阅读量:3
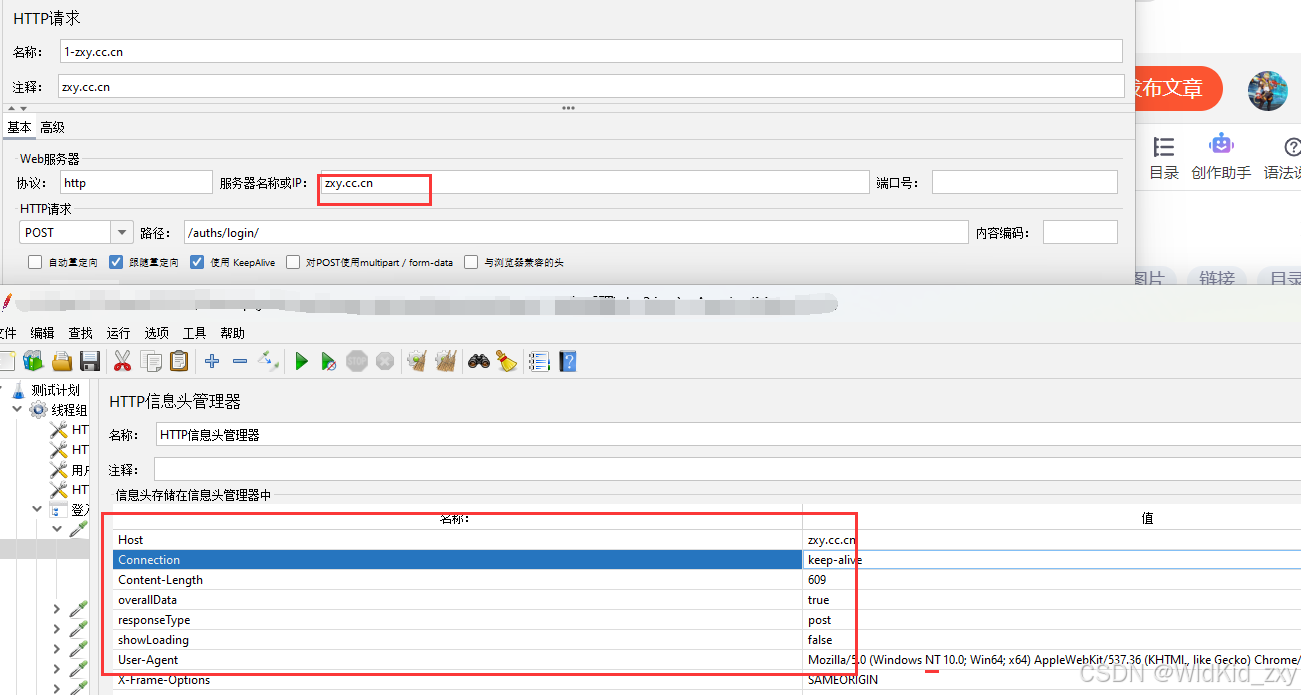
解决fidder小黑怪倒出JMeter文件缺失域名、请求头
1、目录结构:
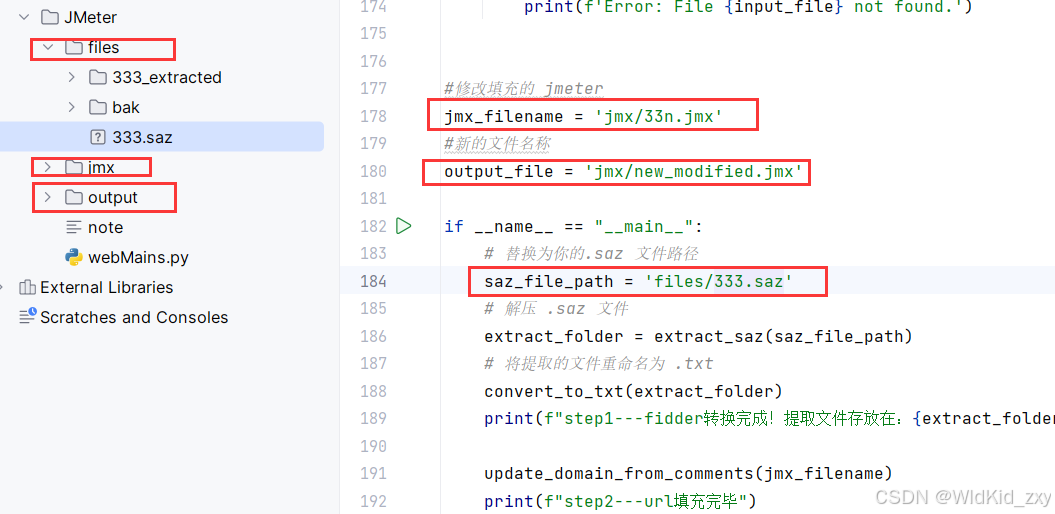
2、代码
''' coding:utf-8 @Software:PyCharm @Time:2024/7/10 14:02 @Author:Dr.zxy ''' import zipfile import os import xml.etree.ElementTree as ET import re #定义信息头 headers_to_extract = [ 'Host', 'Connection', 'Content-Length', 'apiversion', 'apicode', 'User-Agent', 'format', 'content-type', 'accept', 'pagecode', 'x-secure-opt-log', 'appcode', 'Origin', 'Referer', 'Accept-Language', 'Accept-Encoding', 'Cookie' ] # 定义函数解压 .saz 文件 def extract_saz(saz_file): # 创建一个目录来存放解压后的内容 extract_folder = saz_file.replace('.saz', '_extracted') os.makedirs(extract_folder, exist_ok=True) # 打开 saz 文件 with zipfile.ZipFile(saz_file, 'r') as zip_ref: # 解压所有文件到 extract_folder zip_ref.extractall(extract_folder) return extract_folder # 定义函数将提取的文件重命名为 .txt def convert_to_txt(extract_folder): # 遍历提取的文件夹中的所有文件 for root, _, files in os.walk(extract_folder): for file in files: # 如果文件不是 .txt 文件,则重命名为 .txt if not file.endswith('.txt'): original_path = os.path.join(root, file) new_path = os.path.join(root, os.path.splitext(file)[0] + '.txt') os.rename(original_path, new_path) #url填充 def update_domain_from_comments(xml_file): #加载文件 tree = ET.parse(xml_file) root = tree.getroot() for sampler in root.findall('.//HTTPSamplerProxy'): testplan_comments = sampler.find(".//stringProp[@name='TestPlan.comments']") if testplan_comments is not None: domain_value = testplan_comments.text domain_prop = sampler.find(".//stringProp[@name='HTTPSampler.domain']") if domain_prop is not None: domain_prop.text = domain_value tree.write(xml_file, encoding='utf-8', xml_declaration=True) #信息头添加序号 def update_testname(filename): tree = ET.parse(filename) root = tree.getroot() header_managers = root.findall('.//HeaderManager') for idx, header_manager in enumerate(header_managers): # 信息头管理器添加序号 001 002 new_testname = f'{idx:03}-HTTP信息头管理器' # {:03} 确保3位数字的前导为零 header_manager.set('testname', new_testname) # 写到Jmeter文件 tree.write(filename, encoding='utf-8', xml_declaration=True) # 读取文件内容 with open(filename, 'r', encoding='utf-8') as file: content = file.read() # 定义要删除的 XML 片段 pattern = r'<HeaderManager guiclass="HeaderPanel" testclass="HeaderManager" testname="000-HTTP信息头管理器" enabled="true">.*?</HeaderManager>\s*<hashTree\s*/>' # 使用正则表达式删除匹配的部分 new_content = re.sub(pattern, '', content, flags=re.DOTALL) # 将修改后的内容写回文件 with open(filename, 'w', encoding='utf-8') as file: file.write(new_content) # 从文件中读取头并转换为JMeter Header Manager格式的函数 def convert_to_jmeter_xml(directory, headers_to_extract): # 遍历目录中的文件 for filename in os.listdir(directory): if filename.endswith("_c.txt"): file_path = os.path.join(directory, filename) #提取下划线前的数值 numeric_value = filename.split('_')[0].zfill(3) # 处理文件以提取标头 headers = {} with open(file_path, 'r', encoding='utf-8') as file: content = file.read() for header in headers_to_extract: match = re.search(rf'^{header}: (.+)$', content, flags=re.MULTILINE) if match: headers[header] = match.group(1) # 生成JMeter标头管理器XML header_xml = '' for header, value in headers.items(): header_xml += f''' <elementProp name="" elementType="Header"> <stringProp name="Header.name">{header}</stringProp> <stringProp name="Header.value">{value}</stringProp> </elementProp>''' # 包裹式格式 jmeter_xml = f''' <HeaderManager guiclass="HeaderPanel" testclass="HeaderManager" testname="{numeric_value}-HTTP信息头管理器" enabled="true"> <collectionProp name="HeaderManager.headers">{header_xml} </collectionProp> </HeaderManager>''' # 将JMeter XML内容写入新文件 output_filename = f'{numeric_value}_jmeter.xml' output_path = os.path.join(directory, output_filename) with open(output_path, 'w', encoding='utf-8') as output_file: output_file.write(jmeter_xml) #print(f'Converted {filename} to {output_filename}') # 第一步:遍历所有的<HeaderManager>标签,提取testname属性中'-'前的值 def extract_testnames(filename): testnames = [] tree = ET.parse(filename) root = tree.getroot() for header_manager in root.findall('.//HeaderManager'): testname = header_manager.get('testname', '') if '-' in testname: testnames.append(testname.split('-')[0]) return testnames # 第二步:读取替换目标文件的内容 def read_file_content(filename): with open(filename, 'r', encoding='utf-8') as file: content = file.read() return content # 第三步:替换<HeaderManager>标签节点的内容为指定文件的内容 def replace_header_manager_content(filename, testname, replacement_content): # 解析 XML 文件 tree = ET.parse(filename) root = tree.getroot() # 查找所有 <HeaderManager> 节点 for header_manager in root.findall('.//HeaderManager'): # 检查 testname 属性是否以指定的 testname 开头 if header_manager.get('testname', '').startswith(testname): # 清空 <HeaderManager> 节点的内容 header_manager.clear() # 设置新的内容 header_manager.text = replacement_content # 保存修改后的 XML 文件 tree.write(filename, encoding='utf-8', xml_declaration=True) def modify_jmx_file(input_file, output_file): try: # 读取原始文件内容 with open(input_file, 'r', encoding='utf-8') as f: content = f.read() # 替换操作 content = content.replace('<HeaderManager>', '') content = content.replace('</HeaderManager>', '') content = content.replace('<', '<') content = content.replace('>', '>') # 写入修改后的内容到目标文件 with open(output_file, 'w', encoding='utf-8') as f: f.write(content) #print(f'文件处理完成,修改后的文件保存为 {output_file}') except FileNotFoundError: print(f'Error: File {input_file} not found.') #修改填充的 jmeter jmx_filename = 'jmx/33n.jmx' #新的文件名称 output_file = 'jmx/new_modified.jmx' if __name__ == "__main__": # 替换为你的.saz 文件路径 saz_file_path = 'files/333.saz' # 解压 .saz 文件 extract_folder = extract_saz(saz_file_path) # 将提取的文件重命名为 .txt convert_to_txt(extract_folder) print(f"step1---fidder转换完成!提取文件存放在:{extract_folder}") update_domain_from_comments(jmx_filename) print(f"step2---url填充完毕") update_testname(jmx_filename) print(f"step3---信息头管理器【序号】添加完成") convert_to_jmeter_xml(extract_folder+"/raw", headers_to_extract) print(f"step4---信息头管理器【新节点·生成】生成完成") # 第一步:提取所有testname中'-'前的值 testnames = extract_testnames(jmx_filename) # 第二步和第三步:针对每个testname,读取对应的XML文件并替换内容 for testname in testnames: xml_filename = os.path.join(extract_folder+"/raw/", f'{testname}_jmeter.xml') if os.path.exists(xml_filename): replacement_content = read_file_content(xml_filename) replace_header_manager_content(jmx_filename, testname, replacement_content) else: print(f"Warning: File {xml_filename} not found.") print(f"step5---信息头管理器【新节点·替换】完成") modify_jmx_file(jmx_filename, output_file) print(f"step6---信息头管理器【新节点·替换清洗】完成") 3、注意事项
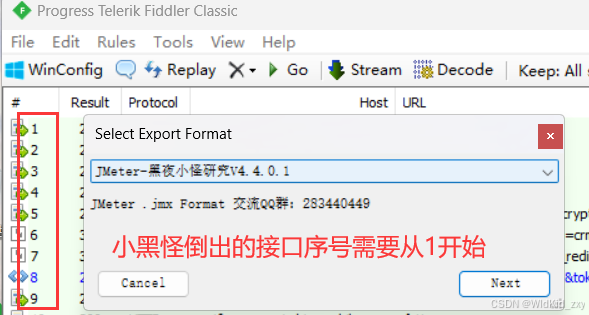
4、结果