
阅读量:6

💌 所属专栏:【Python脚本随手笔记】
😀 作 者:我是夜阑的狗🐶
🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询!
💖 欢迎大家:这里是CSDN,我总结知识的地方,喜欢的话请三连,有问题请私信 😘 😘 😘
您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!🤩 🤩 🤩
文章目录
前言
大家好,又见面了,我是夜阑的狗🐶,本文是专栏【Python脚本随手笔记】专栏的第2篇文章;
今天的需求是通过 Git 获取修改的文件,针对这些文件进行单模块编译,从而加快编译速度;
专栏地址:【Python脚本随手笔记】 , 此专栏是我是夜阑的狗对python脚本处理的总结,希望能够加深自己的印象,以及帮助到其他的小伙伴😉😉。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
一、获取改动文件
要获取 Git 仓库中所有 .c 和 .h 文件的更改,可以使用 git diff 命令来比较工作区与暂存区的差异。在Python脚本中,你可以使用 subprocess 模块来运行 Git 命令并捕获其输出。再使用Python的字符串处理功能来筛选出 .c 和 .h 文件。
1.check_output()函数
这里可以使用 Python 的 subprocess 模块中的 check_output 函数;
#!/usr/bin/python3 import subprocess def get_git_c_h_file_changes(): try: # 运行 git diff 命令获取更改 output = subprocess.check_output(['git', 'diff', '--name-only']) changes = output.decode().strip().split('\n') # 筛选出以 .c 或 .h 结尾的文件 c_h_files = [file for file in changes if file.endswith(('.c', '.h'))] return c_h_files except subprocess.CalledProcessError as e: print("Error: Failed to get git changes.") return [] # 调用函数获取更改的 .c 和 .h 文件列表 changed_c_h_files = get_git_c_h_file_changes() # 打印更改的 .c 和 .h 文件列表 for file in changed_c_h_files: print(file) 在上面的代码中,get_git_changes() 函数使用 subprocess.check_output() 函数运行 git diff --name-only 命令,并捕获其输出。然后,通过解码输出并按行拆分,将更改的文件路径存储在 changes 列表中。最后,返回该列表。
注意:在运行这段代码之前,确保你在一个Git仓库目录下,并且有未提交的更改或已暂存的更改。
二、获取文件目录
在工程中,有些改动文件的当下目录可以会没有 .gn 文件,有可能在上级目录或者上上级目录,这里为了最大可能检索到 .gn,当前目录检索不到 .gn 文件时,将向上级目录进行查询。可以使用 Python 的 os.path 模块来操作文件路径,从而获取当前文件的目录的上级目录和上上级目录。
1.dirname()函数
import os current_directory = os.getcwd() # 获取当前文件的目录 # 上级目录 parent_directory = os.path.dirname(current_directory) print(f"上级目录: {parent_directory}") # 上上级目录 grandparent_directory = os.path.dirname(parent_directory) print(f"上上级目录: {grandparent_directory}") 三、获取GN文件
由前面提供查询的目录路径,要查询当前文件的目录中是否存在以 .gn 为后缀的文件,你可以使用 Python 的 glob 模块来实现。glob模块提供了一个函数 glob.glob() ,可以用来查找符合特定模式的文件。
1.glob()函数
import glob import os current_directory = os.getcwd() # 获取当前文件的目录 pattern = os.path.join(current_directory, '*.gn') # 匹配后缀为.gn的文件 gn_files = glob.glob(pattern) if gn_files: print("current directory exist .gn:") for file in gn_files: print(file) else: print("current directory not exist .gn") 在这段代码中,我们首先构建了一个匹配后缀为 .gn 的文件路径模式,然后使用 glob.glob() 函数查找匹配的文件。如果找到符合条件的文件,则打印出文件路径;否则打印提示信息表示未找到符合条件的文件。
四、读取检索gn文件
检索到 .gn 文件之后,需要查询 .gn 里面的参与编译的组名,这里主要搜索"hdf_driver",“group”, "kernel_module"这几个关键字的组名中双引号或者单引号里面的内容,可以使用正则表达式来匹配行内容并提取引号内的内容。
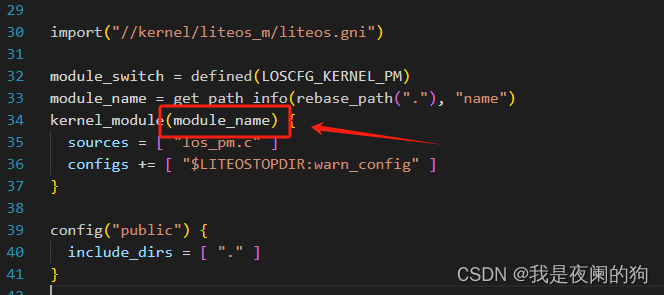
1.search()函数
import re def find_strings_with_keywords(build_gn_file_path): file_open_switch = 1 match = False gn_file_path = "" # pattern = '|'.join(map(re.escape, keywords)) # print(f"pattern: {pattern}") try: for file_path in build_gn_file_path: gn_file_path = file_path with open(file_path, 'r') as file: for line in file: # 使用 re.search() 检查字符串中是否包含任一关键字 match_line = re.search("hdf_driver|group|kernel_module", line) if match_line: # 使用正则表达式匹配引号内的内容 match = re.search(r"[(](.*?)[)]", line) # 调用函数退出所有循环 raise StopIteration except StopIteration: pass # 捕获异常并忽略 if match: return [remove_quotes(match.group(1)), gn_file_path] else: return ["ERROR"] # 传入gn文件路径和目标关键词列表,查找匹配的字符串 gn_file_path = 'path/to/your/gn/file.gn' matching_strings = find_strings_with_keywords(gn_file_path) # 打印匹配的字符串 for string in matching_strings: print(string) 在上面的代码中,find_strings_with_keywords() 函数接收一个 gn 文件的路径和目标关键词列表作为参数。它将尝试打开该文件,并逐行读取文件内容。对于每一行,它会使用正则表达式匹配目标关键词,并提取双引号或单引号之间的内容。如果匹配成功,则将其添加到matching_strings列表中。
该函数通过抛出 StopIteration 异常来实现退出所有循环。然后,我们在外层使用 try-except 块来捕获异常并忽略。
2.sub()函数
在获取组名之后,还需要去除组名的双引号或者单引号。想要移除字符串中的双引号和单引号,可以使用正则表达式的 sub() 方法来替换这些引号。
import re def remove_quotes(string): # 使用正则表达式替换双引号和单引号为空字符串 new_string = re.sub(r'[\'"]', '', string) return new_string # 测试示例 string1 = 'This is a "quoted" string.' new_string1 = remove_quotes(string1) print(new_string1) string2 = "Another 'quoted' string." new_string2 = remove_quotes(string2) print(new_string2) 在上面的代码中,remove_quotes() 函数接收一个字符串作为参数。它使用正则表达式 ['"] 来匹配双引号和单引号,并使用 re.sub() 方法将其替换为空字符串,生成一个新的字符串。
到这里就能拿到基于改动文件的gn编译组名,后面可根据该组名对项目进行单目标编译了,下篇即将讲解整个过程。
总结
感谢观看,如果有帮助到你,请给文章点个赞和收藏,让更多的人看到。🌹 🌹 🌹

也欢迎你,关注我。👍 👍 👍
原创不易,还希望各位大佬支持一下,你们的点赞、收藏和留言对我真的很重要!!!💕 💕 💕 最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
更多专栏订阅:
- 😀 【LeetCode题解(持续更新中)】
- 👑 【Python脚本笔记】
- 🚝 【Java Web项目构建过程】
- 💛 【数字图像处理】
- ⚽ 【JavaScript随手笔记】
- 🤩 【大数据学习笔记(华为云)】
- 🦄 【程序错误解决方法(建议收藏)】
- 🚀 【软件安装教程】
订阅更多,你们将会看到更多的优质内容!!
