
阅读量:1
写在前面:本文为个人八股复习所用,整合了其他平台的答案加自己的理解,希望能对大家的八股复习有所帮助,答案可能存在出入,请大家理性食用~~
1. 数据库事务特性(ACID)
原子性(Atomicity):原子性指的是事务是一个不可分割的工作单位,事务中的所有操作要么全部完成,要么全部不完成,不存在部分完成的情况。如果事务中的任何一步操作失败,整个事务都会被回滚(Rollback)到事务开始前的状态,以保证数据的一致性和完整性。
一致性(Consistency):一致性确保了当事务完成时,数据从一个一致性状态转换到另一个一致性状态。事务在执行前后,数据库的完整性约束没有被破坏,如主键、外键、触发器等约束条件依然有效。这保证了数据库的结构和数据在事务开始和结束时都是有效的。
隔离性(Isolation):隔离性指的是并发执行的事务之间是相互隔离的,一个事务的执行不应该受到其他事务的干扰。即使多个事务并发执行,各个事务之间也不会互相影响,每个事务看到的数据应该是一致的。数据库通过锁定机制来实现事务的隔离性,确保并发执行的事务不会相互干扰。
持久性(Durability):持久性指的是一旦事务提交,所做的修改将永久保存在数据库中,即使系统发生故障,如数据库崩溃、服务器宕机,也不应该丢失提交的数据。
2. 什么是索引?索引的底层数据结构
- 索引是帮助MySQL高效获取数据的数据结构(有序)
- 索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
3. MySQL中的索引,根据创建索引的列的不同,可以分为:
- 主键索引:在数据表的主键字段创建的索引,这个字段必须被primary key修饰,每张表只
能有一个主键
- 唯一索引:在数据表中的唯一列创建的索引(unique),此列的所有值只能出现一次,可以为
NULL
- 普通索引:在普通字段上创建的索引,没有唯一性的限制
- 组合索引:两个及以上字段联合起来创建的索引
创建索引的sql语句:
-- 创建唯一索引: 创建唯一索引的列的值不能重复 -- create unique index <index_name> on 表名(列名); create unique index index_test1 on tb_testindex(tid);查看索引:
-- 查询数据表的索引 show indexes from tb_testindex; -- 查询索引 show keys from tb_testindex;4. 什么是B树和B+树,为什么 MySQL 的索引使用B+树而不是B树?
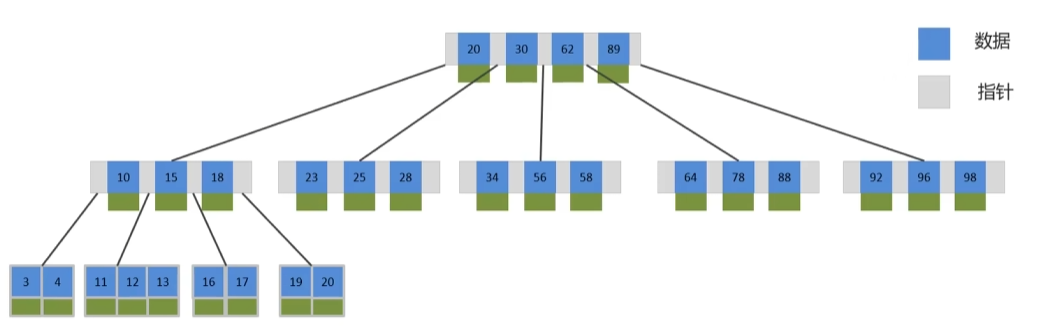
B-tree:因为B树不管叶子节点还是非叶子节点,都会保存数据,在单个节点存储容量有限的情况下,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
B+树:B+树和B树的区别在于非叶子节点不再存储数据,数据只存储在同一层的叶子节点上,且叶节点之间增加了链表,便于查询。
Hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
5. B树和B+树的区别
- B树叶子节点和非叶子节点都存储数据,B+树非叶子节点不存储数据,数据只存储在同一层的叶子节点上。
- B树的查询效率比B+树低,因为B树的内部节点存储了部分数据,在单个节点存储容量有限的情况下,会导致内部节点的大小较大,使树的高度增加,从而提高了查询效率;B+树的内部节点只存储键值对的索引信息,大小较小,在单个节点存储容量有限的情况下可以容纳更多的索引信息,从而减少了树的高度,提高了查询效率。
- B+树的叶子节点使用双向链表进行连接,可以通过遍历叶子节点来实现范围查询,而B树需要在内部节点和叶子节点之间进行额外的搜索,效率较低。同时B+树支持范围查询,因此不需要回溯内部节点。
6. MySQL事务管理
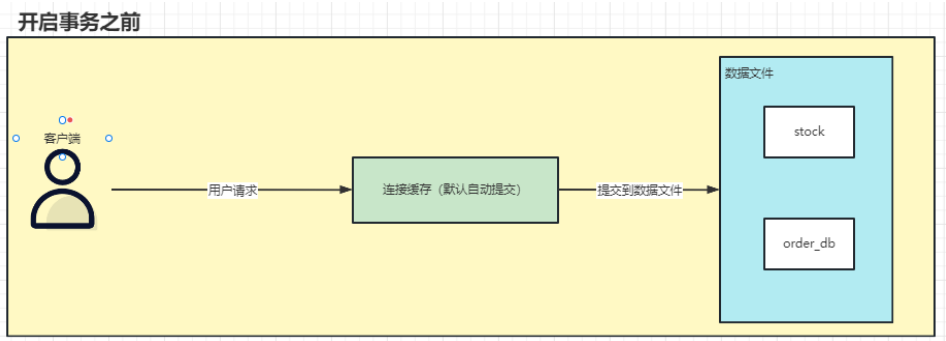
自动提交
- 在MySQL中,默认DML指令的执行时自动提交的,当我们执行一个DML指令之后,自动同
步到数据库中。
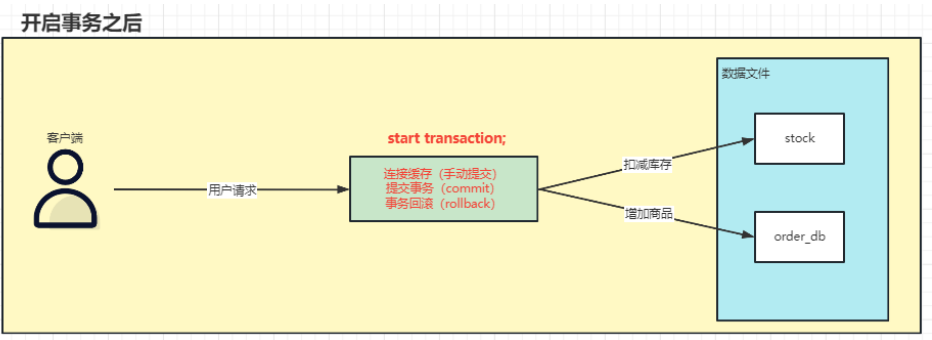
事务管理
开启事务,就是关闭自动提交
- 在开始事务第一个操作之前,执行
start transaction开启事务 - 依次执行事务中的每个DML操作
- 如果在执行的过程中的任何位置出现异常,则执行
rollback回滚事务 - 如果事务中所有的DML操作都执行成功,则在最后执行
commit提交事务
事务管理示例sql:
create database db_test3; use db_test3; # 库存表 create table stock( id int primary key auto_increment, name varchar(200), num int not null ) # 订单表 create table order_db( id int primary key auto_increment, name varchar(200) not null, price double, num int ); insert into stock(name,num) values('鼠标',10); insert into stock(name,num) values('键盘',20); insert into stock(name,num) values('耳机',30); # 开启事务 start transaction; # 操作1:扣减库存 update stock set num = num-1 where name = '鼠标'; select aaa; # 此处会执行失败 # 操作2:新增订单 insert into order_db(name,price,num) values('鼠标',20.5,1); # 事务回滚:清除缓存中的操作,撤销当前事务已经执行的操作 rollback; # 提交事务: 将缓存中的操作写入数据文件 commit;7. 事务隔离级别
MySQL数据库事务隔离级别:
- 读未提交
- 读已提交
- 可重复读
- 串行化
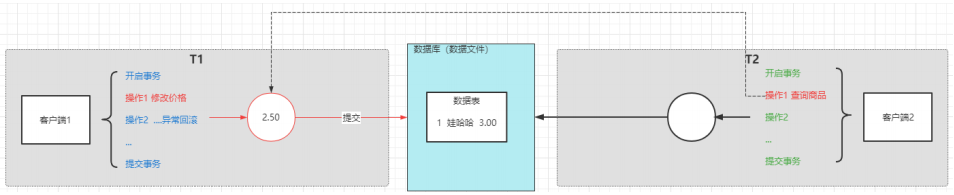
读未提交(read uncommitted)
T2可以读取T1执行但未提交的数据;可能会导致出现脏读、不可重复读和幻读
脏读,一个事务读取到了另一个事务中未提交的数据
读已提交(read committed)
T2只能读取T1已经提交的数据;避免了脏读,但可能会导致不可重复度、幻读
不可重复度(虚读): 在同一个事务中,两次查询操作读取到数据不一致
例如:T2进行第一次查询之后在第二次查询之前,T1修改并提交了数据,T2进行第二次查询时读取到的数据和第一次查询读取到数据不一致。

可重复读(repeatable read)
T2执行第一次查询之后,在事务结束之前其他事务不能修改对应的数据,但可以操作其他数据;避免了不可重复读,但可能会导致幻读
幻读,T2对数据表中的数据进行修改然后查询,在查询之前T1向数据表中新增了一条数
据,就导致T2以为修改了所有数据,但却查询出了与修改不一致的数据(T1事务新增的数
据)

串行化(serializable)
同时只允许一个事务对数据表进行操作;避免了脏读、虚读、幻读问题
MySQL数据库默认的隔离级别为可重复读
