
阅读量:1
一、JVM的内存区域划分
一个进程在运行的时候,会向操作系统申请到内存资源,从来存放程序运行的相关数据。
JVM本质上就是一个java进程,在运行的时候也会从操作系统那搞一块内存,供Java代码执行使用。
JVM又把申请的一块内存根据不同的用途划分出了不同区域。
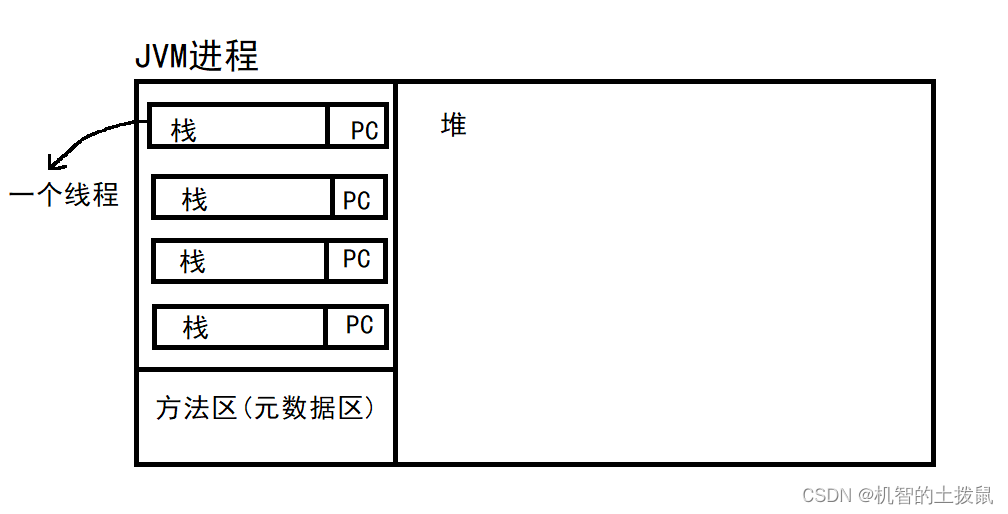
每一个线程中都独有一份自己的栈空间和程序计数器(PC)
栈:存放方法调用关系,局部变量。
程序计数器(PC):记录当前线程执行的下一条指令的内存地址。
堆:存放对象的实例,即new出来的对象都在这里。
方法区(元数据区):存放类对象,常量池,静态成员。
二、JVM类加载机制
类加载本质上就是将.class文件(硬盘)加载到内存(方法区)中。
Java程序最开始在编写的时候是一个.java文件,然后通过编译生成.class(字节码)文件,运行java程序,JVM就会读取.class文件,把文件的内容放到内存中,构造.class对象。
类加载的过程
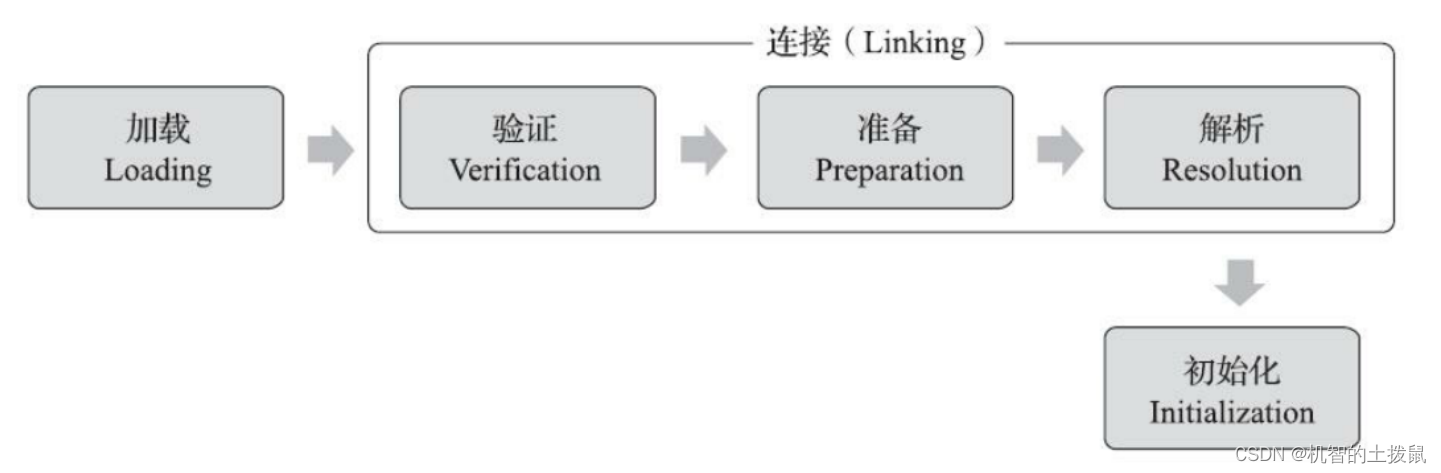
加载:找到.class文件,打开文件,读取文件内容。
验证:检查当前.class文件的格式。
准备:给类对象分配内存空间。给类对象分配空间并进行默认初始化(一般置为0)。
解析:主要针对字符串常量,将常量池中的符号引用替换为直接引用。
符号引用:相对的位置
直接引用:真是的内存地址
在.class文件中,由于还未加载到内存中,无法确定内存地址,只能使用一个相对偏移量来表示内存地址。当JVM将.class文件进行加载分配了内存地址,此时字符串常量就有了真实地址,然后将一些引用变量中的"符号引用"替换成直接引用。
初始化:对类对象进行初始化。初始化静态成员,执行静态代码块,加载父类.....
双亲委派模型
双亲委派模型描述的是类加载的过程中,如何找.class文件。
JVM在加载.class文件的时候,需要用到类加载器,在JVM中就自带了三个类加载器。
这三个类加载器存在"父子关系",这里的父子关系并不是通过继承形成的,而是对象中有一个引用指向"父类"加载器实例
Bootstarp ClassLoader 负责加载标准库中的类(Java标准文档中规定了需要提供哪些基本类)
Extension ClassLoader 负责加载JVM扩展库中的类(JVM厂商可能还会添加一些类)
Application ClassLoader 负责加载第三方库的类(mysql、jackson.......以及一些自己写的类)
双亲委派模型就描述了类加载的流程:
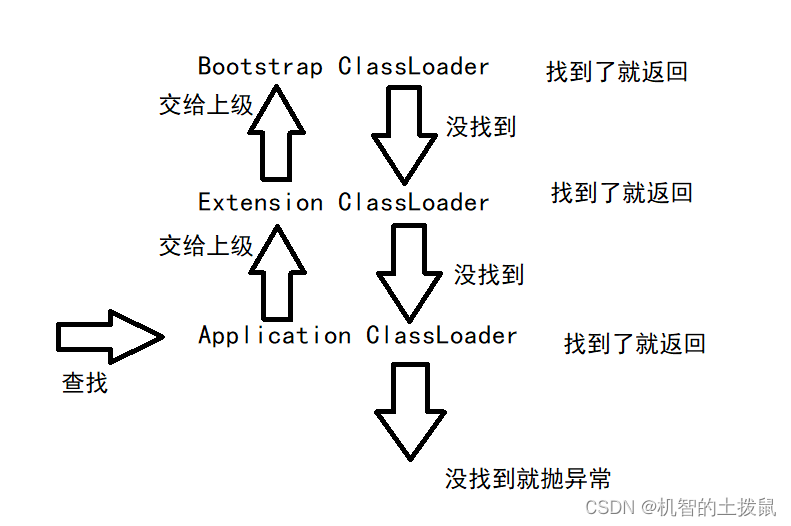
1.先从Application ClassLoader开始,此时并不会立即搜索第三方库的类,而是先把加载任务委派给"父亲",让父亲先尝试加载
2.到了Extension ClassLoader,此时也不会立即搜索扩展库的类,而是再把加载任务委派给"父亲",让父亲先尝试加载
3.到了Bootstrap ClassLoader,此时Bootstrap ClassLoader没有"父亲"了,只好自己去加载类了。如果找到了这个类,就会进行下一个类的加载,如果没找到了就会回到委派的那个类加载器,即Extension ClassLoader
4.任务回到Exension ClassLoader,此时只能自己去搜索扩展库的类了。如果找到了这个类,就会进行下一个类的加载,如果没找到了就会回到委派的那个类加载器,即Application ClassLoader
5.任务回到Application ClassLoader,此时只能自己去搜索第三方库的类了。
如果找到了这个类,就会进行下一个类的加载,如果没找到了会抛出异常。
总结:双亲委派模型就是一个找.class文件的过程。平时如果我们创建一个跟标准库中名字一样的类,使用的时候依旧是标准库中的那一个,因为双亲委派模型机制,会优先使用标准库的类,这也是这个机制的意义。
类加载时机
类加载使用了懒汉模式,即当使用的时候才会进行加载。
大致可以分为三个时机:
构造类的实例
使用了类的静态方法/静态属性
子类的加载会触发父类
一旦类被加载好了,后续使用就不必再加载了,直接使用即可。
三、JVM垃圾回收机制
在C语言中使用malloc手动申请完内存后需要手动释放,如果光申请而不去释放的话,到达一定程度后,内存被耗尽,程序就会崩溃,但是通过程序猿来手动操作就非常考验个人水平了,无法保证可靠。
Java为了解决上述问题,就引入了垃圾回收机制,自动的把垃圾释放掉。
虽然这个垃圾回收(GC)这个机制非常香,但是也是需要付出代价的,即消耗额外的系统资源和性能开销,同时也出现STW问题。
STW问题:
Stop-The-World 简称 STW,是指在执行垃圾回收的过程冻结所有用户线程的运行,直到垃圾回收线程执行结束。
垃圾回收的主战场在堆区,进行垃圾回收需要两步:判断对象是否为"垃圾"; 释放对象的内存。
判断对象是否为"垃圾"
当一个对象,在后续代码中不会被继续使用了,即这个对象已经没有任何引用指向它了,就可以认为是垃圾了。
如何判断,有如下两种思路:引用计数和可达性分析。
引用计数
核心思路:给每个对象里面安排一个计数器,每当有引用指向它的时候,就把计数器的值+1,每当引用被销毁,计数器的值-1.当计数器为0的时候,表示这个对象为垃圾。
优点:简单,好实现。
缺点:空间利用率低,浪费内存空间(当对象本身比较小的时候,会大大降低空间利用率);
存在循环引用问题,导致对象不能被正确识别为垃圾。如图:
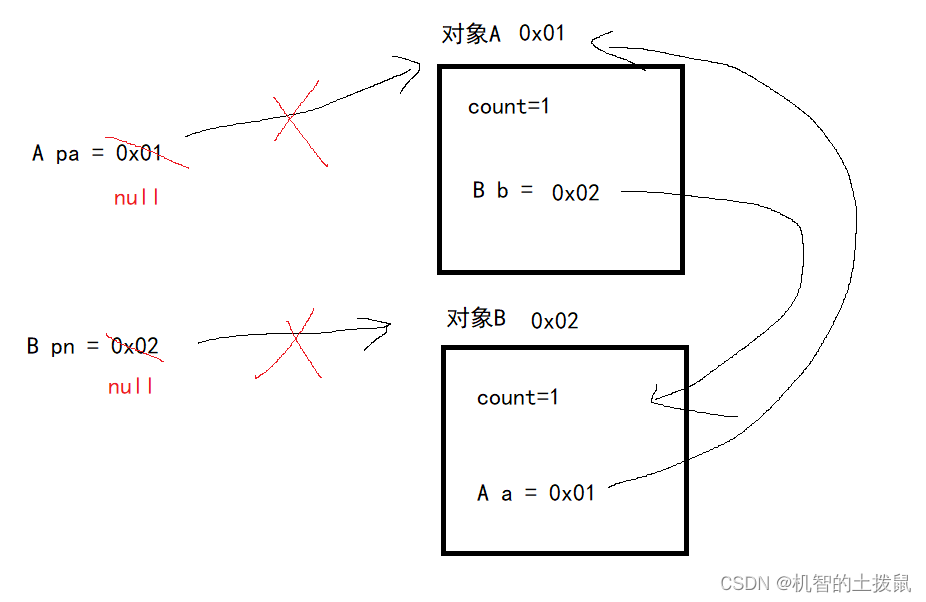
此时对象A,B在外部已经没有人指向了,即此时我们无法通过代码再去操作A和B了,按理来说已经成为了垃圾,但此时他们的计数器都不为0,无法正确的被识别为垃圾。
在Java中没有使用这种方式,但在Python,PHP的虚拟机中就是使用了引用计数的方式来完成的。
可达性分析
在Java中就采用了这个方案。
核心思路:JVM首先会从现有代码中的能直接访问到的引用出发,尝试遍历所有能访问的对象,只要对象能访问到,就会被标记为"可达"。完成整个遍历后,除开可达对象外,其它的也就是不可达对象,也就相当于是垃圾了。
优点:能够很好的解决引用计数中的循环引用问题。
缺点:需要消耗更多的时间。
释放对象内存
释放对象内存主要有三种方式:标记清除;复制算法;标记整理。
标记清除
标记清除是一种直接释放对象内存的方式。这种方式简单粗暴,但会遇到如下问题,即当GC对象是离散,空间不连续的时候:
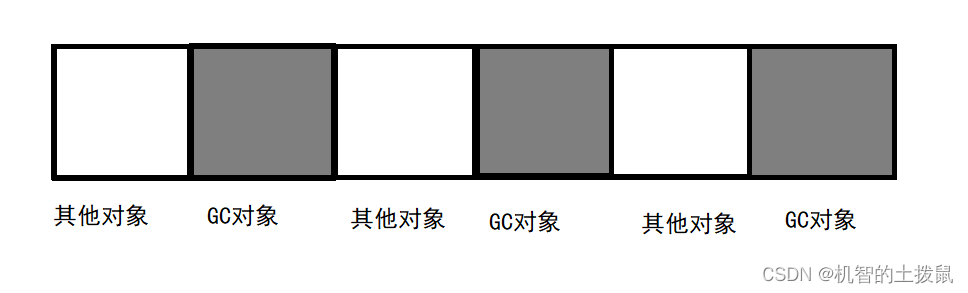
此时如果直接释放对象的话,就会引起"内存碎片"。在申请内存空间的时候都是申请一块连续的内存,当使用标记清除直接释放的话,此时如果申请的内存空间比正GC对象大的话,就无法使用这块已经被回收的内存。
例如:假设上图中的每个GC对象的大小是1MB,但我们此时要申请一个2MB的内存空间,由于每个GC对象内存的前后的内存被占用了,我们就无法申请到空间.
复制算法
复制算法的核心思路是将空间分成两份,把有效对象复制到另一部分内存空间,来避免内存空间。
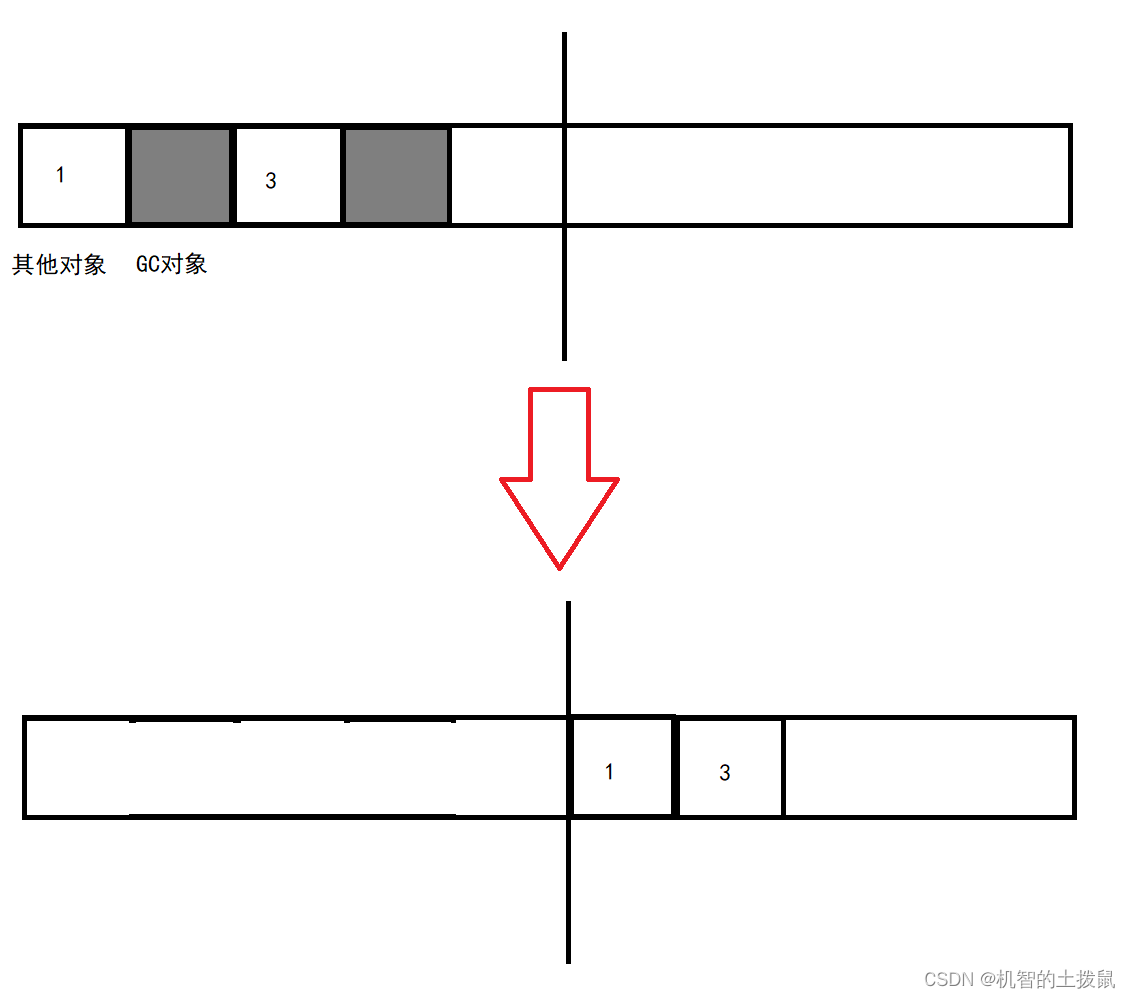
先是将左侧有效对象进行复制,放到右侧,然后再释放内存,当用了一段时间后,右侧也会有许多需要GC的对象,此时就将有效对象复制到左侧,循环往复。
虽然这种方式能有效的解决内存碎片问题,但当需要复制的对象内容比较多,就会引发不小的开销,并且由于会将内存进行划分,也会造成内存利用低的问题。
标记整理
标记整理是使用顺序表删除元素的思路。
每当要GC一个对象,会将后面的对象往前搬运。
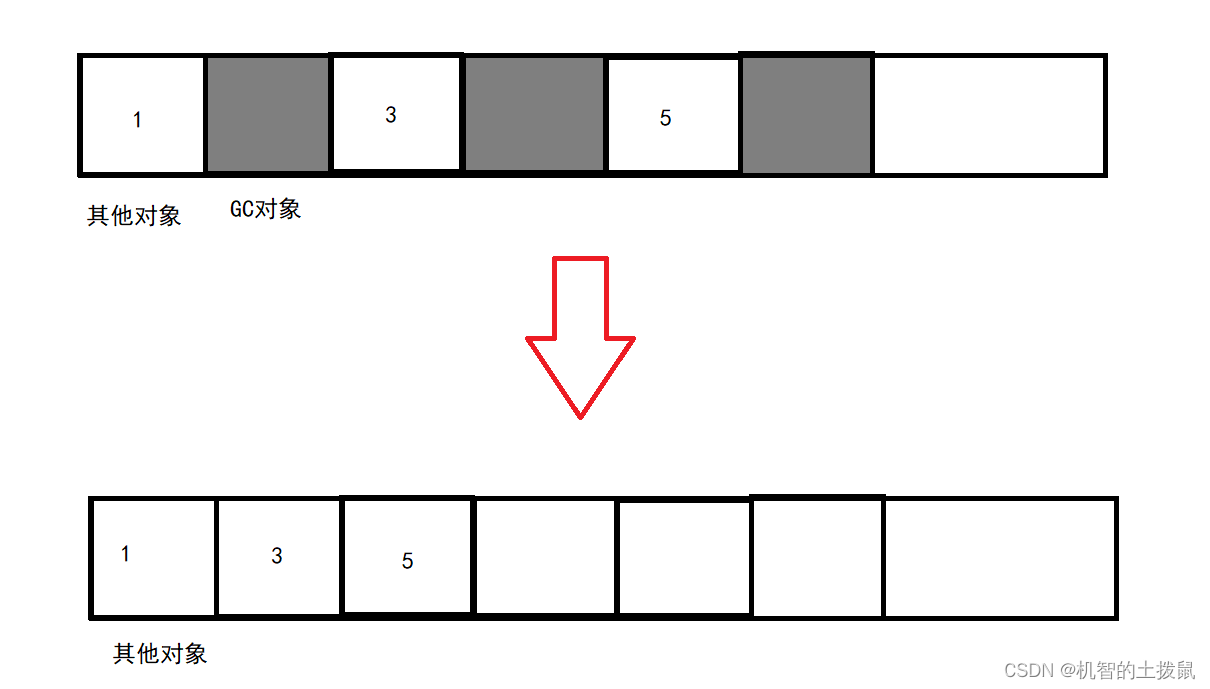
这种方式,不仅可以解决内存碎片问题,也解决了内存利用率低的问题,但是会涉及频繁搬运的问题,这就会带来不小的开销。
分代回收
设计JVM的大佬集百家之长,搞了一个综合性的解决方法:分代回收。
分代回收是基于"一个对象存在的越久,那么它将继续存在的可能性就越高"的事实,然后对每个对象使用"年龄"标记,根据年龄来制定不同的回收策略。

分代回收将整个堆分成了两部分:新生代和老年代。在新生代中又划分了两个不同的区域:伊甸区和幸存区。
在新生代中以复制算法为主,在老年代中以标记整理算法为主。
伊甸区中存放的是新生的对象,在经过一轮的GC后,没有被回收的对象就会被通过复制算法,复制到幸存区中。
幸存区中又划分了两块不同的空间,用来针对后续的复制算法,当第二轮GC后,没有被回收的对象就会被复制到幸存区中另一块空间。
如果一个对象在幸存区中存活了好多轮都没有挂,这个对象的年龄就比较大了,就会被复制到老年代中。
在新生代中每一轮GC留下的对象并不会很多,所以进行复制算法的开销并不会很大,而在老年代中,对象比较重要,所以销毁的也很少,此时标记整理开销也不会很大。
