
阅读量:5
Hi~!这里是奋斗的小羊,很荣幸各位能阅读我的文章,诚请评论指点,欢迎欢迎~~
💥个人主页:小羊在奋斗
💥所属专栏:C语言
本系列文章为个人学习笔记,在这里撰写成文一为巩固知识,二为一些学友们展示一下我的学习过程及理解。文笔、排版拙劣,望见谅。
1、大小端字节序和字节序判断
2、浮点数在内存中的存储
2.1浮点数存的过程
2.2浮点数取的过程
1、大小端字节序和字节序判断
在 C语言(操作符)1 中,我们介绍了整数在内存中的存储,但是我们只介绍了整数的存储形式,并没有介绍整数是如何存储的,那本节我们就来探讨一下整数在内存中究竟是怎么存储的。
当我们想把0x11223344这个数存到一个整型变量a中时,因为整型数据的大小是4个字节,以字节为单位存储,那么11占一个字节,22占一个字节,33占一个字节,44占一个字节,假设从低地址向高地址存储,那先存11还是先存44就是一个问题。其实超过一个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为大端字节序存储和小端字节序存储。

也就是说,大端字节序存储是地址由低到高依次存高位,小端字节序存储是地址由低到高依次存低位。
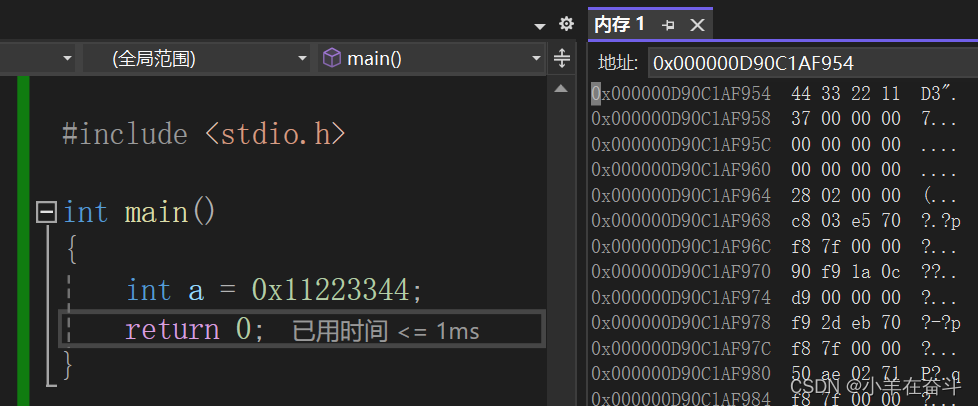
我们之前可能会疑惑VS中整数在内存中为什么是反着存的,那这里就给了我们解释,VS所在的当前计算机系统使用的是小端字节序存储,而大多数计算机架构使用的都是小端字节序存储。
如果我们想知道当前的机器使用的是哪种存储方式,可以写一个简单的判断小程序来实现。当我们在一个整型变量中存一个整数1时,如果当前机器是大端字节序存储,那么它存的就是 00 00 00 01,如果当前机器是小端字节序存储,那么它存的就是 01 00 00 00。既然如此,我们只需要将这个整型变量最小字节中的数据拿出来,看这个最小字节单元中存的数是0还是1,如果是0就是大端字节序存储,反之则为小端字节序存储。
了解了大小端存储,我们来做一些练习加深理解。
练习1

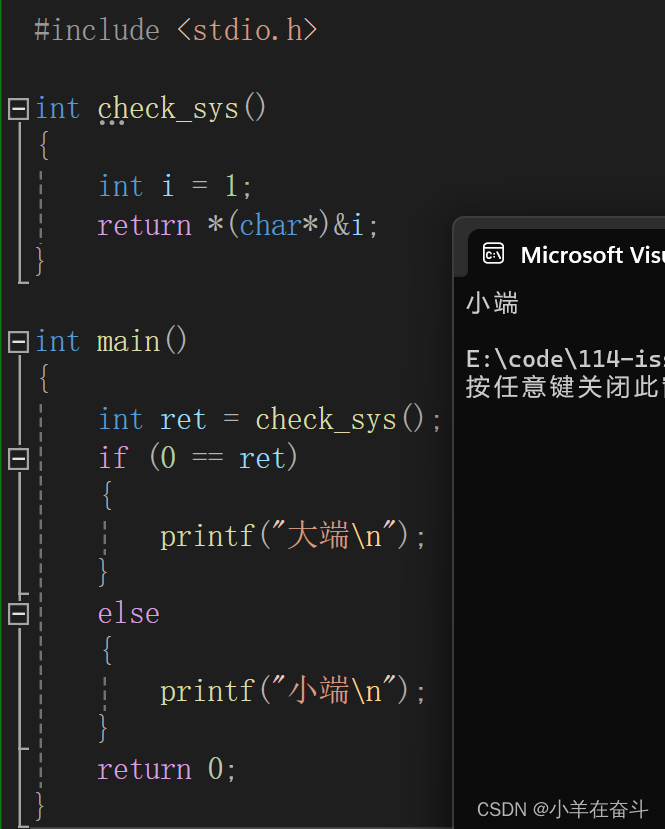
上面代码的输出结果是什么呢?(其实我们在C语言(操作符)2中的表达式求值部分已经学习过)我们来分析一下:
我们想将整数-1存入一个字符型变量a中,整型和字符型不兼容,通过C语言(操作符)2的学习我们知道要发生截断,所以只将-1的补码的后8位存到a中,我们又用%d(打印有符号整型)打印字符型变量a,那%d就认为它打印的数是整型,a不是整型所以要发生整型提升,a是char(signed char)类型,整型提升高位补符号位,补完后还是32个1,取反加一得原码又变为了-1,最终结果就打印出了-1,因为在VS中char和signed char是一样的,所以打印b也就同样的道理。
而我们将整数-1存入一个无符号字符型变量c中,截断只存入-1的补码的后8位,用%d打印需要整型提升,而c是无符号字符型,整型提升高位补0,补完后用%d打印时%d看它就是一个比较大的正数,原反补相同,00000000000000000000000011111111就是255。
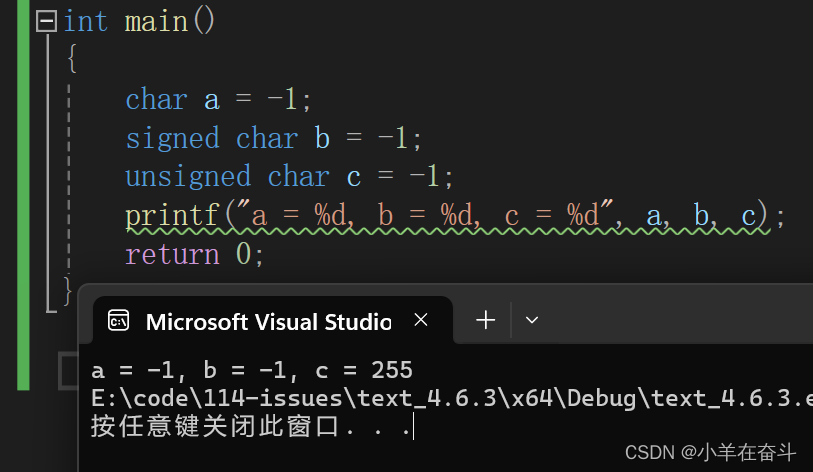
练习2

将整数-128(补码:11111111111111111111111110000000)存入(signed)char类型a中,截断后a中存的是10000000,用%u(打印无符号整数)打印需要整型提升,a为signed char所以高位补符号位,补完就是11111111111111111111111110000000,目前还是补码,但是在%u眼中无符号整形原反补相同,所以%u再以原码打印出来就是4294967168。
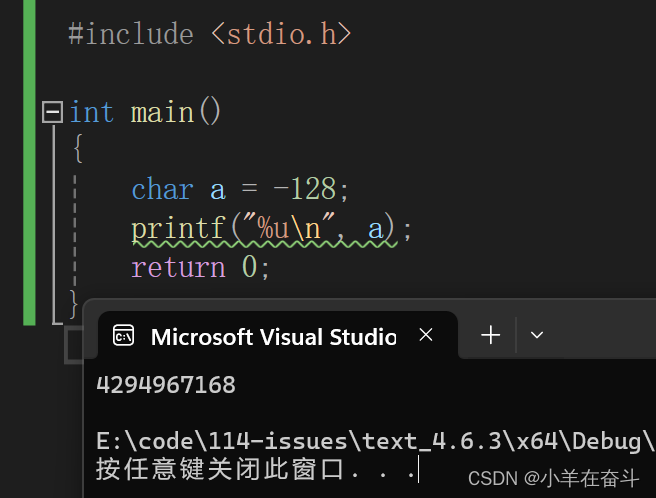
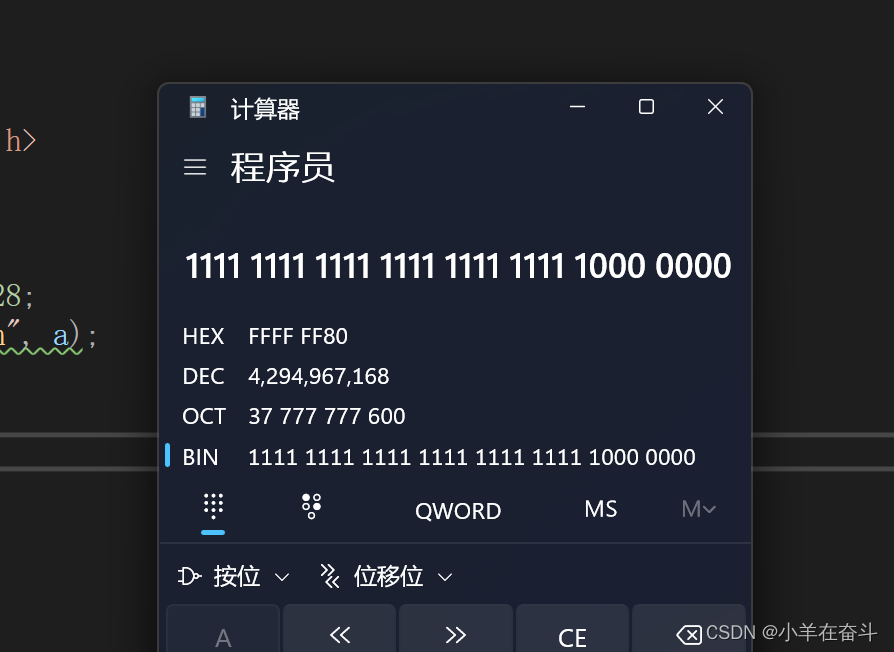
将a改为128,结果还是一样的,因为它们截断的结果是一样的。
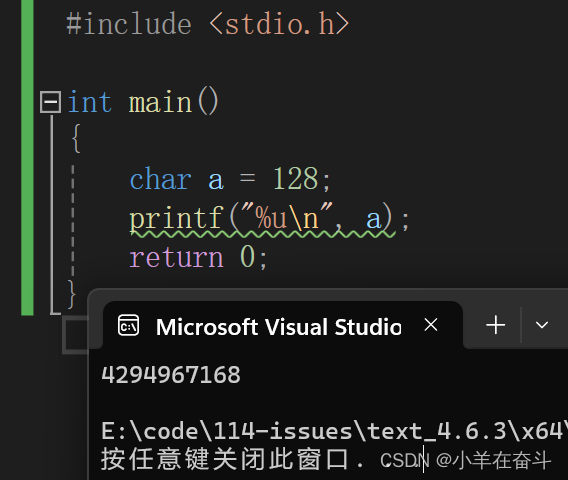
至于为什么对a存-128还是128结果是一样的,这里再做一个解释:
我们很早就知道,(signed)char类型的取值范围是:-128~127 ,但是为什么是这个范围并没有解释。char类型占一个字节也就是8个比特位,最高位当做符号位来看待,就剩下了7位存0、1值。

在C语言(操作符)2中,我们还画了这样一个图,并做了相应解释。
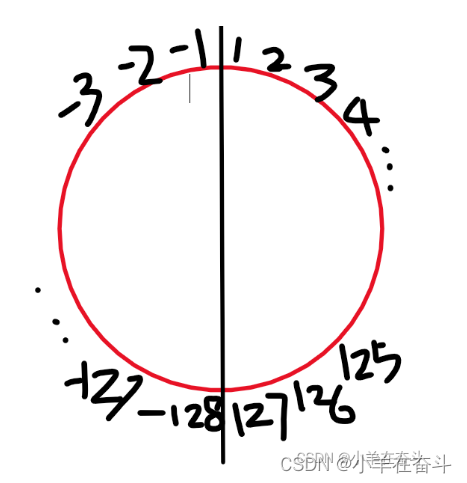
127+1在数学上是128,但在char类型中就是-128,因为char类型最大的正数就是127,所以给char类型存128和-128是一样的。其他的类型都是这样的道理。
练习3
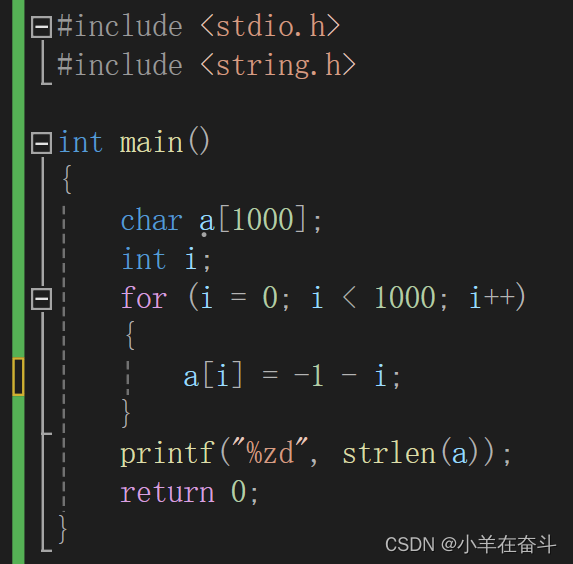
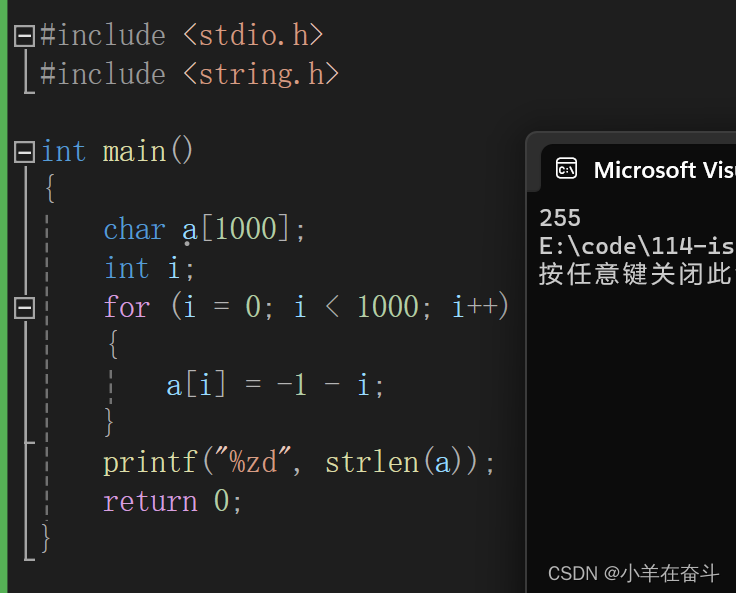
创建一个字符数组大小1000,向数组中存入-1、-2、-3..,然后strlen求字符数组a的长度。我们知道strlen是求字符串的长度,统计的是\0之前的字符个数,那看来意思就是让我们找字符‘\0’了又因为a是字符数组所以-1、-2、..、-127、-128、127、126、...、2、1、0,0在字符眼中就是\0,所以求的是-1~0的长度,是255。
练习4

unsigned char的范围是0~255,所以上面的代码给我们的感觉就是打印255个hello world,但事实真是如此吗?当我们运行起来就会发现程序陷入了死循环。这是因为当i加到256时虽然此时不满足循环了,但是这时候的256只是数学上的256,而在unsigned char眼中255+1就变成了0,所以循环继续。

上面这个代码也是如此,当i为0时,0-1就变成了2^32-1,因为在unsigned int的世界里没有负数,所以程序陷入了死循环。
练习5

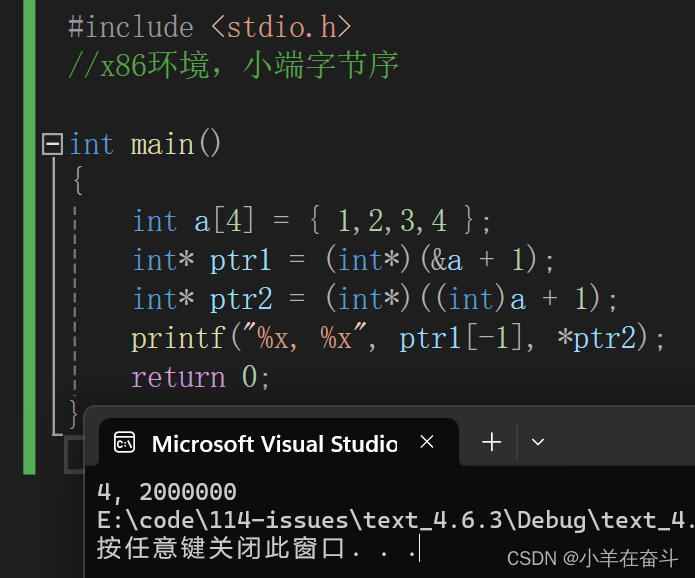
创建一个整型数组大小4,&a取出整个数组的地址再+1跳过整个数组指向数组末尾,此时指针(地址)的类型是int (*) [4],再强转为 int * 类型的指针赋给ptr1,ptr1[-1]( *(ptr -1) )就是int *类型的指针-1向后推4个字节指向数组最后一个元素4,再解引用用%x(打印16进制)打印出来就是4。
数组名a表示数组首元素的地址,强转为int类型的整数再+1,再强转为int *类型的指针,最终的结果就是数组首元素的地址+1(整数+1),注意ptr2是一个整型类型的指针,所以它访问的是4个字节的地址。
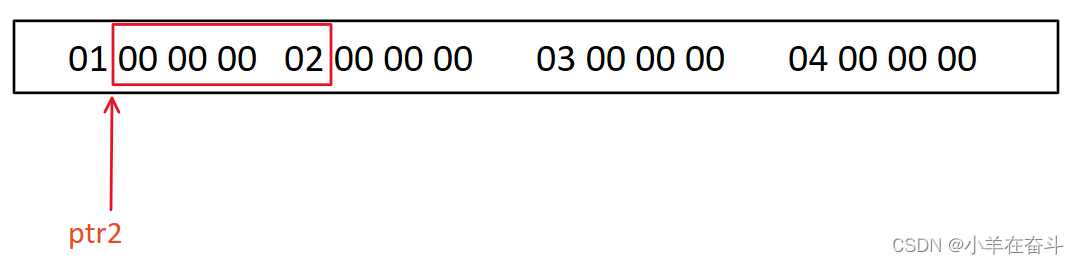
我们又知道小端字节序是反着存的,所以ptr2指向的数值就是02 00 00 00,打印出来就是2000000。
如果我们想把代表16进制的0x也打印出来,可以在%的后面加上#。
2、浮点数在内存中的存储
2.1浮点数存的过程
浮点数和整数在内存中的存储有什么区别吗?

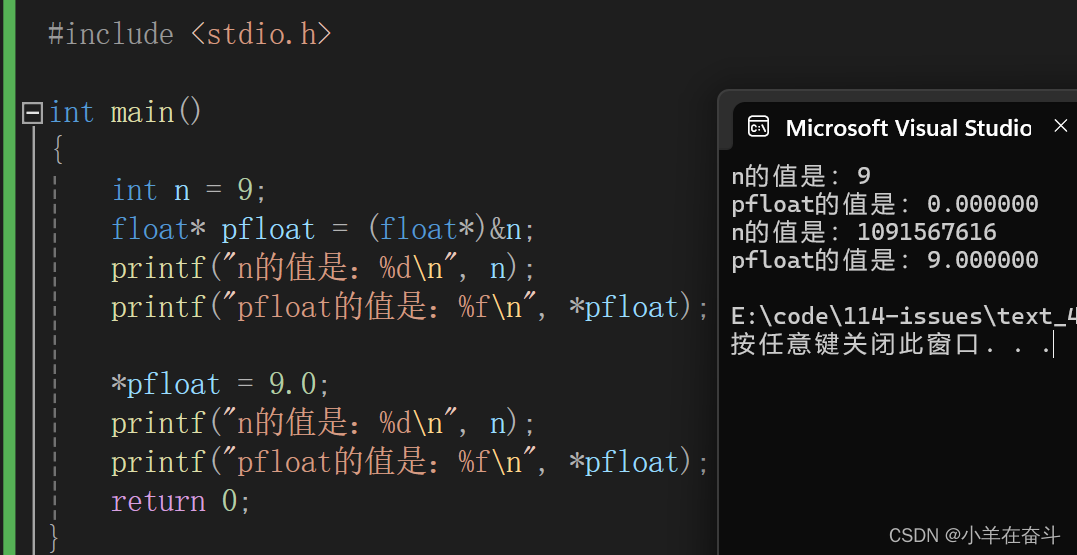
如果用我们学到的整数存储的方法来解读上面的代码,打印出来的结果应该就是9、9.000000、9、9.000000。
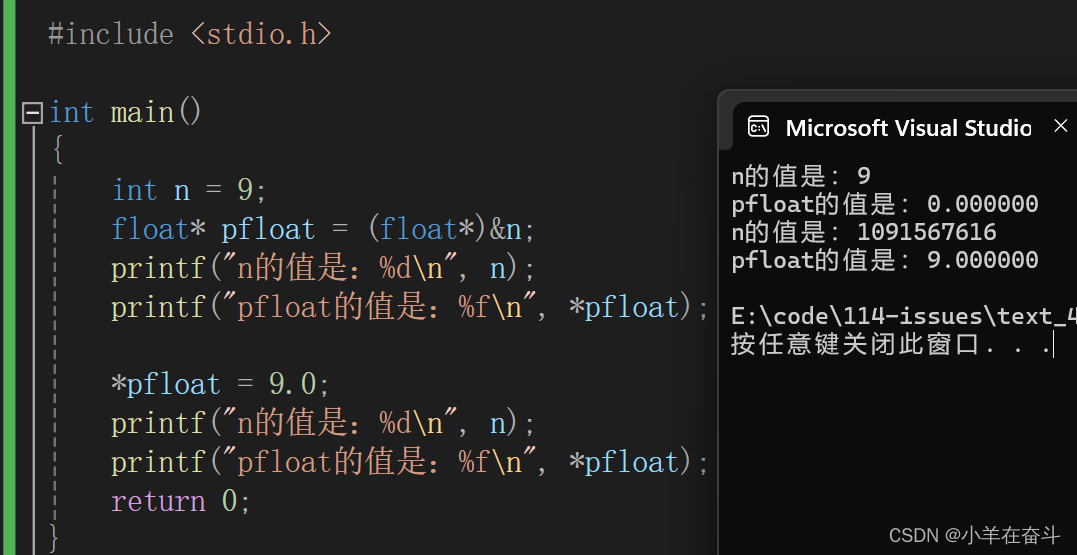
但结果并不是这样,通过观察我们发现,只有当n是整数9时用%d打印的结果和当n是浮点数9.0时用%f打印的结果是我们预料中的,所以可以肯定的是整数和浮点数在内存中的存储是不一样的。
那浮点数在内存中是怎么存的呢?根据 IEEE 754规定,任意一个二进制浮点数V可以表示为这样的形式:V=(-1)^S*M*2^E。(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。M表示有效数字,M是大于等于1小于2的。2^E表示指数位。
比如十进制的5.5,写成二进制就是101.1,转化的方法是按位权来转化,小数点前面的位权是2的1次方、2的2次方、2的3次方....,小数点后面的位权是2的-1次方、2的-2次方、2的-3次方......。十进制的5.5二进制表示101.1用科学计数法表示就是1.011*2^2,又因为5.5是正数,所以用IEEE 754标准表示就是:(-1)^0*1.011*2^2。其中的S=0,M=1.011,E=2。
任何一个浮点数都可以用S、M、E这三个值来表示,所以浮点数的存储,存储的就是S、M、E 相关的值。
IEEE 754规定:
对于32位的浮点数(float),最高的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M。

对于64位的浮点数(double),最高的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M。
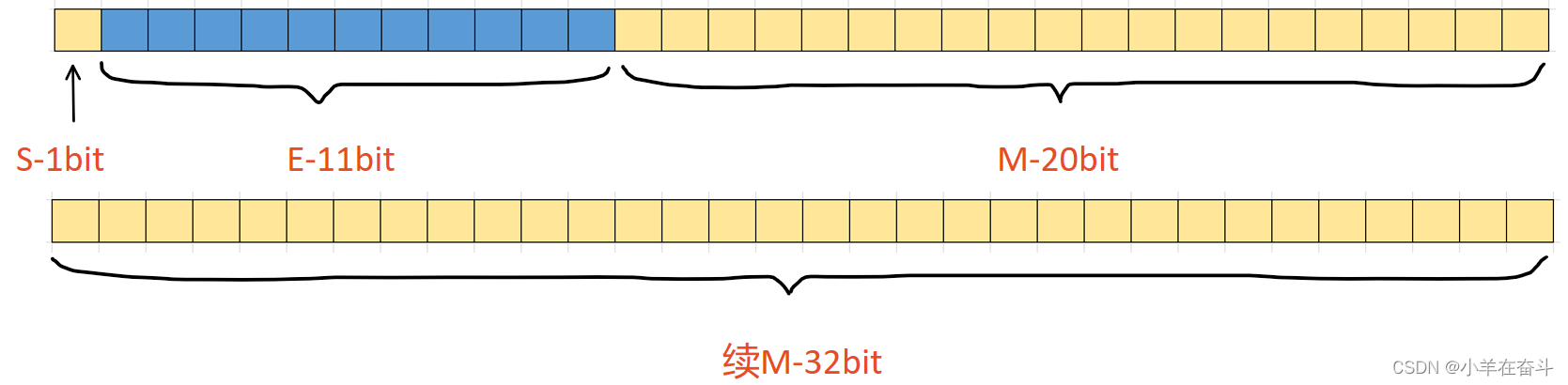
IEEE 754对有效数字M和指数E还有一些特别规定。
前面说过,1<=M<=2,所以M总是1.xxxxx,IEEE 754规定,在计算机内部保存M时,默认这个数的第一位是1,因此1可以舍去,只保存小数点后面的xxxxx,读取的时候再把第一位的1加上就行。这样做的目的是节省1位有效数字,使存储的精度更高。
E作为一个无符号整数,如果E为8位,它的取值范围是0~255;如果E为11位,它的取值范围是0~2047。但是在科学计数法中指数有可能是负数,所以 IEEE 754规定,存入内部的E的真实值必须再加上一个中间数,对8位的E这个中间数是127;对11位的E这个数是1023。比如2^10的E是10,保存成32位的浮点数时,必须保存成137,即10001001。我们也不用担心加上这个中间数后E的值还不能为正数,因为当E非常小时已经无限接近于0了,而float和double也是有精度限度的。
比如float类型的5.5在内存中的存储就是:
![]()
本计算机系统采用的是小端字节序存储。
2.2浮点数取的过程
指数E从内存中取出的过程可分为三种情况:
E不全为0或不全为1(常规情况)
指数E的计算值减去127或1023得到真实值,再将有效数字M前加上第一位的1。
E全为0(罕见)
这时,浮点数的指数E等于1-127或1-1023即为真实值,有效数字M不再加上第一位的1,而是还原为0.xxxxx的小数。这样做是为了表示+-0,以及无限接近于0的极小的数字。
E全为1(罕见)
这时,E的真实值为255-127=128,这又是一个极大的数,大到我们无法想象,所以就不去讨论它了。
了解清楚了浮点数在内存中的存取后,我们再来分析一下前面的那个代码。

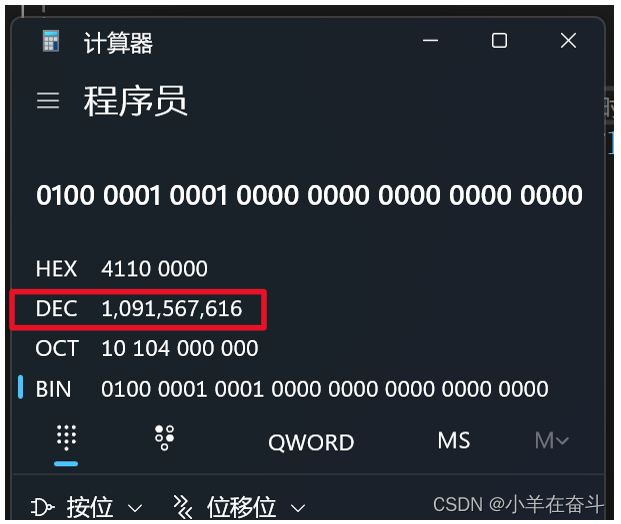
创建一个整型变量n赋值为9,用%d打印时就按常规打印出整数9。我们再取出n的地址将其强转为float *类型的指针再赋给pfloat,再解引用pfloat用%f打印,9在内存中的补码是:
00000000000000000000000000001001,而pfloat是float *类型的指针,所以pfloat就认为它指向的数是一个浮点数,就会按浮点数存取的规则来读取,在pfloat眼中整数9的补码是这个样子:

S=0,E为全0,那这个值就是一个极小的正数,无限接近于0,而float只能打印小数点后6位,所以打印的结果应该就是0.000000。
而将9.0存到float *类型的地址中时,9.0用二进制表示为:1001.0,根据 IEEE 754 规定,S=0,M=1.001,E=3,那在内存中的存储就应该是下面这个样子的:

用%d打印时%d就认为这是一个很大的正数 ,原反补相同。而用%f打印就是正常的9.000000。
本节内容并不需要我们死记硬背,只需要知道整数和浮点数在底层是怎么存取的,又有什么差异,当某天我们错用格式符打印不同类型的值时,我们要知道是怎么回事,要会分析,为什么会输出这个值,这个值是随机的还是有它的道理的就行。
只要我们遵守规则,有符号整数就用%d打印,无符号整数就用%u打印,float类型就用%f打印,double类型就用%lf打印,size_t类型就用%zd打印……就行。
如果觉得我的文章还不错,请点赞、收藏 + 关注支持一下,我会持续更新更好的文章。
点击跳转下一节—> C语言(结构体)
