
阅读量:0
1.范围分区
比如:根据时间进行分区
注意:分区语句中只能使用less,不能使用more,也不能使用less than (xxx) and more than (xxx)
1.1.创建分区
创建分区
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by range (save_date)
(
partition worker202301 values less than (to_date(‘20230201’,‘YYYYMMDD’)),
partition worker202302 values less than (to_date(‘20230301’,‘YYYYMMDD’)),
partition worker202303 values less than (maxvalue)
);
–添加数据
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘ddd’,‘c++’,to_date(‘20221231’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘aaa’,‘java’,to_date(‘20230128’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘bbb’,‘c++’,to_date(‘20230228’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘ccc’,‘c++’,to_date(‘20230328’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘ddd’,‘c++’,to_date(‘20230428’,‘YYYYMMDD’));
1.2.查询分区数据
查询当前表有哪些分区
select * from user_tab_partitions where table_name = ‘WORKER_202301’;
–查询指定分区的数据
select * from worker_202301 partition (worker202301);
select * from worker_202301 partition (worker202302);
select * from worker_202301 partition (worker202303);
1.3.添加分区
添加分区
alter table worker_202301 add partition worker202305 values less than (to_date(‘20230501’,‘YYYYMMDD’));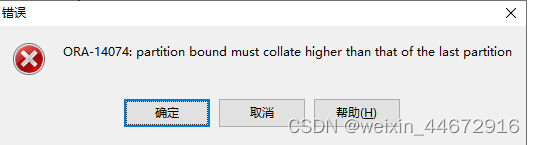
直接添加分区会报错,因为添加的分区要比最大的分区要比最大的分区范围要大。
1.3.1.解决方案(会删除数据)
:
删除最大的分区之后,再添加分区
–删除分区
alter table worker_202301 drop partition worker202303;
–添加分区
alter table worker_202301 add partition worker202305 values less than (to_date(‘20230401’,‘YYYYMMDD’));
1.4.删除分区
删除分区会删除该分区下的数据
–删除分区
alter table worker_202301 drop partition worker202303;
2.列表分区
该分区方式适用于一个字段有多个固定的值,比如:产品、月份、类型等。
2.1.创建分区
创建分区
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by list (technology)
(
partition technology_java values (‘java’),
partition technology_python values (‘python’),
partition technology_c values (‘c’)
);
–添加数据
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘ddd’,‘java’,to_date(‘20221231’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘aaa’,‘java’,to_date(‘20230128’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘bbb’,‘c’,to_date(‘20230228’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘ccc’,‘python’,to_date(‘20230328’,‘YYYYMMDD’));
如果添加的数据中,分区字段的内容不在分区中,会报错
insert into worker_202301 (id,name,technology,save_date)
values (sys_guid(),‘ddd’,‘c++’,to_date(‘20230428’,‘YYYYMMDD’));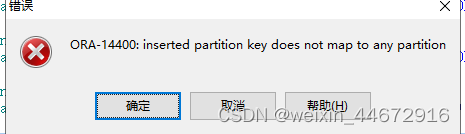
2.2.查询分区数据
查询当前表有哪些分区
select * from user_tab_partitions where table_name = ‘WORKER_202301’;
–查询指定分区的数据
select * from worker_202301;
select * from worker_202301 partition (technology_java);
select * from worker_202301 partition (technology_python);
select * from worker_202301 partition (technology_c);
2.3.删除分区
删除分区会删除该分区下的数据
alter table worker_202301 drop partition technology_c;
2.4.添加分区
alter table worker_202301 add partition technology_c values (‘c’);
2.5.当数据量不大时,可以合并进行分区
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by list (technology)
(
partition technology_java values (‘java’,’c’),
partition technology_python values (‘python’)
);
3.hash分区
范围分区和列分区都是根据某个字段进行分区,会存在分布不均匀的情况;Hash分区相比较前两种分区会更加均匀。
注意事项:分区的键最好是连续的;
分区的键最好是2的n次方,对hash运算更加友好;
Hash分区是不能删除的。
3.1. 创建分区
创建分区
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by hash (id)
(
partition worker_id_1,
partition worker_id_2,
partition worker_id_3,
partition worker_id_4
);
–添加数据
insert into worker_202301 (id,name,technology,save_date)
values (‘101’,‘ddd’,‘c++’,to_date(‘20221231’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘102’,‘aaa’,‘java’,to_date(‘20230128’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘103’,‘bbb’,‘c++’,to_date(‘20230228’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘104’,‘ccc’,‘c++’,to_date(‘20230328’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘105’,‘ddd’,‘c++’,to_date(‘20230428’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘106’,‘ddd’,‘c++’,to_date(‘20230428’,‘YYYYMMDD’));
3.2.查询分区数据
select * from worker_202301;
select * from worker_202301 partition (worker_id_1);
select * from worker_202301 partition (worker_id_2);
select * from worker_202301 partition (worker_id_3);
select * from worker_202301 partition (worker_id_4);
3.3.删除分区–hash分区不能删除
alter table worker_202301 drop partition worker_id_4;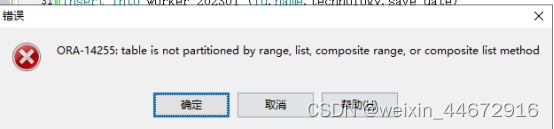
3.4.添加分区
在添加分区时,所有数据都会重新计算hash值进行分配。
alter table worker_202301 add partition worker_id_5;
4.范围分区+列表分区的组合分区
4.1.创建分区
创建分区
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by range (save_date) subpartition by list (technology)
(
partition worker1 values less than (to_date(‘20230201’,‘YYYYMMDD’))
(
subpartition technology_java_1 values (‘java’),
subpartition technology_c_1 values (‘c’),
subpartition technology_python_1 values (‘python’)
),
partition worker2 values less than (to_date(‘20230301’,‘YYYYMMDD’))
(
subpartition technology_java_2 values (‘java’),
subpartition technology_c_2 values (‘c’),
subpartition technology_python_2 values (‘python’)
)
);
–添加数据
insert into worker_202301 (id,name,technology,save_date)
values (‘101’,‘ddd’,‘c’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘102’,‘aaa’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘103’,‘bbb’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘104’,‘ccc’,‘python’,to_date(‘20230225’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘105’,‘ddd’,‘java’,to_date(‘20230225’,‘YYYYMMDD’));
4.2.查询分区数据
查询全部数据
select * from worker_202301;
–查询分区数据
select * from worker_202301 partition (worker1);
select * from worker_202301 partition (worker2);
–查询子分区数据
select * from worker_202301 subpartition (technology_java_1);
select * from worker_202301 subpartition (technology_c_1);
select * from worker_202301 subpartition (technology_python_1);
select * from worker_202301 subpartition (technology_java_2);
select * from worker_202301 subpartition (technology_c_2);
select * from worker_202301 subpartition (technology_python_2);
4.3.删除分区
删除主分区,会删除该分区下所有的数据;删除子分区只会删除子分区下的数据
–删除分区
alter table worker_202301 drop partition worker3;
–删除子分区
alter table worker_202301 drop subpartition technology_python_3;
4.4.添加分区
在添加主分区时最好新增一个子分区,如果不新增子分区,oracle会自动生成一个默认的子分区;如果在给这个主分区添加子分区时会报错,也无法删除这个默认的子分区。
–添加主分区
alter table worker_202301 add partition worker3 values less than (to_date(‘20230401’,‘YYYYMMDD’))
(
subpartition technology_java_3 values (‘java’),
subpartition technology_c_3 values (‘c’)
);
–添加子分区
alter table worker_202301 modify partition worker3 add subpartition technology_python_3 values (‘python’);
5.范围分区+hash分区的组合分区
因为hash分区的存在,可能分区会使数据不均匀。
当hash分区作为主分区时,oracle中看不到子分区,但是能根据子分区进行查询。
5.1.创建分区
创建分区
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by range (save_date) subpartition by hash (id)
(
partition worker1 values less than (to_date(‘20230201’,‘YYYYMMDD’))
(
subpartition worker_id_1,
subpartition worker_id_2
),
partition worker2 values less than (to_date(‘20230301’,‘YYYYMMDD’))
(
subpartition worker_id_3,
subpartition worker_id_4
)
);
–添加数据
insert into worker_202301 (id,name,technology,save_date)
values (‘101’,‘ddd’,‘c’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘102’,‘aaa’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘103’,‘bbb’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘104’,‘ccc’,‘python’,to_date(‘20230225’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘105’,‘ddd’,‘java’,to_date(‘20230225’,‘YYYYMMDD’));
5.2.查询分区数据
查询全部数据
select * from worker_202301;
–查询分区数据
select * from worker_202301 partition (worker1);
select * from worker_202301 partition (worker2);
–查询子分区数据
select * from worker_202301 subpartition (worker_id_1);
select * from worker_202301 subpartition (worker_id_2);
select * from worker_202301 subpartition (worker_id_3);
select * from worker_202301 subpartition (worker_id_4);
5.3.删除分区
删除主分区,会删除该分区下所有的数据;删除子分区只会删除子分区下的数据
1.当hash分区为子分区时,不能删除子分区;可以删除主分区
–删除分区
alter table worker_202301 drop partition worker3;
–删除子分区
alter table worker_202301 drop subpartition worker_id_7;
删除子分区报错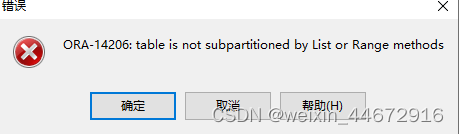
2.当hash分区为主分区时,不能删除主分区;可以删除子分区
5.4.添加分区
添加主分区
alter table worker_202301 add partition worker3 values less than (to_date(‘20230401’,‘YYYYMMDD’))
(
subpartition worker_id_5,
subpartition worker_id_6
);
–添加子分区
alter table worker_202301 modify partition worker3 add subpartition worker_id_7;
6.列表分区+hash分区
因为hash分区的存在,可能会使数据分布不均匀。
6.1.创建分区
创建分区
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by list (technology) subpartition by hash (id)
(
partition technology_java values (‘java’)
(
subpartition worker_id_1,
subpartition worker_id_2
),
partition technology_python values (‘python’)
(
subpartition worker_id_3,
subpartition worker_id_4
)
);
–添加数据
insert into worker_202301 (id,name,technology,save_date)
values (‘101’,‘ddd’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘102’,‘aaa’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘103’,‘bbb’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘104’,‘ccc’,‘python’,to_date(‘20230225’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘105’,‘ddd’,‘java’,to_date(‘20230225’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘106’,‘eee’,‘java’,to_date(‘20230325’,‘YYYYMMDD’));
6.2.查询分区数据
查询全部数据
select * from worker_202301;
–查询分区数据
select * from worker_202301 partition (technology_java);
select * from worker_202301 partition (technology_python);
–查询子分区数据
select * from worker_202301 subpartition (worker_id_1);
select * from worker_202301 subpartition (worker_id_2);
select * from worker_202301 subpartition (worker_id_3);
select * from worker_202301 subpartition (worker_id_4);
6.3.删除分区
删除主分区,会删除该分区下所有的数据;删除子分区只会删除子分区下的数据
1.当列表分区是主分区时,可以删除主分区
–删除分区
alter table worker_202301 drop partition technology_c;
2.当hash分区是子分区时,删除子分区会报错
–删除子分区
alter table worker_202301 drop subpartition worker_id_6;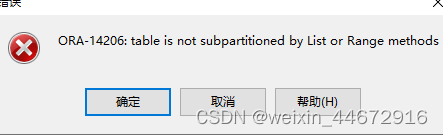
3.当列表分区是子分区,hash分区是主分区时;可以删除子分区,不能删除主分区。
6.4.添加分区
添加主分区
alter table worker_202301 add partition technology_c values (‘c’)
(
subpartition worker_id_5
);
–添加子分区
alter table worker_202301 modify partition technology_c add subpartition worker_id_6;
7.对已有表进行分区
在对已有表进行分区时,由于未分区表不能直接转换为分区表;所以需要重建一个相同表结构且有分区的表将原表数据转移到分区表中,然后再将原表删除,将分区表表名修改为原表的表名。
注意:分区表最好是分区好之后再进行数据的转移。
7.1.创建一张没有分区的表并添加数据
创建一张普通表插入数据
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
);
–添加数据
insert into worker_202301 (id,name,technology,save_date)
values (‘101’,‘ddd’,‘c’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘102’,‘aaa’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘103’,‘bbb’,‘java’,to_date(‘20230125’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘104’,‘ccc’,‘python’,to_date(‘20230225’,‘YYYYMMDD’));
insert into worker_202301 (id,name,technology,save_date)
values (‘105’,‘ddd’,‘java’,to_date(‘20230225’,‘YYYYMMDD’));
7.2.创建一张相同表结构的表,并添加分区
创建一张相同表结构的分区表
create table worker_202301tmp(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by range (save_date)
(
partition worker01 values less than (to_date(‘20230201’,‘YYYYMMDD’)),
partition worker02 values less than (to_date(‘20230301’,‘YYYYMMDD’))
);
7.3.将没有分区的表数据插入到有分区的表中
将没有分区的表中数据插入到有分区的表中
insert into worker_202301tmp (select * from worker_202301);
7.4.检查分区表中的分区是否生效
检查分区是否生效
select * from worker_202301tmp;
–查询当前表的分区
select * from user_tab_partitions where table_name = ‘WORKER_202301TMP’;
–根据分区查询数据
select * from worker_202301tmp partition (worker01);
select * from worker_202301tmp partition (worker02);
7.5.删除普通表,修改分区表名
删除原表,将分区表表名进行修改
drop table worker_202301;
rename worker_202301tmp to worker_202301;
7.6.将一个分区拆分成多个分区
7.6.1.错误示范
截断分区的at关键子不能写字段的名称。
alter table worker_202301 split partition worker01 at (id) into (partition worker02,partition worker03);
7.6.2.正确示范
1.范围分区,一个分区拆分成多个分区示例
alter table worker_202301 split partition worker01 at (to_date(‘20230101’,‘YYYYMMDD’)) into (partition worker03,partition worker04);
2.列表分区,一个分区拆分成多个分区示例
alter table worker_202301 split partition technology_java into (partition technology_c values (‘c’),partition technology_java);
或
alter table worker_202301 split partition technology_java into (partition technology_java values (‘java’),partition technology_c);
3.hash分区,一个分区拆分成多个分区的示例
一个hash分区不能被再次拆分
7.7.截断分区
截断分区是指删除某个分区的中的数据,不会删除分区。也不会删除其他分区。
alter table worker_202301 truncate partition worker03;
7.8.合并分区
合并分区是将多个分区的数据合并到一起,其他分区的数据会被删除。
–将worker02和worker03分区中的数据合并到worker03分区中,同时删除worker02分区
alter table worker_202301 merge partitions worker02,worker03 into partition worker03;
注意事项:
7.8.1.范围分区
1.大范围的分区要写在后面,小范围的分区要放在前面(worker02放在前,worker03放在后)。下图就是一个错误的示范,应该写成
alter table worker_202301 merge partitions worker02,worker03 into partition worker02;

2.合并分区时,应将多个分区合并到范围最大的分区中
错误示范:
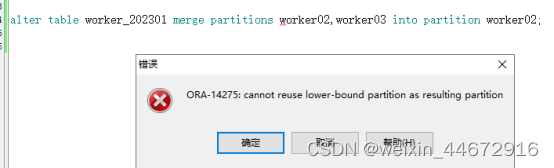
应该将worker02,worker03合并到worker03中,因为worker02和worker03中worker03分区的范围最大。
7.8.2.列表分区
1.列表分区没有范围大小的限制,会将多个分区合并到一个分区中;如下图,此时不能再添加单独的java或者c的分区
alter table worker_202301 merge partitions technology_java ,technology_c into partition technology_java;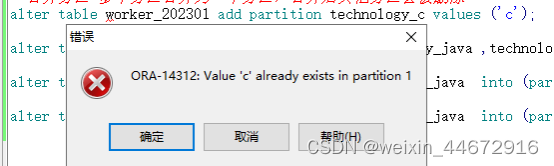
7.8.3.不能合并子分区
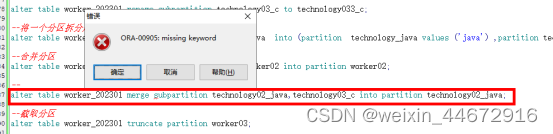
8.根据日期自动分区
注意:分区字段类型必须为date类型,使用自动分区时分区的名字是自动生成的。
create table worker_202301(
id varchar2(32) not null,
name varchar2(200),
technology varchar2(100),
save_date date
)
partition by list (save_date) interval (numtoyminterval(1,‘month’))(
partition worker_20230903 values less than (to_date(‘20231001’,‘YYYYMMDD’))
);
interval (numtoyminterval(1,‘year’))–按年分区
interval (numtoyminterval(1,‘month’))–按月分区
interval (numtoyminterval(1,‘day’))–按天分区
9.更改已有分区的名称
修改主分区名称
alter table worker_202301 rename partition worker03 to technology_go;
修改子分区名称
alter table worker_202301 rename subpartition technology03_c to technology033_c;
