
阅读量:2
基于泰坦尼克号生还数据进行 Spark 分析
在这篇博客中,我们将展示如何使用 Apache Spark 分析著名的泰坦尼克号数据集。通过这篇教程,您将学习如何处理数据、分析乘客的生还情况,并生成有价值的统计信息。
数据解析
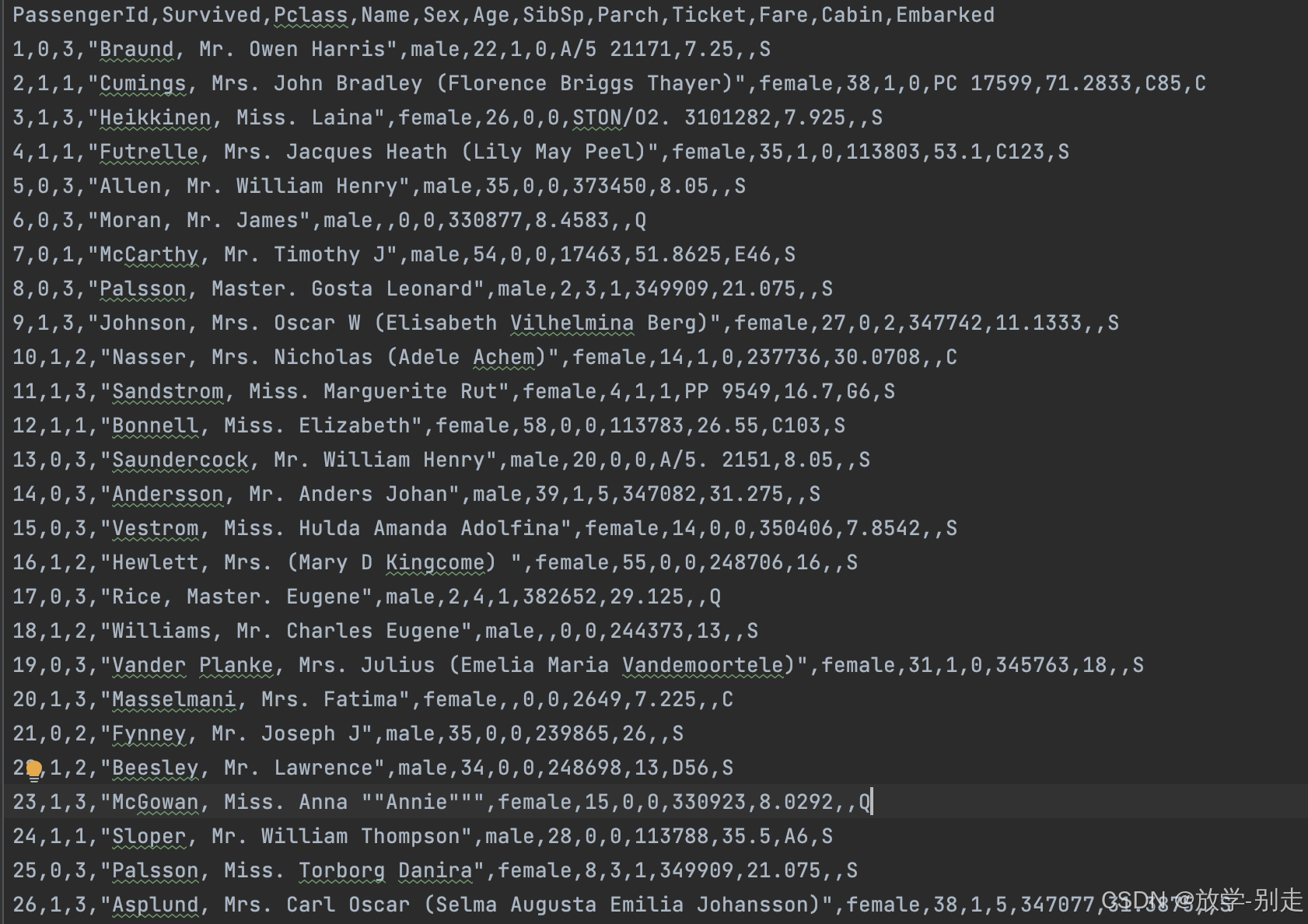
• PassengerId : 乘客编号。
• Survived : 是否存活,0表示未能存活,1表示存活。
• Pclass : 描述乘客所属的等级,总共分为三等,用1、2、3来描述:1表示高等;2表示中等;3表示低等。
• Name : 乘客姓名。
• Sex : 乘客性别。
• Age : 乘客年龄。
• SibSp : 与乘客同行的兄弟姐妹(Siblings)和配偶(Spouse)数目。
• Parch : 与乘客同行的家长(Parents)和孩子(Children)数目。
• Ticket : 乘客登船所使用的船票编号。
• Fare : 乘客上船的花费。
• Cabin : 乘客所住的船舱。
• Embarked : 乘客上船时的港口,C表示Cherbourg;Q表示Queenstown;S表示Southampton。
环境设置
首先,我们需要设置 Spark 环境并创建 SparkSession 对象。以下是代码片段:
val conf = new SparkConf().setMaster("local[*]").setAppName("practice1") val spark = SparkSession.builder() .config(conf) .getOrCreate() // 导入隐式转换相关依赖 import spark.implicits._ // 读取 CSV 文件生成 DataFrame 对象 val df = spark.read.format("csv") .option("header", "true") .option("mode", "DROPMALFORMED") .load("titanic.csv") 数据预处理
在分析之前,我们需要对数据进行预处理,包括数据类型转换和缺失值处理。
修改字段数据类型
我们将字段转换为适当的数据类型:
val md_df = df.withColumn("Pclass", df("Pclass").cast(IntegerType)) .withColumn("Survived", df("Survived").cast(IntegerType)) .withColumn("Age", df("Age").cast(DoubleType)) .withColumn("SibSp", df("SibSp").cast(IntegerType)) .withColumn("Parch", df("Parch").cast(IntegerType)) .withColumn("Fare", df("Fare").cast(DoubleType)) 删除不必要的字段
删除不需要的字段,以简化数据集:
val df1 = md_df.drop("PassengerId").drop("Name").drop("Ticket").drop("Cabin") 处理缺失值
统计缺失值,并填充缺失数据:
val columns: Array[String] = df1.columns val missing_cnt: Array[Long] = columns.map(field => df1.select(col(field)).where(col(field).isNull).count()) val tuples: Array[(Long, String)] = missing_cnt.zip(columns) val result_df: DataFrame = spark.sparkContext.parallelize(tuples).toDF("missing_cnt", "column_name") result_df.show() 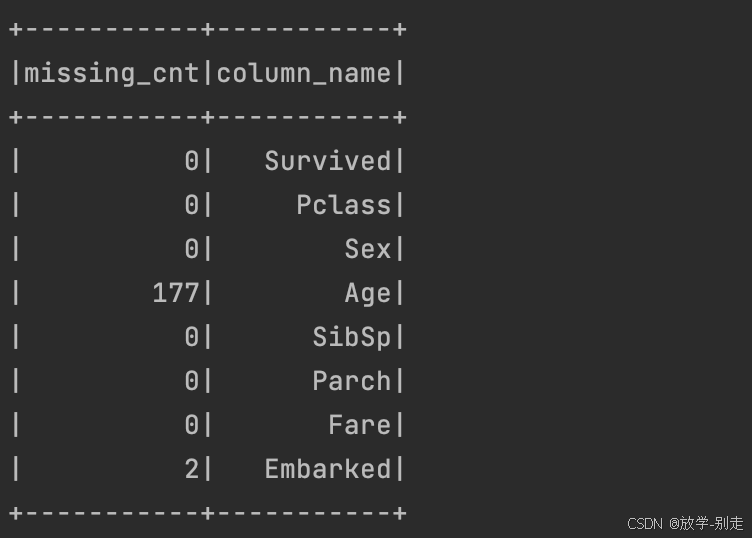
def meanAge(dataFrame: DataFrame): Double = { dataFrame.select("Age") .na.drop() .agg(round(mean("Age"), 0)) .first() .getDouble(0) } val df2 = df1.na.fill(Map("Age" -> meanAge(df1), "Embarked" -> "S")) df2.show() 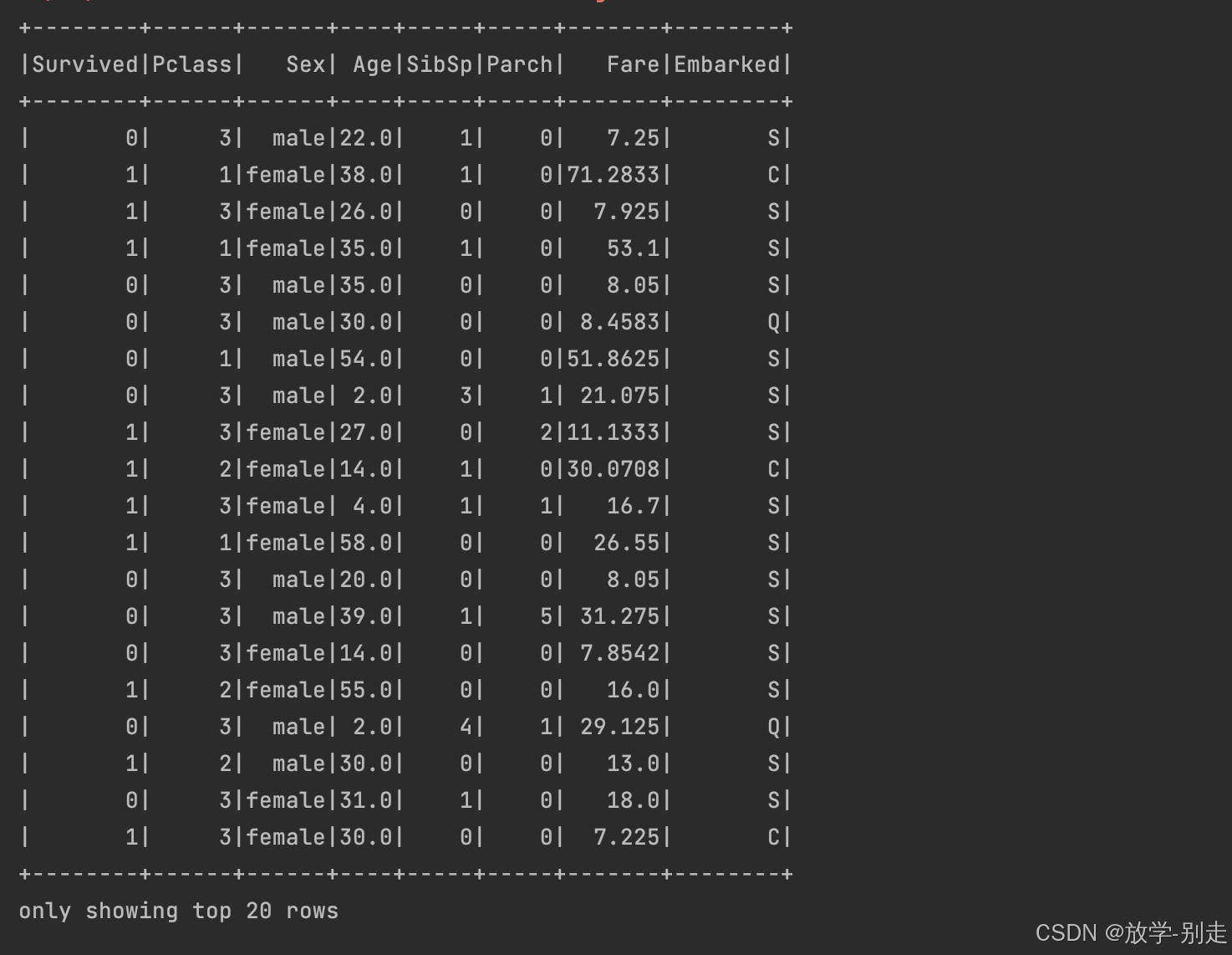
数据分析
1. 生还人数统计
统计生还人数,并保存结果:
val survived_count: DataFrame = df2.groupBy("Survived").count() survived_count.show() survived_count.coalesce(1).write.option("header", "true").csv("output/practice1/survived_count.csv") 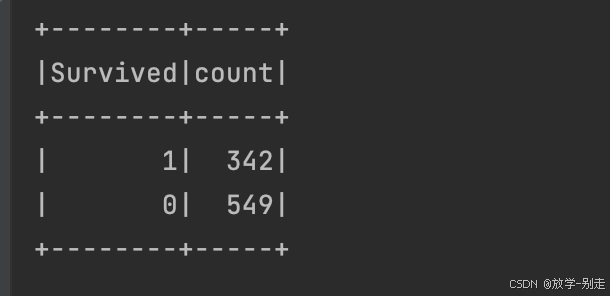
2. 不同上船港口生还情况
val survived_embark = df2.groupBy("Embarked", "Survived").count() survived_embark.show() survived_embark.coalesce(1).write.option("header", "true").csv("data/practice1survived_embark.csv") 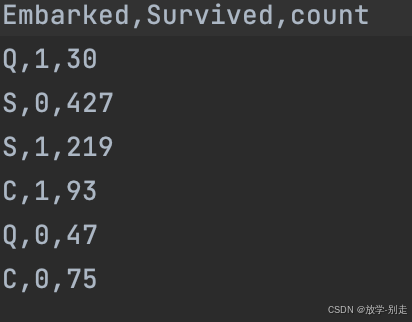
3. 存活/未存活的男女数量及比例
val survived_sex_count = df2.groupBy("Sex", "Survived").count() val survived_sex_percent = survived_sex_count.withColumn("percent", format_number(col("count").divide(functions.sum("count").over()).multiply(100), 5)) survived_sex_percent.show() survived_sex_percent.coalesce(1).write.option("header", "true").csv("data/practice1/survived_sex_percent.csv") 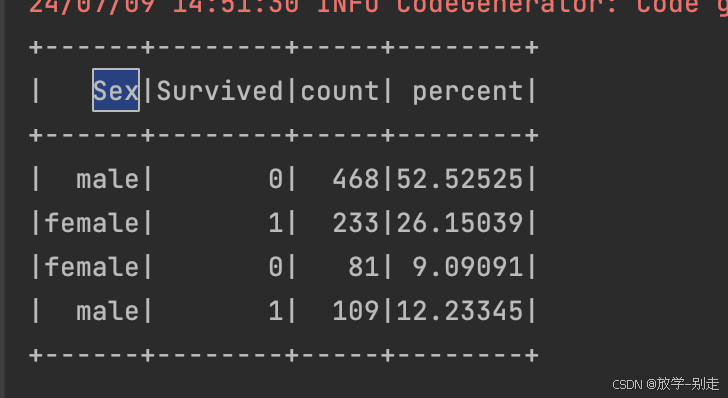
4. 不同级别乘客生还人数和占总生还人数的比例
val survived_df = df2.filter(col("Survived") === 1) val pclass_survived_count = survived_df.groupBy("Pclass").count() val pclass_survived_percent = pclass_survived_count.withColumn("percent", format_number(col("count").divide(functions.sum("count").over()).multiply(100), 5)) pclass_survived_percent.show() pclass_survived_percent.coalesce(1).write.option("header", "true").csv("data/practice1/pclass_survived_percent.csv") 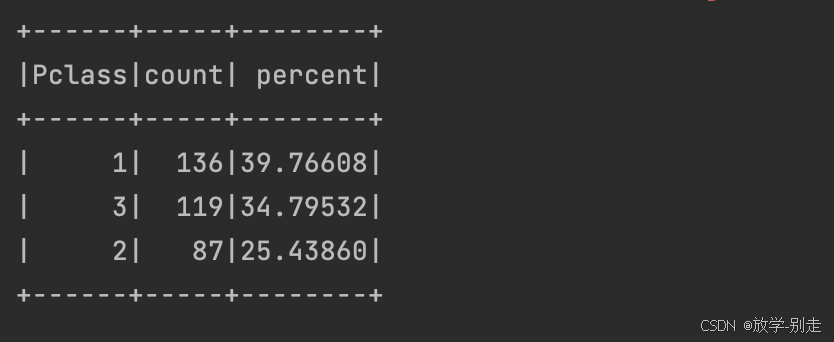
5. 有无同行父母/孩子的生还情况
val df4 = df2.withColumn("Parch_label", when(df2("Parch") > 0, 1).otherwise(0)) val parch_survived_count = df4.groupBy("Parch_label", "Survived").count() parch_survived_count.show() parch_survived_count.coalesce(1).write.option("header", "true").csv("data/practice1/parch_survived_count.csv") 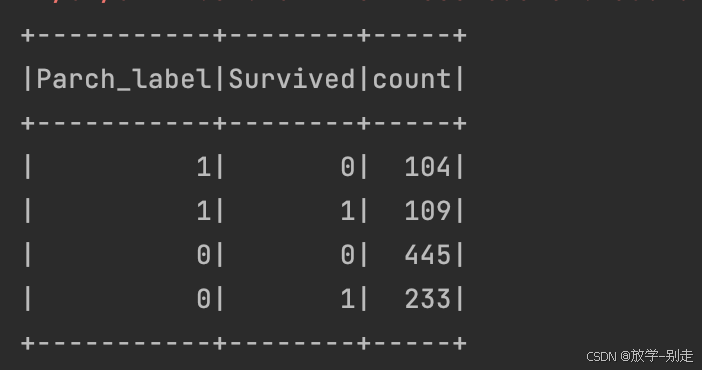
6. 按照年龄分类的生还情况
val df3 = survived_df.withColumn("Age_label", when(df2("Age") <= 18, "minor").when(df2("Age") > 18 && df2("Age") <= 35, "young").when(df2("Age") > 35 && df2("Age") <= 55, "middle").otherwise("older")) val age_survived = df3.groupBy("Age_label", "Survived").count() age_survived.show() age_survived.coalesce(1).write.option("header", "true").csv("data/practice1/age_survived.csv") 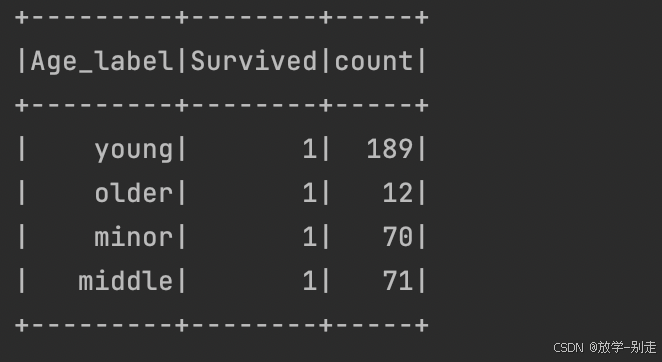
7. 提取乘客等级和上船费用信息
val sef = Seq("Pclass", "Fare") val df5 = df2.select(sef.head, sef.tail: _*) df5.show(5) df5.coalesce(1).write.option("header", "true").csv("data/practice1/pclass_fare.csv") 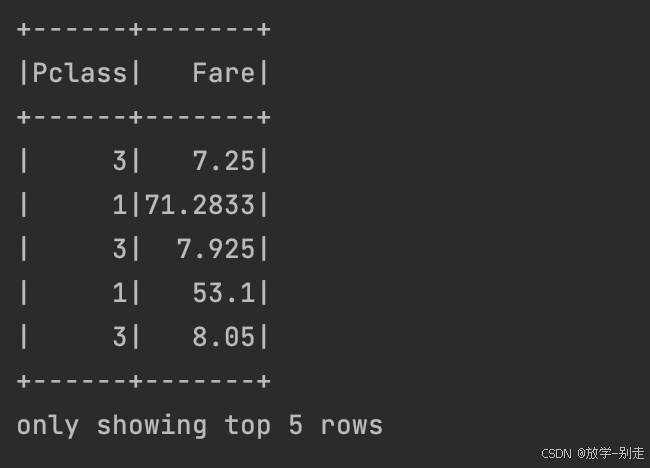
总结
通过上述步骤,我们使用 Spark 对泰坦尼克号数据进行了全面的分析,从数据预处理到统计分析。希望这篇博客能帮助您更好地理解如何使用 Spark 进行数据处理和分析。
如有遇到问题可以找小编沟通交流哦。另外小编帮忙辅导大课作业,学生毕设等。不限于MapReduce, MySQL, python,java,大数据,模型训练等。 hadoop hdfs yarn spark Django flask flink kafka flume datax sqoop seatunnel echart可视化 机器学习等
