
阅读量:2
目录
Question:
给定n个物品,第i个物品的重量为wgt[i-1],价值为val[i-1],和一个容量为cap的背包。每个物品可以重复选取,问在限定背包容量的情况下能放入物品的最大价值。
图例:
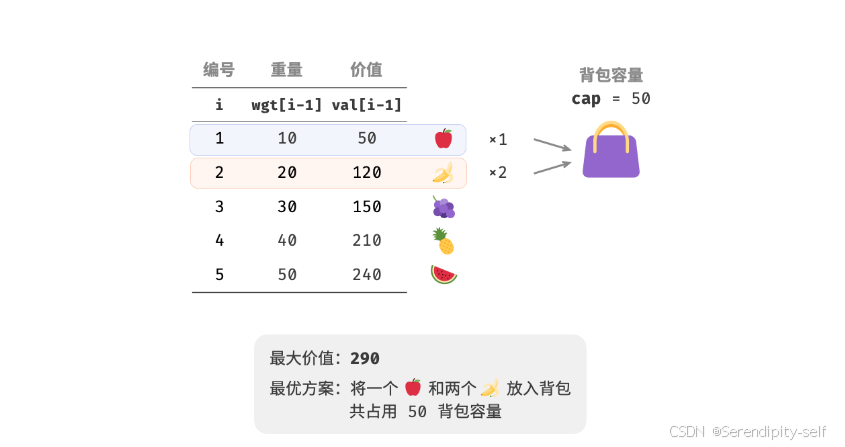
动态规划思路
完全背包问题和0-1背包问题非常相似,区别仅在于不限制物品的选择次数。
- 在0-1背包问题中,每种物品只有一个,因此将物品i放入到被曝后,只能从前i-1个物品选择。
- 在完全背包问题中,每种物品的数量都是无限的,因此将物品i放入到背包后,仍可以从前i个物品中选择。
在完全背包问题的规定下,状态[i,c]的变化分为以下两种情况。
- 不放入物品i:与0-1背包问题相同转移至[i-1,c]。
- 放入物品i:与0-1背包问题不同,转移至[i,c-wgt[i-1]]。
从而转移状态方程为:
dp[i,c] = max(dp[i-1,c],dp[i,c-wgt[i-1]]+val[i-1])
2代码实现:
# python 代码示例 def unbound_knap_sack_dp(wgt, val, cap) : n = len(wgt) dp = [ [0] * (cap + 1) for _ in range(n + 1)] for i in range(1, n + 1) : for j in range(1, cap + 1) : if wgt[i - 1] > c : dp[i][c] = dp[i - 1][c] else : dp[i][c] = max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1]) return dp[n][cap]// c++ 代码示例 int unboundKnapSackDP(vector<int> &wgt, vector<int> &val, int cap) { int n = wgt.size() ; vector<vector<int>> dp(n + 1, vector<int>(cap + 1, 0)) ; for (int i = 1 ; i <= n ; i++) { for (int j = 1 ; j <= cap ; j++) { if (wgt[i - 1] > c) { dp[i][c] = dp[i - 1][c] ; } else { dp[i][c] = max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1) ; } } } return dp[n][cap] ; }3 空间优化:
由于当前状态是从左边和上边的状态转移而来,因此空间优化后应该对dp表中的每一行进行正序遍历。
图例所示:

代码实现:
# python 代码示例 def unbound_knap_sack_dp_comp(wgt, val, cap) : n = len(wgt) dp = [0] * (cap + 1) for i in range(1, n + 1) : for j in range(1, cap + 1) : if wgt[i - 1] > c : dp[c] = dp[c] else : dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]) return dp[cap] ;// c++ 代码示例 int unboundKnapSackDPComp(vector<int> &wgt, vector<int> &val, int cap) { int n = wgt.size() ; vector<int> dp(cap + 1, 0) ; for (int i = 1 ; i <= n ; i ++) { for (int j = 1 ; j <= cap ; j++) { if (wgt[i - 1] > c) { dp[c] = dp[c] ; } else { dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]) ; } } } return dp[c] ; }下面是0-1背包和完全背包具体的例题:
零钱兑换问题:给定n中硬币,第i种硬币的面值为coins[i-1],目标金额为amt,每种硬币可以重复选取,问能够凑出目标金额的最少硬币数。如果无法凑出目标金额,则返回-1。
图例:
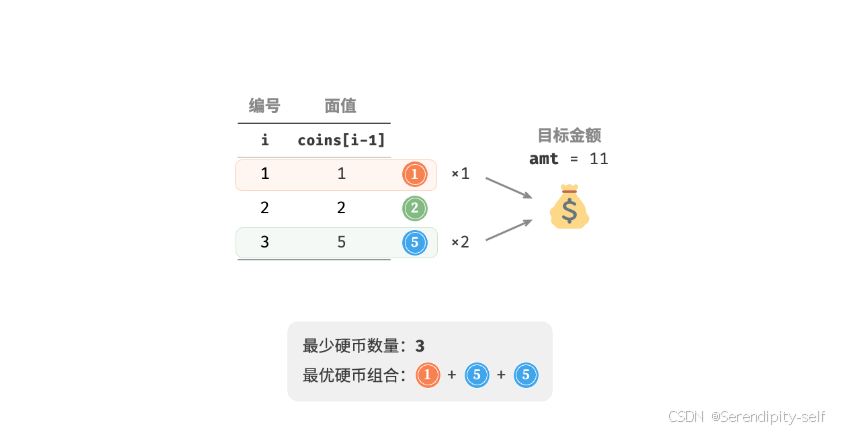
动态规划的思路:
零钱兑换可以看作是完全背包的一种特殊情况,两者具有以下联系和不同点。
- 两道题目可以相互转化,“物品“对应”硬币“、”物品重量“对应”硬币面值“、”背包容量“对应”目标金额“。
- 优化目标相反,完全背包问题是要最大化物品价值,零钱兑换问题是要最小化硬币数量。
- 完全背包问题是求“不超过“背包容量下的解,零钱兑换是求”恰好“凑到目标金额的解。
第一步:思考每轮的决策,定义状态,从而得到dp表
状态[i,a]对应的子问题为:前i种硬币能够凑出金额a的最少硬币数量,记作dp[i,a]。
二维dp表的尺寸为(n+1)*(amt+1).
第二步:找出最优子结构,进而推导出状态转移方程
本题与完全背包问题的转移状态方程存在以下两点差异。
- 本题要求最小值,因此需将运算符max()更改为min()。
- 优化主体是硬币数量而非商品的价值,因此在选中硬币时需执行+1即可。
dp[i,a] = min(dp[i-1,a],dp[i,a-coins[i-1]]+1)
第三步:确定边界和状态转移顺序
当目标金额为0时,凑出它的最小硬币数量为0,即首列所有dp[i,0]都等于0。
当无硬币时,无法凑出任意>0的目标金额,即使无效解。为使状态转移方程中的min()函数能够识别并过滤无效解,我们使用+∞来表示他们,即令首行所有dp[0,a]都等于+∞。
代码实现:
def coin_change_dp(coins, amt) : n = len(coins) dp = [ [0] * (amt + 1) for _ in range(n + 1)] for j in range(1, amt + 1) : dp[0][j] = inf for i in range(1, n + 1) : dp[i][0] = 0 for i in range(1, n + 1) : for j in range(1, cap + 1) : if coins[i - 1] > j : dp[i][j] = dp[i - 1][j] else : dp[i][j] = max(dp[i - 1][j], dp[i][j - coins[i - 1]] + 1) return dp[n][amt] if dp[n][amt] != inf else -1int coinsChangeDP(vector<int> &coins, int amt) { int n = coins.size() ; vector<vector<int>> dp(n + 1, vector<int>(amt + 1, 0)) ; for (int j = 1 ; j <= amt ; j++) { dp[0][j] = INT_MAX ; } for (int i = 1 ; i <= n ; i++) { dp[i][0] = 0 ; } for (int i = 1 ; i <= n ; i++) { for (int j = 1 ; j <= amt ; j++) { if (coins[i - 1] > j) { dp[i][j] = dp[i - 1][j] ; } else { dp[i][j] = min(dp[i - 1][j], dp[i][j - coins[i - 1]] + 1) ; } } } return dp[n][amt] != INT_MAX ? dp[n][amt] : -1 ; }图例:

空间优化代码示例:
# python 代码示例 def coins_change_dp_comp(coins, amt) : n = len(coins) dp = [inf] * (amt + 1) for i in range(1, n + 1) : for j in range(1, cap + 1) : if (coins[i - 1] > j) : dp[j] = dp[j] else : dp[j] = min(dp[j], dp[j - coins[i - 1]] + 1) return dp[amt] if dp[amt] != inf else -1 // c++ 代码示例 int coinsChangeDPComp(vector<int> &coins, int amt) { int n = coins.size() ; vector<int> dp(cap + 1, INT_MAX) ; for (int i = 1 ; i <= n ; i++) { for (int j = 1 ; j <= amt ; j++) { if (coins[i - 1] > j) { dp[j] = dp[j] ; } else { dp[j] = min([j], [j - coins[i - 1]] + 1) ; } } } return dp[amt] != INT_MAX ? dp[amt] : -1 ; }