爬取评分和评论数 info = tag.find(attrs={"class": "star"}).get_text() info = info.replace('\n', ' ') info = info.lstrip() comment = info print('[评分评论]', info) infofile.write("[评分评论]" + comment + "\r\n") # 获取评语 info = tag.find(attrs={"class": "inq"}) if (info): # 避免没有影评调用get_text()报错 content = info.get_text() print('[影评]', content) infofile.write(u"[影评]" + content + "\r\n") print('') if __name__ == '__main__': # 存储文件 infofile = codecs.open("../Top250_Movies.txt", 'a', 'utf-8') # 消息头 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} # 翻页 i = 0 while i < 10: print('页码', (i + 1)) num = i * 25 # 每次显示25部 URL序号按25增加 url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter=' GetContent(url, headers) sleep(5 + random.random()) infofile.write("\r\n\r\n") i = i + 1 infofile.close() 爬取结果如下,爬取完的数据存放在Top250_Movies.txt文件中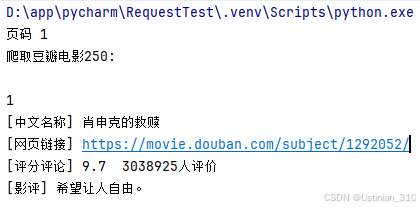
如果需要获取其他的数据,可自行扩展
