
阅读量:0

📝个人主页:哈__
期待您的关注

目录
1. 🔥引言
背景介绍
生成对抗网络(Generative Adversarial Networks, GANs)由Ian Goodfellow等人于2014年提出,迅速成为机器学习领域的一项革命性技术。GANs通过一个生成器(Generator)和一个判别器(Discriminator)之间的对抗性训练,实现了数据生成的突破。生成器负责生成逼真的数据样本,而判别器则用于区分生成样本与真实样本,两者相互竞争,共同提升生成样本的质量。
自从GANs问世以来,它在图像生成、视频合成、文本生成等多个领域展现了强大的能力。例如,GANs能够生成高分辨率的图像,修复损坏的图像,甚至生成逼真的视频内容。这些技术不仅在学术界引起了广泛关注,也在工业界得到了广泛应用。
研究意义
随着计算机视觉和图像处理技术的不断发展,GANs在图像和视频技术中的潜在应用越来越受到重视。GANs在图像生成方面的应用可以极大地提升图像处理和生成的效率和质量,使其在艺术创作、虚拟现实、医学影像等领域具有广阔的应用前景。
在视频合成领域,GANs通过生成连续的视频帧,实现了从静态图像到动态视频的转换。这种技术可以应用于电影制作、游戏开发、虚拟现实等多个领域,极大地丰富了视觉内容的呈现方式。此外,GANs在视频修复和去噪、视频超分辨率等方面也展现了巨大的潜力,为视频处理技术的发展提供了新的思路。
总之,GANs作为一种强大的生成模型,不仅在图像和视频技术中具有重要应用前景,还为未来视觉技术的发展提供了新的可能性。本文将深入探讨GANs在图像和视频技术中的最新进展和应用前景,为未来研究和应用提供参考。

2. 🎈GANs的基本概念和工作原理
生成对抗网络简介
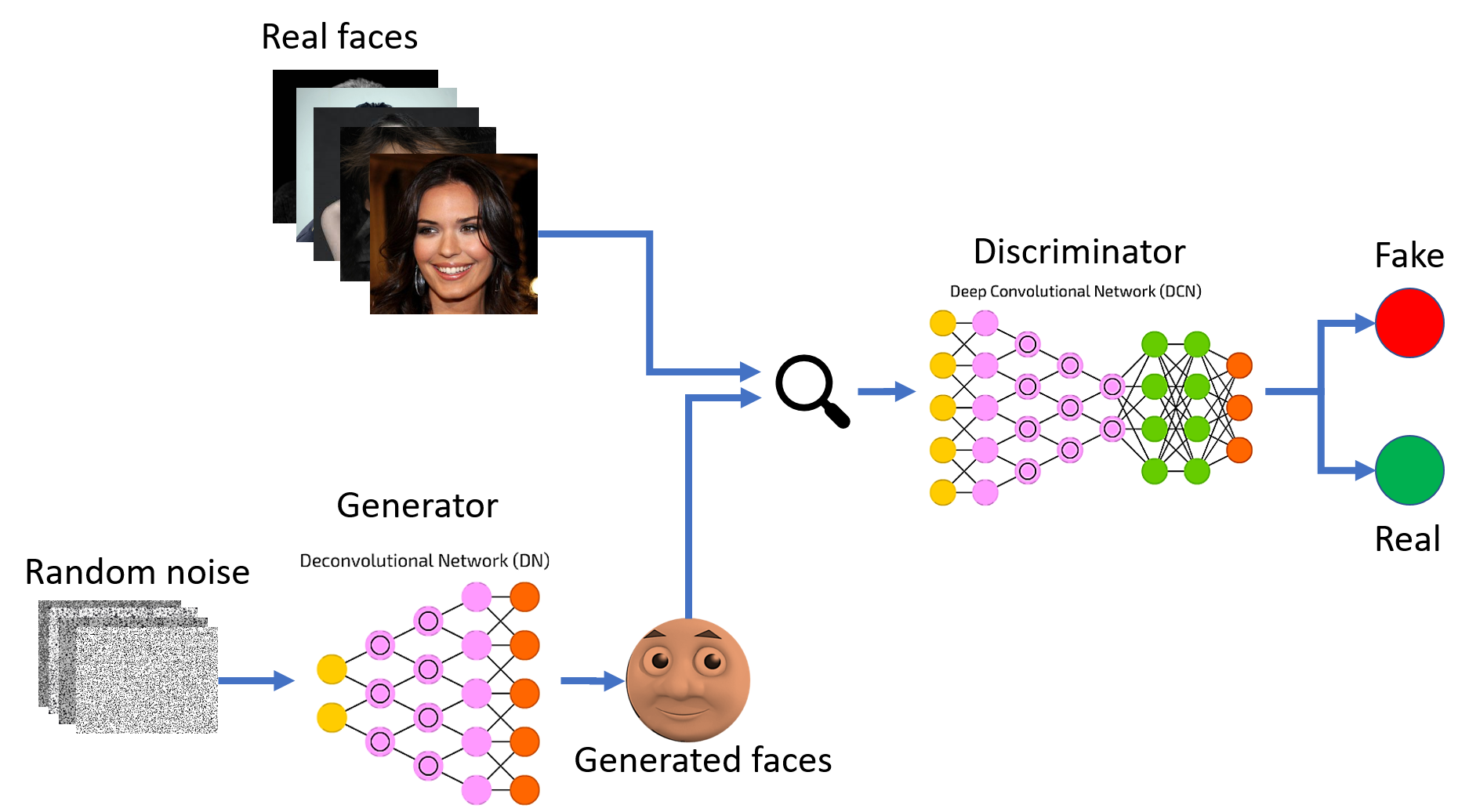
生成对抗网络(Generative Adversarial Networks, GANs)是一种由两个神经网络相互对抗组成的深度学习模型:生成器(Generator)和判别器(Discriminator)。这两个网络在训练过程中互相竞争,通过这种对抗性的训练机制,使得生成器可以产生高度逼真的数据样本,而判别器则不断提高区分生成样本和真实样本的能力。
生成器(Generator):生成器的主要任务是从随机噪声中生成逼真的数据样本。它接收一个随机向量(通常是从正态分布中采样的噪声)作为输入,通过一系列的神经网络层,生成一个假样本(如图像或视频帧)。生成器的目标是迷惑判别器,使其无法区分生成样本与真实样本。
判别器(Discriminator):判别器的任务是区分真实数据和生成数据。它接收真实数据样本和生成数据样本作为输入,通过一系列的神经网络层,输出一个概率值,表示输入样本是来自真实数据还是生成数据。判别器的目标是尽可能准确地将真实样本和生成样本区分开来。
工作原理
GANs的工作机制可以理解为生成器和判别器之间的博弈过程。在这个过程中,生成器试图生成尽可能逼真的样本,以欺骗判别器;而判别器则不断优化自身,以提高区分真假样本的能力。整个过程可以通过以下步骤详细描述:
初始化:生成器和判别器的参数初始化,生成器生成初始样本,判别器初步尝试区分真实样本和生成样本。
生成器训练:生成器接收一个随机噪声向量作为输入,生成一个假样本。生成器的目标是最大化判别器错误分类的概率,即让判别器认为生成的假样本是真实的。这通过最小化生成器的损失函数来实现。
判别器训练:判别器同时接收真实样本和生成样本作为输入,通过计算两个样本的损失函数来优化其参数。判别器的目标是最大化区分真实样本和生成样本的准确率,即最小化判别器的损失函数。
对抗训练:在一个训练步骤中,生成器和判别器交替更新各自的参数。生成器优化其参数以生成更逼真的样本,判别器优化其参数以提高区分样本的准确性。
收敛:随着训练的进行,生成器生成的样本越来越逼真,判别器区分真假样本的能力也不断提高。当生成器生成的样本与真实样本难以区分时,模型达到一种动态平衡,即收敛。
GANs的这种对抗性训练机制,使得生成器能够在不断的试错过程中学会生成高质量的数据样本,同时也推动了判别器不断提升其判别能力。通过这种方式,GANs在图像和视频的生成、修复、增强等方面展现了强大的潜力。
3. 🤖GANs在图像生成中的应用
图像超分辨率
图像超分辨率是通过提高图像的分辨率来增加图像的清晰度和细节。GANs中常用的结构是基于生成对抗网络的超分辨率方法(SRGAN)。
工作原理
- 生成器网络:生成器接收低分辨率图像作为输入,输出高分辨率图像。
- 判别器网络:判别器评估生成器输出的图像与真实高分辨率图像之间的差异。
# 导入必要的库 import tensorflow as tf from tensorflow.keras.layers import Conv2D, Input from tensorflow.keras.models import Model # 定义生成器网络 def generator(): # 输入层 inputs = Input(shape=(None, None, 3)) # 特征提取层 x = Conv2D(64, 9, padding='same', activation='relu')(inputs) x = Conv2D(64, 3, padding='same', activation='relu')(x) # 残差块 for _ in range(16): x = residual_block(x) # 上采样层 x = Conv2D(64, 3, padding='same', activation='relu')(x) x = Conv2D(256, 3, padding='same')(x) x = tf.nn.depth_to_space(x, 2) # 输出层 outputs = Conv2D(3, 9, padding='same', activation='tanh')(x) # 创建模型 return Model(inputs, outputs) # 定义残差块 def residual_block(x): y = Conv2D(64, 3, padding='same', activation='relu')(x) y = Conv2D(64, 3, padding='same')(y) return tf.keras.layers.add([x, y]) # 创建生成器模型 gen_model = generator() gen_model.summary()图像去噪
图像去噪是指消除图像中的噪声,以提高图像的质量和清晰度。GANs可以通过生成器网络学习如何从带有噪声的图像中生成干净的图像。
工作原理
- 生成器网络:生成器接收带有噪声的图像作为输入,输出去噪后的图像。
- 判别器网络:判别器评估生成器输出的图像与真实干净图像之间的差异。
下方代码演示了如何使用基于GANs的方法进行图像去噪。这里使用了PyTorch和GANs库,但是实际上,GANs在图像去噪领域上的应用可能会更加复杂和深入。
import torch import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms from torchvision import datasets # 定义生成器网络 class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.model = nn.Sequential( nn.Linear(100, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 512), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 1024), nn.LeakyReLU(0.2, inplace=True), nn.Linear(1024, 28*28), nn.Tanh() ) def forward(self, z): img = self.model(z) return img.view(img.size(0), 1, 28, 28) # 定义判别器网络 class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Linear(28*28, 1024), nn.LeakyReLU(0.2, inplace=True), nn.Linear(1024, 512), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 1), nn.Sigmoid() ) def forward(self, img): flattened_img = img.view(img.size(0), -1) validity = self.model(flattened_img) return validity # 超参数 batch_size = 64 lr = 0.0002 b1 = 0.5 b2 = 0.999 n_epochs = 200 # 初始化网络 generator = Generator() discriminator = Discriminator() optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2)) optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2)) adversarial_loss = nn.BCELoss() # 数据加载和预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ]) dataloader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=True, download=True, transform=transform), batch_size=batch_size, shuffle=True) # 训练网络 for epoch in range(n_epochs): for i, (imgs, _) in enumerate(dataloader): # 真实数据 real_imgs = imgs.view(imgs.size(0), -1) # 训练判别器 optimizer_D.zero_grad() z = torch.randn(batch_size, 100) fake_imgs = generator(z) real_validity = discriminator(real_imgs) fake_validity = discriminator(fake_imgs) d_loss = adversarial_loss(real_validity, torch.ones_like(real_validity)) + \ adversarial_loss(fake_validity, torch.zeros_like(fake_validity)) d_loss.backward() optimizer_D.step() # 训练生成器 optimizer_G.zero_grad() z = torch.randn(batch_size, 100) gen_imgs = generator(z) validity = discriminator(gen_imgs) g_loss = adversarial_loss(validity, torch.ones_like(validity)) g_loss.backward() optimizer_G.step() # 打印训练信息 if i % 100 == 0: print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, n_epochs, i, len(dataloader), d_loss.item(), g_loss.item()))图像修复与填充
图像修复与填充是指修复受损图像中的缺失部分。GANs可以通过生成器网络学习如何从受损图像中生成完整的图像。
工作原理
- 生成器网络:生成器接收受损图像作为输入,输出修复后的图像。
- 判别器网络:判别器评估生成器输出的图像与真实完整图像之间的差异。
4. 🚀GANs在视频技术中的应用
视频生成
GANs在视频生成方面取得了显著进展。通过训练生成器网络来生成连续的视频帧,GANs可以用于创建虚拟场景、增强视频内容以及制作电影特效。这种技术为虚拟现实、视频游戏和电影制作等领域提供了新的可能性。
视频超分辨率
视频超分辨率是指将低分辨率视频转换为高分辨率视频的技术。GANs在视频超分辨率方面的应用已经取得了重要进展。通过学习视频帧之间的时空关系,GANs可以生成高质量的高分辨率视频,从而提高视频的质量和清晰度。
视频修复与去噪
GANs在视频修复和去噪方面也有着广泛的应用。通过训练生成器网络来恢复受损或缺失的视频帧,同时利用判别器网络来评估修复后的视频帧与真实视频帧之间的差异,GANs可以实现视频的修复和去噪。这种技术可以用来修复老旧视频、去除视频中的噪声以及提高视频质量。
深度伪造视频
深度伪造视频是指利用深度学习技术生成逼真的假视频,如Deepfake。这种技术可以用于影视特效和创意艺术等领域,但也带来了一些伦理和法律上的问题。深度伪造视频技术可能被滥用于制作虚假视频,可能导致信息误传和社会问题。

5.❓ 面临的挑战与解决方案
技术挑战
模式崩溃(Mode Collapse): GANs在训练过程中可能会出现模式崩溃问题,即生成器倾向于生成类似的样本而缺乏多样性。
训练不稳定性: GANs的训练过程可能不稳定,导致生成器和判别器之间的博弈无法达到理想状态,甚至可能导致训练失败。
梯度消失和梯度爆炸: GANs的训练过程中可能会出现梯度消失或梯度爆炸问题,使得网络无法有效地学习。
模式骤变(Mode Collapse): GANs在处理复杂数据集时,可能会出现模式骤变问题,即生成器只学习到数据集的部分模式而忽略了其他模式。
解决方案
生成器和判别器的平衡: 可以通过调整生成器和判别器的架构和超参数来平衡它们之间的博弈,从而避免模式崩溃问题。
增加样本多样性: 可以通过增加数据集的多样性或调整损失函数来促进生成器生成多样化的样本。
使用正则化技术: 可以使用正则化技术如权重约束、批量归一化等来减轻训练不稳定性问题。
改进的优化算法: 可以使用改进的优化算法如Adam、RMSProp等来解决梯度消失和梯度爆炸问题。
多尺度训练: 可以使用多尺度训练技术来提高模型的稳定性和生成效果。
对抗训练技巧: 使用对抗训练技巧如生成器和判别器的周期性更新,以及渐进式增强网络的训练方法,来改善训练过程的稳定性和生成效果。
虽然GANs在图像和视频技术中有着广泛的应用前景,但仍然面临着一些挑战,需要不断地研究和改进才能更好地发挥其潜力。

6. 💡未来发展趋势与前景展望
未来,生成对抗网络(GANs)在图像和视频技术中的应用前景广阔,但也面临一些挑战和问题。
技术趋势: GANs在图像和视频技术中的发展趋势将主要体现在以下几个方面:
- 生成质量和稳定性的提高: 随着算法和模型的不断优化,生成图像和视频的质量将更加接近真实,训练过程也将更加稳定。
- 多模态生成能力: 未来的GANs模型将具备更强的多模态生成能力,能够同时生成多个领域(如图像、文本、音频等)的内容。
- 实时生成与交互性应用: 随着计算能力的提升,未来GANs将能够实现更快速的实时生成,支持更多交互性应用场景。
应用前景: GANs在未来将在各个领域中发挥重要作用,包括但不限于影视制作、医学影像分析、虚拟现实、艺术创作等领域。GANs的应用将带来更高效、更创新的解决方案,推动技术和产业的发展。
伦理与法律问题: 随着GANs技术的应用,可能会引发一些伦理和法律问题,如虚假信息和隐私问题、知识产权和版权问题、道德问题等。因此,需要加强监管和法律规范,确保其应用的合法和道德性。
综上所述,GANs在图像和视频技术中的应用前景广阔,但也需要注意解决相关的技术、伦理和法律问题,以推动其健康、可持续发展。
