
阅读量:2
超大文件下载,支持断点续传
前言
好记性不如烂笔头,站在岸上学不会游泳。这次分享一是为了记录下忙碌几天的成果,方便以后查阅;二是避免别人走弯路,给别人方便就是给自己方便。
一、背景
客户下载超大文件(1G以上)时,下载异常断开,分析了下有以下原因:
- nginx配置允许下载大小超限
- 网络带宽限制,导致龟速下载;
- 下载长时间连接可能会导致超时
针对上述问题,找到一个合理的解决方案 分片下载,既可不超限亦不需要保持长连接,如果出现网络波动断开连接,亦可断点续传。多的不说,直接上干货。
二、代码实现
1.后端
创建下载工具类DownloadUtil.java
import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.*; import java.net.URLEncoder; public class DownloadUtil { /** * 每个分片大小 50M */ private final static int BUFFER_SIZE = 1024 * 1024 * 50; public static void downloadByBlock(File file, HttpServletRequest request, HttpServletResponse response) throws IOException { // 获取文件名 String fileName = file.getName(); // 获取文件大小 long fileSize = file.length(); // 设置返回头 response.setContentType("application/octect-stream;charset=UTF-8"); response.setHeader("Content-Disposition", "attachment; filename=" + URLEncoder.encode(fileName, "UTF-8")); response.setHeader("Accept-Ranges", "bytes"); // 判断是否包含Range String rangeHeader = request.getHeader("Range"); if (rangeHeader == null) { // 返回文件大小信息 response.setHeader("Content-Length", String.valueOf(fileSize)); response.setHeader("Buffer-Size", String.valueOf(BUFFER_SIZE)); response.setHeader("Access-Control-Expose-Headers", "Buffer-Size"); } else { // 分片下载 long start = 0; long end = fileSize - 1; String[] range = rangeHeader.split("=")[1].split("-"); if (range.length == 1) { start = Long.parseLong(range[0]); end = fileSize - 1; } else { start = Long.parseLong(range[0]); end = Long.parseLong(range[1]); } long contentLength = end - start + 1; // 返回头里存放每次读取的开始和结束字节 response.setHeader("Content-Length", String.valueOf(contentLength)); response.setHeader("Content-Range", "bytes " + start + "-" + end + "/" + fileSize); InputStream in = new FileInputStream(file); OutputStream out = response.getOutputStream(); // 跳到第start字节 in.skip(start); byte[] buffer = new byte[BUFFER_SIZE]; int bytesRead = -1; long bytesWritten = 0; while ((bytesRead = in.read(buffer)) != -1) { if (bytesWritten + bytesRead > contentLength) { out.write(buffer, 0, (int) (contentLength - bytesWritten)); break; } else { out.write(buffer, 0, bytesRead); bytesWritten += bytesRead; } } in.close(); out.close(); } } } 后端代码借鉴其他博友 来源
2.前端
前端使用vue脚手架项目作为实例,也可用其他方式实现;
当前实例需要用到的技术:
localforage:localForage 是一个 JavaScript 库,通过简单类似 localStorage API 的异步存储来改进你的 Web 应用程序的离线体验,最最重要的一点是通过它可以将数据持久化至本地磁盘
streamsaver:用于实现在Web浏览器中直接将大文件流式传输到用户设备的功能
创建工具类 download.js
import axios from 'axios'; import localForage from 'localforage' import streamSaver from 'streamsaver' import store from "@/store/index" // 基础数据库 存放其他文件的数据库实例名 const baseDataBaseName = "localforageInstance"; // 数据库进度数据主键 const progressKey = "progress"; /** * @description 分片下载 * @param fileName 文件名 * @param url 下载地址 * @param dataBaseName 数据库名,用于存放分片数据 每个文件唯一 * @param progress 下载进度 type:continue 续传 again重新下载 cancel取消 */ export async function downloadByBlock(fileName, url, dataBaseName, progress) { if(progress.type){ await controlFile(fileName, progress.type, dataBaseName) } // 创建基础数据库 用于保存文件信息 const baseDataBase = createInstance(baseDataBaseName); // 判断数据库中是否已存在该文件的下载任务 let isError = false; await getData(dataBaseName, baseDataBase, async(res) => { if(res && !progress.type){ alert("已存在下载进度!"); isError = true; } }) if(isError){ return; } // 创建数据库 用于存储每个文件的分片数据 const dataBase = createInstance(dataBaseName); // 获取文件大小 const response = await axios.head(url); // 文件大小 注意转为数字 const fileSize = +response.headers['content-length']; // 分片大小 注意转为数字 const chunkSize = +response.headers['buffer-size']; // 开始节点 let start = 0; // 结束节点 let end = chunkSize -1; if(fileSize < chunkSize){ end = fileSize - 1; } // 所有分片信息 let ranges = []; // 计算需要多少分片 const numChunks = Math.ceil(fileSize / chunkSize); // 回写文件大小 progress.fileSize = fileSize; progress.url = url; // 保存数据库实例 文件信息 await saveData(dataBaseName, fileName, baseDataBase); if(!progress.progress){ // 保存整个文件的进度数据(包括文件名 下载地址 文件大小 方便刷新页面后继续断点续传) await saveData(progressKey, progress, dataBase); } // 组装参数 用于准备分片下载文件数据 for(let i = 0; i < numChunks; i++){ // 创建请求控制器 用于控制往后端的请求 const controller = new AbortController(); const range = `bytes=${start}-${end}`; // 如果是续传 先判断是否已下载 if(progress.type == 'continue'){ // 先修改状态 store.commit('setProgress',{ dataInstance: dataBaseName, status: 'downloading' }) let isContinue = false; await getData(range, dataBase, async function(res){if(res) isContinue = true}); if(isContinue){ ranges.push(range); // 重置开始节点 start = end + 1; // 重置结束节点 end = Math.min(end + chunkSize, fileSize -1); continue; } } const config = { headers: { Range: range }, responseType: 'arraybuffer', // 绑定取消请求的信号量 signal: controller.signal, // 文件下载进度监听 onDownloadProgress: function(pro){ if(progress.type == 'stop' || progress.type == 'cancel'){ // 终止请求 controller.abort(); } // 获取当前分片的下载进度 loaded表示已下载的数量 total表示总数量 let downProgress = (pro.loaded / pro.total); // 计算整个文件的下载进度 downProgress = Math.round((i / numChunks) * 100 + downProgress / numChunks * 100); store.commit('setProgress',{ dataInstance: dataBaseName, fileName: fileName, progress: downProgress, status: downProgress == 100 ? 'success' : 'downloading' }) } }; try{ // 开始分片下载 const response = await axios.get(url, config); // 【重点1】 以分片名为key保存分片数据至本地磁盘 如果用localstorage 保存至浏览器内存,数据太多会导致浏览器奔溃 await saveData(range, response.data, dataBase); // 将分片名保存 方便后面通过key取出分片数据 ranges.push(range); // 重置开始节点 start = end + 1; // 重置结束节点 end = Math.min(end + chunkSize, fileSize -1); } catch (error) { // 如果中途终止请求,会有异常信息 所以在此处理 if(error.message == "canceled"){ await controlFile(fileName, progress.type, dataBaseName); return; } } } // 下载完成后 开始合并分片数据 // 流操作 // 如果项目在内网,连接不了外部网络或者没法连接github,需要把streamSaver模块中的mitm.html和sw.js手动拷贝至项目public目录下,然后重新配置mitm地址即可 // streamSaver.mitm="http://localhost:8081/mitm.html?version=2.0.0" const fileStream = streamSaver.createWriteStream(fileName, {size: fileSize}); const writer = fileStream.getWriter(); // 循环分片名 for(let i = 0;i < ranges.length; i++){ let range = ranges[i]; // 从数据库获取分片数据 await getData(range, dataBase, async function(res){ if(res){ // 【重点2】读取流 不能将流数据直接存到浏览器内存中 然后合并,这样同样会使浏览器崩溃 // let 分片数据1 = []; // let 分片数据2 = []; // let 分片数据 。。。 // 合并 let array = 分片数据1 + 分片数据2 + ... // 这种不可取 // 读出来就直接生成文件往磁盘写 不在内存中停留 const reader = new Blob([res]).stream().getReader(); while(true){ const { done, value } = await reader.read(); if(done) break; // 写入 writer.write(value); } // 判断如果是最后一个分片 if(i == ranges.length-1){ // 结束写入 关闭 writer.close(); // 清空分片数据 dropDataBase(dataBaseName); // 基础数据库删除文件数据实例 代表当前文件已下载完成 下载进度表删除当前文件 removeData(dataBaseName, baseDataBase); // 清除store store.commit('delProgress',{ dataInstance: dataBaseName }) } } }) } } /** * @description 状态控制 * @param fileName 文件名 * @param dataBaseName 数据库名,用于存放分片数据 每个文件唯一 * @param type下载方式 continue 续传 again重新下载 cancel取消 */ async function controlFile(filename, type, dataBaseName){ if(type == 'continue'){ }else if(type == 'again'){ // 删除分片数据 await dropDataBase(dataBaseName); // 基础数据库 const baseDataBase = createInstance(baseDataBaseName); // 删除文件实例 removeData(dataBaseName, baseDataBase); }else if(type == 'cancel'){ // 删除分片数据 await dropDataBase(dataBaseName); // 基础数据库 const baseDataBase = createInstance(baseDataBaseName); // 删除文件实例 await removeData(dataBaseName, baseDataBase); // 移除store store.commit('delProgress',{ dataInstance: dataBaseName }) }else if(type == 'stop'){ store.commit('setProgress',{ dataInstance: dataBaseName, status: 'stopped' }) } } localforage 相关方法
/** * @description 创建数据库实例 每个实例对象都有独立的数据库 不会影响其他实例 * @param dataBasse 数据库名 */ function createInstance(dataBase){ return localForage.createInstance({ name: dataBase }); } /** * @description 保存数据 * @param name 键名 * @param value 数据 * @param storeName 仓库/数据库实例 */ async function saveData(name, value, storeName){ await storeName.setItem(name,value).then(()=>{ // success }).catch(err=>{ // err }) } /** * @description 获取数据 * @param name 键名 * @param storeName 仓库/数据库实例 * @param callback 回调函数 */ async function getData(name, storeName, callback){ await storeName.getItem(name).then((val)=>{ // success callback(val); }).catch(err=>{ // err callback(false); }) } /** * @description 移除数据 * @param name 键名 * @param storeName 仓库/数据库实例 */ async function removeData(name, storeName){ await storeName.removeItem(name).then(()=>{ // success }).catch(err=>{ // err }) } /** * @description 删除数据库实例 * @param dataBasse 数据库名 */ async function dropDataBase(dataBase){ await localForage.dropInstance({ name: dataBase }).then(()=>{ // success }).catch(err=>{ // err }) } 3.效果展示
localforage数据展示
F12打开管理器,application -> indexedDB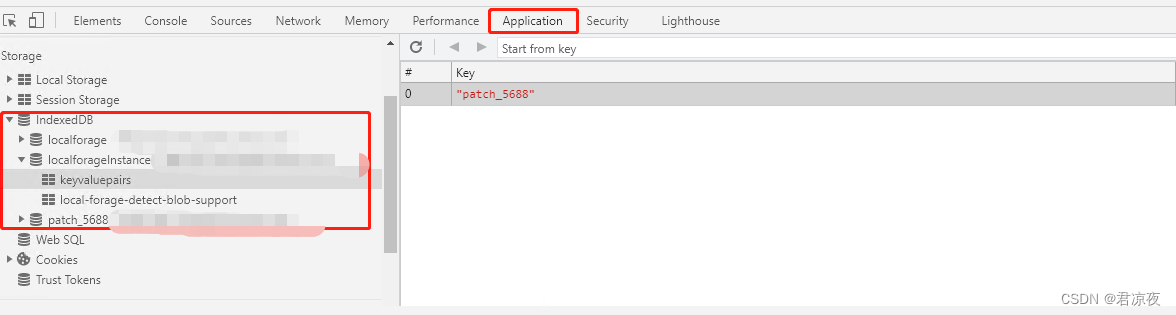
下载进度展示
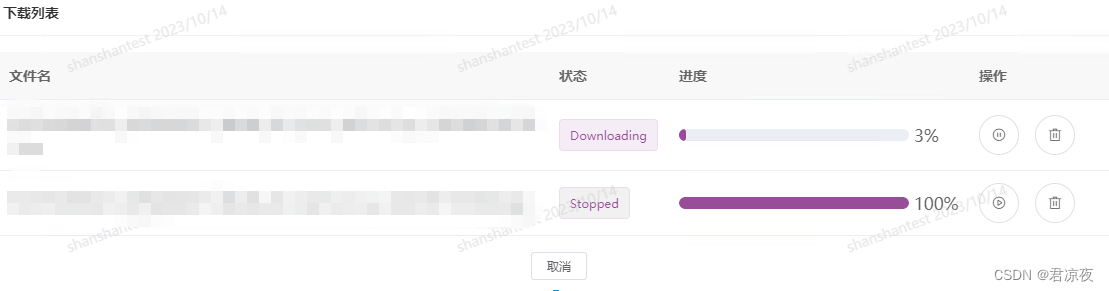
三、总结
以上就是所有核心代码,当前功能涉及到下载、暂停、续传、取消,也可动态展示下载进度,因为是纯手工敲的,所以可能会有个别错误,见谅。其他细枝末节的代码就不在这陈述,再就是功能代码之前赶得比较急,也没怎么仔细整理,有些地方可能有更优的解法,欢迎大家评论区讨论
