
阅读量:2
前言:
本篇博客超级详细,请尽量使用电脑端结合目录阅读
阅读时请打开右侧 “只看目录” 方便阅读


一、什么是Python
1.1 Python的诞生
1989年,为了打发圣诞节假期,Gudio van Rossum吉多·范罗苏姆(龟叔)决心开发一个新的解释程序(Python雏形)
1991年,第一个Python解释器诞生
Python这个名字,来自龟叔所挚爱的电视剧Monty Python's Flying Circus


1.2 为什么学习Python

简单易学、全球第一、优雅、应用场景丰富(就业方向多)
1.3Python的应用场景

1.4 Python环境及软件的安装
请移步其他博客,此篇博客主要讲述Python语法 软件的安装会在后一段时间再发表新博客
二、Python的基础语法
2.1字面量
2.1.1 什么是字面量
在代码中,被写下来的固定的值(数据),叫做字面量
"abcd" 1 3.62.1.2 字面量类型
同时也是值(数据)类型

2.1.3 什么是字符串
注:先简单提出概念,方便写简易的代码,后续字符串有详解
字符串(string),又称文本,是由任意数量的字符如中文、英文、各类符号、数字等组成。所以叫做字符的串
如:
"abcde"
"世界真美好"
"123456大揭秘"
都是字符串
Python中,字符串需要用双引号("字符串内容")包围起来
被引号包围起来的,都是字符串
注:实际使用字符串时,无论是单引号,双引号,还是三引号都可以
即:字符串有三种不同的定义方式

三引号定义法,表示在一堆三个双引号的范围内,均是字符串(可以换行),如下:

2.2 基础Python语句 体验Python特点
2.2.1 print
print 相当于C语言中的 printf ,用法些许类似
如:
print("abc") print(123) print("9277万物可爱")运行结果:
abc
123
9277万物可爱
需要注意的是,单独输出常数和变量时,不需要使用引号
2.2.2 Python 语句格式与C的区别
首先,python语句不需要以分号结尾,而是以每一行作为区分,有点像每一行末尾处都加了分号(当然,实际不是,也不相同)
代码缩进:在C中,代码的缩进只影响代码的可读性和美观,不影响实际使用
而在python中,代码缩进控制着不同函数相互间的嵌套和归属
Python通过缩进判断代码块的归属关系。
大括号格式:Kernighan和Ritchie格式 (Kb&R格式)
当大括号内需要有多行语句,左侧的大括号与语句同行,不再另一分行
stu_score_dict = { #回车符对字典间的元素无影响 "王力鸿": { "语文": 77, "数学": 66, "英语": 33 }, "周杰轮": { "语文": 88, "数学": 86, "英语": 55 }, "林俊节": { "语文": 99, "数学": 96, "英语": 66 } } print(f"学生的考试信息是:{stu_score_dict}")由上图可以看出左侧大括号并未独自占一行
注:Python语句和C语句之间还有很多区别,后续会逐步发掘
2.3 注释
注释:在程序代码中对程序代码进行解释说明的文字。
作用:注释不是程序,不能被执行,只是对程序代码进行解释说明,让别人可以看懂程序代码的作用,能够大大增强程序的可读性。
2.3.1 单行注释
单行注释:通过#号定义,在#号右侧的所有内容均作为注释
以#开头,#右边的所有文字当作说明,而不是真正要执行的程序,起辅助说明作用

注:#号和注释内容一般建议以一个空格隔开
单行注释一般用于对一行或一小部分代码进行解释
2.3.2 多行注释
以 一对三个双引号引起来 """注释内容""" 来解释说明一段代码的作用使用方法

注:多行注释可以换行
多行注释一般对:Python文件、类或方法进行解释
2.3.3 关于注释的面试题
1. 单行注释中能否使用多行注释?
可以,但实际使用时敲下回车键会跳转下一行并自动蹦出# 实际没有三引号的太多关系
2. 多行注释中能否使用单行注释?
可以,但无论使用还是不使用,结果都完全一致
3. 多行注释中能否使用多行注释?
不可以,三引号之间会就近匹配
2.4 变量
2.4.1 什么是变量
变量:在程序运行时,能储存计算结果或能表示值的抽象概念。
简单的说,变量就是在程序运行时,记录数据用的
2.4.2 变量的定义格式

如:
a = 10待处理位置
print语句如何输出多份内容?
print(内容1, 内容2, ......, 内容N)
和那个加号的区别
2.5 数据类型(初识)
2.5.1 入门款三种输入类型
目前在入门阶段,我们主要接触如下三类数据类型:

string、int、float这三个英文单词,就是类型的标准名称。
2.5.2 type() 语句
当某个数据编写的令人迷惑时,问题来了,如何验证数据的类型呢?
我们可以通过type()语句来得到数据的类型:
语法:
type(被查看类型的数据)
使用方式:
1. 在print语句中,直接输出类型信息:
print(type("云边有个小卖部")) print(type(123)) print(type(11.345))运行结果:

2. 用变量存储type()的结果(返回值):
type_1 = type("云边有个小卖部") type_2 = type(123) type_3 = type(11.345) print(type_1) print(type_2) print(type_3)运行结果:
2.5.3 变量有类型么
答:变量无类型
我们通过type(变量)可以输出类型,这是查看变量的类型还是数据的类型?
查看的是:变量存储的数据的类型。因为,变量无类型,但是它存储的数据有。
2.6 类型转换
数据类型之间,在特定的场景下,是可以相互转换的,如字符串转数字、数字转字符串等
2.6.1 常见的转换语句

同前面学习的type()语句一样,这三个语句,都是带有结果的(返回值)
我们可以用print直接输出
或用变量存储结果值
2.6.2 类型转换注意事项
类型转换不是万能的,毕竟强扭的瓜不甜,我们需要注意:
1. 任何类型,都可以通过str(),转换成字符串
2. 字符串内必须真的是数字,才可以将字符串转换为数字

浮点数转整数会丢失精度,也就是小数部分
2.7 标识符
是用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名。
2.7.1 标识符命名规则
Python中,标识符命名的规则主要有3类:
• 内容限定 • 大小写敏感 • 不可使用关键字
标识符命名规则1 —— 内容限定
标识符命名中,只允许出现:
•英文•中文•数字•下划线(_)
这四类元素。
其余任何内容都不被允许。
注意:1. 不推荐使用中文
2.数字不可以开头
标识符命名规则2 —— 大小写敏感
以定义变量为例:
Andy = “安迪1”
andy = “安迪2”
字母a的大写和小写,是完全能够区分的。
标识符命名规则3 —— 不可使用关键字
Python中有一系列单词,称之为关键字
关键字在Python中都有特定用途
我们不可以使用它们作为标识符
常见的关键字有:

2.7.2 变量的命名规范
变量命名规范 —— 见名知意
变量的命名要做到:
• 明了:尽量做到,看到名字,就知道是什么意思a = "张三" name = ''张三'' b = 11 age = 11• 简洁:尽量在确保“明了”的前提下,减少名字的长度
a_person_name = "张三" name = "张三"
很明显,大多数情况下,都是右侧的命名规范更合适一些
变量命名规范 —— 下划线命名法
多个单词组合变量名,要使用下划线做分隔。
firstnumber = 1
studentnickname = "小明"
first_number = 1
student_nickname = "小明"
很明显,下面的两个变量命名更合适一些
2.8 运算符
2.8.1 算术运算符

算术运算符的演示:

2.8.2 赋值运算符

2.8.3 复合赋值运算符

2.9 字符串拓展
引号的嵌套:
• 可以使用转移字符(\)来将引号解除效用,变成普通字符串 • 单引号内可以写双引号或双引号内可以写单引号
2.9.1 字符串拼接
使用“+”号连接字符串变量或字符串字面量即可
name = "阿蛮" print("这位青年的名字叫做" + name + ",他今年18岁了")
字符串无法和非字符串变量进行拼接 因为类型不一致,无法接上
name = "阿蛮" age = 18 print("这位青年的名字叫做" + name + "年龄周岁是" + age)
2.9.2 字符串格式化
当变量过多时,我们会发现上述的字符串拼接并不好用,由此引出字符串格式化这个方法。
name = "CSDN" message = "学IT就来%s" % name print(message) 
其中的,%s
• % 表示:我要占位 • s 表示:将变量变成字符串放入占位的地方所以,综合起来的意思就是:我先占个位置,等一会有个变量过来,我把它变成字符串放到占位的位置
多个变量占位,变量要用括号括起来,并按照占位的顺序填入:

数字也能用%s占位吗?
可以的哦,这里是将数字转换成了字符串哦
也就是数字57,变成了字符串"57"被放入占位的地方
Python中,其实支持非常多的数据类型占位,最常用的是如下三类:

如下代码,完成字符串、整数、浮点数,三种不同类型变量的占位(演示):

2.9.3 格式化的精度控制
我们可以使用辅助符号"m.n"来控制数据的宽度和精度
• m,控制宽度,要求是数字(很少使用),若设置的宽度小于数字自身,不生效 • .n,控制小数点精度,要求是数字,会进行小数的四舍五入示例:
• %5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。 • %5.2f:表示将宽度控制为5,将小数点精度设置为2小数点和小数部分也算入宽度计算。如,对11.345设置了%7.2f 后,结果是:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35
(此处需要注意的是小数点本身也是占一个宽度的,然后有些朋友可能下去也试了 print("%4.2f" % 11.345) 这段代码,发现输出是11.35,带上小数点是有5个宽度的,这是怎么回事呢?简单解释就是编译器在格式化时,如果格式化代码出现问题,会根据语义进行了代码优化,不然你试试下面这个代码 print("%1.2f" % 11.345) ,会发现输出依然是11.35,足以证实)
%.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35
体验代码:

2.9.4 字符串格式化方法二
通过语法:f"内容{变量}"的格式来快速格式化
演示代码:

这种写法不做精度控制,也不理会类型,适用于快速格式化字符串
2.9.5 表达式的格式化
什么是表达式?
表达式:一条具有明确执行结果的代码语句
如:
1 + 1、5 * 2,就是表达式,因为有具体的结果,结果是一个数字
又或者,常见的变量定义:
name = “张三” age = 11 + 11
等号右侧的都是表达式呢,因为它们有具体的结果,结果赋值给了等号左侧的变量。
演示代码:

在无需使用变量进行数据存储的时候,可以直接格式化表达式,简化代码哦
2.10 数据输入 input()函数
• 使用input()语句可以从键盘获取输入 • 使用一个变量接收(存储)input语句获取的键盘输入数据即可 • 要注意,无论键盘输入什么类型的数据,获取到的数据永远都是字符串类型
print("请问你是谁") name = input () print(f"Get!!! 你是{name}")
绿色字体内容是需要我们主动从键盘输入的数据,input 接收的便是我们输入的内容
input()语句其实是可以在要求使用者输入内容前,输出提示内容的哦,方式如下:
name = input ("请问你是谁 ") print(f"Get!!! 你是{name}")
三、Python判断语句
3.1 布尔类型 bool
布尔(bool)表达现实生活中的逻辑,即真和假
• True表示真 • False表示假。True本质上是一个数字记作1,False记作0
布尔类型也是字面量,也可以用变量存储
3.2 比较运算符
布尔类型的数据,不仅可以通过定义得到,也可以通过比较运算符进行内容比较得到。
比较运算的表达式返回值是布尔类型
result = 10 > 5 print(f"10 > 5 的结果是{result},类型是{type(result)}")

3.3 if语句
3.3.1 if语句的基础语法格式

归属于if判断的代码语句块,需在前方填充4个空格缩进
Python通过缩进判断代码块的归属关系。
演示代码:
age = int(input()) #将字符串转换为整型 print(f"我今年已经{age}岁了") if age >= 18 : print("我已经成年了") print("即将步入大学生活") print("时间过得真快")如果age = 18

如果age = 10

3.3.2 if语句的注意事项
• 判断条件的结果一定要是布尔类型 • 不要忘记判断条件后的:引号 • 归属于if语句的代码块,需在前方填充4个空格缩进
3.4 if else 语句
if 条件:
满足条件的执行语句1
满足条件的执行语句2
...省略...
else:
不满足条件的执行语句1
不满足条件的执行语句2
...省略...
代码演示:

• if和其代码块,条件满足时执行 • else搭配if的判断条件,当不满足的时候执行
if else语句的注意事项: • else不需要判断条件,当if的条件不满足时,else执行 • else的代码块,同样要4个空格作为缩进
3.5 if elif else语句
使用场景:某些场景下,判断条件不止一个,可能有多个。
elif 类似于C中的else if
if 条件一:
满足条件一的执行语句1
满足条件一的执行语句2
...省略...
elif 条件二:
满足条件二的执行语句1
满足条件二的执行语句2
...省略...
elif 条件三:
满足条件三的执行语句1
满足条件三的执行语句2
...省略...
else:
不满足条件的执行语句1
不满足条件的执行语句2
...省略...
演示代码:

用input语句精简代码:

注意事项
• elif可以写多个 • 判断是互斥且有序的,上一个满足后面的就不会判断了 • 可以在条件判断中,直接写input语句,节省代码量
3.6 判断语句的嵌套
3.6.1 语法格式
if 条件一:
条件一满足时的执行语句1
条件一满足时的执行语句2
if 条件二:
条件二满足时的执行语句1
条件二满足时的执行语句2
第二个if,属于第一个if内,只有第一个if满足条件,才会执行第二个if
3.6.2 嵌套的关键点
嵌套的关键点,在于:空格缩进
通过空格缩进,来决定语句之间的:层次关系
3.6.3 演示代码

四、Python的循环语句
4.1 while循环
4.1.1while循环的基础语法
while 条件:
执行语句1
执行语句2
...省略...
每次进入循环后,将执行语句全部执行完毕后再次来到判断,如果条件依然成立,则继续进入循环,以此类推,直到条件不成立,跳出循环
注意事项:
• 条件需提供布尔类型结果,True继续,False停止 • 空格缩进不能忘 • 请规划好循环终止条件,否则将无限循环
4.1.2 演示代码
i = 0 while i < 5: print("小美,我喜欢你") i += 1 
4.1.3 while循环的嵌套
和判断语句的嵌套类似,这里不再长篇介绍
演示代码:

注意事项
• 注意条件的控制,避免无限循环 • 多层嵌套,主要空格缩进来确定层次关系
4.2 for循环
!!!注意!!!
python中的for循环与C语言中的for循环差别巨大,请勿混淆
4.2.1 for循环的语法格式

从待处理数据集中:逐个取出数据,赋值给临时变量
演示代码:
# 定义字符串name name = "itCSDN" # for循环处理字符串 for x in name: print(x)
可以看出,for循环是将字符串的内容:依次取出
所以,for循环也被称之为:遍历循环
同while循环不同,for循环是无法定义循环条件的。
只能从被处理的数据集中,依次取出内容进行处理。
所以,理论上讲,Python的for循环无法构建无限循环(被处理的数据集不可能无限大)
•要注意,循环内的语句,需要有空格缩进
4.2.2 range 语句

for循环语句,本质上是遍历:可迭代对象。
尽管除字符串外,其它可迭代类型目前没学习到,但不妨碍我们通过学习range语句,获得一个简单的数字序列(可迭代类型的一种)。
语法1:
range(num)
获取一个从0开始,到num结束的数字序列(不含num本身)
如range(5)取得的数据是:[0, 1, 2, 3, 4]
语法2:
range(num1,num2)
获得一个从num1开始,到num2结束的数字序列(不含num2本身)
如,range(5, 10)取得的数据是:[5, 6, 7, 8, 9]
语法3:
range(num1,num2,step)
获得一个从num1开始,到num2结束的数字序列(不含num2本身)
数字之间的步长,以step为准(step默认为1)
如,range(5, 10, 2)取得的数据是:[5, 7, 9]
代码演示:
print("输出7内的偶数") for i in range(0,7,2): print(i)
4.2.3 变量的作用域
变量的作用域指变量的有效范围
1. for循环中的变量叫做临时变量,其作用域限定为:循环内
2. 这种限定:
• 是编程规范的限定,而非强制限定 • 不遵守也能正常运行,但是不建议这样做 • 如需访问临时变量,可以预先在循环外定义它
如果在for循环外部访问临时变量:
• 实际上是可以访问到的 • 在编程规范上,是不允许、不建议这么做的4.2.4 for循环的嵌套
for循环嵌套模式与while循环嵌套以及判断语句的嵌套都类似,注意事项如下:
• 需要注意缩进,嵌套for循环同样通过缩进确定层次关系 • for循环和while循环可以相互嵌套使用
4.3 continue 和 break
Python提供continue和break关键字
用以对循环进行临时跳过和直接结束
和C语言中continue和break的用法和作用类似
4.3.1 continue
continue关键字用于:中断本次循环,直接进入下一次循环
continue可以用于: for循环和while循环,效果一致
当continue出现在嵌套循环中时,continue关键字只可以控制:它所在的循环临时中断
代码演示:
for i in range(1,3): print(f"第{i}天:今晚的晚霞很漂亮") for j in range(5,7): print("今天还是去咖啡店买点面包吧") if j == 6: continue print(f"下午{j}点了,晚风吹拂")
可以看到,j == 6时,下面的print语句始终没有执行,而是跳了过去继续循环
4.3.2 break
break关键字用于:直接结束所在循环
break可以用于: for循环和while循环,效果一致
当break出现在嵌套循环中时,break关键字同样只可以控制:它所在的循环永久中断
代码演示:
for i in range(1,5): if i == 3 : break print(i)
五、函数
函数:是组织好的,可重复使用的,用来实现特定功能的代码段。
我们使用过的:input()、print()、str()、int()等都是Python的内置函数
• 将功能封装在函数内,可供随时随地重复利用 • 提高代码的复用性,减少重复代码,提高开发效率
5.1 函数的定义
函数的定义:
def 函数名(传入参数):
函数体return 返回值
函数的调用:
函数名(参数)
注意事项:
① 参数如不需要,可以省略
② 返回值如不需要,可以省略
③ 函数必须先定义后使用
5.2 函数的参数
传入参数的数量是不受限制的。
• 可以不使用参数 • 也可以仅使用任意N个参数

• 函数定义中,提供的x和y,称之为:形式参数(形参),表示函数声明将要使用2个参数 • 参数之间使用逗号进行分隔 • 函数调用中,提供的5和6,称之为:实际参数(实参),表示函数执行时真正使用的参数值 • 传入的时候,按照顺序传入数据,使用逗号分隔
总结:
•函数定义中的参数,称之为形式参数•函数调用中的参数,称之为实际参数•函数的参数数量不限,使用逗号分隔开•传入参数的时候,要和形式参数一一对应,逗号隔开
5.3 函数的返回值
5.3.1 return 返回值
什么是函数的返回值
函数在执行完成后,返回给调用者的结果
返回值的应用语法:
使用关键字:return 来返回结果然后可以用变量来接收这个结果 变量 = 函数(参数)
注意事项:
函数体在遇到return后就结束了,所以写在return后的代码不会执行。
5.3.2 None类型
思考:如果函数没有使用return语句返回数据,那么函数有返回值吗?
实际上是:有的。
Python中有一个特殊的字面量:None,其类型是:<class 'NoneType'>
无返回值的函数,实际上就是返回了:None这个字面量
None表示:空的、无实际意义的意思
函数返回的None,就表示,这个函数没有返回什么有意义的内容。
也就是返回了空的意思。
None可以主动使用return返回,效果等同于不写return语句: return None
None的应用场景:
None作为一个特殊的字面量,用于表示:空、无意义,其有非常多的应用场景。
• 用在函数无返回值上 • 用在if判断上 • 在if判断中,None等同于False • 一般用于在函数中主动返回None,配合if判断做相关处理 • 用于声明无内容的变量上 • 定义变量,但暂时不需要变量有具体值,可以用None来代替例如:name = None
5.4 函数的说明文档
函数是纯代码语言,想要理解其含义,就需要一行行的去阅读理解代码,效率比较低。
我们可以给函数添加说明文档,辅助理解函数的作用。
语法如下:

• :param 用于解释参数 • :return 用于解释返回值通过多行注释的形式,对函数进行说明解释
•内容应写在函数体之前
在PyCharm编写代码时,可以通过鼠标悬停,查看调用函数的说明文档

5.5 函数的嵌套调用
所谓函数嵌套调用指的是一个函数里面又调用了另外一个函数
执行过程:


如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
注:其实函数调用非常简单,和正常使用函数无太大区别,多写几段代码就明白了
5.6 变量的作用域
变量作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用)
主要分为两类:局部变量和全局变量
5.6.1 局部变量
所谓局部变量是定义在函数体内部的变量,即只在函数体内部生效
局部变量的作用:在函数体内部,临时保存数据,即当函数调用完成后,则销毁局部变量
演示代码:

变量a是定义在`testA`函数内部的变量,在函数外部访问则立即报错.
5.6.2 全局变量
所谓全局变量,指的是在函数体内、外都能生效的变量
思考:如果有一个数据,在函数A和函数B中都要使用,该怎么办?
答:将这个数据存储在一个全局变量里面

当全局变量和局部变量发生冲突时,优先使用局部变量
5.6.3 global 关键字
☆ 使用 global关键字 可以在函数内部声明变量为全局变量, 如下所示

若不声明,则num = 100 因为: 当全局变量和局部变量发生冲突时,优先使用局部变量
六、数据容器
6.1 数据容器入门 数据容器是什么
什么是数据容器?
一种可以存储多个元素的Python数据类型

学习数据容器,就是为了批量存储或批量使用多份数据
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素
每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如:
• 是否支持重复元素 • 是否可以修改 • 是否有序,等分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
6.2 list 列表
6.2.1 列表的定义
基本语法:
字面量 [元素1,元素2,元素3,元素4, ...] 定义变量 变量名称 = [元素1,元素2,元素3,元素4, ...] 定义空变量 变量名称 = [] 变量名称 = list()
列表内的每一个数据,称之为元素
以 [ ] 作为标识列表内每一个元素之间用, 逗号隔开元素的数据类型没有任何限制,甚至元素也可以是列表,这样就定义了嵌套列表
演示代码:
name1_list = ['欧阳无双','上官婉儿','tom','black'] print(name1_list)
也可以嵌套:
name2_list = [['red','green'],['bule','white'],name1_list] print(name2_list) 
6.2.2 列表的下标索引
如图,列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增

我们只需要按照下标索引,即可取得对应位置的元素。

或者,可以反向索引,如图,从后向前,下标索引为:-1、-2、-3,依次递减。


如果列表是嵌套的列表,同样支持下标索引
#取出嵌套列表的元素 my_list2 = [[1,2,3],[4,5,6]] print(my_list2[1][1])
嵌套列表时,被嵌套的列表可以看作一个元素,第一个下标就是确定元素是列表[1,2,3],再用一个下标取出这个被嵌套的列表中的元素
总结:
1. 列表的下标索引是什么?
列表的每一个元素,都有编号称之为下标索引
从前向后的方向,编号从0开始递增
从后向前的方向,编号从-1开始递减
2. 如何通过下标索引取出对应位置的元素呢?
列表[下标],即可取出
3. 下标索引的注意事项:
• 要注意下标索引的取值范围,超出范围无法取出元素,并且会报错
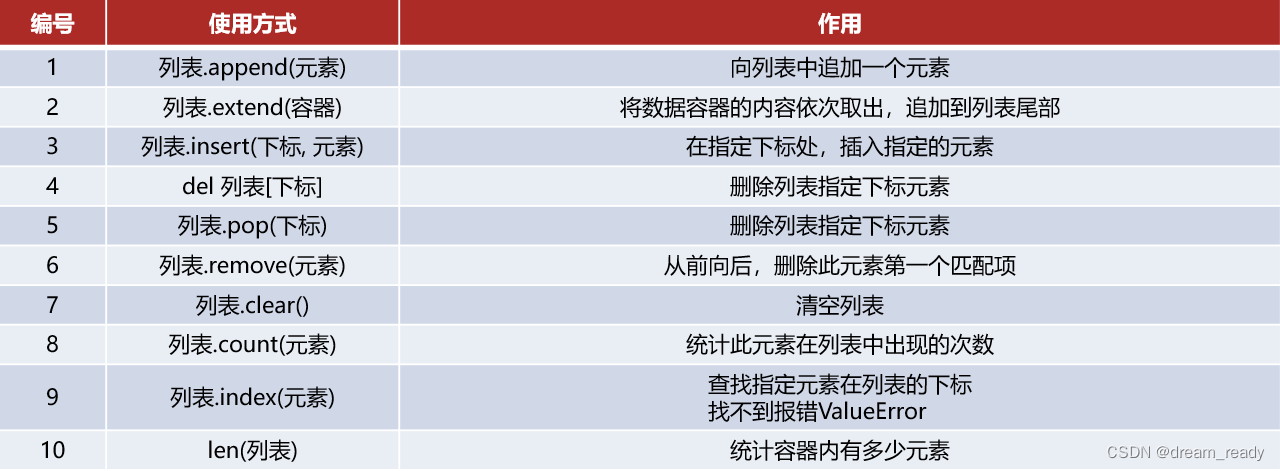
6.2.3 列表的常用操作(方法)
演示代码:
1、在列表的尾部追加 ''' 单个 ''' 元素 语法:列表.append(元素)
mylist = ["itCSDN", "itlove", "python"] mylist.append("CSDN程序员") print(f"列表在追加了元素后,结果是:{mylist}")
2、在列表的尾部追加 ''' 一批 ''' 元素 语法:列表.extend(另一个数据容器)
将另一个数据容器的内容取出,依次加到列表尾部
mylist = ["itCSDN", "itlove", "python"] mylist2 = [1, 2, 3] mylist.extend(mylist2) print(f"列表在追加了一个新的列表后,结果是:{mylist}")
3、在指定下标位置插入新元素 语法:列表.insert(下标,元素)
在指定的下标位置,插入指定的元素,其余元素向后移动
mylist = ["itCSDN", "itlove", "python"] mylist.insert(1, "best") print(f"列表插入元素后,结果是:{mylist}")
4、删除列表指定下标元素 语法:del 列表[下标]
与pop的区别:仅仅能完成删除操作
mylist = ["itCSDN", "itlove", "python"] del mylist[2] print(f"列表删除元素后结果是:{mylist}")
5、删除指定下标元素 语法:列表.pop(下标)
与del的区别:不仅能把元素删掉,还能把删除元素作为返回值去得到
mylist = ["itCSDN", "itlove", "python"] element = mylist.pop(2) print(f"通过pop方法取出元素后列表内容:{mylist}, 取出的元素是:{element}")
6、删除某元素在列表中的第一个匹配项 语法:列表.remove(元素)
mylist = ["itCSDN", "itlove", "python"] mylist.remove("itlove") print(f"通过remove方法移除元素后,列表的结果是:{mylist}")
7、清空列表 语法:列表.clear()
mylist = ["itCSDN", "itlove", "python"] mylist.clear() print(f"列表被清空了,结果是:{mylist}")
8、统计列表内某元素的数量 语法:列表.count(元素)
mylist = ["itCSDN", "itlove", "itlove", "itlove", "python"] count = mylist.count("itlove") print(f"列表中itlove的数量是:{count}")
9、查找某元素在列表中的下标索引 语法:列表.index(元素)
mylist = ["itCSDN", "itlove", "python"] index = mylist.index("itlove") print(f"itlove在列表中的下标索引值是:{index}")
如果被查找的元素不存在,会报错
10、统计列表中全部的元素数量 语法:len(列表)
mylist = ["itCSDN", "itlove", "python"] count = len(mylist) print(f"列表的元素数量总共有:{count}个")
6.2.4 总结列表的特点
• 可以容纳多个元素(上限为2**63-1、9223372036854775807个) • 可以容纳不同类型的元素(混装) • 数据是有序存储的(有下标序号) • 允许重复数据存在 • 可以修改(增加或删除元素等)
6.2.5 列表的遍历
既然数据容器可以存储多个元素,那么,就会有需求从容器内依次取出元素进行操作。
将容器内的元素依次取出进行处理的行为,称之为:遍历、迭代。
列表的遍历——while循环
index = 0
while index < len(列表) :
元素 = 列表[index]
对元素进行处理
index += 1
列表的遍历——for循环
对比while,for循环更加适合对列表等数据容器进行遍历。
for 临时变量 in 数据容器 :
对临时变量进行处理
for循环和while对比
• for循环更简单,while更灵活 • for用于从容器内依次取出元素并处理,while用以任何需要循环的场景
6.3 tuple 元组
元组一旦定义完成,就不可修改
6.3.1 元组的定义
元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
#定义元组字面量 (元素,元素,......,元素) #定义元组数量 变量名称 = (元素,元素,...... ,元素) #定义空元组 变量名称 = () 方式一 变量名称 = tuple() 方式二
注:1、元组只有一个数据时,这个数据后面要添加逗号,否则不是元组类型!
2、元组也支持嵌套
演示代码:
t2 = ("Hello",) print(f"t2的类型是:{type(t2)},t2的内容是:{t2}")
6.3.2 元组的相关操作

元组由于不可修改的特性,所以其操作方法非常少。
元组的三种方法和列表相对应的这三种方法操作一致,这里就不再讲解,若有疑问,请私信博主或者移步前文列表方法查看
6.3.3 元组的遍历
元组同样支持while循环和for循环的遍历操作
用法和列表遍历一致,请移步前文列表遍历处查看
6.3.4总结元组的特点
• 可以容纳多个数据 • 可以容纳不同类型的数据(混装) • 数据是有序存储的(下标索引) • 允许重复数据存在 • 不可以修改(增加或删除元素等) • 支持for循环
多数特性和list一致,不同点在于不可修改的特性。
但如果元组中嵌套的有列表,那么列表中的元素可以修改(列表list的本质没有改变,所以不违背元组不可以修改的原则)
演示代码:
t4 = (1,2,['青灯古刹','刹那芳华']) t4[2][0] = '黄粱一梦' t4[2][1] = '大梦初醒' print(t4)
6.4 str 字符串
字符串是字符的容器,一个字符串可以存放任意数量的字符。
同元组一样,字符串是一个:无法修改的数据容器。
6.4.1 字符串的下标索引
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
• 从前向后,下标从0开始 • 从后向前,下标从-1开始

6.4.2 字符串的常用操作(方法)

1、根据下标索引取出特定位置字符 语法:字符串[下标]
str = "mountain and sea" str1 = str[3] str2 = str[-2] print(f"从字符串{str}取下标为3的元素,值是{str1},取下标为-2的元素,值是{str2}")
2、查找给定字符的第一个匹配项的下标 语法:字符串.index(字符串)
str = "mountain and sea" value = str.index("and") print(f"在字符串{str}中查找“and”,其起始下标是{value}")
3、将字符串1替换为字符串2 语法:字符串.replace(字符串1,字符串2)
注意:不是修改字符串本身,而是得到了一个新字符串
str = "itmountain and itsea" new_str = str.replace("it","程序") print(f"将字符串 {str},进行替换得到 {new_str}")
4、按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
语法:字符串.spilt(分隔符字符串)
注意:字符串本身不变,而是得到了一个新的列表对象
my_str = "hello python itCSDN itlove" my_str_list = my_str.split(" ") print(f"将字符串{my_str}进行split切分后得到:{my_str_list}, 类型是:{type(my_str_list)}")
5、字符串的规整操作(移除首尾的空格和换行符或指定字符串)
语法1:字符串.strip() 不传入参数时,去除首尾空格
my_str = " itCSDN and itlove " new_my_str = my_str.strip() # 不传入参数,去除首尾空格 print(f"字符串{my_str}被strip后,结果:{new_my_str}")
语法2:字符串.strip(字符串)
注意:传入的是"12",其实就是:"1"和"2"都会移除,是按照单个字符
my_str = "12itCSDN and itlove21" new_my_str = my_str.strip("12") print(f"字符串{my_str}被strip('12')后,结果:{new_my_str}")
6、统计字符串内某字符或字符串的出现次数 语法:字符串.count(字符串)
my_str = "itCSDN and itlove" count = my_str.count("it") print(f"字符串{my_str}中it出现的次数是:{count}")
7、统计字符串的字符个数 语法:len(字符串)
my_str = "itCSDN and itlove" num = len(my_str) print(f"字符串{my_str}的长度是:{num}")
6.4.3 总结字符串的特点
作为数据容器,字符串有如下特点:
• 只可以存储字符串 • 长度任意(取决于内存大小) • 支持下标索引 • 允许重复字符串存在 • 不可以修改(增加或删除元素等) • 支持for循环
6.5 序列
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列。
6.5.1 序列的常用操作——切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
• 起始下标表示从何处开始,可以留空,留空视作从头开始 • 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾 • 步长表示,依次取元素的间隔 • 步长1表示,一个个取元素 • 步长2表示,每次跳过1个元素取 • 步长N表示,每次跳过N-1个元素取 • 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意,此操作不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
注:可以用此方法倒序字符串等序列(步长设为-1)







可以看到,这个操作对列表、元组、字符串是通用的
同时非常灵活,根据需求,起始位置,结束位置,步长(正反序)都是可以自行控制的
6.6 set 集合
6.6.1 集合的特点
• 集合内不允许重复元素(去重) • 集合内元素是无序的(不支持下标索引)
6.6.2 集合的定义

结合集合特点进行代码演示:
my_set_empty = set() # 定义空集合 print(f"my_set_empty的内容是:{my_set_empty}, 类型是:{type(my_set_empty)}") my_set = {"CSDN程序员社区", "CSDN灌水乐园", "itCSDN", "CSDN灌水乐园", "CSDN程序员社区", "itCSDN"} print(f"my_set的内容是:{my_set}, 类型是:{type(my_set)}")
6.6.3 集合的常用操作

1、添加新元素 语法:集合.add(元素)
my_set = {"CSDN程序员社区", "CSDN灌水乐园", "itCSDN"} my_set.add("Python") my_set.add("CSDN程序员社区") print(f"my_set添加元素后结果是:{my_set}")
注意1:当集合本身就含有被添加的元素时,则添加无效(去重)
注意2:因为集合本身没有顺序,所以被添加元素位置随机
2、移除集合内指定的元素 语法:集合.remove(元素)
my_set = {"CSDN程序员社区", "CSDN灌水乐园", "itCSDN"} my_set.remove("CSDN程序员社区") print(f"my_set移除黑马程序员后,结果是:{my_set}")
3、从集合中随机取出一个元素,原集合此元素会被删除 语法:集合.pop()
my_set = {"CSDN程序员社区", "CSDN灌水乐园", "itCSDN"} element = my_set.pop() print(f"集合被取出元素是:{element}, 取出元素后:{my_set}")
4、清空集合 语法:集合.clear()
my_set = {"CSDN程序员社区", "CSDN灌水乐园", "itCSDN"} my_set.clear() print(f"集合被清空啦,结果是:{my_set}")
5、取两个集合的差集(得到一个新集合) 语法:集合1.difference(集合2)
set1 = {1, 2, 3} set2 = {1, 5, 6} set3 = set1.difference(set2) print(f"取出差集后的结果是:{set3}") print(f"取差集后,原有set1的内容:{set1}") print(f"取差集后,原有set2的内容:{set2}")
6、消除两个集合的差集,集合1被修改,集合2不变 语法:集合1.difference_update(集合2)
set1 = {1, 2, 3} set2 = {1, 5, 6} set1.difference_update(set2) print(f"消除差集后,集合1结果:{set1}") print(f"消除差集后,集合2结果:{set2}")
7、 得到一个新的集合,内含两个集合的所有元素,原有的两个集合不变
语法:集合1.union(集合2)
set1 = {1, 2, 3} set2 = {1, 5, 6} set3 = set1.union(set2) print(f"2集合合并结果:{set3}") print(f"合并后集合1:{set1}") print(f"合并后集合2:{set2}")
8、统计集合的去重后的元素数量 语法:len(集合)
set1 = {1, 2, 3, 4, 5, 1, 2, 3, 4, 5} num = len(set1) print(f"集合内的元素数量有:{num}个")
6.6.4 集合的遍历
集合同样支持使用for循环遍历
要注意:集合不支持下标索引,所以也就不支持使用while循环。
set1 = {1, 2, 3, 4, 5} for element in set1: print(f"集合的元素有:{element}")
6.6.5 集合的特点
经过上述对集合的学习,可以总结出集合有如下特点:
• 可以容纳多个数据 • 可以容纳不同类型的数据(混装) • 数据是无序存储的(不支持下标索引) • 不允许重复数据存在 • 可以修改(增加或删除元素等) • 支持for循环
6.7 字典
6.7.1 字典的定义
通过 key 找出对应的 value

字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:
• 使用{}存储原始,每一个元素是一个键值对 • 每一个键值对包含Key和Value(用冒号分隔) • 键值对之间使用逗号分隔 • Key和Value可以是任意类型的数据(key不可为字典) • Key不可重复,重复会对原有数据覆盖 •字典不可用下标索引,而是通过Key检索Value
键值对 key :value 三者结合被称为键值对

字典同集合一样,不可以使用下标索引
但是字典可以通过Key值来取得对应的Value

演示代码:
# 定义字典 my_dict1 = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77} # 定义空字典 my_dict2 = {} my_dict3 = dict() print(f"字典1的内容是:{my_dict1}, 类型:{type(my_dict1)}") print(f"字典2的内容是:{my_dict2}, 类型:{type(my_dict2)}") print(f"字典3的内容是:{my_dict3}, 类型:{type(my_dict3)}")
# 从字典中基于Key获取Value my_dict1 = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77} score = my_dict1["王力鸿"] print(f"王力鸿的考试分数是:{score}") score = my_dict1["周杰轮"] print(f"周杰轮的考试分数是:{score}")
6.7.2 字典的嵌套
字典的Key和Value可以是任意数据类型(Key不可为字典)
那么,就表明,字典是可以嵌套的

演示代码:
# 定义嵌套字典 stu_score_dict = { #回车符对字典间的元素无影响 "王力鸿": { "语文": 77, "数学": 66, "英语": 33 }, "周杰轮": { "语文": 88, "数学": 86, "英语": 55 }, "林俊节": { "语文": 99, "数学": 96, "英语": 66 } } print(f"学生的考试信息是:{stu_score_dict}") # 从嵌套字典中获取数据 # 看一下周杰轮的语文信息 score = stu_score_dict["周杰轮"]["语文"] print(f"周杰轮的语文分数是:{score}") score = stu_score_dict["林俊节"]["英语"] print(f"林俊节的英语分数是:{score}")
6.7.3 字典的常用操作

1、获取指定Key对应的Value值 语法:字典[key]
my_dict1 = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77} score = my_dict1["王力鸿"] print(f"王力鸿的考试分数是:{score}")
2、添加或更新键值对 语法:字典[key] = Value
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77} # 新增元素 my_dict["张信哲"] = 66 print(f"字典经过新增元素后,结果:{my_dict}") #更新元素 my_dict["周杰轮"] = 33 print(f"字典经过更新后,结果:{my_dict}")
3、取出Key对应的Value并在字典内删除此Key的键值对 语法:字典.pop(key)
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77} score = my_dict.pop("周杰轮") print(f"字典中被移除了一个元素,结果:{my_dict}, 周杰轮的考试分数是:{score}")
4、清空字典 语法:字典.clear
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77} my_dict.clear() print(f"字典被清空了,内容是:{my_dict}")
5、获取字典的全部Key,可用于for循环遍历字典 语法:字典.key
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77} keys = my_dict.keys() print(f"字典的全部keys是:{keys}") # 遍历字典 # 方式1:通过获取到全部的key来完成遍历 for key in keys: print(f"字典的key是:{key}") print(f"字典的value是:{my_dict[key]}")
6、计算字典内的元素数量
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77} num = len(my_dict) print(f"字典中的元素数量有:{num}个")
6.7.4 字典的遍历
方法1:通过获取到全部的key来完成遍历
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77} keys = my_dict.keys() print(f"字典的全部keys是:{keys}") # 遍历字典 # 方式1:通过获取到全部的key来完成遍历 for key in keys: print(f"字典的key是:{key}") print(f"字典的value是:{my_dict[key]}")
方法2:直接对字典进行for循环,每一次循环都是直接得到key
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77} for key in my_dict: print(f"字典的key是:{key}") print(f"字典的value是:{my_dict[key]}")
6.7.5 字典的特点
经过上述对字典的学习,可以总结出字典有如下特点:
• 可以容纳多个数据 • 可以容纳不同类型的数据 • 每一份数据是KeyValue键值对 • 可以通过Key获取到Value,Key不可重复(重复会覆盖) • 不支持下标索引 • 可以修改(增加或删除更新元素等) • 支持for循环,不支持while循环
6.8 数据容器对比总结

基于各类数据容器的特点,它们的应用场景如下: • 列表:一批数据,可修改、可重复的存储场景 • 元组:一批数据,不可修改、可重复的存储场景 • 字符串:一串字符串的存储场景 • 集合:一批数据,去重存储场景 • 字典:一批数据,可用Key检索Value的存储场景
• 列表使用:[] • 元组使用:() • 字符串使用:"" • 集合使用:{} •字典使用:{}和键值对
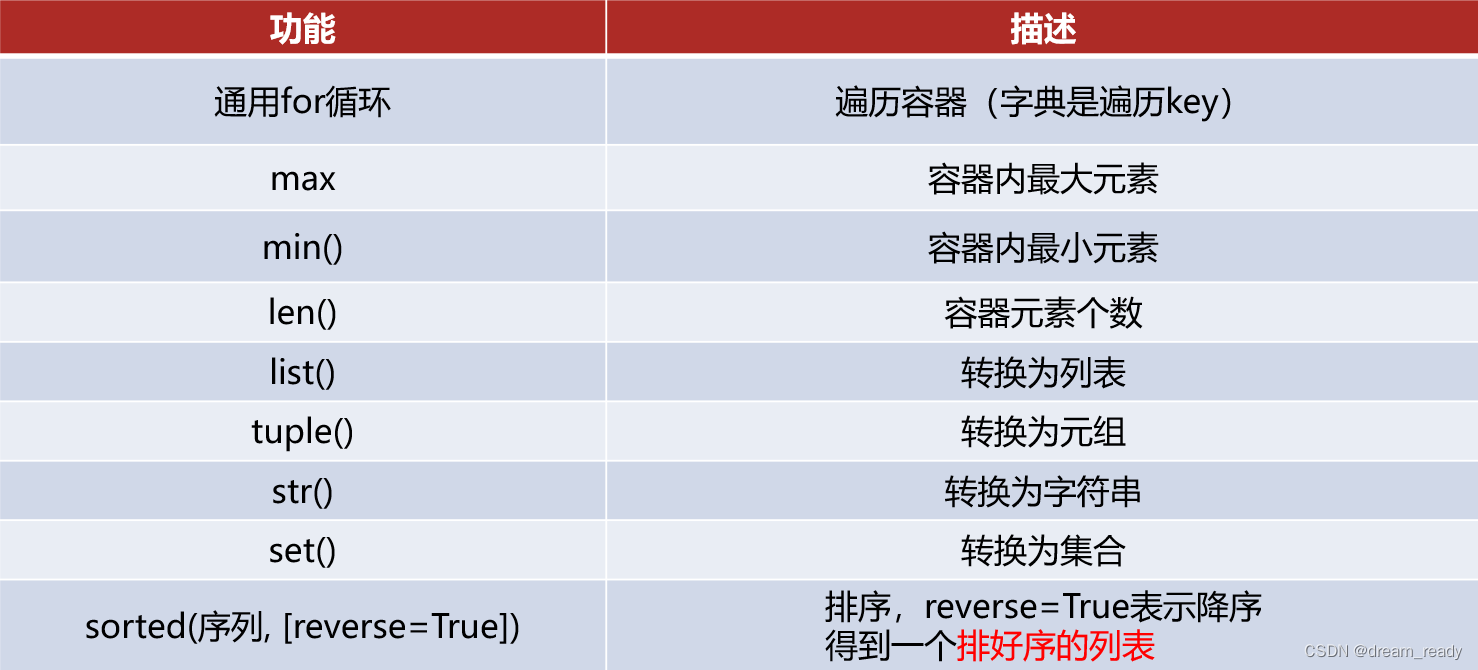
6.9 数据容器的通用操作及相互转换
my_list = [1, 2, 3, 4, 5] my_tuple = (1, 2, 3, 4, 5) my_str = "abcdefg" my_set = {1, 2, 3, 4, 5} my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}6.9.1 数据容器的遍历
此处不再讲,前面非常详细、
6.9.2 容器内最大元素 语法:max(数据容器名)
# max最大元素 print(f"列表 最大的元素是:{max(my_list)}") print(f"元组 最大的元素是:{max(my_tuple)}") print(f"字符串最大的元素是:{max(my_str)}") print(f"集合 最大的元素是:{max(my_set)}") print(f"字典 最大的元素是:{max(my_dict)}")
6.9.3 容器内最小元素 语法:min(数据容器名)
# min最小元素 print(f"列表 最小的元素是:{min(my_list)}") print(f"元组 最小的元素是:{min(my_tuple)}") print(f"字符串最小的元素是:{min(my_str)}") print(f"集合 最小的元素是:{min(my_set)}") print(f"字典 最小的元素是:{min(my_dict)}")
6.9.4 计算容器内元素个数 语法:len(数据容器名)
# len元素个数 print(f"列表 元素个数有:{len(my_list)}") print(f"元组 元素个数有:{len(my_tuple)}") print(f"字符串元素个数有:{len(my_str)}") print(f"集合 元素个数有:{len(my_set)}") print(f"字典 元素个数有:{len(my_dict)}")
6.9.5 数据容器转列表 语法:list(数据容器名)
字典转列表时会丢掉value值
# 类型转换: 容器转列表 print(f"列表转列表的结果是:{list(my_list)}") print(f"元组转列表的结果是:{list(my_tuple)}") print(f"字符串转列表结果是:{list(my_str)}") print(f"集合转列表的结果是:{list(my_set)}") print(f"字典转列表的结果是:{list(my_dict)}")
6.9.6 数据容器转元组 语法:tuple(数据容器名)
字典转元组时会丢掉value值
# 类型转换: 容器转元组 print(f"列表转元组的结果是:{tuple(my_list)}") print(f"元组转元组的结果是:{tuple(my_tuple)}") print(f"字符串转元组结果是:{tuple(my_str)}") print(f"集合转元组的结果是:{tuple(my_set)}") print(f"字典转元组的结果是:{tuple(my_dict)}")
6.9.7 数据容器转字符串 语法:str(数据容器名)
# 类型转换: 容器转字符串 print(f"列表转字符串的结果是:{str(my_list)}") print(f"元组转字符串的结果是:{str(my_tuple)}") print(f"字符串转字符串结果是:{str(my_str)}") print(f"集合转字符串的结果是:{str(my_set)}") print(f"字典转字符串的结果是:{str(my_dict)}")
6.9.8 数据容器转集合 语法:set(数据容器名)
# 类型转换: 容器转集合 print(f"列表转集合的结果是:{set(my_list)}") print(f"元组转集合的结果是:{set(my_tuple)}") print(f"字符串转集合结果是:{set(my_str)}") print(f"集合转集合的结果是:{set(my_set)}") print(f"字典转集合的结果是:{set(my_dict)}")
6.9.9 容器排序 可正序也可倒序
# 进行容器的排序 my_list = [3, 1, 2, 5, 4] my_tuple = (3, 1, 2, 5, 4) my_str = "bdcefga" my_set = {3, 1, 2, 5, 4} my_dict = {"key3": 1, "key1": 2, "key2": 3, "key5": 4, "key4": 5}1、正序排列 语法:sorted(数据容器名)
print(f"列表对象的排序结果:{sorted(my_list)}") print(f"元组对象的排序结果:{sorted(my_tuple)}") print(f"字符串对象的排序结果:{sorted(my_str)}") print(f"集合对象的排序结果:{sorted(my_set)}") print(f"字典对象的排序结果:{sorted(my_dict)}")
2、逆序排列 语法:sorted(数据容器名,reverse = True)
print(f"列表对象的反向排序结果:{sorted(my_list, reverse=True)}") print(f"元组对象的反向排序结果:{sorted(my_tuple, reverse=True)}") print(f"字符串对象反向的排序结果:{sorted(my_str, reverse=True)}") print(f"集合对象的反向排序结果:{sorted(my_set, reverse=True)}") print(f"字典对象的反向排序结果:{sorted(my_dict, reverse=True)}")
结尾留言
尊敬的读者,您好!
当你将这篇博客看完并加以实践后,Python的语法到这里也告了一段落
后续博主会不定时对这篇文章加以补充并往后续写Python新的内容
