
阅读量:0
hash表原理与实战
专栏内容:
文章目录
一、概述
hash表的应用非常广泛,在网上也可以看到分享的各种hash表的实现,都比较概念化。
本章节从实战的角度出发,以数据库内核中的应用为例,来看看hash表的原理与实现。
二、hash表整体介绍
哈希算法(Hash)又称摘要算法,它的作用是:对任意一组输入数据进行计算,得到一个固定长度的输出摘要。
哈希算法最重要的特点就是:
- 相同的输入一定得到相同的输出;
- 不同的输入大概率得到不同的输出;
我们想利用hash算法的这一特性,将输入的一组数据,经过hash算法计算后,输出唯一的 32位或64位的整形值key。
当我们需要找到存储的数据时,通过这个key查找,而查找整型值的效率就很高了,可以用二分法进行查找。
这样一个存储数据的结构,我们叫它hash表,也就是通常说的key-value形式的存储,它的查找效率与数据的类型无关。
2.1 hash表的应用场景
hash表一般用于存储大量的数据,而数据的类型是字符串,或者更复杂的复合类型结构体,或者是更大的数据;
直接通过原始数据进行查找时,代价非常高,将它们转换为hash 值后,就可以通过恒定的效率进行查找。
在数据库中的应用有:
- 数据块缓存,某个数据块是否已经在缓存中,通过对数据块编号的hash值进行查找;
- 系统字典的查找,某个表是否已经创建了,通过表的hash值进行查找;
- hash索引,记录数据的hash值,查找时按hash值进行查找;
2.2 整体架构
hash表的实现一般由几方面组成,hash算法,bucket计算,冲突处理,key-value对应形式,以及三种操作。
- 既然是一个table,那么内部基本存储结构是一个数组,数组的最大元素个数就是capacity;
- 数组中的每个元索叫做bucket桶,来存储key-value对数据;
- bucket位置的计算,一般会采用
hash值 % capacity来计算;hash值一般是一个32位,64位或者128位的整数,取余后得到数组中的下标,这就是当前key-value要存储的位置;
三、hash算法选择
查找主要依赖高效的hash值的计算,一个高效,碰撞少的算法,能让hashtable的效率大大提升。
常见的hash算法有,MD5, sha-256等,这些常用于加密,而hashtable并不需要对数据进行加密,更看重计算的效率。
由此出现了一些快速hash算法,比较有名的如:
- murmurhash3, 这是第三个版本,速度公认的非常快,开源了各种语言实现;
- Spookyhash,这个目前支持128位;
- cityhash,是google发布的,会利用现代CPU的特性进行性能提升,对于低于64位的输入处理比较复杂;
建议使用murmurhash3,算法简单高效,对于较少的输入也能高效处理。
这些算法都可以在github上下载得到,加入.c,.h文件后就可以直接调用使用。
类似如下调用:
seed = 123456789 data = "example data" hash_value = murmur_hash(seed, data) 四、hash表操作
hash表的操作一般有插入,查找,删除三类基本操作。
对于修改操作可以分解为这三项的组合,先查找,再删除,然后插入,因为修改后的键值发生变化,对于它在hash表中的位置也会发生变化。
4.1 冲突处理
在开始操作之前,需要注意一种情况,因为我们数组元素个数有限,在取余之后难免会出现多个key-value数据在相同位置的情况,也就是key产生了冲突。
一般有两种处理方式:
- 一是在冲突位置往后继续找空位置存储;
- 二是在当前桶内以链表的形式存储;
两种不同的冲突处理,对应了后面操作的不同。这里采用第二种方法,如果有多个相同数据在同一桶中时,以单链表的形式存储。
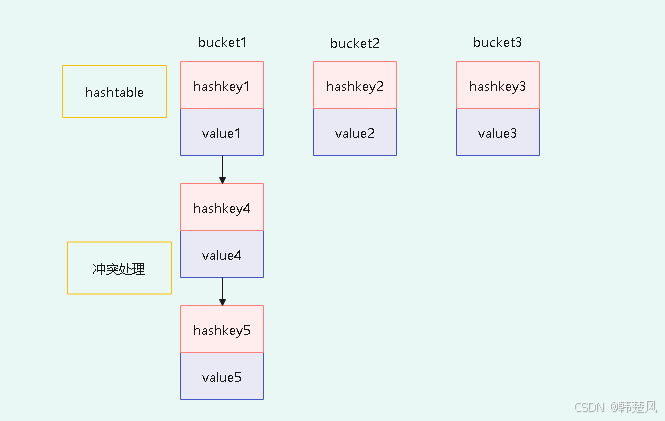
图中可以看到,出现冲突时,key4,key5直接追加到key1后面。
那么定义数组元素类型时,就要定义为链表形式。
typedef unsigned long long HASHKEY; typedef struct HashElement { struct HashElement *link; HASHKEY hashKey; char *value; }HashElement; 这里定义hash为64位的整形,当然可以是其它位数。
4.2 查找操作
查找一个key-value值是否在hashtable中的步骤如下:
- 调用hash算法接口,计算value的hash值;
- 按找hash值计算bucket位置;
- 找到bucket,查看是否为空;
- 如果bucket中有多个元素,遍历链表进行比对hash值;
- 如果存在相同的hash值元素,则找到;否则没有找到。
获取hashkey函数
#define Hash_capacity 100 HashElement * hashtable[Hash_capacity]; HASHKEY getHashKey(char *value, int valueSize) { return spooky_hash64(value, valueSize, 0); } 获取bucket函数
int GetBucketIndex(HASHKEY key, PHashTableInfo hashTableInfo) { int bucket = key & Hash_capacity; return bucket; } 查找函数
HashElement* HashFindEntry(char *value) { HashElement *entry = NULL; int bucket = 0; HASHKEY key = 0; key = getHashKey(value, strlen(value)); bucket = GetBucketIndex(key); entry = GetHashEntryFromBucket(hashtable[bucket], key); return entry; } 从bucket链中查找
HashElement* GetHashEntryFromBucket(HashElement* bucket, HASHKEY key) { HashElement* element = bucket; while(element != NULL) { if(element->hashKey == key) { return element; } element = element->link; } return NULL; } 当然这里,除取比较key值外,还可以对value定义比较函数,这样避免hash值冲突的情况。
4.3 插入操作
插入操作就比较简单,步骤如下:
- 计算hash 值;
- 根据hash值获取bucket位置;
- 存储对应bucket,如果已经有元素,存到链到头部;
HashElement* HashInsertEntry(char *value) { HashElement *entry = NULL; int bucket = 0; HASHKEY key = 0; key = getHashKey(value, strlen(value)); bucket = GetBucketIndex(key); entry = malloc(sizeof(HashElement)); if(NULL == entry) { return NULL; } entry->link = NULL; entry->hashKey = key; entry->value = value; if(NULL != hashtable[bucket]) entry->link = hashtable[bucket]; hashtable[bucket] = entry; return entry; } hash节点数量不确定,故采用动态内存分配;
在冲突时采用了头插法,这样操作比较简单;
4.4 删除操作
从hash表中找到并删除一个元素的步骤如下:
- 计算value的hash值;
- 计算对应的bucket位置
- 从bucket链中进行查找,同时记录下它的前继;
- 将对应key的元素从链表中删除;注意链表只有一个元素的情况;
- 将删除的元素返回,由调用者释放内存空间;
HashElement* DeleteHashEntry(char *value) { HashElement *pre = NULL; HashElement* element = NULL; int bucket = 0; HASHKEY key = 0; key = getHashKey(value, strlen(value)); bucket = GetBucketIndex(key); pre = element = hashtable[bucket]; while(element != NULL) { if(element->hashKey == key) { if(pre == element) { hashtable[bucket] = NULL; } else { pre->link = element->link; } return element; } pre = element; element = element->link; } return NULL; } 五、总结
本文介绍了哈希表的实现及原理,同时介绍了几种hash计算方法。
当然本节介绍的内容,都是在没有并发冲突的情况下使用,如果多线程操作时,需要进行加锁处理。
如果需要更高效的并发场景下的hash表,后面章节会继续介绍。
结尾
非常感谢大家的支持,在浏览的同时别忘了留下您宝贵的评论,如果觉得值得鼓励,请点赞,收藏,我会更加努力!
作者邮箱:study@senllang.onaliyun.com
如有错误或者疏漏欢迎指出,互相学习。
注:未经同意,不得转载!
