
阅读量:0
目录
一、引言
在Elasticsearch中,过滤文档以满足特定条件是一个常见的需求。传统的过滤器(Filter)在Elasticsearch的早期版本中扮演着重要角色,但在后续的版本中,过滤器的概念逐渐被查询(Query)中的布尔子句(Bool Clause)所取代。
然而,在某些场景下,我们可能需要在查询执行完成后对结果进行额外的过滤,这就是Post_Filter后置过滤器的作用所在。本文将详细介绍Elasticsearch中的Post_Filter后置过滤器技术,包括其工作原理、使用场景、DSL使用示例以及优化策略等内容。
二、Post_Filter后置过滤器概述
Post_Filter后置过滤器是一种在查询执行完成后对结果进行过滤的机制。与传统的过滤器不同,Post_Filter不会对查询的性能产生显著影响,因为它是在查询完成后对结果进行过滤的。这使得Post_Filter在处理大量数据或复杂查询时成为一种高效的选择。
Post_Filter的工作原理是在查询执行完毕后,对返回的文档集进行过滤。这意味着所有与查询匹配的文档都会被检索出来,然后Post_Filter会对这些文档进行额外的过滤操作,以满足特定的条件。这种机制允许我们在不牺牲查询性能的前提下,对结果进行精细化的控制。
三、使用场景
Post_Filter后置过滤器适用于以下场景:
- 需要对查询结果进行二次过滤
在某些情况下,我们可能需要根据额外的条件对查询结果进行过滤。这些条件可能无法在查询阶段直接指定,或者它们的计算成本较高,不适合在查询阶段执行。这时,我们可以使用Post_Filter对这些条件进行过滤。
- 需要对聚合结果进行过滤
在Elasticsearch中,聚合操作允许我们对数据进行统计和分析。然而,在某些情况下,我们可能需要对聚合结果进行过滤,以排除不满足特定条件的聚合项。Post_Filter可以在聚合完成后对结果进行过滤,实现这一需求。
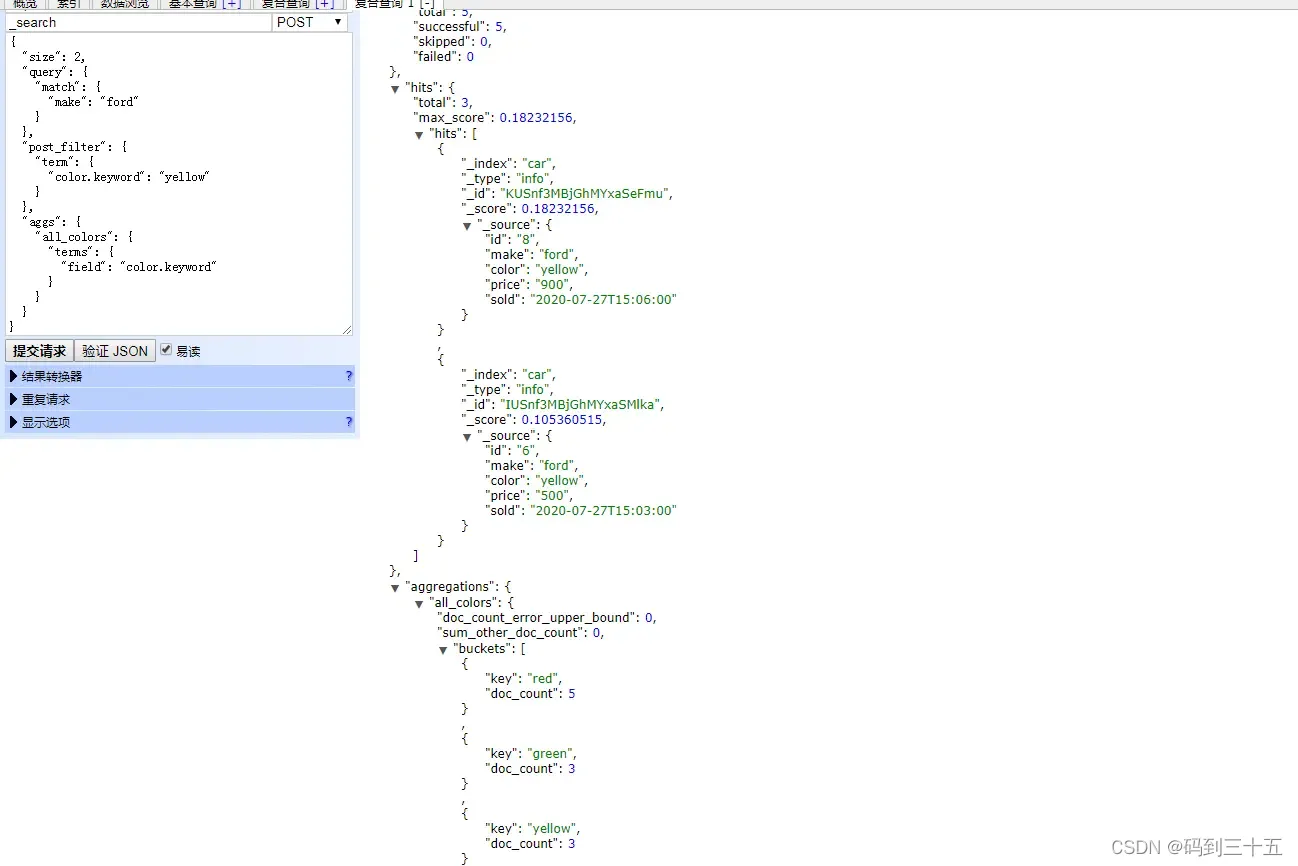
- 需要对高亮结果进行过滤
在全文搜索中,高亮功能允许我们将匹配的关键词以特殊的方式显示出来,以便用户快速定位到相关信息。然而,在某些情况下,我们可能需要对高亮结果进行过滤,以排除不满足特定条件的高亮项。Post_Filter可以在高亮操作完成后对结果进行过滤,实现这一需求。
四、DSL使用
1. 使用DSL构建包含Post_Filter的查询
GET /products/_search { "query": { "bool": { "must": [ { "match": { "description": "smartphone" } } ], "filter": [ { "range": { "price": { "gte": 100, "lte": 500 } } } ] } }, "post_filter": { "term": { "brand.keyword": "Apple" } }, "highlight": { "fields": { "description": {} } } } 首先使用bool查询来匹配描述中包含"smartphone"的商品,并使用range过滤器来限制价格范围在100到500之间。然后,我们使用Post_Filter来进一步过滤结果,只保留品牌为"Apple"的商品。最后,我们使用高亮功能来突出显示匹配的描述字段。
注意,虽然Post_Filter是在查询执行完成后对结果进行过滤的,但它仍然可以对查询的性能产生影响。如果Post_Filter的条件非常严格,导致只有很少的文档满足条件,那么查询的总体性能可能会受到一定的影响。因此,在使用Post_Filter时,我们需要权衡其带来的便利性和潜在的性能开销。
2. Elasticsearch的先聚合再后置过滤
假设有一个名为sales的索引,其中包含了销售数据。每个文档代表一个销售记录,包含product_id、sale_date和amount等字段。现在,我们想要找出某个时间段内的销售总额,并且只关注特定品牌的销售记录。
GET /sales/_search { "size": 0, "aggs": { "sales_over_time": { "date_histogram": { "field": "sale_date", "calendar_interval": "month", "format": "yyyy-MM" }, "aggs": { "total_sales": { "sum": { "field": "amount" } } } } }, "post_filter": { "term": { "brand.keyword": "Apple" } } } 在这个查询中:
- 我们使用date_histogram聚合来按月份对销售数据进行分组。
- 对于每个时间桶(month bucket),我们使用sum聚合来计算该时间段内的销售总额。
- 使用post_filter来过滤出品牌为"Apple"的销售记录。注意,这里的过滤是在聚合完成后对结果进行过滤的,这意味着所有的销售数据都会被聚合,但只有在品牌为"Apple"的销售记录上的聚合结果才会被返回。
- 将size设置为0,因为我们只对聚合结果感兴趣,而不需要返回具体的文档。
结果类似于以下结构:
{ "took": ..., "timed_out": false, "_shards": { ... }, "hits": { "total": { ... }, "max_score": null, "hits": [] // 注意这里不会有具体的文档,因为我们设置了size为0 }, "aggregations": { "sales_over_time": { "buckets": [ { "key_as_string": "2023-01", "key": 1672531200000, "doc_count": 100, // 这个数字是在过滤前的原始文档数(可能包含非Apple品牌的销售记录) "total_sales": { "value": 10000.0 // 这个数字是过滤后(即Apple品牌)在2023年1月的销售总额 } }, { "key_as_string": "2023-02", "key": 1675113600000, "doc_count": 120, // 同样,这个数字是在过滤前的原始文档数 "total_sales": { "value": 12500.0 // 过滤后在2023年2月的销售总额 } // ... 其他月份的数据 ] } } } } 注意:
- doc_count字段表示的是每个时间桶内的原始文档数(即在应用post_filter之前的数量)。这个数量可能包含非"Apple"品牌的销售记录。
- total_sales.value字段表示的是在每个时间桶内,经过post_filter过滤后(即只计算"Apple"品牌的销售记录)的销售总额。
五、优化策略
为了充分发挥Post_Filter后置过滤器的优势并避免潜在的性能问题,可以采取以下优化策略:
- 避免在Post_Filter中使用复杂的脚本或计算:复杂的脚本或计算可能会增加过滤的开销,从而影响查询的总体性能。我们应尽量使用简单的过滤条件来减少计算成本。
- 合理选择过滤条件:在选择过滤条件时,我们应充分考虑数据的分布和查询的需求。如果某个过滤条件可以提前在查询阶段指定,并且不会显著增加查询的复杂性,那么最好将其放在查询中而不是Post_Filter中。
- 监控和分析查询性能:使用Elasticsearch提供的监控和分析工具来定期检查查询的性能。如果发现Post_Filter对性能产生了显著影响,我们可以考虑调整过滤条件或查询结构来优化性能。
- 利用缓存机制:虽然Post_Filter本身不会缓存结果,但我们可以利用Elasticsearch的其他缓存机制来提高性能。例如,我们可以将经常使用的查询和过滤器缓存起来,以减少重复计算的开销。
六、结语
Post_Filter后置过滤器是Elasticsearch中一种强大的工具,它允许我们在查询执行完成后对结果进行额外的过滤操作。通过合理使用Post_Filter并结合优化策略,我们可以在不牺牲查询性能的前提下实现对结果的精细控制。然而,我们也需要注意避免在Post_Filter中使用复杂的脚本或计算,并合理选择过滤条件来平衡便利性和性能开销之间的关系。

