
阅读量:2
因为官方给的"opengym""opengym-2"这两个例子都很简单,所以自己改了一个demo,把reward-action-state相互影响的关系表现出来
一、准备工作
在ns3.35/scratch目录下创建一个文件夹:
(后续的运行指令后面都需要转移到这个文件夹路径下)
二、主要思路
- Action:离散空间[0,1,2,3],使用ε-贪心策略选择
- ExecuteActions:赋值x=action
- Obs\State:基于action定义一组数,关于x的线性函数
- Reward:对state中的所有数据进行处理,取平均数得到r
PS.发现一个问题,这个框架如果脱离了具体的网络环境其实并不好定义,因为这些要素相互依赖的关系非常抽象,尤其是state是通过全网状态搜集得到的,在这里没有定义具体的网络环境,所以暂时用全局变量来表示一下这种隐性关系
三、关键实现步骤
mygym.cc(定义了存储决策和状态的全局变量,增加了收集状态、执行动作、计算奖励的函数)
①全局变量
static float deci = 0.0; // 全局变量,用于存储决策 std::vector<float> state;// 全局变量,用于存储状态②创建状态空间(只是初始化一个容器,定义好维度就行)
//初始化一般不用大改,建立一个存储空间就行 Ptr<OpenGymSpace> MyGymEnv::GetObservationSpace() { uint32_t nodeNum = 8; float low = 0.0; float high = 100.0; std::vector<uint32_t> shape = {nodeNum,}; std::string dtype = TypeNameGet<uint32_t> (); Ptr<OpenGymBoxSpace> space = CreateObject<OpenGymBoxSpace>(low, high, shape, dtype); NS_LOG_UNCOND ("MyGetObservationSpace: " << space); return space; }③创建动作空间(离散)
// 离散空间[0,1,2,3] Ptr<OpenGymSpace> MyGymEnv::GetActionSpace() { uint32_t nodeNum = 4; Ptr<OpenGymDiscreteSpace> space = CreateObject<OpenGymDiscreteSpace> (nodeNum); NS_LOG_UNCOND ("MyGetActionSpace: " << space); return space; }④执行选定的动作
// action存储到全局变量deci bool MyGymEnv::ExecuteActions(Ptr<OpenGymDataContainer> action) { Ptr<OpenGymDiscreteContainer> discrete = DynamicCast<OpenGymDiscreteContainer>(action); NS_LOG_UNCOND ("MyExecuteActions: " << action); deci = discrete->GetValue(); return true; }⑤收集网络状态
Ptr<OpenGymDataContainer> MyGymEnv::GetObservation() { uint32_t nodeNum = 8; std::vector<uint32_t> shape = {nodeNum,}; Ptr<OpenGymBoxContainer<uint32_t> > box = CreateObject<OpenGymBoxContainer<uint32_t> >(shape); for (uint32_t i=0;i<nodeNum;i++){ uint32_t value = GetValue(i); box->AddValue(value); } } // 将 box 的值放入全局变量 state state.clear(); for (uint32_t i = 0; i < nodeNum; i++) { state.push_back(box->GetValue(i)); // 获取 box 中的值并添加到 state 中 } NS_LOG_UNCOND ("MyGetObservation: " << box); return box; }// 搜集网络状态的函数 float MyGymEnv::GetValue(uint32_t index) { float value = deci*index; return value; }⑥根据状态计算奖励
// 对state进行处理 float MyGymEnv::GetAverage( std::vector<float> state) { uint32_t sum = 0; for (uint32_t value : state) { sum += value; } return static_cast<double>(sum) / state.size(); } /* Define reward function */ float MyGymEnv::GetReward() { float reward = GetAverage(state); NS_LOG_UNCOND ("MyGetReward: " << reward); return reward; }mygym.h(声明全局变量,添加自定义函数到private类)
extern std::vector<float> state;// 全局变量,用于存储状态private: void ScheduleNextStateRead(); float GetValue(uint32_t index); float GetAverage( std::vector<float> state);sim.cc(这一块没有什么要改的,注意总仿真时间和仿真次数的关系,相当于实际的step受到两个地方的参数影响,另一个在创建环境时定义的isGameOver函数中)
double simulationTime = 3; //seconds, 控制仿真次数的位置2 double envStepTime = 0.1; //seconds, ns3gym env step time intervaltest.py(这里主要的改动是使用了ε-贪心策略)
# Choose action if np.random.rand( ) < epsilon: action = env.action_space.sample() print("random") else: for action in range(env.action_space.n):#离散动作空间的定义 Q_value = estimate(action,ob_space) if Q_value > best_value: best_value = Q_value best_action = action action = best_action print("maximum Q")简单模拟了一下Q值的估计(基于action估计reward)
def estimate(action,ob_space): state = [] for i in range(ob_space.shape[0]):{ state.append(action * i) } reward = np.mean(state) Q_value =reward return Q_value简单运行了一下:
ns3端: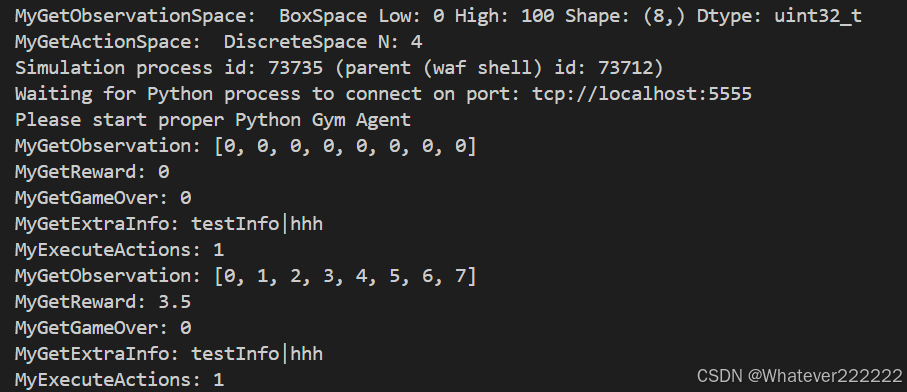
python端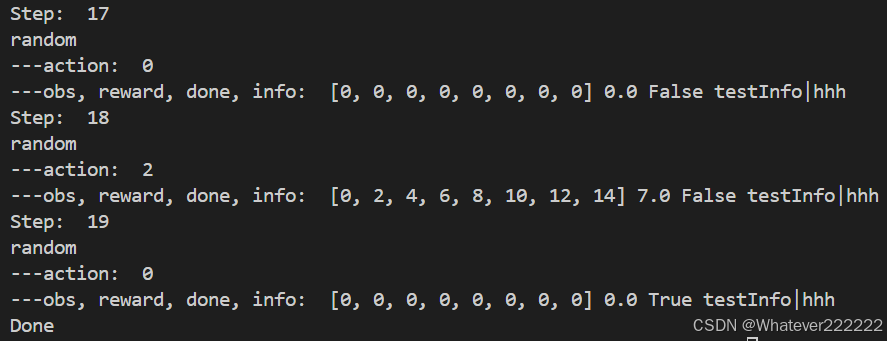
PS.要注意ns3-gym传递的数据类型可能无法直接用len()等函数,要去查看定义的具体数据类型
这个demo只是先按照我的理解大致实现了各个环节的衔接,但是reward对action的调整作用还没有体现出来,强化学习的精髓还没有融合进去,还有一些细节问题可能没有发现,下一个demo见
