
阅读量:4
JVM
运行时数据区
线程共享:方法区、堆
线程独享(与个体“同生共死”):虚拟机栈、本地方法栈、程序计数器
程序计数器
作用:记录下次要执行的代码行的行号
特点:为一个没有OOM(内存溢出)的地方
虚拟机栈
每要执行一个方法就往栈中放一个栈帧,包含把变量放到局部变量表中(局部变量槽),方法的出入口;
基本类型直接存值,应用类型存指针;
本地方法栈
本地方法:非java写的方法
作用与虚拟机栈相似,只不过是对于本地方法而言
有的会将虚拟机栈和本地方法栈合二为一
Java堆
存放对象实例
内存分配Thread Local Allocation Buffer(TLAB)先给一部分内存,用完再取,再取的过程中出现冲突采用CAS和失败重试
物理上不连续的,逻辑连续
方法区
存放:类信息
也是会出现OOM的地方
运行时常量池
方法区的一部分,
用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。除了保存Class文件中描述的符号引用外,还会把由符号引用翻译出来的直接引用也存储在运行时常量池中。
也会抛出OOM
直接内存
不属于运行时数据区的一部分
受物理内存限制,不受JVM限制
对象的内存布局
对象的创建
分配内存:
1.指针碰撞(内存规整,冲突解决方式是加锁)(index+n)
2.空闲列表(内存不规整)列表将可用的内存记录,然后根据列表分配
在分配内存时,为保证线程安全可以使用
1.本地线程分配缓存(TLAB)
2.CAS+失败重试
初始化0值(不包括对象头)
进行必要设置
对对象头进行设置
执行init方法
对象的结构
对象头
两类信息:
于存储对象自身的运行时数据,如哈 希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等
对象头的另外一部分是类型指针,即对象是属于哪一个类的
实例数据
对象真正有效的信息
对齐填充
无特别含义,仅仅起着占位符的作用
对象的访问定位
(就是 A a = new A()中a存了个什么东西)
句柄指针和直接指针
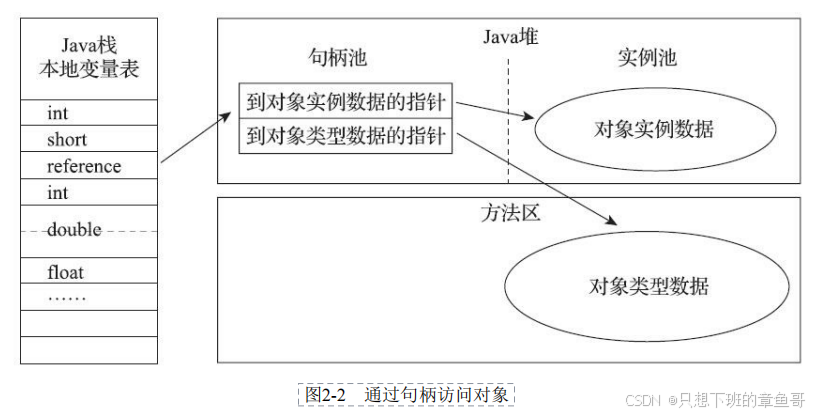
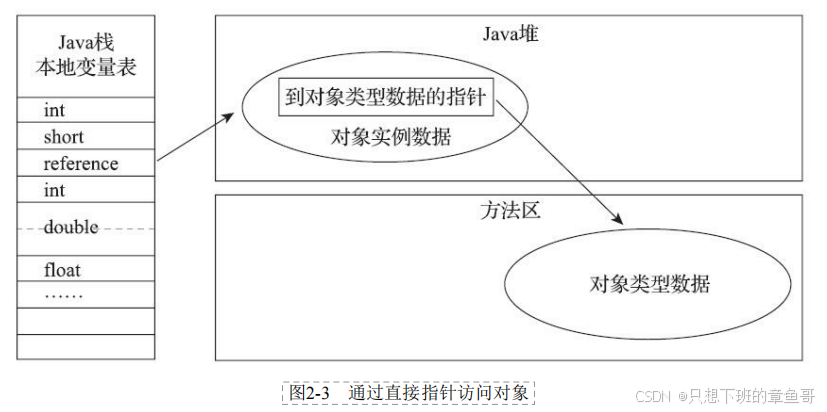
HotSpot采用直接指针
句柄指针两次定位,在对象移动时只需要修改句柄池中,也就是只需修改一次,
直接指针减少了一次定位,在对象移动时需要修改所有指向他的指针
垃圾收集器与内存分配策略
先谈生死
引用计数法
有一个指针指向该对象则+1,当有一个指针不指向他了则-1
缺点:无法解决成环问题
可达性分析法(java采用)
与GC Roots不可达则回收
可作为GC Roots对象的有
·在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的
参数、局部变量、临时变量等。
·在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
·在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。·在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
·Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如
NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
·所有被同步锁(synchronized关键字)持有的对象。
·反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
再谈引用
强、软、弱、虚引用
回收方法区(不太重要,了解即可)
垃圾收集算法
分代收集理论
弱分代
强分代
跨代引用
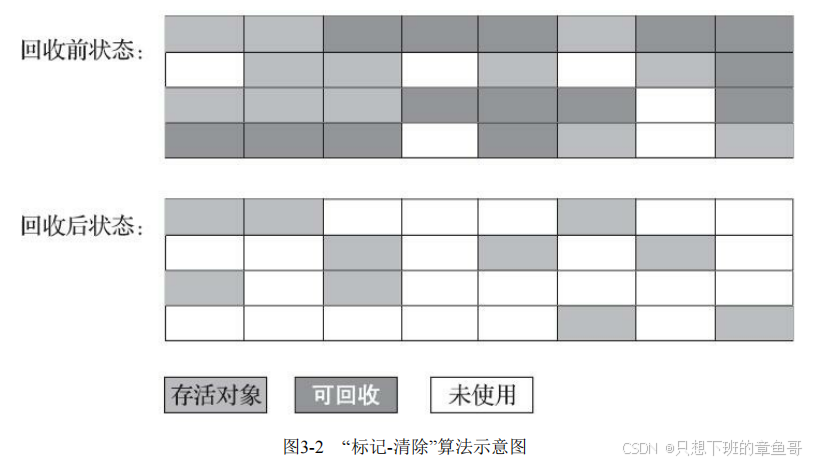
标记清除算法
缺点:
一个是执行效率不稳定
第二个是内存空间的碎片化问题
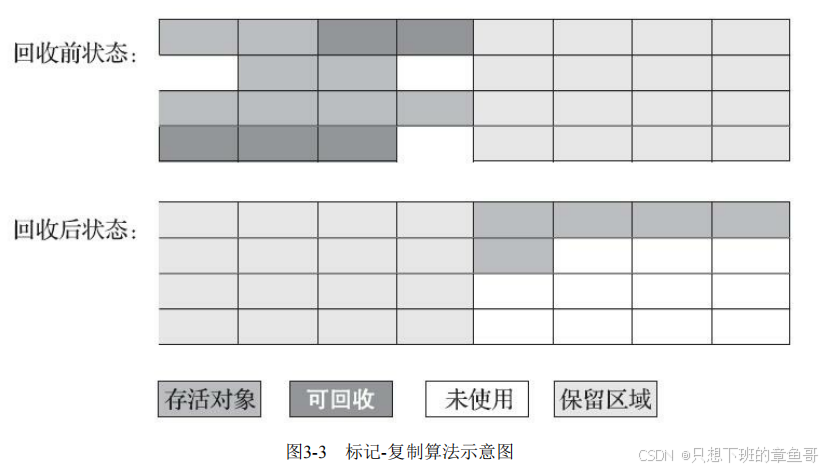
标记复制算法
只用一半,每次清除的时候将“活下来”的直接复制到另一边
缺点:可用内存缩小为了原来的一半
优点:实现简单,运行高效
Appel式回收(改进后的算法):将空间分为一个大的Eden空间和两个小的Survivor空间。对象首先被分配到Eden空间和一个小的Survivor空间。当Eden空间满时,触发Minor GC,存活的对象被复制到另一个Survivor空间。如果Survivor空间不足以容纳存活对象,就会依赖老年代进行内存担保,这些对象便将通过分配担保机制直 接进入老年代。
标记整理算法
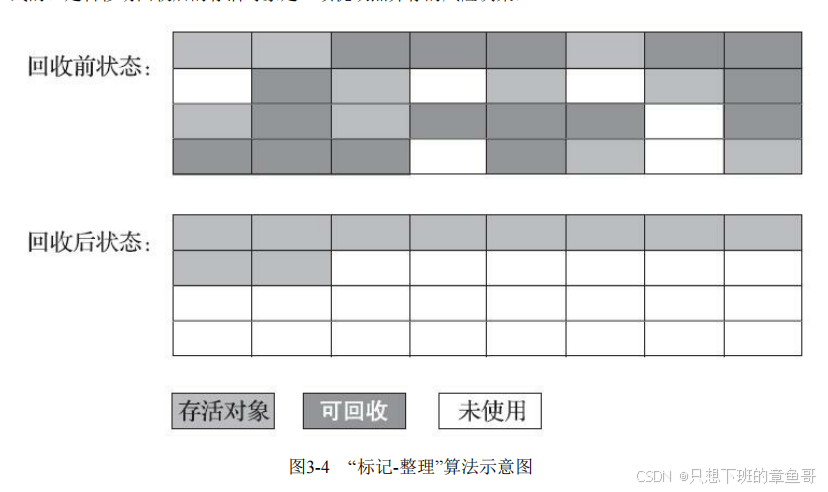
分代算法
分为年轻代和老年代,年轻代用适合年轻代的,老年代用适合老年代的。
总结
即使不移动对象会使得收集器的效率提升一些,但因内存分配和访问相比垃圾收集频率要高得多,这部分的耗时增加,总吞吐量仍然是下降的。HotSpot虚拟机里面关注吞吐量的Parallel Scavenge收集器是基于标记-整理算法的,而关注延迟的CMS收集器则是基于标记-清除算法的,
