
阅读量:2
章节内容
上一节完成了如下的内容:
- 编写Agent Conf配置文件
- 收集Hive数据
- 汇聚到HDFS中
- 测试效果
背景介绍
这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。
之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。
- 2C4G 编号 h121
- 2C4G 编号 h122
- 2C2G 编号 h123

文档推荐
除了官方文档以外,这里有一个写的很好的中文文档:
https://flume.liyifeng.org/
监控目录
业务需求
- 想要监控指定目录 收集信息并上传到HDFS中
Source
选择 spooldir,因为 spooldir 能够保证数据不丢失,且能够进行断点续传,但是延迟较高,不能实时监控。
Channel
选择 memory
Sink
选择 HDFS
需要注意
- 拷贝到 spool 目录下的文件 不可以再打开编辑
- 无法监控子目录的文件夹变动
- 被监控文件夹每500毫秒 扫描一次文件变动
- 适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步
配置文件
cd /opt/wzk/flume_test vim flume_spooldir-hdfs.conf 我们需要写入如下内容
# Name the components on this agent a3.sources = r3 a3.channels = c3 a3.sinks = k3 # Describe/configure the source a3.sources.r3.type = spooldir # 注意这里的文件夹 换成自己的!!! a3.sources.r3.spoolDir = /opt/wzk/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true # 忽略以.tmp结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 10000 a3.channels.c3.transactionCapacity = 500 # Describe the sink a3.sinks.k3.type = hdfs # 注意修改成你自己的IP!!! a3.sinks.k3.hdfs.path = hdfs://h121.wzk.icu:9000/flume/upload/%Y%m%d/%H%M # 上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- # 是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true # 积攒500个Event,flush到HDFS一次 a3.sinks.k3.hdfs.batchSize = 500 # 设置文件类型 a3.sinks.k3.hdfs.fileType = DataStream # 60秒滚动一次 a3.sinks.k3.hdfs.rollInterval = 60 # 128M滚动一次 a3.sinks.k3.hdfs.rollSize = 134217700 # 文件滚动与event数量无关 a3.sinks.k3.hdfs.rollCount = 0 # 最小冗余数 a3.sinks.k3.hdfs.minBlockReplicas = 1 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 启动Agent
$FLUME_HOME/bin/flume-ng agent --name a3 \ --conf-file flume-spooldir-hdfs.conf \ -Dflume.root.logger=INFO,console 
测试效果
Flume
cd /opt/wzk/upload vim 1.txt 随便向其中写入一些内容,并保存,可以看到Flume已经有反应了。
HDFS
查看HDFS,也已经有内容了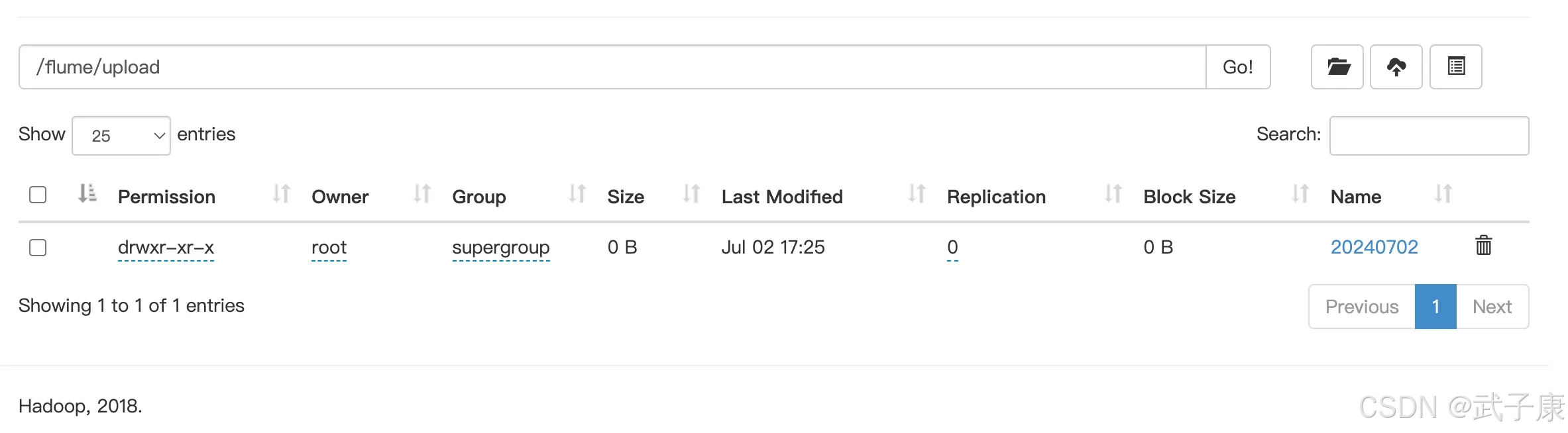
采集双写
这里业务上需要:
- Flume将数据写入本地
- Flume将数据写入HDFS
分析实现
- 需要多个Agent级联实现
- Source选择taildir
- Channel选择memory
- 最终的Sink分别选择HDFS,file_roll
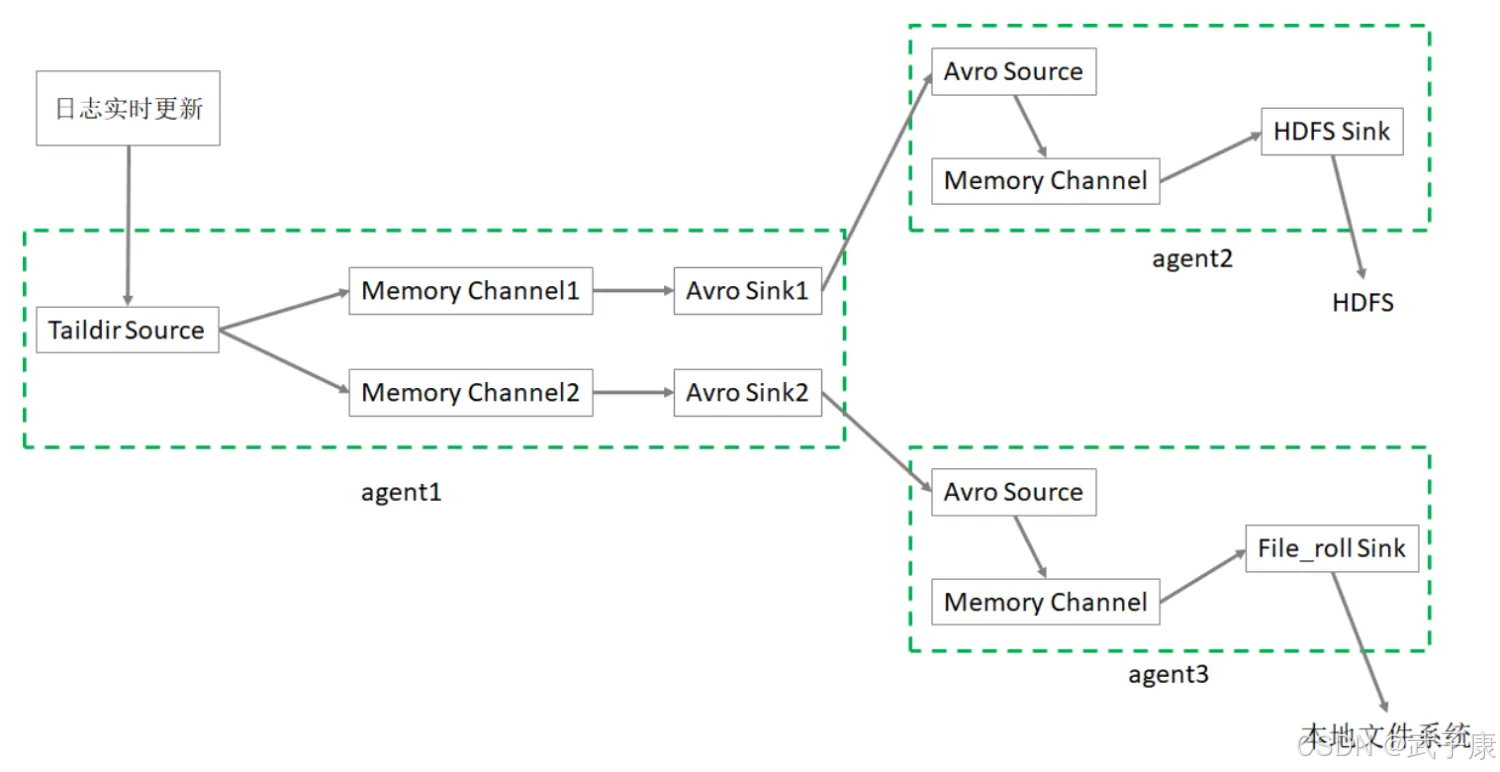
配置文件1
配置文件包含如下内容:
- 1个 taildir source
- 2个 memory channel
- 2个 avro sink
新建文件
vim flume-taildir-avro.conf 写入如下内容
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给所有channel a1.sources.r1.selector.type = replicating # source a1.sources.r1.type = taildir # 记录每个文件最新消费位置 a1.sources.r1.positionFile = /root/flume/taildir_position.json a1.sources.r1.filegroups = f1 # 备注:.*log 是正则表达式;这里写成 *.log 是错误的 a1.sources.r1.filegroups.f1 = /tmp/root/.*log # sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = linux123 a1.sinks.k1.port = 9091 a1.sinks.k2.type = avro a1.sinks.k2.hostname = linux123 a1.sinks.k2.port = 9092 # channel a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 500 a1.channels.c2.type = memory a1.channels.c2.capacity = 10000 a1.channels.c2.transactionCapacity = 500 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 配置文件2
配置文件包含如下内容:
- 1个 avro source
- 1个 memory channel
- 1个 hdfs sink
新建配置文件
vim flume-avro-hdfs.conf 写入如下的内容:
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = linux123 a2.sources.r1.port = 9091 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 10000 a2.channels.c1.transactionCapacity = 500 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://linux121:8020/flume2/%Y%m%d/%H # 上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- # 是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true # 500个Event才flush到HDFS一次 a2.sinks.k1.hdfs.batchSize = 500 # 设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream # 60秒生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 60 a2.sinks.k1.hdfs.rollSize = 0 a2.sinks.k1.hdfs.rollCount = 0 a2.sinks.k1.hdfs.minBlockReplicas = 1 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 配置文件3
配置文件包含如下内容:
- 1个 avro source
- 1个 memory channel
- 1个 file_roll sink
新建配置文件
vim flume-avro-file.conf 写入如下的内容
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = linux123 a3.sources.r1.port = 9092 # Describe the sink a3.sinks.k1.type = file_roll # 目录需要提前创建好 a3.sinks.k1.sink.directory = /root/flume/output # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 10000 a3.channels.c2.transactionCapacity = 500 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 启动Agent1
$FLUME_HOME/bin/flume-ng agent --name a3 \ --conf-file ~/conf/flume-avro-file.conf \ -Dflume.root.logger=INFO,console & 启动Agent2
$FLUME_HOME/bin/flume-ng agent --name a2 \ --conf-file ~/conf/flume-avro-hdfs.conf \ -Dflume.root.logger=INFO,console & 启动Agent3
$FLUME_HOME/bin/flume-ng agent --name a1 \ --conf-file ~/conf/flume-taildir-avro.conf \ -Dflume.root.logger=INFO,console & Hive测试
hive -e "show databases;" 