
阅读量:2
HDFS的架构二
建议:按顺序往下读,并适当的时候停下思考!
启动流程
- HDFS搭建时会格式化,格式化操作会产生一个空的FsImage
- 当Namenode启动时,从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用在内存中的FsImage上,并将这个新版本的FsImage从内存中保存到本地磁盘上(以前旧的就失效了)
- 然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了
安全模式
- NameNode启动后会进入一个称为安全模式的特殊状态,处于安全模式的NameNode是不会进行数据块的复制的。
- Namenode从所有的 Datanode接收心跳信号和块状态报告。
- 每当Namenode检测确认某个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全的。
- 在一定百分比(这个参数可配置)的数据块被Namenode检测确认是安全之后(加上一个额外的等待时间,默认30秒),Namenode将退出安全模式状态。
- 接下来它会确定还有哪些数据块的副本没有达到指定数目,然后将这些数据块复制到其他DataNode上,使副本数达到要求。
为什么要安全模式?
首先我们知道 NameNode 不会存丢你的 块的位置信息,这不是没问题吗,但为什么还要这么做?
考虑一个场景:有一台DataNode就是启动不起来,然后
客户端刚好拿到这个错误的DataNode信息,导致数据一致性出问题
在分布式时代中,数据一致性最重要,源头是不能错宁可不存,等一个时间,等NameNode和DataNode建立“心跳”,数据一致性好了才对外提供服务
服务器的分类
服务器按性能(同时也是价格)分为三类:
- 塔式服务器:类似于台式机电脑的主机

- 机架式服务器:扁的

- 刀片式服务器

企业用得最多的还是:机架式的,空间利用率比塔式的高(可一层层叠),也没有刀片式的那么贵
机架式服务器的组成:机柜、电源、柜内交换机、柜间交换机,内部有多个服务器
缺点:交换机或电源崩了,这整个机柜就下线了
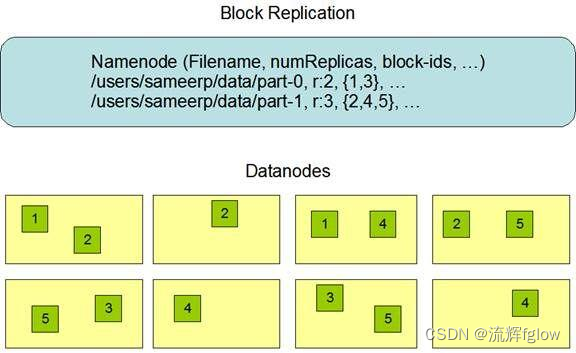
副本放置策略
- 第一个副本:放置在上传文件的DataNode所在节点(本地最快)
- 如果是在集群外的DataNode提交上传,则随机挑选一台磁盘不太满,CPU不太忙的节点
- 第二个副本(出机柜):放置在于第一个副本不同的 机架的节点上
- 因为副本数可能定义为2,不出机柜,一旦机柜出问题就都没了
- 第三个副本(同二):与第二个副本相同机架的节点
- 降低成本
- 更多的副本:随机节点
写流程
- 连接:
Client 找 NN 说上传一个文件,NN 会触发“副本放置策略”,给Client返回“副本数个”DataNode节点的位置(按距离有序的),如:A B C 三个节点
Client与首个(A)DN建立TCP连接,并把后续的节点(BC)发给该首结点(A)
首节点(A)与第二节点(B)建立TCP连接,并把后续的C发送给B节点
依次链式连接:这个链接是双向的,管道Pipeline/双向链表 - 传输:
Client把128M的block切割成更小的64K的包packet,加上一个校验和4B
开始传,把一个包传给首节点,内存一份、磁盘一份,内存那份再传给B,B同理给C,……
同时,Client又可传下一个packet给首节点了
即:流水线,变种的并行
好处:对Client来说,副本数是透明的,不管是多少个副本,时间都是传一个文件的时间 + 一点点
问题:有DN挂了怎么办?DN分两种位置
最后的,挂了就挂,影响很小
中间的,跳过去连接;前一个知道后面有什么,没有找到当前的就去后面的就可以了
如:B挂了,A是不是知道它后面有B和C,发现B挂了,又知道后面还有C,那么A就(跳过B)去连C就好了
存完一块就给NN汇报,最后当NN发现副本数不足,触发从随机一个DN拷贝出一份到别的DN,使达到规定的副本数
Client的业务就非常简单了,一股脑的传就行,屏蔽了NN内部的策略
完整的步骤:
Client和NN连接创建文件元数据
NN判定元数据是否有效(文件名、权限等)
NN处发副本放置策略,返回一个有序的DN列表
Client和DN建立Pipeline连接
Client将128M块切分成packet(64KB)Buffer,并使用chunk512B+chucksum4B填充
Client将packet放入发送队列dataqueue中,并向第一个DN发送
第一个DN收到packet后本地保存并发送给第二个DN
第二个DN收到packet后本地保存并发送给第三个DN
这一个过程中,上游节点同时发送下一个packet
即:流水线:流式其实也是变种的并行计算
HDFS使用这种传输方式,副本数对于Client是透明的
Tomcat结合HDFS,本地存一份,背后跟HDFS层Pipeline,感受不到副本
不用本地文件系统,而用HDFS;既能达到像本地文件的速度,又能达到多副本的可靠性(HBase就是巧妙地利用这点)
当block传输完成,DN们各自向NN汇报,同时Client继续传输下一个block
所以,Client的传输和DNblock的汇报也是并行的
一般业务的客户端都是在DataNode上的,文件切块是第一个DN做的
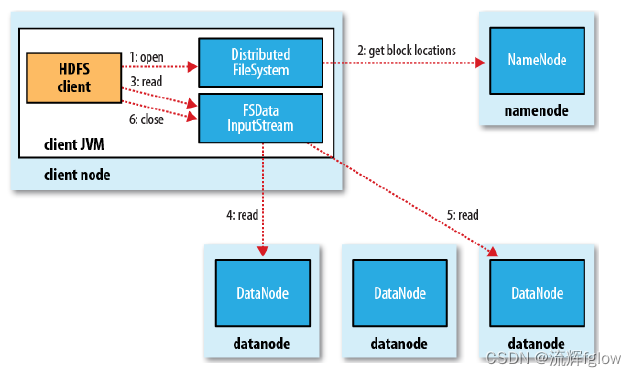
读流程
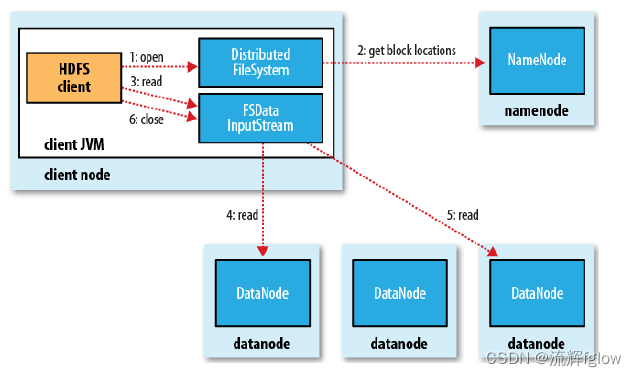
看上去很简单,实际上很精妙
过程:
Client和NN联系,取回块的信息列表,选择最近的DN挨个读块,DN从磁盘读到内存,通过网络返回
全集(全文件)可以,那么子集自然也可以
这件事是极有意义:并行计算,多个计算程序计算块,每个计算程序可以拿到自己想的块
HDFS 可暴露块的位置信息、偏移量,支持Client读取文件的任意位置,去NN拿到信息,跟DN连接,把块读给计算
这就是分布式
为了降低整体的带宽消耗和读取延时,HDFS会尽量让程序读取离它最近的副本
如果在读取程序的同一个机架上有另一个数据块副本,那么就读取这个
如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本
语义:下载一个文件:
Client和NN交互文件元数据获取fileBlockLocation
NN会按距离策略排序返回
Client尝试下载block并校验数据完整性
语义:下载一个文件其实是获取文件的所有的block元数据,那么子集获取某些block应该成立
==HDFS支持client给出文件的偏移量offset自定义连接哪些block的DN,自定义获取数据
这个是支持计算层的分治、并行计算的核心
