
阅读量:4
系列篇章💥
AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研
AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研
AI大模型探索之路-实战篇6:掌握Function Calling的详细流程
AI大模型探索之路-实战篇7:Function Calling技术实战自动生成函数
AI大模型探索之路-实战篇8:多轮对话与Function Calling技术应用
AI大模型探索之路-实战篇9:探究Agent智能数据分析平台的架构与功能
AI大模型探索之路-实战篇10:数据预处理的艺术:构建Agent智能数据分析平台的基础
目录
一、前言
在数据驱动的时代,拥有一个高效且智能的数据分析平台对企业至关重要。继本系列前文全面解析Agent智能数据分析平台的基础与核心功能后,本文深入讨论平台的实际操作,特别是如何应用Function Calling技术整合数据、提升分析的效率与准确性。实战经验的分享,将助读者构建完善的数据处理流程,利用Function Calling增强数据质量与分析精度,同时探索结合大模型API以提供传统及智能化分析服务,从而大幅提升决策支持能力。
二、Function Calling技术整合
随着数据成功存储入库,下一步关键是实施一个高效的函数调用机制,此机制将使不同的数据分析工具和服务能够无缝地访问和操作这些数据。
1、安装mysql依赖
确保Python环境安装了所有必要的MySQL驱动程序和连接库,以便我们可以从Python脚本中直接访问MySQL数据库。
! pip install pymysql 2、创建mysql连接
通过编写函数建立到MySQL数据库的稳定连接,这是后续所有数据操作的基础
import pymysql mysql_pw = "iquery_agent" # 建立连接 connection = pymysql.connect( host='localhost', # 数据库地址 user='iquery_agent', # 数据库用户名 passwd=mysql_pw, # 数据库密码 db='iquery', # 数据库名 charset='utf8' # 字符集选择utf8 ) 连接查看:
connection 
3、数据查询测试
我们编写并执行SQL查询,尝试从数据库中检索数据,以测试连接的实际工作情况
# 定义SQL查询语句,从iquery.user_demographics表中获取前10条数据 sql_query = "SELECT * FROM iquery.user_demographics LIMIT 10" cursor = connection.cursor() # 使用游标对象执行SQL查询语句 cursor.execute(sql_query) 输出:10
获取查询结果
# 获取查询结果 results = cursor.fetchall() results 输出:
(('0003-MKNFE', 'Male', 0, 'No', 'No'), ('0004-TLHLJ', 'Male', 0, 'No', 'No'), ('0011-IGKFF', 'Male', 1, 'Yes', 'No'), ('0013-EXCHZ', 'Female', 1, 'Yes', 'No'), ('0013-SMEOE', 'Female', 1, 'Yes', 'No'), ('0015-UOCOJ', 'Female', 1, 'No', 'No'), ('0017-DINOC', 'Male', 0, 'No', 'No'), ('0017-IUDMW', 'Female', 0, 'Yes', 'Yes'), ('0019-EFAEP', 'Female', 0, 'No', 'No'), 4、获取查询结果的列信息
cursor.description 输出:
(('customerID', 253, None, 255, 255, 0, False), ('gender', 253, None, 255, 255, 0, True), ('SeniorCitizen', 3, None, 11, 11, 0, True), ('Partner', 253, None, 255, 255, 0, True), ('Dependents', 253, None, 255, 255, 0, True)) 5、数据格式转换
使用Python的pandas库将查询结果(results)和列名(column_names)转换为一个DataFrame对象
import pandas as pd # 获取列名(headers) column_names = [desc[0] for desc in cursor.description] # 使用results和column_names创建DataFrame df = pd.DataFrame(results, columns=column_names) df 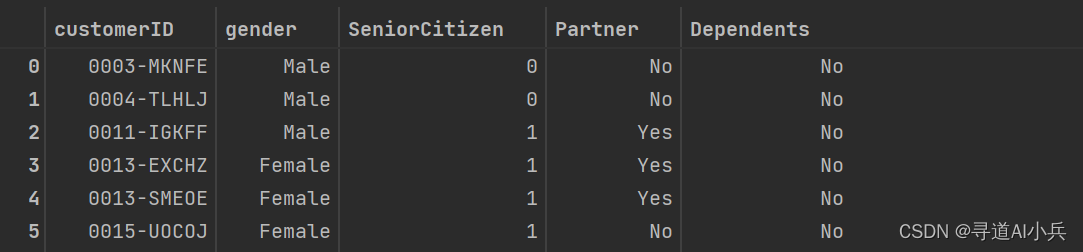
使用pd.read_sql()函数从数据库中读取数据,并将结果存储在DataFrame对象df_temp中。最后输出这个DataFrame对象
#关闭游标 cursor.close() sql_query = "SELECT * FROM user_demographics LIMIT 10" df_temp = pd.read_sql(sql_query, connection) df_temp 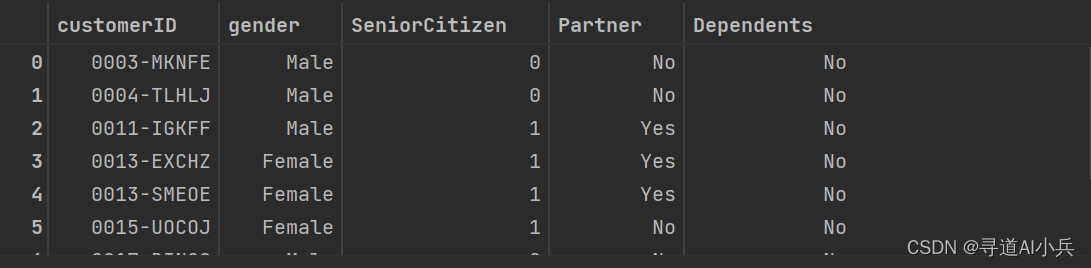
6、数据查询函数封装
为了提高代码的重用性和可维护性,我们将常用的数据查询和处理逻辑封装成函数
def get_user_demographics(sql_query): """ 用户获取user_demographics 表的相关信息 :param sql_query: 字符串形式的SQL语句 :return SQL查询的user_demographics 表的相关信息 """ mysql_pw="iquery_agent" connection = pymysql.connect( host='localhost', # 数据库地址 user='iquery_agent', # 数据库用户名 passwd=mysql_pw, # 数据库密码 db='iquery', # 数据库名 charset='utf8' # 字符集选择utf8 ) try: with connection.cursor() as cursor: sql = sql_query cursor.execute(sql) results = cursor.fetchall() finally: cursor.close() column_names = [desc[0] for desc in cursor.description] # 使用results和column_names创建DataFrame df = pd.DataFrame(results, columns=column_names) return df.to_json(orient = "records") 函数测试
sql_query = "SELECT * FROM user_demographics LIMIT 10" get_user_demographics(sql_query) 输出:
'[{"customerID":"0003-MKNFE","gender":"Male","SeniorCitizen":0,"Partner":"No","Dependents":"No"},{"customerID":"0004-TLHLJ","gender":"Male","SeniorCitizen":0,"Partner":"No","Dependents":"No"},{"customerID":"0011-IGKFF","gender":"Male","SeniorCitizen":1,"Partner":"Yes","Dependents":"No"},{"customerID":"0013-EXCHZ","gender":"Female","SeniorCitizen":1,"Partner":"Yes","Dependents":"No"},{"customerID":"0013-SMEOE","gender":"Female","SeniorCitizen":1,"Partner":"Yes","Dependents":"No"},{"customerID":"0015-UOCOJ","gender":"Female","SeniorCitizen":1,"Partner":"No","Dependents":"No"},{"customerID":"0017-DINOC","gender":"Male","SeniorCitizen":0,"Partner":"No","Dependents":"No"},{"customerID":"0017-IUDMW","gender":"Female","SeniorCitizen":0,"Partner":"Yes","Dependents":"Yes"},{"customerID":"0019-EFAEP","gender":"Female","SeniorCitizen":0,"Partner":"No","Dependents":"No"},{"customerID":"0019-GFNTW","gender":"Female","SeniorCitizen":0,"Partner":"No","Dependents":"No"}]' 7、funcation函数生成器
创建一个功能强大的函数生成器,使我们能够快速生成特定的数据查询函数,以适应不同的数据分析需求。
import openai import os import numpy as np import pandas as pd import json import io from openai import OpenAI import inspect openai.api_key = "xx" openai.api_base="https://a.b.c/v1" client = OpenAI(api_key=openai.api_key ,base_url=openai.api_base) def auto_functions(functions_list): """ Chat模型的functions参数编写函数 :param functions_list: 包含一个或者多个函数对象的列表; :return:满足Chat模型functions参数要求的functions对象 """ def functions_generate(functions_list): # 创建空列表,用于保存每个函数的描述字典 functions = [] # 对每个外部函数进行循环 for function in functions_list: # 读取函数对象的函数说明 function_description = inspect.getdoc(function) # 读取函数的函数名字符串 function_name = function.__name__ system_prompt = '以下是某的函数说明:%s' % function_description user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\ 1.字典总共有三个键值对;\ 2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\ 3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\ 4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\ 5.输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % function_name response = client.chat.completions.create( model="gpt-4-0613", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt} ] ) json_function_description=json.loads(response.choices[0].message.content.replace("```","").replace("json","")) json_str={"type": "function","function":json_function_description} functions.append(json_str) return functions max_attempts = 4 attempts = 0 while attempts < max_attempts: try: functions = functions_generate(functions_list) break # 如果代码成功执行,跳出循环 except Exception as e: attempts += 1 # 增加尝试次数 print("发生错误:", e) if attempts == max_attempts: print("已达到最大尝试次数,程序终止。") raise # 重新引发最后一个异常 else: print("正在重新运行...") return functions 8、funcation函数生成测试
通过一系列的测试用例来验证新生成的函数的正确性和效率,确保它们在实际使用中能够达到预期的效果。
functions_list = [get_user_demographics] tools = auto_functions(functions_list) tools 
9、大模型API调用
OpenAI API调用,检查确认大模型是否能够找到工具函数
messages=[ {"role": "user", "content": "请问user_demographics表中一共有多少条数据?"} ] response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", ) response.choices[0].message 输出:
ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_glXpKDrcgQA2E8OQSTEk9r19', function=Function(arguments='{"sql_query":"SELECT COUNT(*) FROM user_demographics"}', name='get_user_demographics'), type='function')]) 10、大模型调用封装
我们对大模型的调用过程进行封装,使其更加稳定且易于在其他分析流程中复用
def run_conversation(messages, functions_list=None, model="gpt-3.5-turbo"): """ 能够自动执行外部函数调用的对话模型 :param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象 :param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象 :param model: Chat模型,可选参数,默认模型为gpt-3.5-turbo :return:Chat模型输出结果 """ # 如果没有外部函数库,则执行普通的对话任务 if functions_list == None: response = client.chat.completions.create( model=model, messages=messages, ) response_message = response.choices[0].message final_response = response_message.content # 若存在外部函数库,则需要灵活选取外部函数并进行回答 else: # 创建functions对象 tools = auto_functions(functions_list) # 创建外部函数库字典 available_functions = {func.__name__: func for func in functions_list} # 第一次调用大模型 response = client.chat.completions.create( model=model, messages=messages, tools=tools, tool_choice="auto", ) response_message = response.choices[0].message tool_calls = response_message.tool_calls if tool_calls: messages.append(response_message) for tool_call in tool_calls: function_name = tool_call.function.name function_to_call = available_functions[function_name] function_args = json.loads(tool_call.function.arguments) function_response = function_to_call(**function_args) messages.append( { "tool_call_id": tool_call.id, "role": "tool", "name": function_name, "content": function_response, } ) ## 第二次调用模型 second_response = client.chat.completions.create( model=model, messages=messages, ) # 获取最终结果 final_response = second_response.choices[0].message.content else: final_response = response_message.content return final_response 11、调用测试
通过多个实际的案例测试大模型的功能,确保在不同的数据分析场景下都能得到准确可靠的结果。
messages=[ {"role": "user", "content": "请问user_demographics表中一共有多少条数据?"} ] model="gpt-3.5-turbo" run_conversation(messages=messages,functions_list=functions_list,model = model) 第二次测试:
messages=[ {"role": "user", "content": "请问user_demographics表中第一条数据的内容是什么?"} ] model="gpt-3.5-turbo" run_conversation(messages=messages,functions_list=functions_list,model = model) 第三次测试:
messages=[ {"role": "user", "content": "请问user_demographics表中男性和女性的占比分别是多少?"} ] model="gpt-3.5-turbo" run_conversation(messages=messages,functions_list=functions_list,model = model) 三、结语
通过上文的介绍和指导,我们已经能够构建出一个具备完整数据处理流程的Agent智能数据分析平台。利用Function Calling技术进行高效的数据整合,每一步都旨在提升数据的质量及分析的准确性。此外,通过整合大模型API,我们的平台不仅能提供传统的数据分析服务,还能探索智能化的数据洞察生成,极大地提高了决策支持的能力。随着技术的不断进步,这个平台将在未来发挥更大的作用,帮助企业在数据波涛中稳扬帆行,捕捉每一个商机。我们期待与读者共同见证这个平台在未来数据分析和决策支持领域中的成长与突破。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
