
阅读量:0
0202 分段hash表
专栏内容:
文章目录
一、概述
上节介绍了hashTable的原理与实现,在数据库中,往往是高并发,高性能的要求,对于hashTable的操作,必须加读写锁来保护一致性。
当一个任务要插入一条key-value数据时,其它并发都需要等待,吞吐量明显不足。
本节就来分享一种分段式的hashTable,当hashKey 在不同分段时,可以进行并发的插入和删除操作,这对于高并发来讲,性能就会成倍的提升。
二、分段hash并发操作原理
在并发操作中,会对共享数据加锁保护,了为提升读取数据的并发性能,一般会在读操作时加读锁,写操作时加写锁。
其中:
- 读读不冲突,可以同时多个任务进行读操作;
- 读写冲突,读时写的任务在等待,写时读的任务会等待;
- 写写冲突,同一把锁上,只能有一个写的任务运行,其它都会等待;
上面锁的冲突规则是对于一把锁来讲,当有多把锁时,各锁之间是相互不干涉的,也就是有几把锁,就可以同时运行几个写任务。
这就是分段hash的理论基础,每个分段会对应的独立的一把段级别的锁,只负责保护此分段的hashtable操作,这样几个分段就可以同进行分段操作了。
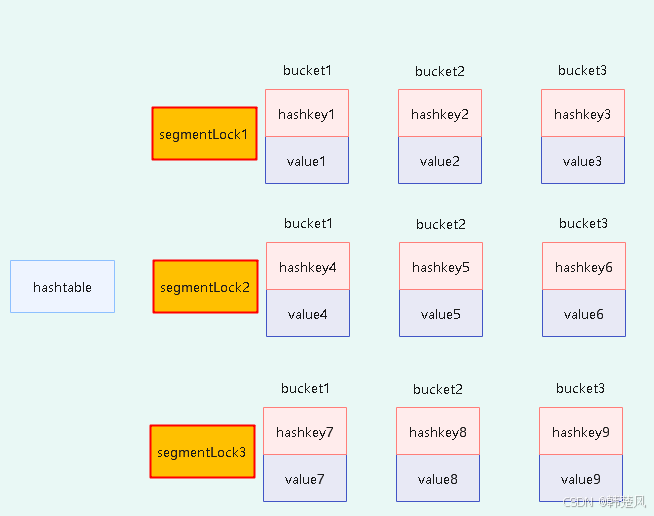
- 分段的hashtable中有多个segment;
- 每个segment相当于一个独立的hashtable;
- 每个segment中有一把并发控制的锁segmentLock;
- 在segment内部用锁进行同步处理。
三、分段算法原理
对于分段的hashtable来讲,分段就非常关键,既要简单高效,又需要算法稳定,同时还要尽可能的分散,看起来要求挺高的,下面我们来看如何设计分段算法。
在hashTable中,散列的主要依据是hashKey,是否继续在hashKey上做文章呢?
答案是肯定的,将hashKey的高bit位定义位segment的序号,低bit位定义位段内的bucket序号;
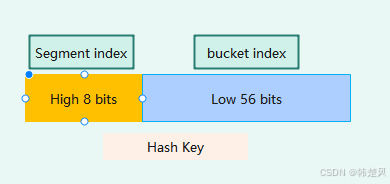
如图所示,对于64bits的hashKey, 可以将高字节定义位segment 序号,低7字节定义为bucket序号;
这里的划分算法可以是固定位的,也可以是不固定位的。
3.1 固定位的分段算法
固定划分,也就是segment序号对应的bit数量是固定的,比如一个字节,8bits。
- 此时最大可以表示256个segment,也就是不能超过最大值。
- 当配置的segment小于256时,可以采用 取余的算法,将一个节字的数字散列到此区间内;
固定划分,算法相对简单,当划分的segment不能一一对应时,需要一次映射计算。
3.1 不固定位的分段算法
当segment数量,可以更新数据量进行优化配置时,比如数据量为2GB时,配置16个segment,而数据量为2TB时,有更多的数据会产生冲突,进一步通过增加segment进行分散,可以配置segment为256。
同时又期望划分后的bits可以直接是segment的下标,那么就要计算不同划分下,需要占用多个少bit。
算法描述如下:
- segment数量必须是2的幂次,如果配置的不是2的幂次时,取大于此值的2的幂次数;这样保证与bit数量一一对应。
- 计算2的幂次数,也就是 2n ,
n的具体值;比如配置为1024个segment,那么它就是210; - 幂次数
n就是segment序号的bit数量,从最高到低位取;
下面来看代码的具体实现。
向上取2的幂次数
对于32位HashKey的算法如下:
HASHKEY getAlignNum(unsigned int num) { HASHKEY mask = num - 1; mask |= mask >> 1; mask |= mask >> 2; mask |= mask >> 4; mask |= mask >> 8; mask |= mask >> 16; return mask+1; } 这是一个很巧妙的算法,通过将该数字二进制中的最高位的1,填充到所有低位的,再加1就变成了最大的2的幂次数。
比如输入时9 对应的二进制是 1001,那么计算步骤为:
- 减1; -> 1000
- mask |= mask >> 1; -> 1100
- mask |= mask >> 2; -> 1111
- 后面步骤没有变化;
- mask + 1 -> 10000
最后得到的是16;
整个操作的位置是hashKey的一半,比如hashKey是32位时,只需要16位的移动,如果hashKey为64bits时,需要最高32位的移动;
计算bit位数
统计key中的最高位1的位置序号。
int getShiftNum(HASHKEY key) { int shift = 0; while(key = key >> 1) { shift ++; } return shift; } 获取segment序号
先要计算segment序号对应的掩码。
#define HASH_BITS (sizeof(HASHKEY)*8) HASHKEY partitionMask = getAlignNum(partNum); HASHKEY partitionShift = HASH_BITS - getShiftNum(partitionMask) partitionMask = ~(((HASHKEY)1 << partitionShift) - 1); - 先对输入的partNum向上取2的幂次数;
- 然后计算对应的二进制位数 partitionShift ;
- 计算segment对应bit为1的掩码,比如当segment占8bits时,掩码的十六进制为
0xF000000000000000
根据掩码可以从HashKey中获取到segment序号。
int GetPartitionIndex(HASHKEY key) { int partition = key & partitionMask >> partitionShift; return partition; } 通过掩码与之后,得到高位为有效数字,低位为0的值,再向右移位得到正常值。
四、hash表操作
分段hash表的操作,与普通hash表操作会多出来获取segment序号,以及对segment加锁的步骤,具体对hash buckets的操作是一样的。
hash bucket序号获取
与segment序号获取一样,先通过掩码与,再根据bucket数量进行散列。
int GetBucketIndex(HASHKEY key, PHashTableInfo hashTableInfo) { int bucket = key & (~partitionMask) % hashBucketSize; return bucket; } - 没有单独记录bucket的掩码,将segment的掩码取反就可以得到;
- hashBucketSize是每个segment中buckets数组的大小,取余后得到bucket的序号;
分段hash的定义
每个segment可以定义位一个结构体,固定数量时,可以直接定义为静态数组;如果数量可变,可以动态申请空间。
hash段数据结构定义
#define HASH_SEGMENT_SIZE (32) typedef struct HashSegment { // SPINLOCK segLock; HashElement segBuckets[HASH_SEGMENT_SIZE]; }HashSegment; 这里的锁可以根据自己需要的类型进行定义,这里暂时注释代替,后面并发分享时再分析。
分段hash表定义
将上面的分散的参数,都可以加到hashTableInfo的数据结构中来。
#define HASH_SEGMENT_NUM (32) typedef struct HashTableInfo { int partitionNum; HASHKEY partitionMask; int partitionShift; int bucketShift; int hashSegmentSize; HashSegment segmentArray[HASH_SEGMENT_NUM]; }HashTableInfo; 这里段的数量采用HASH_SEGMENT_NUM来定义,固定大小,每次修改需要重新编译。
hash 查找
相比简单hash表,分段hash表增加了分段的查找与加锁步骤,hash查找的步骤如下:
- 调用hash计算函数,计算hashKey;
- 获取分段序号;
- 加锁对应的分段;
- 获取bucket序号;
- 从对应的bucket链中查找;
- 如果找到返回;否则返回NULL;
其它插入和删除操作,也是多了2,3步骤,其余相同。
五、总结
本文分享了分段hash表的实现与原理,在高并发场景下,为了hash操作的一致性,又同时提升hash表的吞吐量,采用分段hash,在没有hash段冲突时,可以同时进行N个并发操作,N即为段的数量。
对于分段的原量,分享了段数量可变的分段方法,通过计算段数量的2的幂,来动态确定占用的二进制位的数量,生成对应的段掩码。
结尾
非常感谢大家的支持,在浏览的同时别忘了留下您宝贵的评论,如果觉得值得鼓励,请点赞,收藏,我会更加努力!
作者邮箱:study@senllang.onaliyun.com
如有错误或者疏漏欢迎指出,互相学习。
注:未经同意,不得转载!
