
阅读量:0
代码以及视频讲解
本文所涉及所有资源均在传知代码平台可获取
概述
情感识别是人类对话理解的关键任务。随着多模态数据的概念,如语言、声音和面部表情,任务变得更加具有挑战性。作为典型解决方案,利用全局和局部上下文信息来预测对话中每个单个句子(即话语)的情感标签。具体来说,全局表示可以通过对话级别的跨模态交互建模来捕获。局部表示通常是通过发言者的时间信息或情感转变来推断的,这忽略了话语级别的重要因素。此外,大多数现有方法在统一输入中使用多模态的融合特征,而不利用模态特定的表示。针对这些问题,我们提出了一种名为“关系时序图神经网络与辅助跨模态交互(CORECT)”的新型神经网络框架,它以模态特定的方式有效捕获了对话级别的跨模态交互和话语级别的时序依赖,用于对话理解。大量实验证明了CORECT的有效性,通过在IEMOCAP和CMUMOSEI数据集上取得了多模态ERC任务的最新成果。
模型整体架构
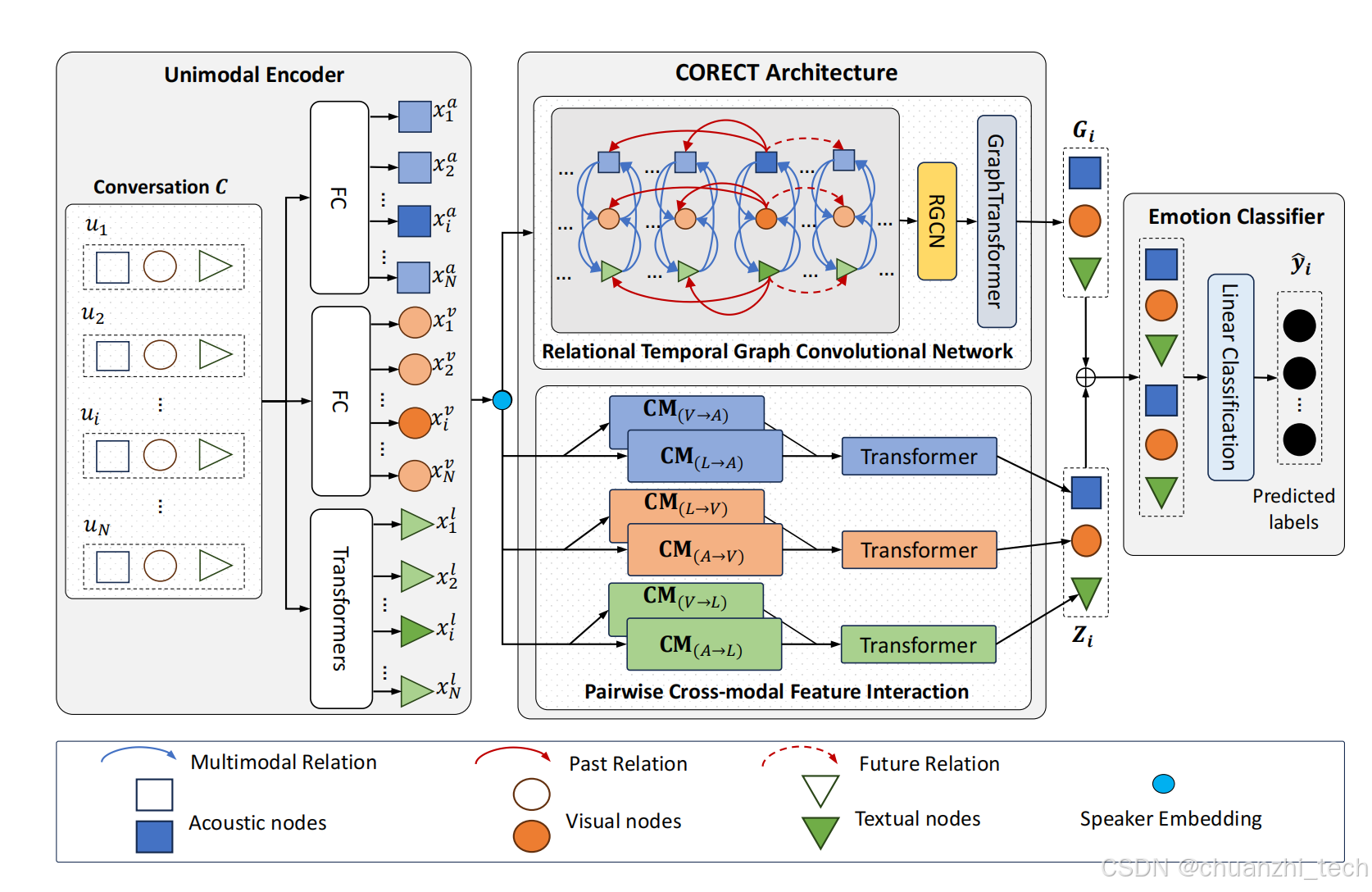
特征提取
文本采用transformerde方式进行编码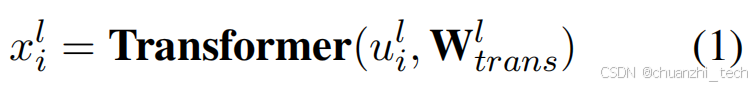
音频,视频都采用全连接的方式进行编码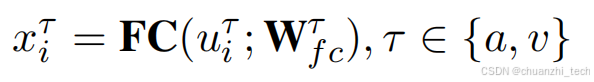
通过添加相应的讲话者嵌入来增强技术增强
关系时序图卷积网络(RT-GCN)
解读:RT-GCN旨在通过利用话语之间以及话语与其模态之间的多模态图来捕获对话中每个话语的局部上下文信息,关系时序图在一个模块中同时实现了上下文信息,与模态之间的信息的传递。对话中情感识别需要跨模态学习到信息,同时也需要学习上下文的信息,整合成一个模块的作用将两部分并行处理,降低模型的复杂程度,降低训练成本,降低训练难度。
建图方式,模态与模态之间有边相连,对话之间有边相连:

建图之后,用图transformer融合不同模态,以及不同语句的信息,得到处理之后特征向量: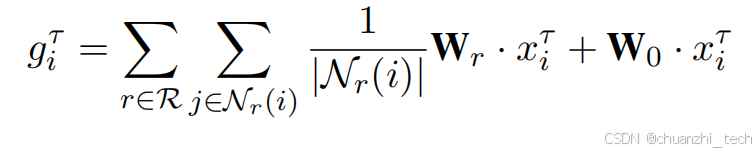
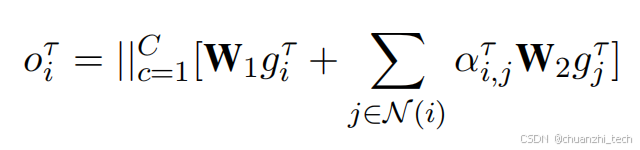
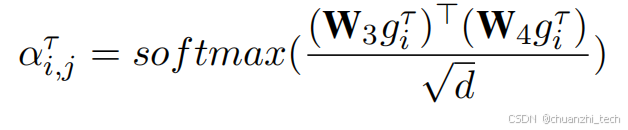
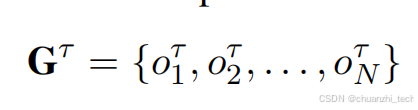
两两交叉模态特征交互
跨模态的异质性经常提高了分析人类语言的难度。利用跨模态交互可能有助于揭示跨模态之间的“不对齐”特性和长期依赖关系。受到这一思想的启发(Tsai等人,2019),我们将配对的跨模态特征交互(P-CM)方法设计到我们提出的用于对话理解的框架中。
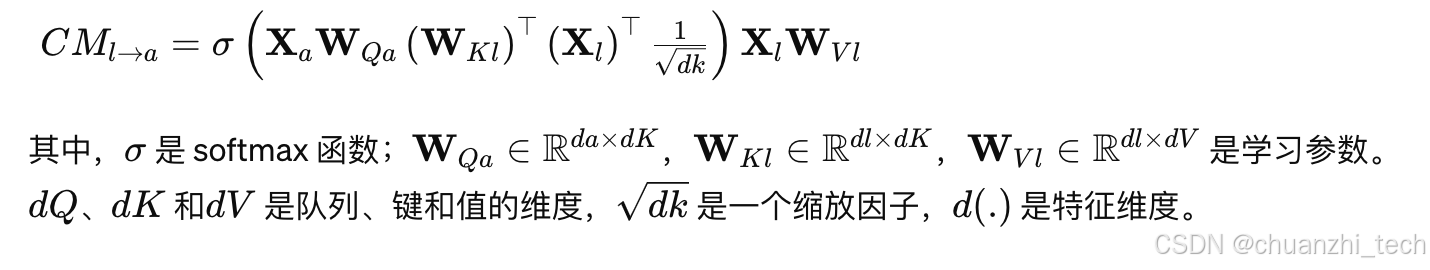
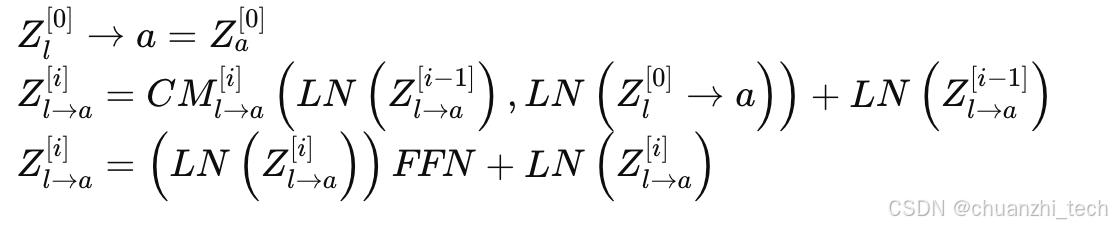

线性分类器
最后就是根据提取出来的特征进行情感分类了:

代码修改
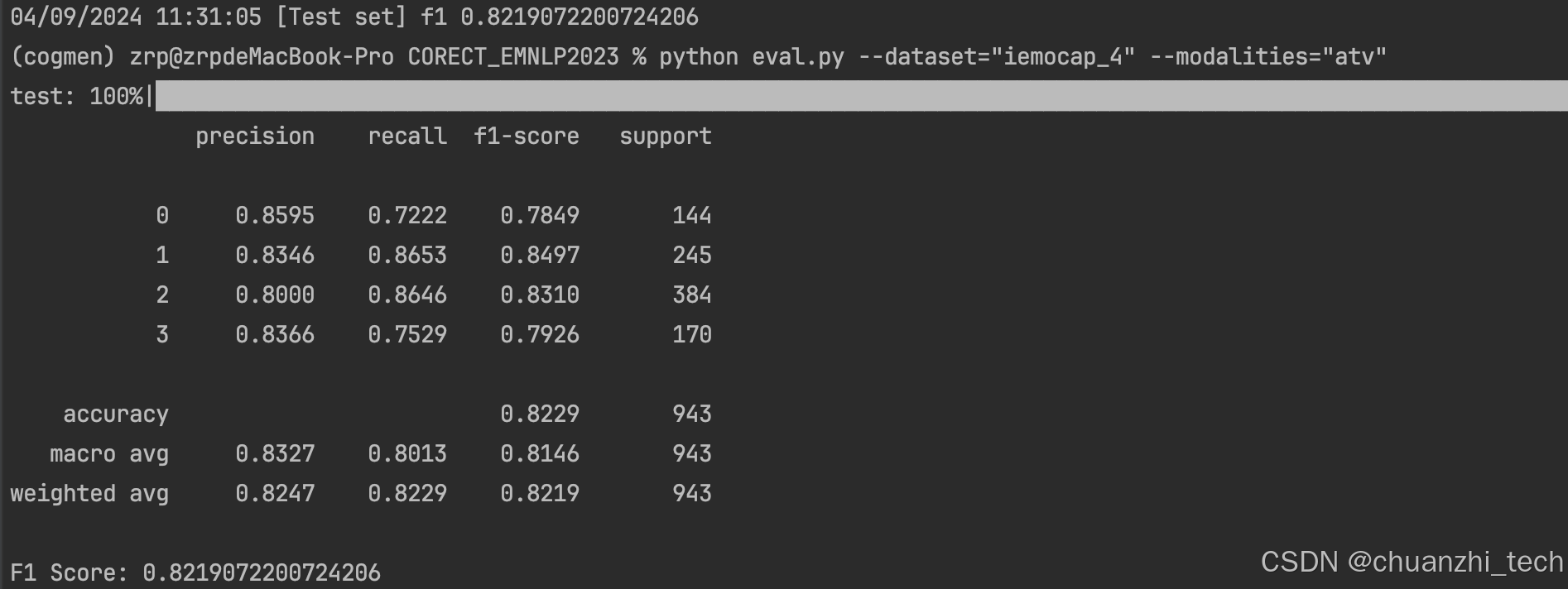
这是对话中多模态情感识别(视觉,音频,文本)在数据集IEMOCAP目前为止的SOTA。在离线系统已经取得了相当不错的表现。(离线系统的意思是,是一段已经录制好的视频,而不是事实录制如线上开会)
但是却存在一个问题,输入的数据是已经给定的一个视频,分析某一句话的情感状态的时候,论文的方法使用了过去的信息,也使用了未来的信息,这样会在工业界实时应用场景存在一定的问题。
比如在开线上会议,需要检测开会双方的情绪,不可能用未来将要说的话预测现在的情绪。因为未来的话都还没被说话者说出来,此时,就不能参考到未来的语句来预测现在语句的情感信息。但是原文的方法在数据结构图的构建的时候,连接上了未来语句和现在语句的边,用图神经网络学习了之间的关联。
因此,修改建图方式,不考虑未来的情感信息,重新训练网络,得到了还可以接受的效果,精度大概在82%左右,原文的精度在84%左右,2%精度的牺牲解决了是否能实时的问题其实是值得的。
演示效果

核心逻辑
在这里可以粘贴您的核心代码逻辑:
# start #模型核心部分 import torch import torch.nn as nn import torch.nn.functional as F from .Classifier import Classifier from .UnimodalEncoder import UnimodalEncoder from .CrossmodalNet import CrossmodalNet from .GraphModel import GraphModel from .functions import multi_concat, feature_packing import corect log = corect.utils.get_logger() class CORECT(nn.Module): def __init__(self, args): super(CORECT, self).__init__() self.args = args self.wp = args.wp self.wf = args.wf self.modalities = args.modalities self.n_modals = len(self.modalities) self.use_speaker = args.use_speaker g_dim = args.hidden_size h_dim = args.hidden_size ic_dim = 0 if not args.no_gnn: ic_dim = h_dim * self.n_modals if not args.use_graph_transformer and (args.gcn_conv == "gat_gcn" or args.gcn_conv == "gcn_gat"): ic_dim = ic_dim * 2 if args.use_graph_transformer: ic_dim *= args.graph_transformer_nheads if args.use_crossmodal and self.n_modals > 1: ic_dim += h_dim * self.n_modals * (self.n_modals - 1) if self.args.no_gnn and (not self.args.use_crossmodal or self.n_modals == 1): ic_dim = h_dim * self.n_modals a_dim = args.dataset_embedding_dims[args.dataset]['a'] t_dim = args.dataset_embedding_dims[args.dataset]['t'] v_dim = args.dataset_embedding_dims[args.dataset]['v'] dataset_label_dict = { "iemocap": {"hap": 0, "sad": 1, "neu": 2, "ang": 3, "exc": 4, "fru": 5}, "iemocap_4": {"hap": 0, "sad": 1, "neu": 2, "ang": 3}, "mosei": {"Negative": 0, "Positive": 1}, } dataset_speaker_dict = { "iemocap": 2, "iemocap_4": 2, "mosei":1, } tag_size = len(dataset_label_dict[args.dataset]) self.n_speakers = dataset_speaker_dict[args.dataset] self.wp = args.wp self.wf = args.wf self.device = args.device self.encoder = UnimodalEncoder(a_dim, t_dim, v_dim, g_dim, args) self.speaker_embedding = nn.Embedding(self.n_speakers, g_dim) print(f"{args.dataset} speakers: {self.n_speakers}") if not args.no_gnn: self.graph_model = GraphModel(g_dim, h_dim, h_dim, self.device, args) print('CORECT --> Use GNN') if args.use_crossmodal and self.n_modals > 1: self.crossmodal = CrossmodalNet(g_dim, args) print('CORECT --> Use Crossmodal') elif self.n_modals == 1: print('CORECT --> Crossmodal not available when number of modalitiy is 1') self.clf = Classifier(ic_dim, h_dim, tag_size, args) self.rlog = {} def represent(self, data): # Encoding multimodal feature a = data['audio_tensor'] if 'a' in self.modalities else None t = data['text_tensor'] if 't' in self.modalities else None v = data['visual_tensor'] if 'v' in self.modalities else None a, t, v = self.encoder(a, t, v, data['text_len_tensor']) # Speaker embedding if self.use_speaker: emb = self.speaker_embedding(data['speaker_tensor']) a = a + emb if a != None else None t = t + emb if t != None else None v = v + emb if v != None else None # Graph construct multimodal_features = [] if a != None: multimodal_features.append(a) if t != None: multimodal_features.append(t) if v != None: multimodal_features.append(v) out_encode = feature_packing(multimodal_features, data['text_len_tensor']) out_encode = multi_concat(out_encode, data['text_len_tensor'], self.n_modals) out = [] if not self.args.no_gnn: out_graph = self.graph_model(multimodal_features, data['text_len_tensor']) out.append(out_graph) if self.args.use_crossmodal and self.n_modals > 1: out_cr = self.crossmodal(multimodal_features) out_cr = out_cr.permute(1, 0, 2) lengths = data['text_len_tensor'] batch_size = lengths.size(0) cr_feat = [] for j in range(batch_size): cur_len = lengths[j].item() cr_feat.append(out_cr[j,:cur_len]) cr_feat = torch.cat(cr_feat, dim=0).to(self.device) out.append(cr_feat) if self.args.no_gnn and (not self.args.use_crossmodal or self.n_modals == 1): out = out_encode else: out = torch.cat(out, dim=-1) return out def forward(self, data): graph_out = self.represent(data) out = self.clf(graph_out, data["text_len_tensor"]) return out def get_loss(self, data): graph_out = self.represent(data) loss = self.clf.get_loss( graph_out, data["label_tensor"], data["text_len_tensor"]) return loss def get_log(self): return self.rlog #图神经网络 import torch import torch.nn as nn from torch_geometric.nn import RGCNConv, TransformerConv import corect class GNN(nn.Module): def __init__(self, g_dim, h1_dim, h2_dim, num_relations, num_modals, args): super(GNN, self).__init__() self.args = args self.num_modals = num_modals if args.gcn_conv == "rgcn": print("GNN --> Use RGCN") self.conv1 = RGCNConv(g_dim, h1_dim, num_relations) if args.use_graph_transformer: print("GNN --> Use Graph Transformer") in_dim = h1_dim self.conv2 = TransformerConv(in_dim, h2_dim, heads=args.graph_transformer_nheads, concat=True) self.bn = nn.BatchNorm1d(h2_dim * args.graph_transformer_nheads) def forward(self, node_features, node_type, edge_index, edge_type): if self.args.gcn_conv == "rgcn": x = self.conv1(node_features, edge_index, edge_type) if self.args.use_graph_transformer: x = nn.functional.leaky_relu(self.bn(self.conv2(x, edge_index))) return x 使用方式&部署方式
首先建议安装conda,因为想要复现深度学习的代码,github上不同项目的环境差别太大,同时处理多个项目的时候很麻烦,在这里就不做conda安装的教程了,请自行学习。
安装pytorch:
请到pytorch官网找安装命令,尽量不要直接pip install
https://pytorch.org/get-started/previous-versions/
给大家直接对着我安装版本来下载,因为图神经网络的包版本要求很苛刻,版本对应不上很容易报错: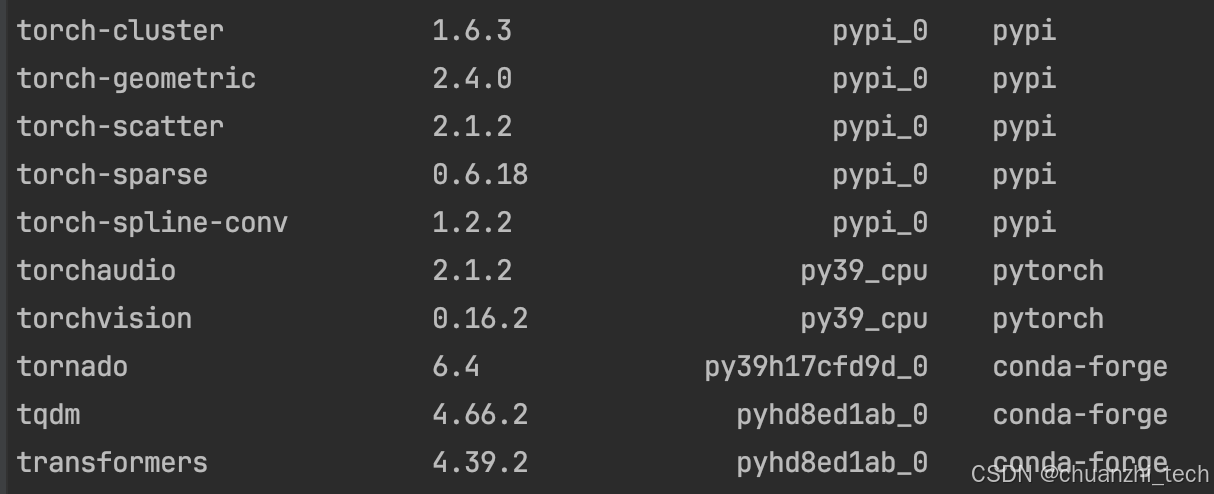

只要环境配置好了,找到这个文件,里面的代码粘贴到终端运行即可
温馨提示
1.数据集和已训练好的模型都在.md文件中有百度网盘链接,直接下载放到指定文件夹即可
2.注意,训练出来的模型是有硬件要求的,我是用cpu进行训练的,模型只能在cpu跑,如果想在gpu上跑,请进行重新训练
3.如果有朋友希望用苹果的gpu进行训练,虽然现在pytorch框架已经支持mps(mac版本的cuda可以这么理解)训练,但是很遗憾,图神经网络的包还不支持,不过不用担心,这个模型的训练量很小,我全程都是苹果笔记本完成训练的。
