
阅读量:2
前言
对于数据结构的线性表,其元素在逻辑结构上都是序列关系,即数据元素之间有前驱和后继关系。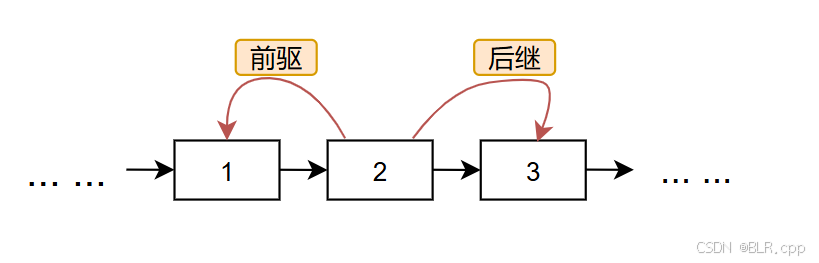
但在物理结构上有两种存储方式:
顺序存储结构:
- 使用此结构的线性表也叫 顺序表
- 物理存储上是连续的,因此可以随机访问,时间复杂度为 O(1)

链式存储结构:
- 使用此结构的线性表也叫 链表
- 物理存储上不连续,因此不支持随机访问

接下来要介绍的就是 链表。
链表分为 单向链表(单链表)与 双向链表(双链表),理解了单链表,双链表自然也明白了。
1. 什么是单链表
1.1 定义
链表由一系列的节点组成(链表中的每个元素都可称为节点),对于单链表而言,它的节点包含两部分:
- 数据域:存储当前节点的数据
- 指针域:存储当前节点的下一个节点(后继节点)的地址
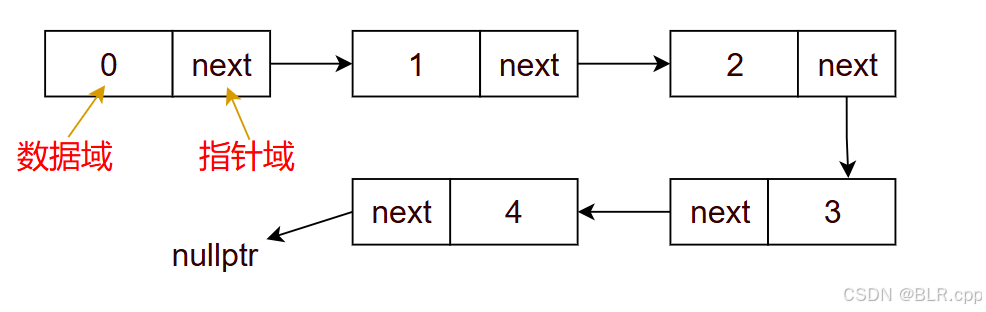
那么现在定义单链表 SingleList 的节点 Node:
1.2 创建 Node
struct Node { int val; // 数据域 Node* next; // 指针域:指向的是 Node,所以类型为 Node* }; 这么定义的 Node 类只能接收数据类型为 int 的数据,对于其他类型的数据当前的类不能处理,因此为了代码的通用性,将 Node 定义为模版类:
template <typename T> struct Node { T val; // 数据域 Node* next; // 指针域 Node(T v, Node* n = nullptr) :val{ v }, next{ n } { } }; 为了方便初始化,Node 还增加了构造函数:一个节点肯定必须有数据域,但指针域可以为空(表示没有后继节点了)
那么我们可以如下创建节点:
Node<int> node2(2); // 数据域为:2 (int),指针域为空 Node<int> node1(1, &node2); // 数据域为:1,指针域为 node2 的地址 
1.3 创建 SingleList
从单链表的定义可以看出,单链表都会有:
- 头结点(head):第一个节点
- 尾结点(rear):最后一个节点

对于 SingleList 来说,我们显然需要能够访问链表中的所有节点。
对于一个节点来说,我们能得到两部分信息:
- 当前节点自身的值(数据域)
- 当前节点的下一个节点(指针域)
也就是说,我们只需要通过头结点,就可以访问该链表上的所有节点,并且不会越界。
当某一节点的后继节点为空时,说明当前节点是尾结点,不能在继续访问下一节点。
因此你可以在 SingleList 类中保存头结点,但是这会有一个问题:
如果当前单链表没有节点怎么办?
之前已经说明节点不能为空:一个节点肯定必须有数据域,但指针域可以为空。
显然保存头结点不是一个好的方法,那么我们可以保存 头指针。
头指针:指向头结点的指针
此时就可以
- 通过 头指针 访问 头结点,进而访问所有节点。
- 当 头指针 为 nullptr 时,说明当前单链表没有节点。
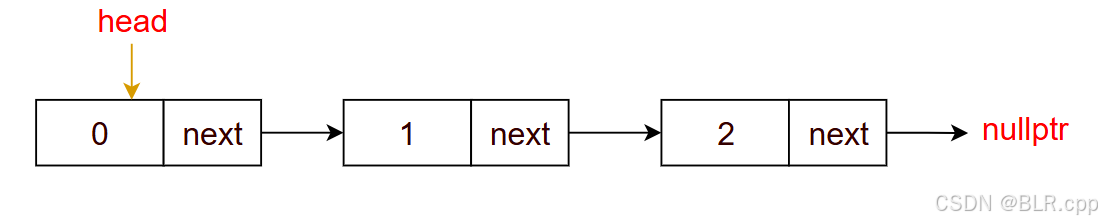
由于 Node 为模版类,因此 SingleList 也为模板类:
template <typename T> class SingleList { public: SingleList() = default; // 默认构造空单链表 private: Node<T>* head = nullptr; }; 下面来实现一些单链表经常会用到的操作:
2 SingleList 的操作
接下来的操作会涉及到指针的相关操作,使用不当很容易导致 bug
补充 SingleList 类:
template <typename T> class SingleList { public: SingleList() = default; // 成员变量为指针,析构时需要释放内存 ~SingleList(); // 返回节点数 int size() const; // 返回 i 位置的节点值 int get(int i) const; // 头插法 void push_front(T t); // 尾插法 void push_back(T t); // 删除头结点 void pop_front(); // 删除尾结点 void pop_back(); // 在 i 位置插入 void insert(int i, T t); // 删除 i 位置的节点 void erase(int i); private: Node<T>* head = nullptr; }; 2.1 size()
作用:求链表的节点个数
在此之前先来看如何遍历链表:
head 为 类指针('Node<...>*'), 可以通过 '->' 去访问类的成员 'head->next' <==> '(*head).next' 对于下面的链表有: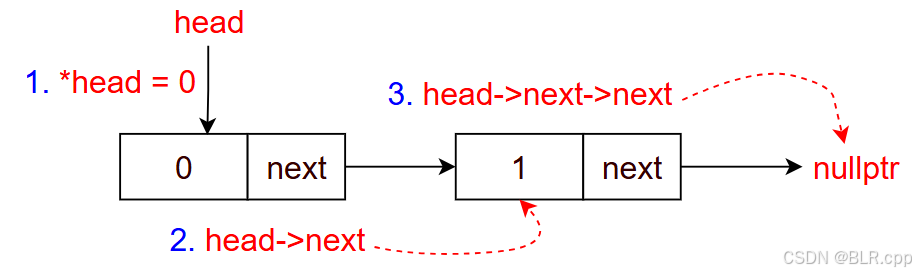
换言之可以通过 head 访问所有节点,那么用一个临时变量 node 来拷贝一份 head,用 node 来遍历链表:
auto node = head; while (node != nullptr) { // node == nullptr 说明 node 为尾结点的下一个节点(空) cout << node->val << endl; node = node->next; // 将 node 后移一个节点 } 用上面的例子来分析此程序:
首先拷贝 head
auto node = head;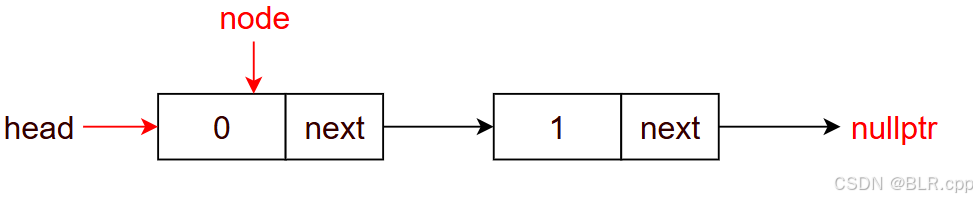
因为 node != nullptr,故进入 while 循环
此时 node 指向第一个节点,node->val = 0,此时有
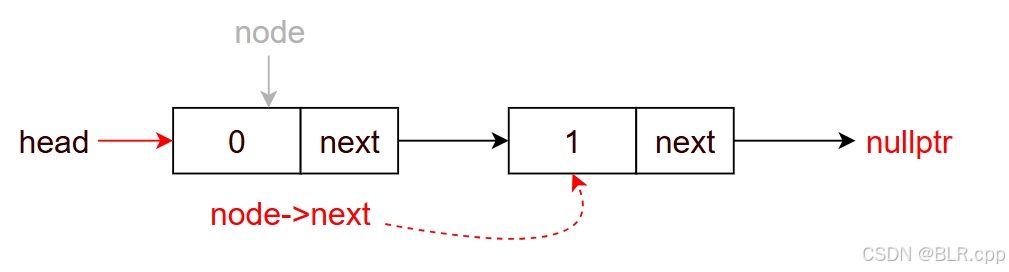
node = node->next
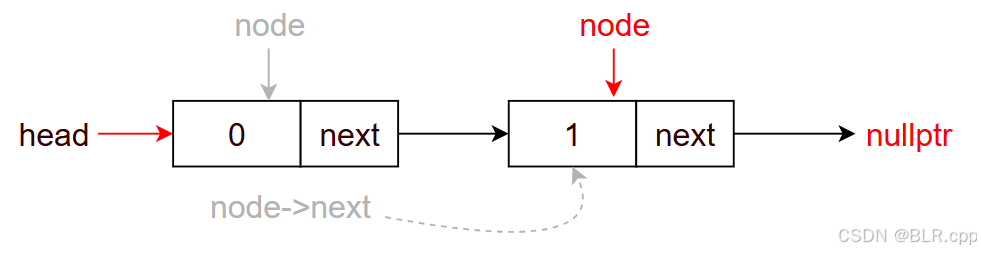
由于 node != nullptr,进入下一次循环
此时 node 指向第二个节点,node->val = 1,此时有
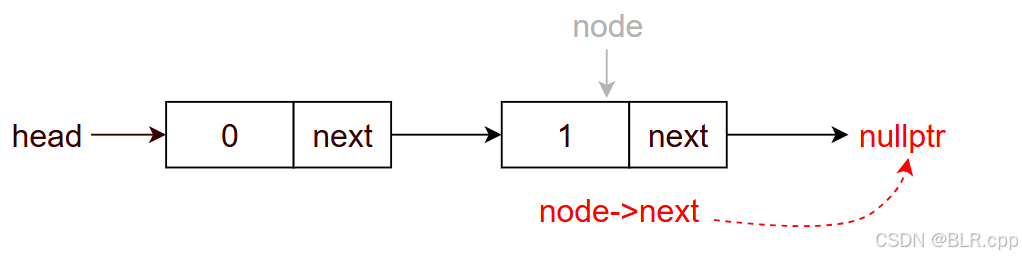
执行 node = node->next
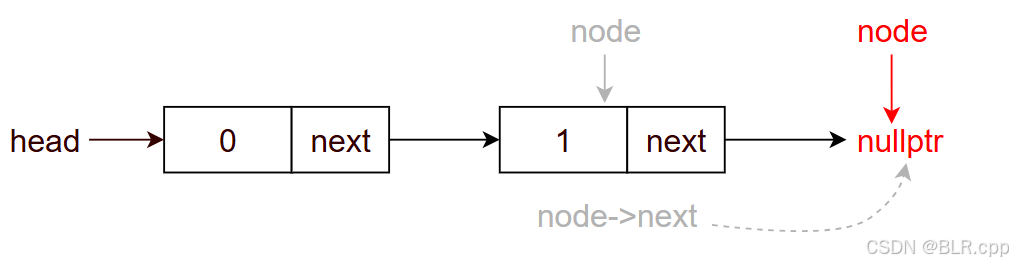
此时 node == nullptr,退出循环
因此可以 size() 函数实现如下:
下面的所有成员函数都是在类内部实现的
int size() const { auto node = head; int res = 0; while (node != nullptr) { res++; node = node->next; } return res; } 【注】为什么不直接用 head 进行遍历,而用一个临时指针?
如果用 head 进行遍历:
while (head != nullptr) { cout << node->val << endl; head = head->next; } 根据前面的分析,如果链表中有节点,采用此方法会造成最后 head 指向链表的尾结点的下一个节点(nullptr),那么之后 head 就无法用来遍历此链表了,即此链表 “丢失” 了。
在链表的插入与删除操作,需要特别注意先后顺序。
2.2 push_front(T t)
作用:头插法,在链表的头部插入一个节点
设待插入节点为 node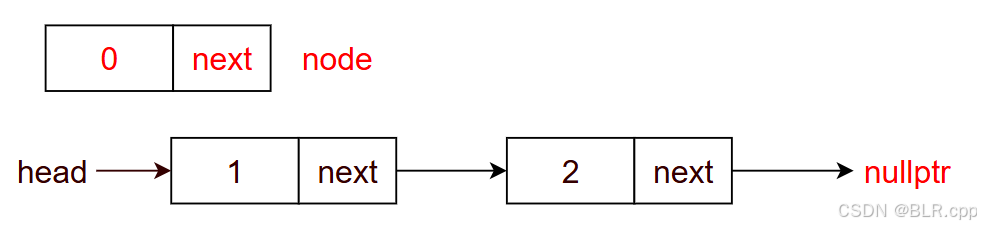
node->next = head
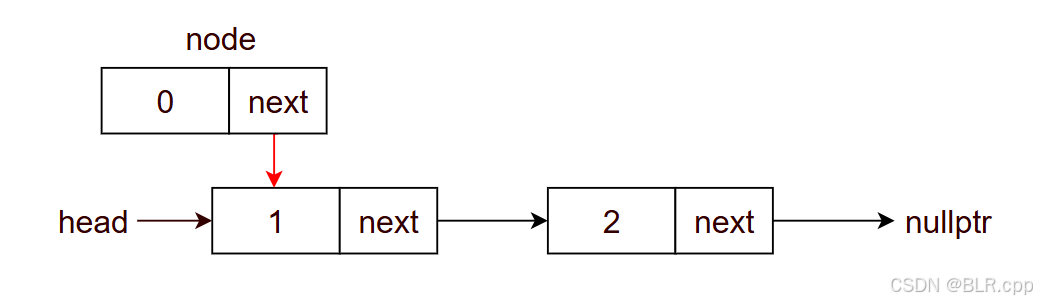
head = node
新加入的节点现在成为头结点了
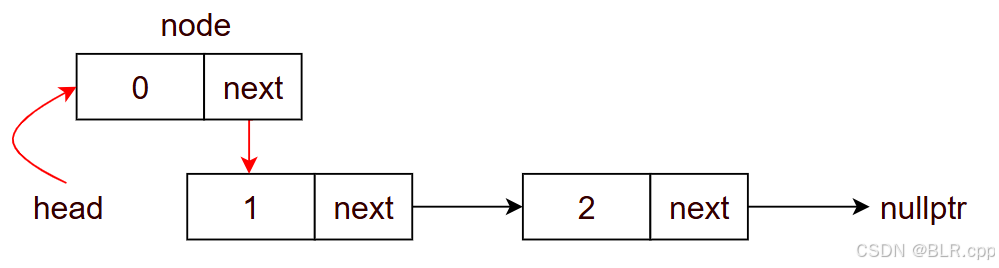
void push_front(T t) { Node<T>* node = new Node<T>(t); // 创建的是指针,需要 new 一块内存 node->next = head; head = node; } 为了用户更易于理解此单链表,从用户视角来看:他关心的仅仅是数据域;指针域用户不需要关心,由类的设计者来管理。因此函数 push_front 的参数应该是节点的数据域( push_front(T t) ),而不应该是节点 ( push_front(Node n) ),后面的几个函数也是如此。
【易错】node->next = head 与 head = node 的顺序不能颠倒。
如果颠倒了,那么:
初始状态:
head = node
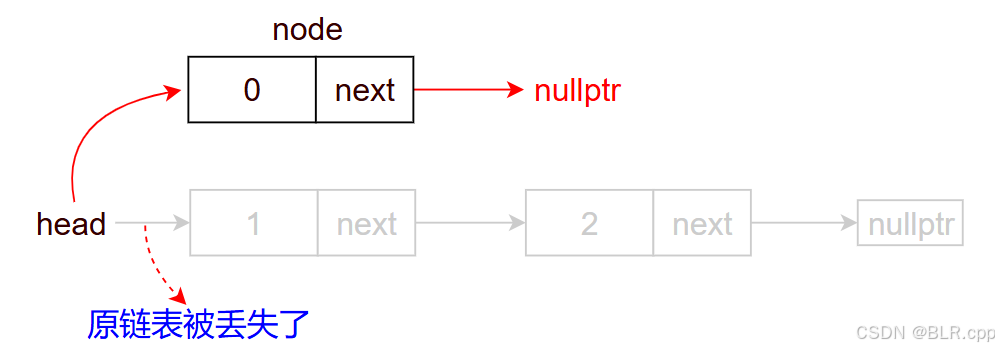
node->next = head
显然结果不对
不需要死记硬背,自己画图分析即可
2.3 push_back(T t)
作用:尾插法,在尾结点后面插入一个节点
只需要:将尾结点的 next 指向待插入节点即可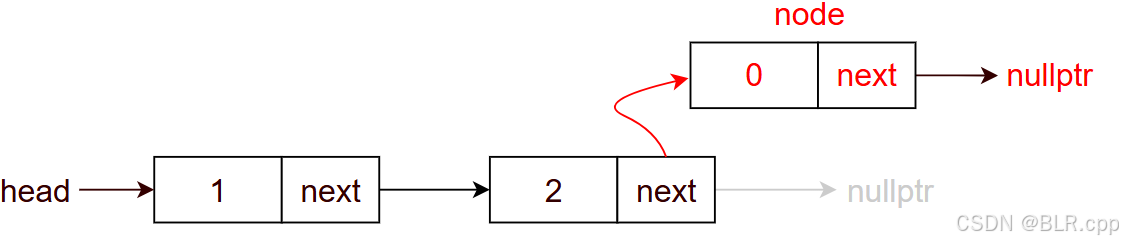
void push_back(T t) { Node<T>* node = new Node<T>(t); auto rear = head; while (rear->next != nullptr) { // 遍历找到尾结点 rear = rear->next; } rear->next = node; // 将尾结点的 next 指向待插入节点 } 2.4 pop_front()
作用:删除头结点
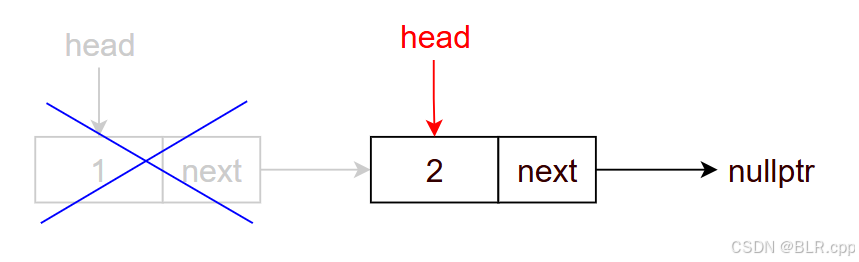
你可能直接如下实现:
void pop_front() { head = head->next; } 但是这存在 内存泄露 问题:被删除的指针所指的内存没有被释放。
void pop_front() { auto node = head; head = head->next; delete node; // 释放旧头指针 } 【注】 注意 delete node 的时机
来看下面代码:
void pop_front() { auto node = head; delete node; head = head->next; } 如果这样做,那么相当于
void pop_front() { delete head; head = head->next; } 先 delete head,那么此时 head 所指的内存已经被释放了,此时 head 的值就是一个随机值,之后再使用 head 就是没有意义的,会导致未定义行为,产生逻辑错误甚至程序直接崩溃。
后面涉及到 delete 的函数也需要考虑此问题
2.5 pop_back()
作用:删除尾结点
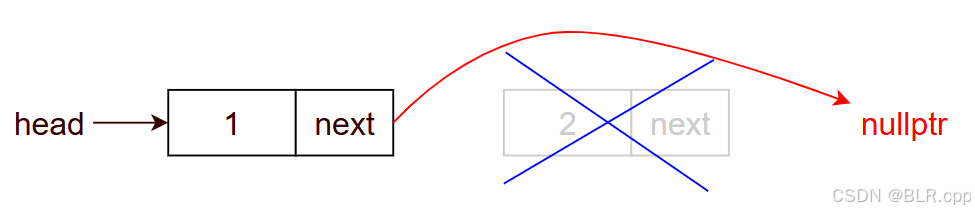
void pop_back() { auto rsecond = head; while (rsecond->next->next != nullptr) { // 得到尾结点的前一个节点 rsecond = rsecond->next; } delete rsecond->next; // 释放尾结点 rsecond->next = nullptr; } 需要注意释放完尾结点后,需要将现在的尾结点的 next 指向 nullptr,否则它将指向一块未定义的内存(随机值)。
insert 与 erase 函数涉及到中间节点的插入与删除,因此下面只讲解方法,所有的代码在文章最后
2.6 中间节点的插入
【例】在位置 1 插入节点 node
- node1 代指图中值为 1 的节点,以此类推… …
- 默认头结点的下标为 0,那么插入前的位置 1 就是下面的 node2,node1 为待插入节点
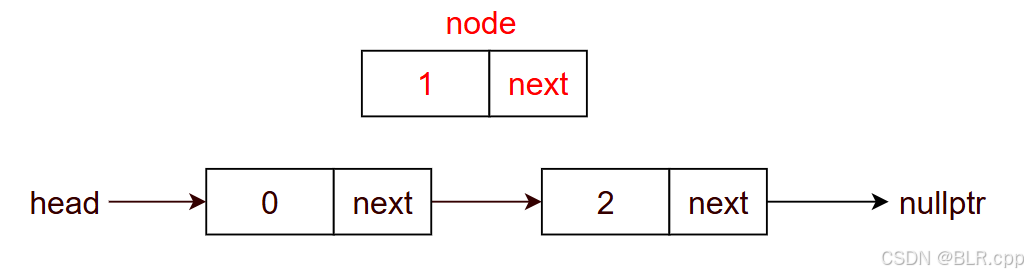
- node1->next = node2
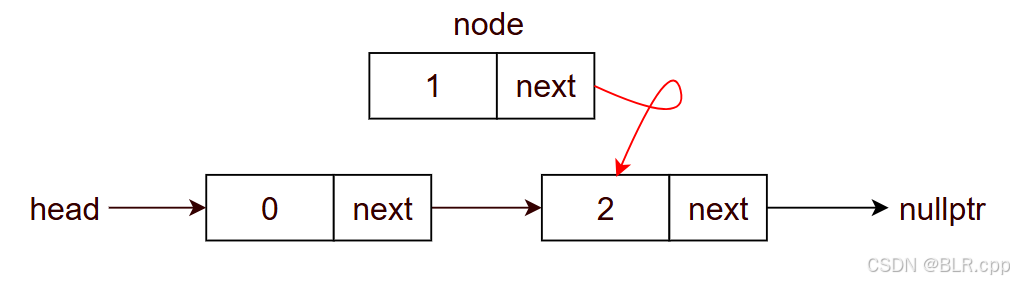
- node0->next = node1
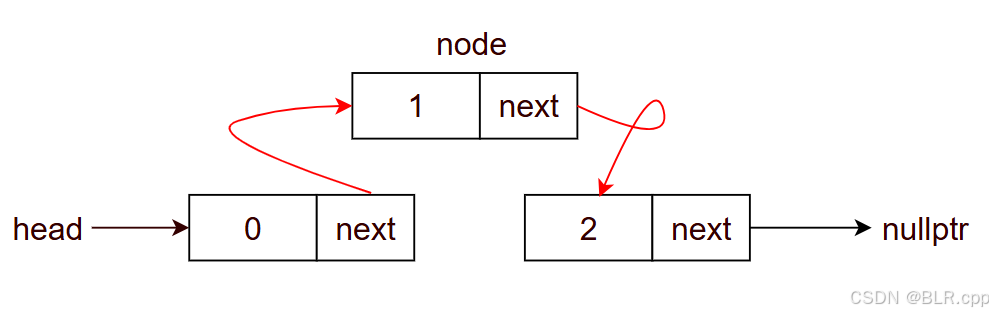
2.7 中间节点的删除
【例】删除位置 1 的节点
初始状态:
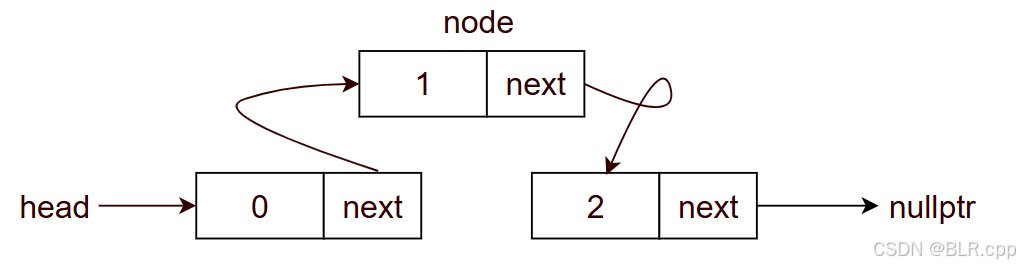
你可以直接 node0->next = node2,逻辑上没有问题,但是代码上存在 内存泄漏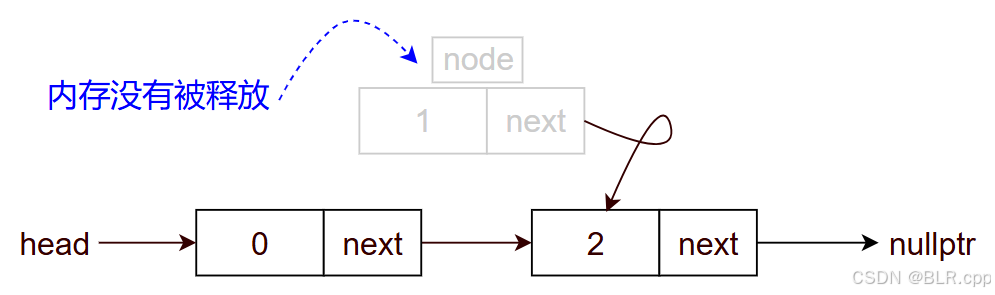
因此在执行 node0->next = node2 前,需要保存被删除的节点,在后续以释放内存。
3. 双向链表
3.1 什么是双链表
在单链表中,你会发现一个问题:单链表只能朝一个方向上(从头到尾)进行遍历,此外由于只存储了头指针,因此在尾结点的插入与删除的时间复杂度都是 O(n)。
为了解决这些问题,双链表就此诞生:
双链表在单链表的基础上增加了尾指针,节点增加了一个指针域(pre)用于指向当前节点的前驱节点。
- 尾指针:指向尾结点的指针
- 前驱节点:某节点的前一个节点

因此你会发现:
- 头节点的前驱节点为空
- 尾节点的后继节点为空
- 其余节点的前驱、后继节点都不为空
由于增加了尾指针,因此在尾结点的插入与删除时间复杂度变为 O(1),因为此时可以通过尾指针直接在尾结点进行操作。
同时由于加入了 pre 指针,因此可以对链表进行双向遍历。
你理解了单链表的操作,双链表的操作也很容易理解,下面讲解较难的中间节点的插入与删除
3.2 中间节点的插入
【例】在位置 1 插入节点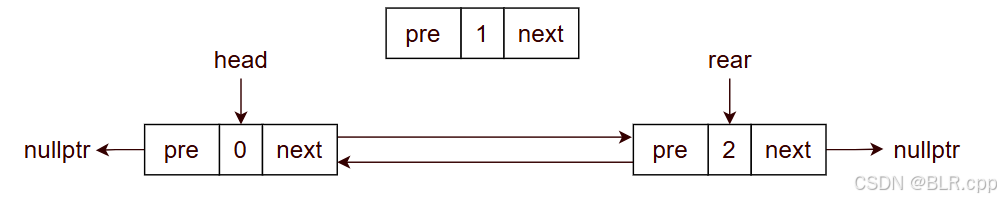
看起来比较复杂,其实只需要从目标反推即可。
我们的目标是: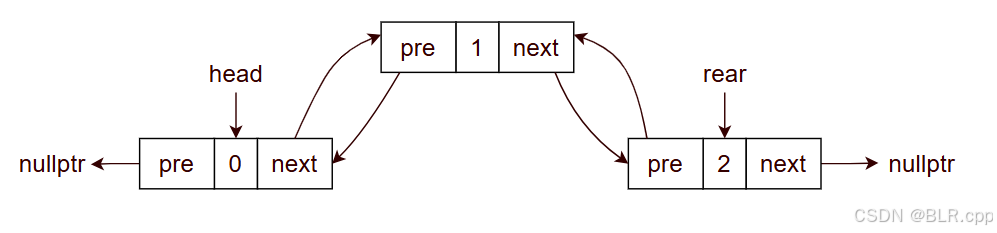
在之前的单链表中,你可以发现 对于节点的插入:
一般是 先给 待插入节点 的指针域进行赋值,否则可能会丢失某些节点。
比如如果我们先执行 node0->next = node1,会导致 node2 丢失
因此需要先对待插入节点的指针域进行赋值
当然针对上面的操作,你可以在执行 node0->next = node1 之前,将 node2 进行保存,就不会丢失 node2。
这也是可以的,但是比较浪费空间。
- node1->pre = node0
- node1->next = node2
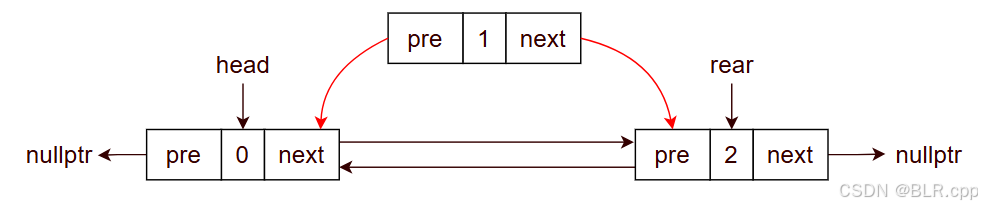
- node0->next = node1
- node2->pre = node1
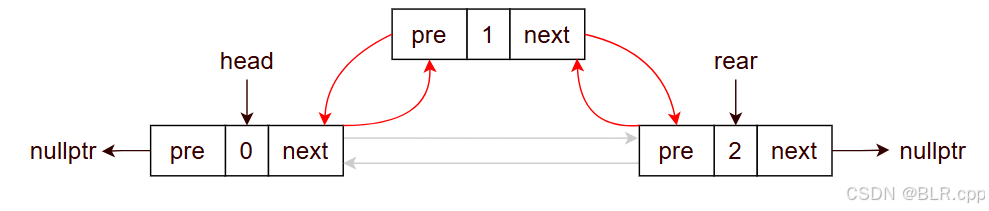
上面的代码有的可以交换位置,有的不可以,所以还是那句话:没必要死记硬背,自己画图分析即可。(在这里重点分析是否是丢失对某节点的指针)
3.3 中间节点的删除
【例】删除位置 1 上的节点
同理从目标反推:
因此我们需要
- node0->next = node2
- node2->pre = node0
两者可以交换顺序。但这只是就逻辑层面上可以,在代码层面上还需要考虑 内存泄漏,node1 需要被释放。
4. 循环链表
首尾相连 的链表。分为:
单循环链表
- rear->next = head

- rear->next = head
双循环链表
- head->pre = rear
- rear->next = head

5. 线性表 与 链表 的比较
| 优点 | 缺点 | 使用场景 | |
|---|---|---|---|
| 顺序表 | (1)程序设计简单;(2)能随机访问,时间复杂度为O(1);(3)存储空间利用率高 | (1)需事先知道表长;(2)插入元素需移动元素;(3)多次插入元素后可能会造成溢出 | (1)事先确定表长;(2)很少在非尾部位置进行插入和删除; |
| 链表 | (1)存储空间动态分配,不需事先确定表长;(2)插入与删除只引起指针的变化; | (1)程序设计较为复杂;(2)不能随机访问,读取的时间复杂度为O(n);(3)存在结构性开销; | (1)事先不确定表长;(2)需要经常进行插入与删除 |
【解释】
- 访问元素的时间复杂度
- 线性表:由于它的物理存储空间是连续的,所以元素的下标与实际的内存地址存在线性关系,可以直接计算得出,即可以随机访问,因此时间复杂度为 O(1)
- 链表:物理存储空间一般不连续,故不能随机访问,时间复杂度为 O(n)
- 不管是线性表还是链表,核心目的都是存储数据。
线性表:它的元素就是所需要存储的数据,所以存储空间利用率高;
链表:它的元素除了所需要存储的数据,还存在指针域以保存额外的信息,但是这部分信息在用户层面上是没必要的。
尽管底层设计需要维护指针,但是使用它的人只关心链表所存储的数据
故存在结构性开销,存储空间利用率较低。
最后
单链表实现代码见:SingleList
源码仅一个头文件,将其包含即可进行使用以及测试,如代码有 bug,敬请指正。
本文参考教科书以及网上资料,并加入自己的一些理解。
如有错误或者不足,欢迎指出。
