
阅读量:6
前言
上一章中完成了faster-rcnn(jwyang版本)的复现,本节将在此基础进一步训练自己的数据集~
项目地址:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
复现环境:autodl服务器+python3.6+cuda11.3+Ubuntu20.04+Pytorch1.10.0
往期回顾
Autodl服务器中Faster-rcnn(jwyang)复现(一)
目录
一、数据准备
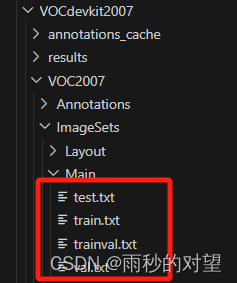
第一步:查看VOC数据集得文件夹tree结构
VOCdevkit2007 └── VOC2007 ├── Annotations ├── ImageSets │ └── Main │ ├── test.txt │ ├── train.txt │ ├── trainval.txt │ └── val.txt └── JPEGImages 其中Annotations内放xml标注文件,JPEGImages内放图片,ImageSets/Main/内的四个txt文件分别是测试集、训练集、训练验证集、验证集。自己数据集依然采用VOC2007数据集的类。
第二步:制作自己数据集
(1)把原来的图片删掉,位置是:
/root/faster-rcnn/data/VOCdevkit2007/VOC2007/JPEGImages 将自己数据集的图片上传至JPEGImages
(2)更改xml文件中属性值
用这个代码可以任意改变xml里的属性值,比如你想把xml文件中类别名称改变,或把图片名称、路径等值改变,参考以下代码
#这里只修改folder部分 import os import os.path import xml.dom.minidom path = "/home/zhangxin/faster-rcnn.pytorch/data/VOCdevkit/VOC2007/Annotations/" files = os.listdir(path) #得到文件夹下所有文件名称 for xmlFile in files: #遍历文件夹 if not os.path.isdir(xmlFile): #判断是否是文件夹,不是文件夹才打开 print(xmlFile) #将获取的xml文件名送入到dom解析 dom = xml.dom.minidom.parse(os.path.join(path, xmlFile)) #输入xml文件具体路径 root = dom.documentElement #获取标签<name>以及<folder>的值 name = root.getElementsByTagName('name') folder = root.getElementsByTagName('folder') #对每个xml文件的多个同样的属性值进行修改。此处将每一个<folder>属性修改为VOC2007 for i in range(len(folder)): print(folder[i].firstChild.data) folder[i].firstChild.data = 'VOC2007' print(folder[i].firstChild.data) #将属性存储至xml文件中 with open(os.path.join(path, xmlFile),'w') as fh: dom.writexml(fh) print('已写入') 这里修改folder部分,与VOC一样
完成后同样把原来的xml删掉,位置是:
/root/faster-rcnn/data/VOCdevkit2007/VOC2007/Annotations 将自己数据集的图片上传至Annotations
(3)自己制作trainval.txt,里面存储自己的待训练图片名称,记住不要带.jpg后缀,代码如下:
# !/usr/bin/python # -*- coding: utf-8 -*- import os import random trainval_percent = 0.8 #trainval占比例多少 train_percent = 0.7 #test数据集占比例多少 xmlfilepath = '/root/faster-rcnn/data/VOCdevkit2007/VOC2007/Annotations/' txtsavepath = '/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/' total_xml = os.listdir(xmlfilepath) num=len(total_xml) list=range(num) tv=int(num*trainval_percent) tr=int(tv*train_percent) trainval= random.sample(list,tv) train=random.sample(trainval,tr) ftrainval = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt', 'w') ftest = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt', 'w') ftrain = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/train.txt', 'w') fval = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/val.txt', 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest .close() 生成结果:
二、修改源代码
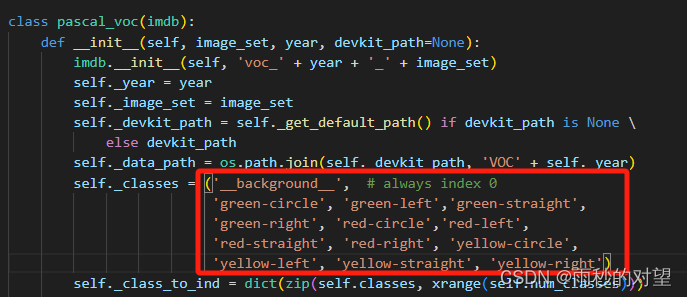
第一步:在lib\datasets\pascal_voc.py中更改self._classes中的类别,添加自己的类
三、开始训练
训练之前一定要激活自己创建的my-env虚拟环境
conda activate my-env 参考:Autodl服务器中Faster-rcnn(jwyang)复现
CUDA_VISIBLE_DEVICES=0 python trainval_net.py \ --dataset pascal_voc --net vgg16 \ --bs 4 --nw 0 \ --lr 0.002 \ --cuda 报错1
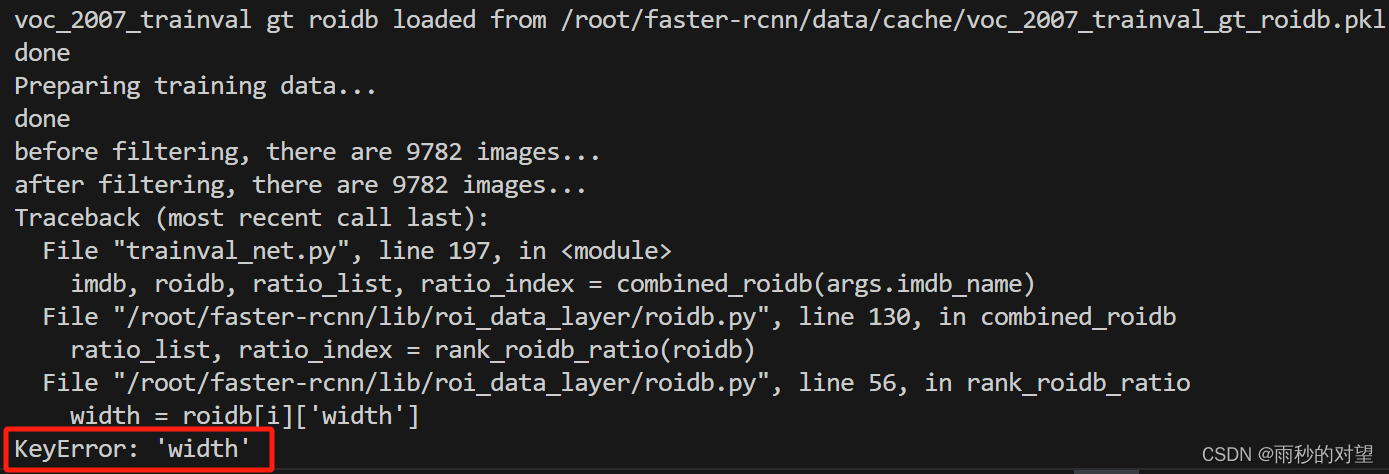
原因:在训练原数据集VOC时,图像数量是5964张(进行了数据增强),这时会保存训练信息至缓存中,文件路径为:/home/mw/faster-rcnn/data/cache/voc_2007_trainval_gt_roidb.pkl
解决:在重新训练新数据集的时候,会读取这个缓存配置,以加快训练,那么此时就入坑了,我的新集合只有994张,所以训练时读的缓存里,需要读的图像还是原来那5964张,那势必会找不到这5964张图像,所以要做的就是,把这个缓存文件voc_2007_trainval_gt_roidb.pkl删除报错2
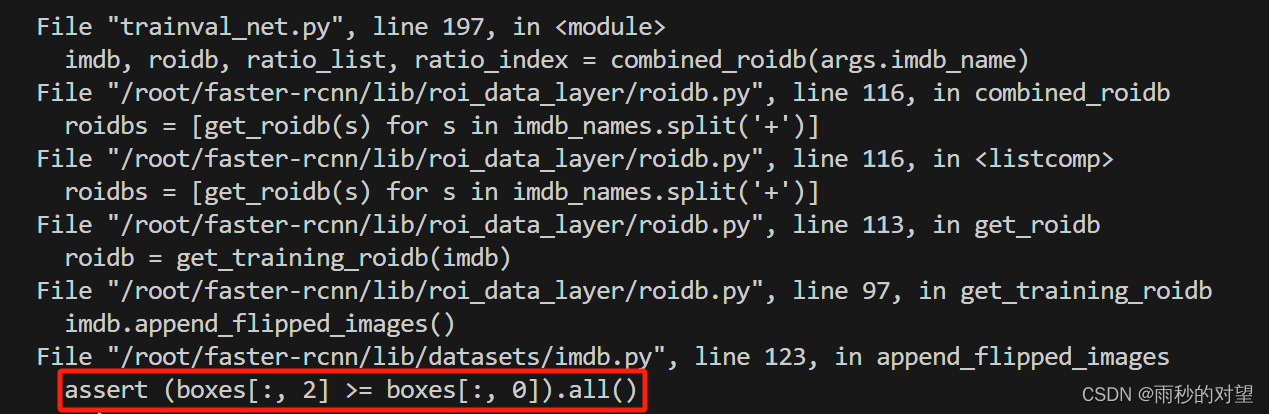
解决过程:https://blog.csdn.net/xzzppp/article/details/52036794
跑通如下:
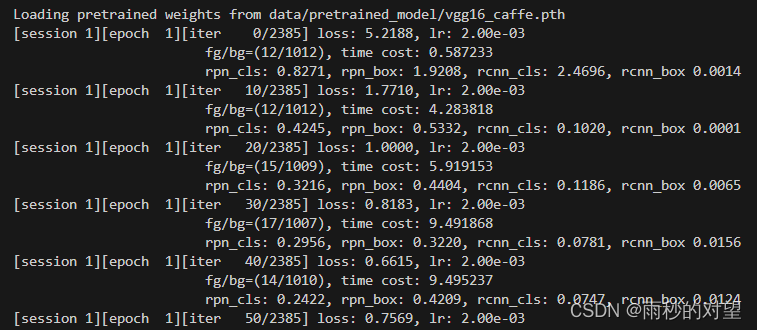
四、开始测试
python test_net.py --dataset pascal_voc --net vgg16 --checksession 1 --checkepoch 3 --checkpoint 2384 --cuda 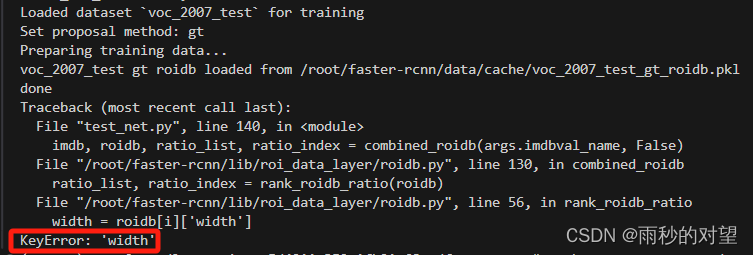
解决:与上述相似,把这个缓存文件/home/mw/faster-rcnn/data/cache/voc_2007_test_gt_roidb.pkl删除
效果如下:

在VOC上12个class的mAP为83.4%
五、开始推理
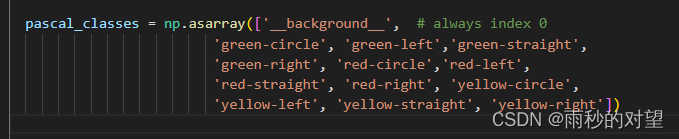
第一步:修改demo.py中pascal_classes类别
第二步:把几张测试图片放到images中
第三步:运行demo.py
python demo.py --net vgg16 --checksession 1 --checkepoch 3 --checkpoint 2384 --cuda --load_dir models 推理结果如下:

好了,到这一步关于faster-rcnn训练自己的数据集就结束了,完结撒花~
