
阅读量:18
AGI 之 【Hugging Face】 的【问答系统】的 [构建问答系统] / [ 构建基于评论的问答系统 ] 的简单整理
目录
AGI 之 【Hugging Face】 的【问答系统】的 [构建问答系统] / [ 构建基于评论的问答系统 ] 的简单整理
一、简单介绍
AGI,即通用人工智能(Artificial General Intelligence),是一种具备人类智能水平的人工智能系统。它不仅能够执行特定的任务,而且能够理解、学习和应用知识于广泛的问题解决中,具有较高的自主性和适应性。AGI的能力包括但不限于自我学习、自我改进、自我调整,并能在没有人为干预的情况下解决各种复杂问题。
- AGI能做的事情非常广泛:
跨领域任务执行:AGI能够处理多领域的任务,不受限于特定应用场景。
自主学习与适应:AGI能够从经验中学习,并适应新环境和新情境。
创造性思考:AGI能够进行创新思维,提出新的解决方案。
社会交互:AGI能够与人类进行复杂的社会交互,理解情感和社会信号。
- 关于AGI的未来发展前景,它被认为是人工智能研究的最终目标之一,具有巨大的变革潜力:
技术创新:随着机器学习、神经网络等技术的进步,AGI的实现可能会越来越接近。
跨学科整合:实现AGI需要整合计算机科学、神经科学、心理学等多个学科的知识。
伦理和社会考量:AGI的发展需要考虑隐私、安全和就业等伦理和社会问题。
增强学习和自适应能力:未来的AGI系统可能利用先进的算法,从环境中学习并优化行为。
多模态交互:AGI将具备多种感知和交互方式,与人类和其他系统交互。
Hugging Face作为当前全球最受欢迎的开源机器学习社区和平台之一,在AGI时代扮演着重要角色。它提供了丰富的预训练模型和数据集资源,推动了机器学习领域的发展。Hugging Face的特点在于易用性和开放性,通过其Transformers库,为用户提供了方便的模型处理文本的方式。随着AI技术的发展,Hugging Face社区将继续发挥重要作用,推动AI技术的发展和应用,尤其是在多模态AI技术发展方面,Hugging Face社区将扩展其模型和数据集的多样性,包括图像、音频和视频等多模态数据。
- 在AGI时代,Hugging Face可能会通过以下方式发挥作用:
模型共享:作为模型共享的平台,Hugging Face将继续促进先进的AGI模型的共享和协作。
开源生态:Hugging Face的开源生态将有助于加速AGI技术的发展和创新。
工具和服务:提供丰富的工具和服务,支持开发者和研究者在AGI领域的研究和应用。
伦理和社会责任:Hugging Face注重AI伦理,将推动负责任的AGI模型开发和应用,确保技术进步同时符合伦理标准。
AGI作为未来人工智能的高级形态,具有广泛的应用前景,而Hugging Face作为开源社区,将在推动AGI的发展和应用中扮演关键角色。
(注意:以下代码运行,可能需要科学上网)
二、构建问答系统
无论你是研究人员、分析师还是数据科学家,都很有可能需要在浩如烟海的文档中跋山涉水才能找到你所需要的信息。最让人感到崩溃的是,在使用Google或者Bing搜索引擎的时候,它们还不断提醒你,还有更好的搜索方法。例如,使用Google搜索:玛丽·居里什么时候获得她的第一个诺贝尔奖?可以立即得到正确答案:1903,如图下图所示。
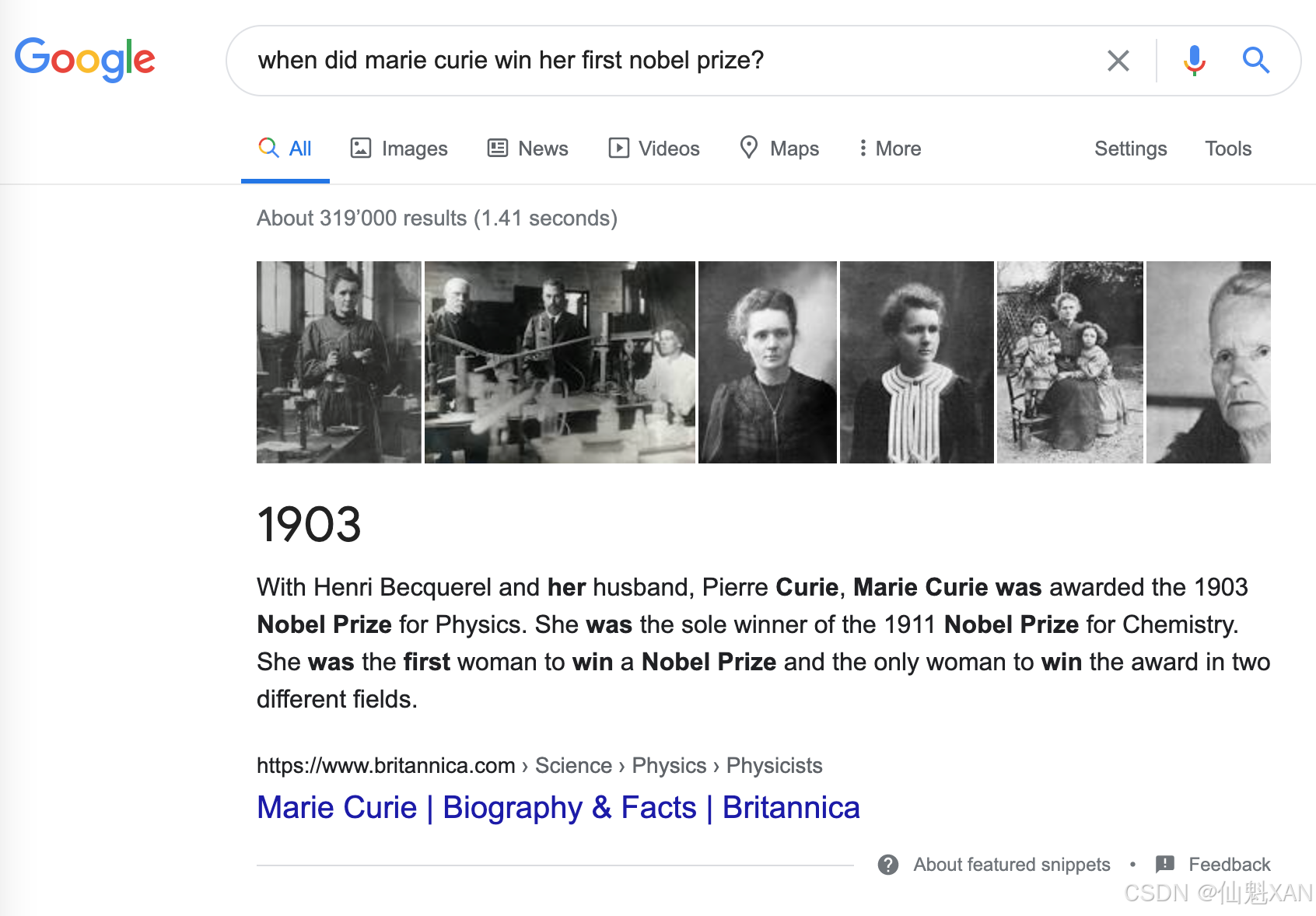
虽然在这种情况下,每个人都知道DropC是最好的吉他调音方式。
在这个例子中,Google首先检索出了大约319 000个与查询信息相关的文档,然后执行了另一个处理步骤,即从这些文档中提取出带有相应段落和网页的答案片段。所以,搜索引擎的每条搜索结果看起来似乎对你都很有用。再比如,使用Google搜索一个稍微棘手的问题:“哪种吉他调音最好?”这次并没有直接显示出答案片段,而是需要点击搜索引擎推荐的网页链接,跳转到各个网站中才能找到我们想要的答案。
这项技术背后的方法被称为问答系统,问答系统有各种各样的类型,但最为常见的是提取式问答系统,它将所涉问题的答案识别为文档中的一小段文本,这里的文档可以是网页、法律合同或新闻文章。这种先查到相关文档,然后再从中提取答案的两阶段处理方式,是许多现代问答系统的理论基础,像语义搜索引擎、智能助手或者自动信息提取器,都是基于这种理论来构建的。在本节中,我们将使用这种处理方式来解决电商网站所面临的一个常见问题:帮助消费者解答特定问题,帮助其了解一个商品。在这个场景中,把用户的评论当作问答系统的文本数据源,在此过程中,我们将了解到Transformer模型如何作为强大的阅读理解工具,来从文本中提取有价值的信息。
- 什么是问答系统?
问答系统(Question Answering, QA)是一种自然语言处理(NLP)任务,旨在从给定的文本或知识库中找到问题的答案。这些系统可以分为以下几种类型:
- 开放域问答系统:能够回答关于广泛主题的问题,通常需要从大量未结构化数据中提取答案。
- 封闭域问答系统:专注于特定领域内的问题,通常基于领域特定的知识库。
- 基于文本的问答系统:直接从给定的文本(如一段文章)中提取答案。
- 知识库问答系统:从结构化的知识库(如数据库)中检索答案。
- 问答系统的实现方式
构建问答系统有多种方法,每种方法都有其优缺点。以下是一些常见的实现方式:
- 1. 基于规则的方法
这种方法依赖于预定义的规则和模板来匹配问题并从文本中提取答案。这种方法适用于简单且格式固定的问答任务,但在处理复杂和多变的问题时效果不佳。
- 2. 基于信息检索的方法
这类系统首先使用信息检索技术找到与问题相关的文档,然后从这些文档中提取答案。典型的步骤包括:
- 文档检索:从大型文档库中找到最相关的文档。
- 段落检索:从相关文档中找到最相关的段落。
- 答案提取:从相关段落中提取答案。
- 3. 基于深度学习的方法
深度学习方法已经显著提高了问答系统的性能。常见的模型包括:
- BERT(Bidirectional Encoder Representations from Transformers):一个双向Transformer模型,可以理解上下文并从中提取答案。
- RoBERTa(Robustly optimized BERT approach):BERT的改进版,性能更强。
- DistilBERT:BERT的轻量级版本,计算效率更高。
这些模型通常在大型问答数据集(如SQuAD)上进行预训练,然后在特定任务上进行微调。
- 基于深度学习的问答系统构建步骤
以下是使用Hugging Face的Transformers库构建基于深度学习的问答系统的步骤:
- 1. 安装库
pip install transformers torch
- 2. 加载预训练模型和Tokenizer
from transformers import AutoTokenizer, AutoModelForQuestionAnswering # 加载预训练的BERT模型和tokenizer tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad") model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
- 3. 编写问答函数
import torch def answer_question(question, context): inputs = tokenizer.encode_plus(question, context, return_tensors="pt") input_ids = inputs["input_ids"].tolist()[0] outputs = model(**inputs) answer_start_scores = outputs.start_logits answer_end_scores = outputs.end_logits # 获取答案的开始和结束位置 answer_start = torch.argmax(answer_start_scores) answer_end = torch.argmax(answer_end_scores) + 1 # 将答案token转换为字符串 answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])) return answer
- 4. 测试问答系统
context = "Hugging Face 是一个开源社区,专注于自然语言处理技术。" question = "Hugging Face 是什么?" answer = answer_question(question, context) print(f"Question: {question}") print(f"Answer: {answer}")
本节着重介绍提取式问答,不同场景适用的问答形式也不同。比如,技术社区的问答系统收集的是用户在Stack Overflow(https://stackoverflow.com)等技术论坛上的问答对,然后使用语义相似度搜索来找到与新问题最匹配的答案。还有开放域长格式(long-form)问答,旨在为诸如“为什么天空是蓝色的?”之类的开放性问题生成复杂的长文本答案。另外还可以针对表格,像TAPAS(https://oreil.ly/vVPWO)这种Transformer模型能为表格生成聚合操作语句,来获取相关信息。
三、构建基于评论的问答系统
如果你在电商网站买过商品,那你很有可能参考过其他人对该商品的评论,来帮助你做出是否下单的决定。这里的评论是指回答“这把吉他有背带吗?”或者“这台相机可以在晚上使用吗?”这类的具体问题,不是那种对商品的描述性评论,仅从描述性评论很难获取这种具体问题的答案。因为一般的热门商品都有成千上万条描述性评论,所以要从中找到与某个确切问题相关的评论是一件很难的事。有一种替代方法倒是可以直接获取答案,那就是在Amazon这种电商网站提供的社交问答平台上发布问题,不过这种方法的时效性很难保证,一般要在几天后才能得到答案,甚至更久。那么有什么方法能像上图中Google搜索示例一样,又快又准确地获取答案呢?下面就让我们来看看Transformer是如何做到的。
1、准备数据集
J. Bjerva et al., “SubjQA:A Dataset for Subjectivity and Review Comprehension”(https://arxiv.org/abs/2004.14283),(2020).
不久之后我们会看到,会有一些根本无法回答的问题出现,旨在生成更健壮的模型。
本书使用SubjQA数据集 来构建问答系统,该数据集包含10 000多条关于商品和服务的英文用户评论,涉及六个领域:旅行社、餐厅、电影、书籍、电子产品和杂货店。如图7-2所示,每条数据都包含一个问题和一个评论,评论里面会有一个或多个词条可以准确回答该问题 。
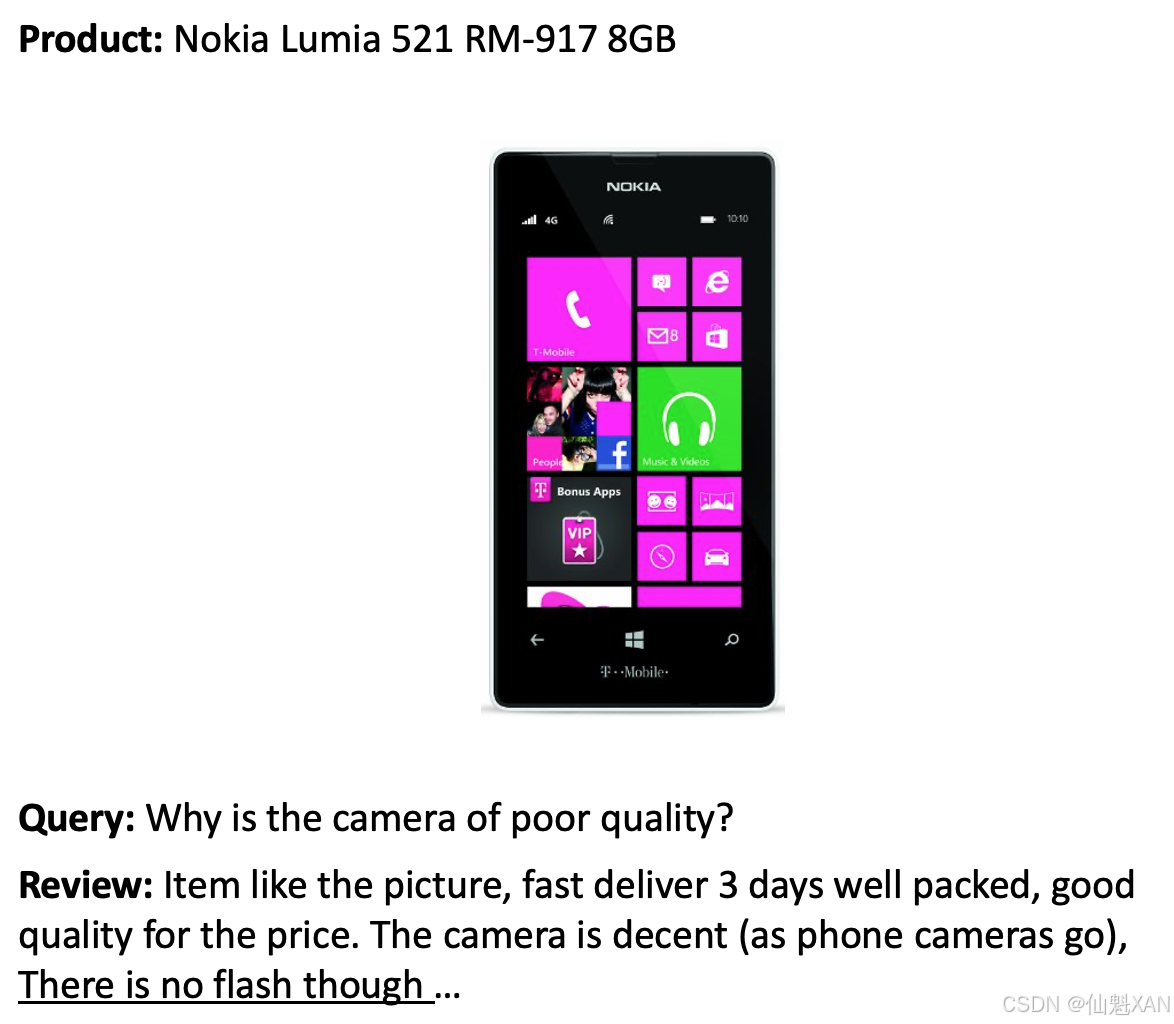
SubjQA数据集的有趣之处在于,它其中的大多数问题和答案都是偏向主观的,也就是说,它们取决于用户的个人体验。从上图中可以看出,回答这种主观性的问题,要比回答“英国的货币是什么?”这种事实类问题要难得多。首先,“品质低劣”(poor quality)是一个主观性的词汇,完全取决于用户自身对于品质的定义;其次,可用于检索的关键词也没有出现在评论中,这样就无法使用关键词搜索来获取答案了。而上图中的内容完全有可能在现实世界里遇到,因此这个数据集是比较贴近现实情况的。由于这个特性,就可以将SubjQA数据集作为一个反映了客观世界真实情况的测试集来对我们的问答模型进行基准测试,这样得出的结果也更具备说服力。
问答系统通常根据它们在响应查询时可以访问的数据域进行分类,封闭域问答系统(Closed-Domain QA,CDQA)处理窄域问题(例如,单个商品类别),而开放域问答系统(Open-Domain QA,ODQA)几乎可以处理所有问题(例如,Amazon电商网站的整个商品目录),并且能够仅仅依赖通用知识本体和世界知识。封闭域问答系统涉及搜索的文档数量一般少于开放域问答系统。
首先,我们从Hugging Face Hub(https://oreil.ly/iO0s5)下载数据集,像在之前介绍的那样操作,使用get dataset config names()函数来从下载的多域数据集中找出可用的数据子集:
# 从datasets库中导入get_dataset_config_names函数 from datasets import get_dataset_config_names # 使用get_dataset_config_names函数获取名为"subjqa"的数据集的所有配置名称 # "subjqa" 是一个主观问答数据集,包含来自不同领域的问答对 domains = get_dataset_config_names("subjqa",trust_remote_code=True) # 打印获取到的配置名称,这些配置名称表示数据集中不同领域的子集 # 例如,"books", "electronics", "grocery" 等 print(domains)运行结果:
['books', 'electronics', 'grocery', 'movies', 'restaurants', 'tripadvisor']
本次示例将专注为电子领域(上面的electronics)构建问答系统。在确定了领域之后,便要开始加载electronics数据子集,我们将该值传给load_dataset()函数的name参数即可:
# 从datasets库中导入load_dataset函数 from datasets import load_dataset # 使用load_dataset函数加载名为"subjqa"的数据集,并指定领域为"electronics" # 这里的"name"参数指定了数据集的具体配置,即我们只加载与电子产品相关的问答数据 subjqa = load_dataset("subjqa", name="electronics") # 打印加载的数据集的基本信息,通常包括训练集(train)、验证集(validation)和测试集(test)等 print(subjqa) 运行结果:

DatasetDict({ train: Dataset({ features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'], num_rows: 1295 }) test: Dataset({ features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'], num_rows: 358 }) validation: Dataset({ features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'], num_rows: 255 }) }) 与Hugging Face Hub上的其他问答类数据集一样,SubjQA数据集将每个问题与对应的答案存储为嵌套字典结构。比如我们查看answers列中的其中一行:
# 打印训练集中第二个问答对的答案 # "subjqa['train']" 访问训练集,"subjqa['train']['answers']" 访问训练集中所有问答对的答案 # "[1]" 访问第二个问答对的答案,因为索引从0开始 print(subjqa["train"]["answers"][1])运行结果:
{'text': ['Bass is weak as expected', 'Bass is weak as expected, even with EQ adjusted up'], 'answer_start': [1302, 1302], 'answer_subj_level': [1, 1], 'ans_subj_score': [0.5083333253860474, 0.5083333253860474], 'is_ans_subjective': [True, True]} 我们可以看到答案存储在text字段中,answer_start字段则提供答案字符的起始索引。为了更加直观地查看数据集,可以使用flatten()方法展平这些嵌套列,并将每个拆分单元转换为Pandas的DataFrame实例:
# 从pandas库中导入pandas,并命名为pd import pandas as pd # 将subjqa数据集中每个分割(例如,训练集、验证集和测试集)转换为pandas DataFrame,并存储在一个字典中 # subjqa.flatten() 用于将嵌套的数据结构展平,确保每个数据集都可以被转换 dfs = {split: dset.to_pandas() for split, dset in subjqa.flatten().items()} # 遍历字典中的每个分割和对应的DataFrame for split, df in dfs.items(): # 打印每个分割(例如,train、validation、test)中唯一问题的数量 # 通过计算DataFrame中'id'列的唯一值数量来实现 print(f"Number of questions in {split}: {df['id'].nunique()}") 运行结果:
Number of questions in train: 1295 Number of questions in test: 358 Number of questions in validation: 255
D. Hendrycks et al., “CUAD:An Expert-AnnotatedNLPDataset for Legal Contract Review”(https://arxiv.org/abs/2103.06268),(2021).
从结果可以看出,这个electronics数据子集相对较小,只有1908个样本。这其实也反映这个领域的现实情况,因为让领域专家来标注提取式问答数据集将会花费不菲。例如,用于法律合同领域提取问答对的CUAD数据集价值大约200万美元,因为标注其中的13 000个案例 需要非常专业的法律知识才能完成。
SubjQA数据集中有许多的列,但最有趣的不是这些数据本身,而是使用它们构建问答系统,如下表所示:

下面我们来看一些训练样本,使用sample()方法来选择一个随机样本:
# 定义一个包含感兴趣的列名的列表 # 这些列名包括标题、问题、答案文本、答案开始位置和上下文 qa_cols = ["title", "question", "answers.text", "answers.answer_start", "context"] # 从训练数据集中提取包含这些列的一个样本DataFrame # 使用sample方法随机抽取2行数据,random_state=7确保结果可重复 sample_df = dfs["train"][qa_cols].sample(2, random_state=7) # 打印样本DataFrame,显示提取的样本问答数据 print(sample_df) 运行结果:

从样本中可以看出一些特点,首先,样本中的问题question在语法上有些问题,这在电商网站的FAQ中比较常见的,因为都是真人写的;其次,如果answers.text为空,表示在评论中无法找到答案,当前问题对当前评论而言是没有答案的;最后,可以使用答案片段的起始索引和长度来从评论中切分出答案所对应的文本范围:
# 获取sample_df中第一行的答案开始位置 # .iloc[0] 获取DataFrame的第一行 # [0] 获取答案开始位置的第一个值,因为答案开始位置是一个列表 start_idx = sample_df["answers.answer_start"].iloc[0][0] # 计算答案的结束位置 # len(sample_df["answers.text"].iloc[0][0]) 获取答案文本的长度 # end_idx 表示答案的结束位置 end_idx = start_idx + len(sample_df["answers.text"].iloc[0][0]) # 从上下文中提取答案 # .iloc[0] 获取DataFrame的第一行 # [start_idx:end_idx] 切片操作,从上下文中提取答案文本 answer_in_context = sample_df["context"].iloc[0][start_idx:end_idx] # 打印提取的答案文本 print(answer_in_context) 运行结果:
this keyboard is compact
接下来,我们通过统计几个以常见词汇开头的问题的数量,来了解训练中不同问题类型的分布情况:
import matplotlib.pyplot as plt # 初始化一个空字典,用于存储不同类型问题的计数 counts = {} # 定义一个包含感兴趣的常见问题类型的列表 question_types = ["What", "How", "Is", "Does", "Do", "Was", "Where", "Why"] # 遍历每种问题类型 for q in question_types: # 计算训练集中以该问题类型开头的问题数量 # dfs["train"]["question"].str.startswith(q) 返回一个布尔Series,表示问题是否以q开头 # .value_counts() 统计True和False的数量 # [True] 获取以q开头的问题数量 counts[q] = dfs["train"]["question"].str.startswith(q).value_counts().get(True, 0) # 将counts字典转换为pandas Series,并按值排序 # .sort_values() 按值排序,默认升序 # .plot.barh() 生成水平条形图 ax = pd.Series(counts).sort_values().plot.barh() # 设置图表标题 plt.title("Frequency of Question Types") # 自适应调整图表,以便更好地保存 plt.tight_layout() # 保存图表为图片文件,格式可以是png、jpg等 plt.savefig("images/question_types_frequency.png") # 显示图表 plt.show() 运行结果:
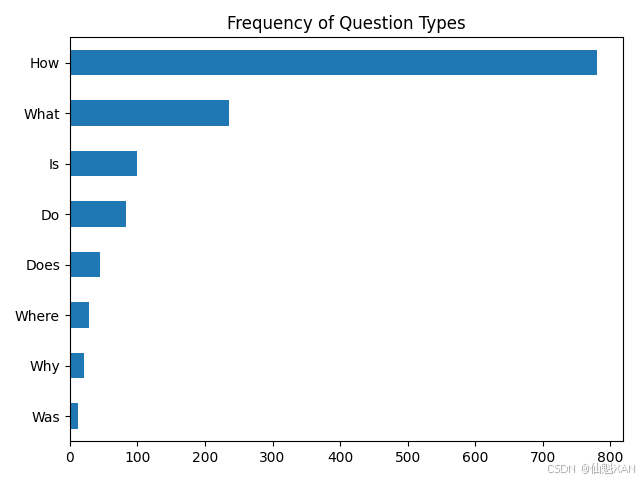
从以上运行结果可以看到,以“How”“What”和“Is”开头的问题是最为常见的,尤其是以“How”开头的问题,远远多于其他类型的问题,我们再来看一些实际的问题例子:
# 遍历感兴趣的常见问题类型列表 ["How", "What", "Is"] for question_type in ["How", "What", "Is"]: # 从训练数据集中筛选出以当前问题类型开头的问题,并随机抽取3个问题 # dfs["train"] 访问训练数据的 DataFrame # dfs["train"].question.str.startswith(question_type) 返回一个布尔 Series,表示问题是否以 question_type 开头 # dfs["train"][条件] 筛选出符合条件的行 # .sample(n=3, random_state=42) 从符合条件的行中随机抽取3行,random_state=42 确保抽样结果可重复 # ['question'] 只保留问题列 for question in ( dfs["train"][dfs["train"].question.str.startswith(question_type)] .sample(n=3, random_state=42)['question']): # 打印随机抽取的每个问题 print(question) 运行结果:
How is the camera? How do you like the control? How fast is the charger? What is direction? What is the quality of the construction of the bag? What is your impression of the product? Is this how zoom works? Is sound clear? Is it a wireless keyboard?
斯坦福问答数据集
P. Rajpurkar et al., “SQuAD:100,000+Questions for Machine Comprehension of Text”(https://arxiv.org/abs/1606.05250),(2016).
P. Rajpurkar, R. Jia, and P. Liang, “Know What You Don't Know: Unanswerable Questions for SQuAD”(https://arxiv.org/abs/1806.03822), (2018).
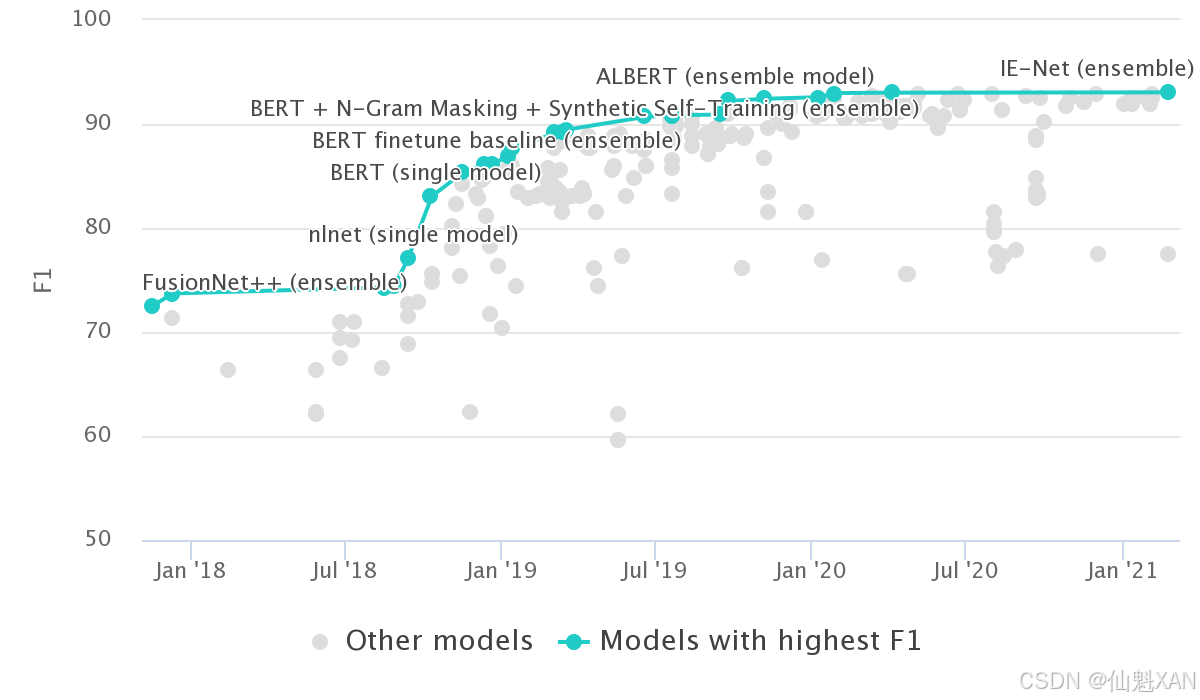
SubjQA的(question,review,[answer sentences])格式在提取式问答数据集中非常常见,它在斯坦福问答数据集(SQuAD) 中被首度应用。SQuAD数据集知名度很高,常被用来测试模型在理解一段文本后,回答相关问题的能力。该数据集基于维基百科数百篇英文文章,每篇文章被切分成段落,然后让众包标注人员为每个段落标注一系列问题和答案。在SQuAD数据集的第一个版本中,每个问题的答案都保证存在于相应的段落中,但没过多久,人们发现使用序列模型(Sequence Model)也开始可以胜任此工作,甚至比人类的标注效果更好。为了让模型获得更佳的泛化能力,SQuAD 2.0在SQuAD 1.1的基础上,增加了与给定段落相关,但不能仅从文本中找到答案的对立问题,来使标注难度加大 。本书写作时的最新成果如图7-3所示,事实上,自2019年以来,大多数的此类模型都超越了人类的表现。
T. Kwiatkowski et al., “Natural Questions: A Benchmark for Question Answering Research,”Transactions of the Association for Computational Linguistics 7(March 2019):452-466,http://dx.doi.org/10.1162/tacl_a_00276.
然而,这种超乎常人的表现似乎并不能反映出真实的阅读理解能力,因为那种“无法回答”的问题可以通过段落中的某种匹配模式来解决(如查找反义词)。为了解决这种问题,Google发布了自然问答(Natural Question,NQ)数据集 ,该数据集包含了30万个自然产生的问题和对应的回答标注,每个回答都是人工从维基百科找到的答案。NQ数据集中的答案比SQuAD数据集中的答案长得多,并且提出了更具挑战性的基准。
现在我们已经对数据集进行了一些探索,下面让我们深入了解Transformer如何从文本中提取答案。
2、从文本中提取答案
问答系统需要做的第一件事,是找到一种方法将用户评论中的潜在答案文本段识别出来。例如,有一个“Is it waterproof?”(它防水吗?)的问题,评论是“This watch is waterproof at 30m depth”(这个手表在水下30米深都能防水),模型正确的输出该是“waterproof at 30m”(防水30米)。要从文本中准确提取答案,要搞清楚以下三个问题:
●如何将问题转化为监督学习问题。
●如何针对问答任务做输入处理和编码。
●如何处理超过模型最大上下文限制的长文本问题。
下面我们来看看如何理解和解决这些问题。
2.1 片段分类
从文本中提取答案最常用的方法是将问题转化成一个监督的片段分类(span classification)任务,也就是预测答案片段的起始词元和终止词元。这个过程如下图所示:
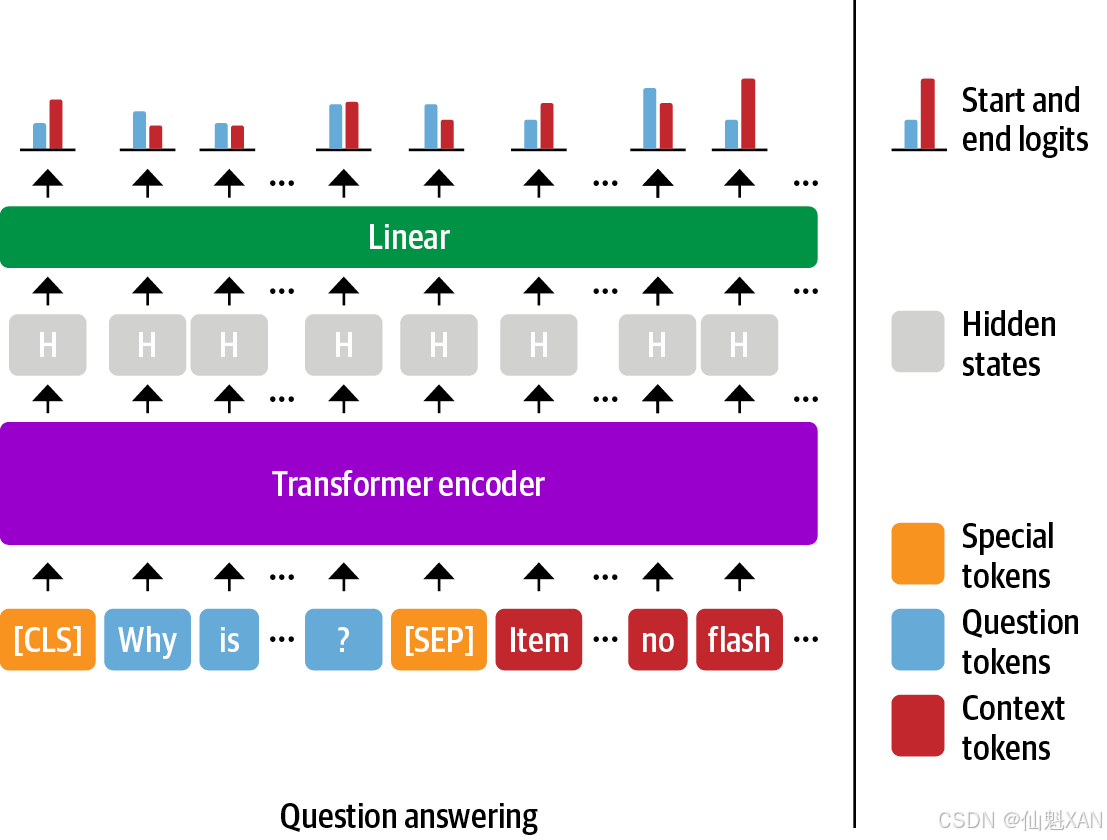
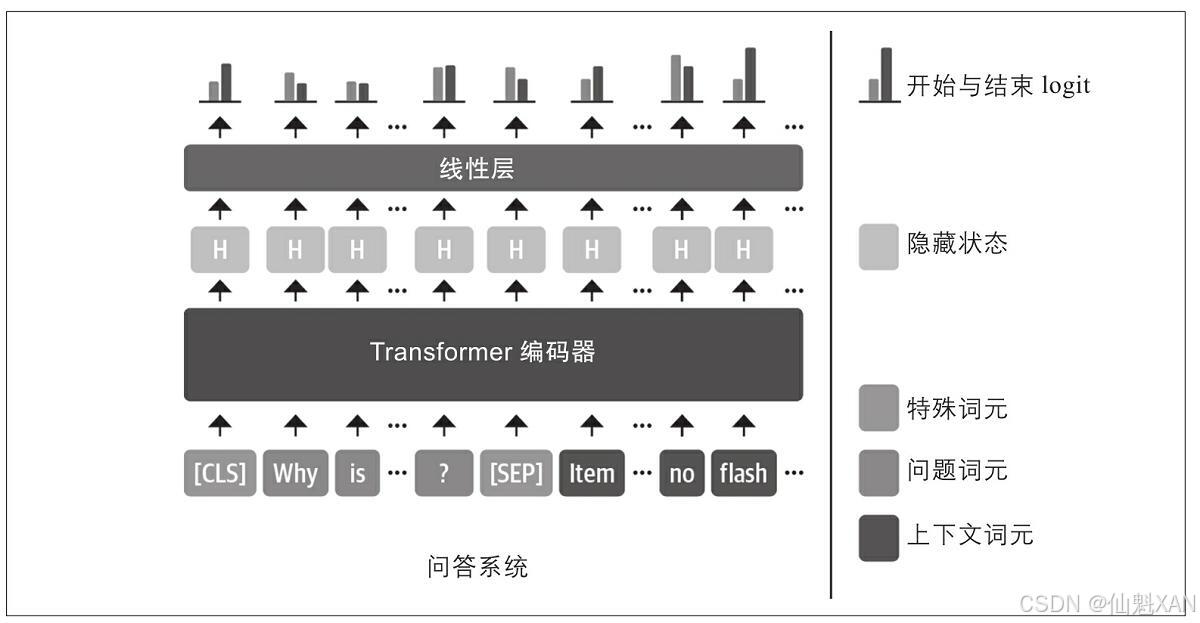
由于SubjQA数据集中与电子产品相关的数据子集相对较小,只有1295个训练样本,因此最好直接使用已经在大型问答数据集(如SQuAD)上进行过微调的语言模型。一般来说,这种语言模型已经具有了较强的文本阅读理解能力,可以作为构建更加精准模型的基础模型来使用。这与前几章采用的方式不同,在前几章中,通常是从预训练模型开始,然后对特定任务头进行微调。例如,在之前介绍中,我们必须对分类头进行微调,因为分类的数量是与数据集相关联的。对提取式问答来说,可以直接使用微调过的模型,因为标注结构在不同数据集当中是保持一致的。
可以访问Hugging Face Hub(https://oreil.ly/dzCsC)网站的顶部的“Models”tab页,输入“squad”,再点击左侧的“Question Answering”选项卡来查找提取式问答模型,如下图所示。
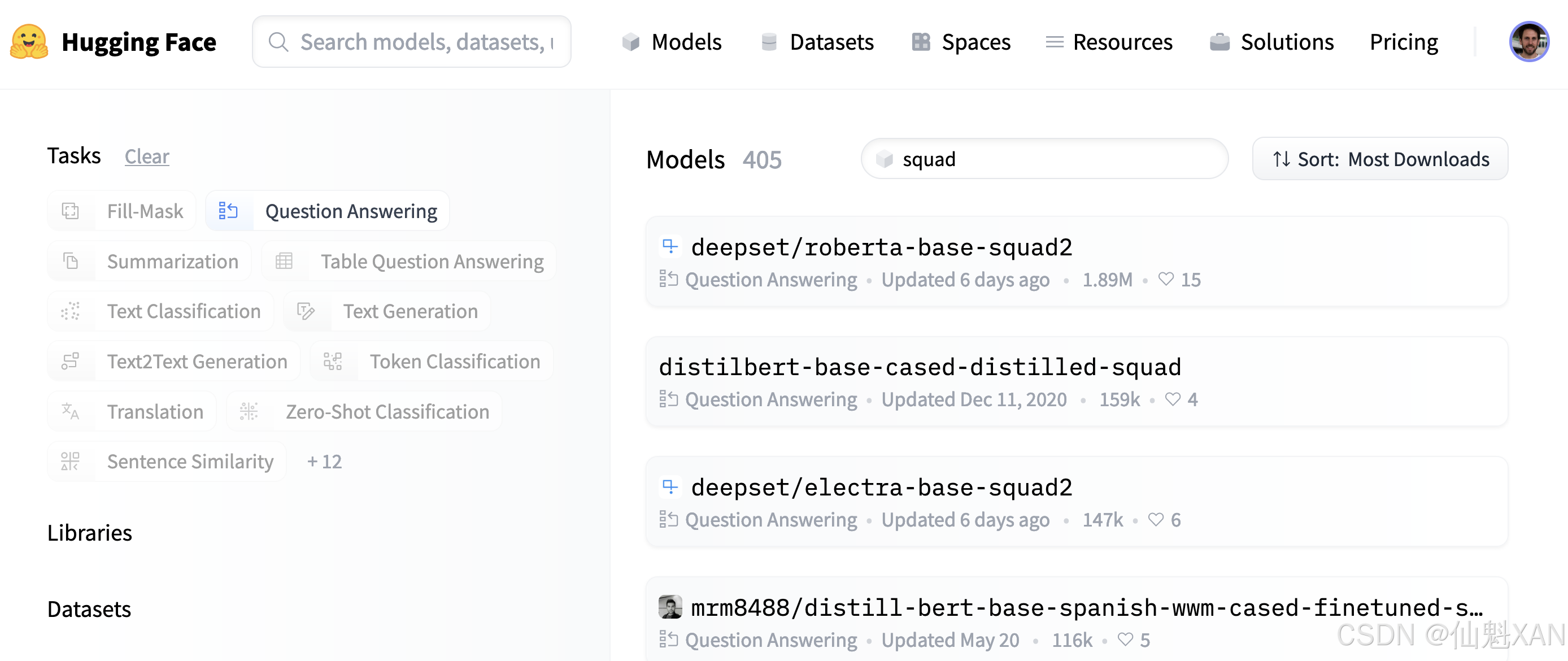
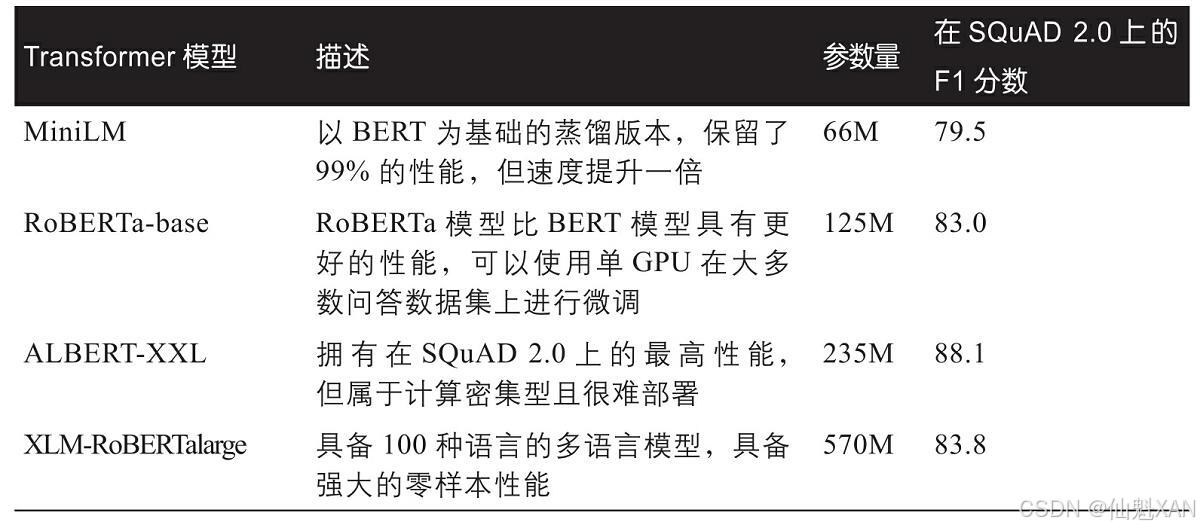
在撰写本书时,按照图7-5这样来操作,可以发现已经有350多个问答模型可供选择,如此多的模型,我们应该选择哪个呢?这需要考虑多种因素,比如根据语料库是单语言还是多语言的,以及运行环境对于模型的限制条件,等等。如下表列出了几种模型,可以帮助我们在选择的时候做一下参考。
W. Wang et al., “MINILM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”(https://arxiv.org/abs/2002.10957),(2020).
出于对本章内容的考虑,这里选用经过微调处理的MiniLM模型,因为它在训练阶段速度很快,能够满足快速迭代的需求 。我们在使用它的时候,需要一个词元分析器来对文本进行编码操作,下面来看一下具体过程。
2.2 文本词元化
首先需要从Hugging Face Hub(https://oreil.ly/df5Cu)加载MiniLM模型的checkpoint,来对文本进行编码操作:
# 从transformers库中导入AutoTokenizer类 from transformers import AutoTokenizer # 指定要使用的预训练模型的检查点(checkpoint) # 这里使用的是 "deepset/minilm-uncased-squad2" 模型 model_ckpt = "deepset/minilm-uncased-squad2" # 使用AutoTokenizer类从预训练模型的检查点加载分词器(tokenizer) # from_pretrained() 方法会下载并缓存分词器配置和词汇表 tokenizer = AutoTokenizer.from_pretrained(model_ckpt)运行结果:
为了查看这个模型的效果如何,我们首先尝试从一段短文本中提取答案。在提取式问答任务中,我们一般将问题和上下文成对(question,context)传给词元分析器:
# 定义问题字符串,表示用户提出的问题 question = "How much music can this hold?" # 定义上下文字符串,提供问题答案所在的文本段落 context = """An MP3 is about 1 MB/minute, so about 6000 hours depending on \ file size.""" # 使用之前加载的分词器将问题和上下文转换为模型可以处理的格式 # tokenizer() 方法会将输入的文本转换为token ID,并返回一个字典 # 参数: # - question: 用户提出的问题文本 # - context: 提供问题答案的上下文文本 # - return_tensors="pt": 指定返回的格式为 PyTorch tensors inputs = tokenizer(question, context, return_tensors="pt")以上代码返回Pytorch Tensor对象,用它们来运行模型的前向传递。如果我们将词元化的输入看作一个表:
# 使用之前加载的分词器将问题和上下文转换为字典格式 # 这里没有指定 return_tensors 参数,因此返回的不是张量,而是普通的 Python 数据类型(例如列表) tokenized_inputs = tokenizer(question, context) # 将 tokenized_inputs 字典转换为 pandas DataFrame,以便于查看和分析 # from_dict() 方法从字典创建 DataFrame # orient="index" 参数表示字典的键应该作为 DataFrame 的行索引 input_df = pd.DataFrame.from_dict(tokenized_inputs, orient="index") # 打印 DataFrame,显示分词后的输入 input_df运行结果:

注意,并非所有的Transformer模型都存在token_type_ids,在类似BERT的模型中,比如MiniLM,token_type_ids在训练期间也被用来合并下一个语句的预测任务。
从表格里面可以看到熟悉的input ids与attention mask张量,而另一个token_type_ids张量表示的是哪部分输入内容和问题与上下文相对应(0代表问题的词元,1代表上下文的词元) 。
为了直观了解词元分析器如何格式化问答任务的输入内容,这里对inputs_ids张量进行解码:
# 将模型输入的 token ID 解码为可读文本 # inputs["input_ids"] 是一个包含 token ID 的张量列表 # inputs["input_ids"][0] 获取第一个样本的 token ID 列表 # tokenizer.decode() 方法将 token ID 列表解码为字符串 decoded_text = tokenizer.decode(inputs["input_ids"][0]) # 打印解码后的文本 print(decoded_text)运行结果:
[CLS] how much music can this hold? [SEP] an mp3 is about 1 mb / minute, so about 6000 hours depending on file size. [SEP]
可以看出,每一个问答任务,其输入内容都保持如下格式:
[CLS] Question Tokens [SEP] Answer Tokens [SEP]
第一个[SEP]词元的位置由token_type_ids决定。现在文本已经被词元化了,接下来只需要使用一个问答头来实例化模型,并通过前向传递(forward pass)运行输入内容:
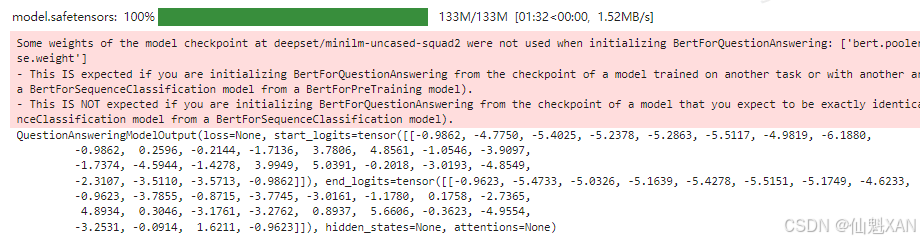
# 导入 PyTorch 库 import torch # 从 transformers 库中导入 AutoModelForQuestionAnswering 类 from transformers import AutoModelForQuestionAnswering # 使用指定的预训练模型检查点加载用于问答的预训练模型 # from_pretrained() 方法会下载并缓存模型配置和权重 model = AutoModelForQuestionAnswering.from_pretrained(model_ckpt) # 在不计算梯度的上下文中运行模型 # 这在推理过程中使用,可以节省内存并提高计算速度 with torch.no_grad(): # 将模型输入传递给模型,并获取模型输出 # **inputs 将输入字典解包为关键字参数 outputs = model(**inputs) # 打印模型输出 print(outputs)运行结果:
有关如何提取这些隐藏状态的详细信息,请参阅之前的内容。
可以看出,问答头输出了一个QuestionAnsweringModelOutput对象。如图7-4所示,问答头对应一个线性层,该层从编码器获取隐藏状态,并计算开始和结束片段的logit,也就是将问答视为词元分类的一种形式,类似于第4章中介绍的命名实体识别的情况。下一步是将输出转换为答案片段,需要先获取开始和结束词元的logit:
# 获取模型输出中的开始位置得分(start_logits)和结束位置得分(end_logits) # start_logits 和 end_logits 是模型输出的两个张量,表示上下文中每个位置作为答案起点和终点的得分 start_logits = outputs.start_logits end_logits = outputs.end_logits如果将这些logit形状与输入ID进行比较:
# 打印输入的 token ID 的形状(size) # inputs.input_ids 是一个张量,包含分词后的 token ID # .size() 方法返回张量的形状 print(f"Input IDs shape: {inputs.input_ids.size()}") # 打印开始位置得分(start_logits)的形状 # start_logits 是一个张量,表示上下文中每个位置作为答案起点的得分 # .size() 方法返回张量的形状 print(f"Start logits shape: {start_logits.size()}") # 打印结束位置得分(end_logits)的形状 # end_logits 是一个张量,表示上下文中每个位置作为答案终点的得分 # .size() 方法返回张量的形状 print(f"End logits shape: {end_logits.size()}") 运行结果:
Input IDs shape: torch.Size([1, 28]) Start logits shape: torch.Size([1, 28]) End logits shape: torch.Size([1, 28])
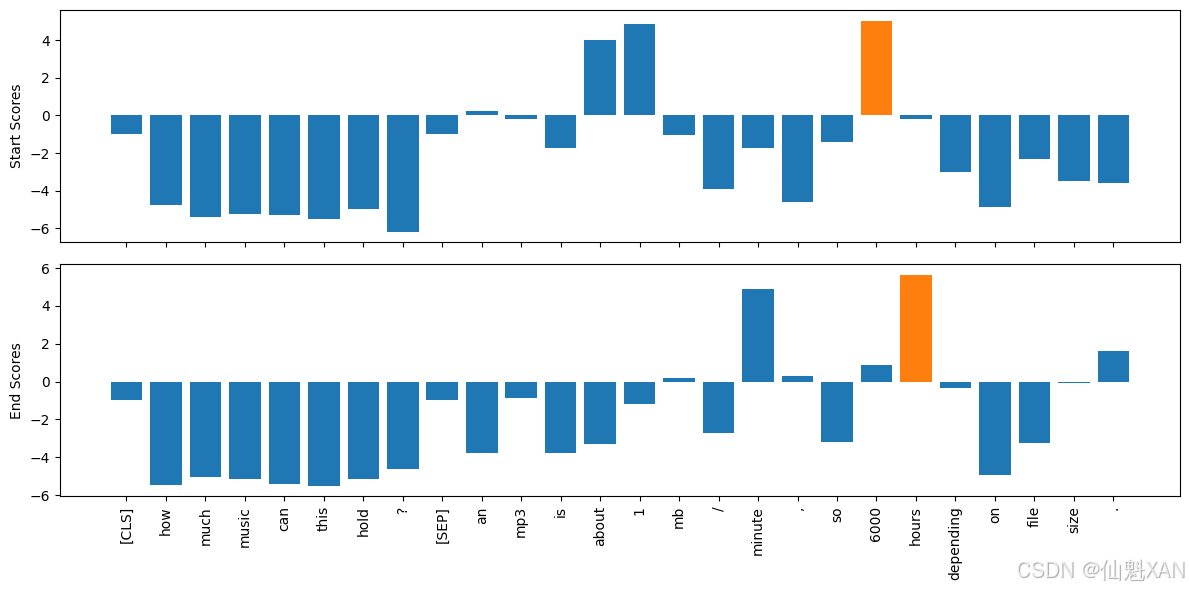
可以看出,每个输入词元有两个相关的logit(开始和结束)。如下图所示,较大的正logit对应于更有可能的开始和结束词元。在这个示例中,可以看到模型将最高起始词元的logit分配给数字“1”和“6000”,这是合理的,因为原始问题就是一个关于数量的问题。同样地,具有最高logit的结束词元则是“minute”和“hours”。
# 导入 numpy 库,用于处理数组操作 import numpy as np # 导入 matplotlib 库,用于数据可视化 import matplotlib.pyplot as plt # 将开始位置得分的张量转换为 numpy 数组,并展平为一维数组 s_scores = start_logits.detach().numpy().flatten() # 将结束位置得分的张量转换为 numpy 数组,并展平为一维数组 e_scores = end_logits.detach().numpy().flatten() # 将输入的 token ID 转换为可读的 token tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]) # 创建一个包含两个子图的图形对象,子图共享 x 轴 fig, (ax1, ax2) = plt.subplots(nrows=2, sharex=True, figsize=(12, 6)) # 为开始位置得分绘制条形图 colors = ["C0" if s != np.max(s_scores) else "C1" for s in s_scores] ax1.bar(x=tokens, height=s_scores, color=colors) ax1.set_ylabel("Start Scores") # 为结束位置得分绘制条形图 colors = ["C0" if s != np.max(e_scores) else "C1" for s in e_scores] ax2.bar(x=tokens, height=e_scores, color=colors) ax2.set_ylabel("End Scores") # 设置 x 轴标签的旋转角度为垂直方向 plt.xticks(rotation="vertical") # 调整布局以确保标签不会被裁剪 plt.tight_layout() # 保存图形为文件,确保图片保存完整 plt.savefig("images/qa_scores.png", bbox_inches="tight") # 显示绘制的图形 plt.show() 运行结果:
为了得到最终的答案,我们可以在开始和结束词元的logit之上计算argmax,然后从输入内容中切分出片段。以下代码运行这些步骤并且将结果进行解码,然后输出结果:
# 导入 PyTorch 库 import torch # 使用 argmax 函数找到开始位置的最大值索引 start_idx = torch.argmax(start_logits) # 使用 argmax 函数找到结束位置的最大值索引,并加 1(因为结束位置是开区间) end_idx = torch.argmax(end_logits) + 1 # 根据找到的开始和结束位置索引从输入的 token ID 中提取答案 span answer_span = inputs["input_ids"][0][start_idx:end_idx] # 将 token ID 转换为可读的答案字符串 answer = tokenizer.decode(answer_span) # 打印问题和找到的答案 print(f"Question: {question}") print(f"Answer: {answer}") 运行结果:
Question: How much music can this hold? Answer: 6000 hours
在Hugging Face Transformers库中,所有的预处理和后处理步骤都被封装在使用起来非常方便的专用pipeline中。我们可以传入词元分析器和经过微调的模型来实例化pipeline,如下所示:
# 从 transformers 库中导入 pipeline 函数 from transformers import pipeline # 使用 pipeline 函数创建一个问答系统的管道 # "question-answering" 指定了管道类型为问答系统 # model 和 tokenizer 参数指定了使用的模型和分词器 pipe = pipeline("question-answering", model=model, tokenizer=tokenizer) # 使用管道进行问答,指定问题和上下文,并返回前三个可能的答案 # question 参数为问题字符串 # context 参数为包含问题答案的上下文字符串 # topk 参数指定返回的前 k 个答案 pipe(question=question, context=context, topk=3)运行结果:
[{'score': 0.2651616334915161, 'start': 38, 'end': 48, 'answer': '6000 hours'}, {'score': 0.22082963585853577, 'start': 16, 'end': 48, 'answer': '1 MB/minute, so about 6000 hours'}, {'score': 0.10253521800041199, 'start': 16, 'end': 27, 'answer': '1 MB/minute'}] pipeline返回的结果里面除了答案之外,还在分数(score)字段中给出了模型概率估计值(通过对logit做softmax获得)。当通过设置topk参数来让模型预测返回多个结果的时候,该字段在单个上下文中对比多个答案时是很有用的。有时我们还会碰到那种无法回答的问题,就像前文提到的SubjQA数据集中的answers.answer_start空值情况。当出现这种情况的时候,模型会为[CLS]词元分配一个较高的开始和结束分数,pipeline会将此输出映射成一个空字符串。
# 使用创建的管道进行问答,指定问题和上下文,并处理不可能的答案情况 # question 参数为问题字符串 # context 参数为包含问题答案的上下文字符串 # handle_impossible_answer=True 参数指定处理不可能的答案情况 pipe(question="Why is there no data?", context=context, handle_impossible_answer=True) 运行结果:
{'score': 0.9068413972854614, 'start': 0, 'end': 0, 'answer': ''} 在上面的简单示例中,我们通过获取相应logit的argmax来获得开始和结束索引。然而,这种启发式方法也可以通过选择属于问题而不是上下文的词元来产生超出范围的答案。在实际应用中,pipeline会根据各种约束条件来计算出最佳的开始和结束索引组合,比如必须要在一定范围内,或开始索引必须要在结束索引之前等约束条件。
2.3处理长文本段落
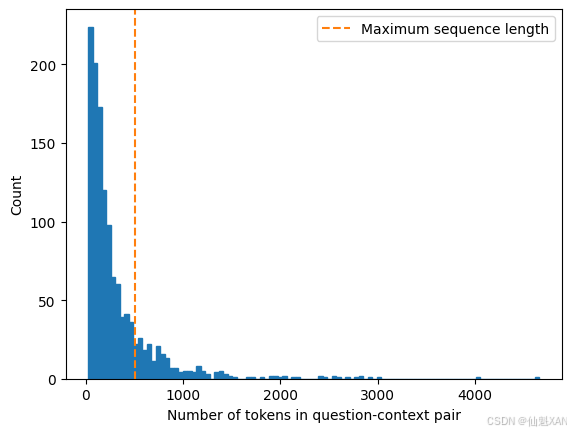
在阅读理解场景有一个比较常见的问题,文本段落的长度经常会超出模型限制的最大输入长度(一般最多只有几百个词元)。如图7-7所示,SubjQA训练集中有相当一部分文本段落长度超出了MiniLM模型限制的512个词元数量。
def compute_input_length(row): # 使用分词器处理问题和上下文,返回输入 token 的长度 inputs = tokenizer(row["question"], row["context"]) return len(inputs["input_ids"]) # 在训练集的 DataFrame 中新增一列 "n_tokens",表示每个样本的 token 数量 dfs["train"]["n_tokens"] = dfs["train"].apply(compute_input_length, axis=1) # 创建一个新的图形对象和子图 fig, ax = plt.subplots() # 绘制 "n_tokens" 列的直方图 dfs["train"]["n_tokens"].hist(bins=100, grid=False, ec="C0", ax=ax) # 设置 x 轴标签为 "Number of tokens in question-context pair" plt.xlabel("Number of tokens in question-context pair") # 添加垂直虚线,表示最大序列长度为 512 ax.axvline(x=512, ymin=0, ymax=1, linestyle="--", color="C1", label="Maximum sequence length") # 添加图例 plt.legend() # 设置 y 轴标签为 "Count" plt.ylabel("Count") # 保存图形为文件,确保图片保存完整 plt.savefig("images/tokens_in_question_context_pair.png", bbox_inches="tight") # 显示绘制的图形 plt.show() 运行结果:
对于文本分类等其他场景,最常用的方法是将超出长度的文本直接截断并丢弃,因为即使缺失一部分文档,也能得出正确的分类预测结果。但在问答场景,这种做法是有问题的,因为问题的答案很可能位于上下文的末尾附近。如图7-8所示,处理这种问题的标准方法是在输入上加一个滑动窗口,将原始长文本处理成多个短文本,其中每个窗口都包含完全适配模型上下文的词元数量。
Hugging Face Transformers库提供了相关的API,可以在词元分析器中设置return_overflowing_tokens=True来启用滑动窗口功能,滑动窗口的大小由max_seq_length参数控制,步幅大小则由doc stride参数控制。下面从训练集中选取一组数据,并定义一个滑动窗口来演示它是如何使用的:
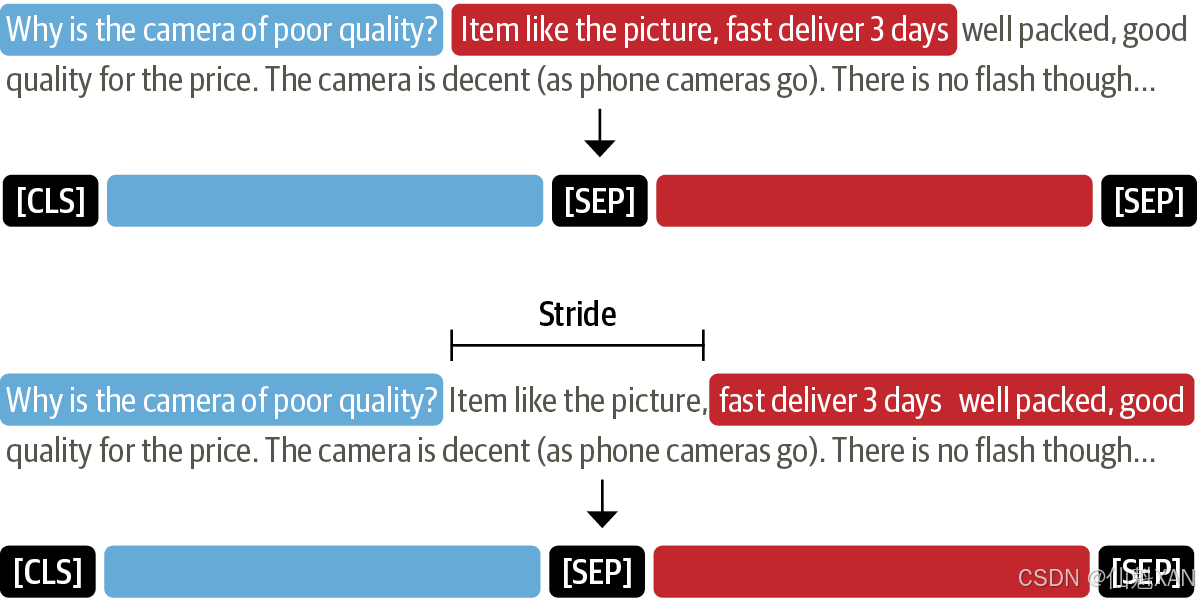
# 从训练集 DataFrame 中提取第一个样本的问题和上下文列 example = dfs["train"].iloc[0][["question", "context"]] # 使用分词器处理问题和上下文,并进行分词 # example["question"] 是问题字符串 # example["context"] 是上下文字符串 # return_overflowing_tokens=True 表示返回超出最大长度的 token # max_length=100 指定最大长度为 100 # stride=25 指定滑动窗口的步长为 25 tokenized_example = tokenizer(example["question"], example["context"], return_overflowing_tokens=True, max_length=100, stride=25)在这个案例中,每个滑动窗口都获取了一个input_ids数组,下面来查看每个滑动窗口中的词元数量:
# 遍历 tokenized_example 中的每个窗口 for idx, window in enumerate(tokenized_example["input_ids"]): # 打印每个窗口的索引号和其中的 token 数量 print(f"Window #{idx} has {len(window)} tokens") 运行结果:
Window #0 has 100 tokens Window #1 has 88 tokens
最后,我们通过解码input_ids来查看两个滑动窗口重叠的地方:
# 遍历 tokenized_example 中的每个窗口 for window in tokenized_example["input_ids"]: # 使用分词器的 decode 方法将 token ID 列表转换为可读的文本并打印 print(f"{tokenizer.decode(window)} \n") 运行结果:
[CLS] how is the bass? [SEP] i have had koss headphones in the past, pro 4aa and qz - 99. the koss portapro is portable and has great bass response. the work great with my android phone and can be " rolled up " to be carried in my motorcycle jacket or computer bag without getting crunched. they are very light and do not feel heavy or bear down on your ears even after listening to music with them on all day. the sound is [SEP] [CLS] how is the bass? [SEP] and do not feel heavy or bear down on your ears even after listening to music with them on all day. the sound is night and day better than any ear - bud could be and are almost as good as the pro 4aa. they are " open air " headphones so you cannot match the bass to the sealed types, but it comes close. for $ 32, you cannot go wrong. [SEP]
到目前为止,我们对问答模型如何从文本中提取答案已经有了一些认知,下面我们来看看如何使用其他组件来构建一个端到端的问答pipeline。
