
阅读量:0

近日,华为2012实验室中央软件院旗下的欧拉多咖创新团队成功举办了【欧拉多咖 — 操作系统研讨会】。本次研讨会以“系统安全+AI=?”为主题,探讨了大模型技术如何推动基础软件迈向大规模算力时代,并详细讨论了在这一过程中系统软件所面临的机遇与挑战。云起无垠的技术负责人周鹏先生在活动中发表了题为《大模型在模糊测试领域的探索》的演讲,深入讨论了模糊测试的发展历程、大模型与模糊测试的结合应用,以及模糊测试智能体的未来技术趋势。
周鹏的分享围绕三个核心议题展开:首先,回顾了模糊测试技术的发展历程,阐述了其在软件测试中的重要性;其次,探讨了大模型技术如何与模糊测试相结合,以及这种结合在实际应用中的优势;最后,展望了模糊测试智能体技术的未来发展方向,为行业提供了新的思路和视角。
模糊测试的发展
自1988年模糊测试技术首次被提出以来,这一技术已经经历了30多年的发展历程,逐步成熟并广泛应用于软件安全领域。模糊测试技术在多个关键发展节点上不断演变,展示了其在发现安全缺陷方面的强大能力。
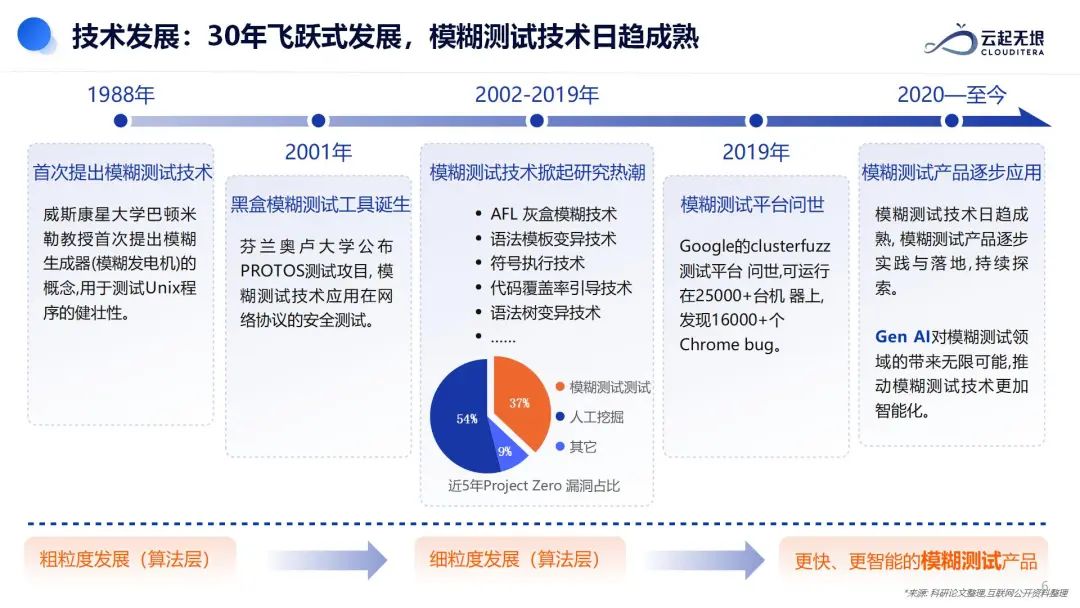
尤其是2020年以来,模糊测试与人工智能技术的融合为网络安全领域带来了革命性的变革,开启了自动化攻防的新篇章。在DARPA(美国国防高级研究计划局)举办的网络超级挑战赛中,卡耐基梅隆大学开发的Mayhem自动攻击系统展示了模糊测试在自动化网络攻击和防御中的巨大潜力。Mayhem系统在比赛中利用先进的模糊测试技术,通过生成大量变异的输入数据来发现软件中的漏洞,从而在决赛中以显著优势胜出,证明了将模糊测试与超级计算能力相结合的策略在网络安全领域的强大效能。
在2024年,随着人工智能技术的进一步发展,超亿元奖金的AIxCC(人工智能与网络安全交叉挑战赛)进一步推动了这一领域的创新。AIxCC比赛鼓励参赛者将大语言模型与安全引擎相结合,以解决网络安全中的实际问题。这种结合不仅提升了自动化检测和响应的能力,还能够更有效地识别和防御网络攻击,从而保护关键基础设施和数据安全。
与此同时,模糊测试技术在0Day漏洞挖掘方面的优势也日益显著,吸引了美国国防部、Google、微软、华为等大型机构逐年增加在该技术上的研发投入。这些机构通过模糊测试技术挖掘漏洞的效果显著,尽管模糊测试技术的门槛较高,市场化推广尚未全面展开。

大模型与模糊测试的实践应用
模糊测试作为一种强大的测试技术,通过系统化的输入变异和执行监控,能够有效发现软件中的安全缺陷,显著提高软件安全性。然而,模糊测试技术的应用难度大,开发和维护成本高,尤其是在修复安全缺陷时,需要投入大量资源。因此,亟需找到合适的解决方案,通过持续改进和优化模糊测试流程,进一步提升测试效率和覆盖率,发现更多潜在的安全问题。
云起无垠作为国内率先提出AI安全智能体概念的企业,专注于利用大模型技术探索安全缺陷的智能检测与修复技术。公司依托自主研发的“云起AI安全大脑”,成功推出了AI安全智能体平台,该平台集成了多项安全智能体能力,显著提升了软件测试的自动化水平和代码质量。
云起AI安全大脑的安全数据基座收集了包括漏洞库、开源代码库和安全前沿论文等多种安全数据源,通过采集、清洗和标记将其存入大模型数据库。然后,通过基座模型筛选,进行模型测试数据集和模型能力评估,以选取最优模型。随后,使用开源大模型、商业大模型和SecGPT进行基础训练和开发。模型训练过程中涵盖安全知识监督学习、安全业务强化学习和安全场景知识增强等多个方面,包括漏洞信息、威胁情报、安全工具、ATT&CK、安全流量监控、偏好优化、AI反馈学习、人类反馈、提示词工程、工具调用和检索增强等。
针对不同任务,云起AI安全大脑训练细化的场景模型,如程序语言模型集和自然语言模型集,包括修复代码生成模型、代码解释模型、测试驱动生成模型等。通过数据反馈和模型能力的持续改进,软件安全智能体不断提升测试驱动生成的成功率、代码检测准确率和代码修复成功率,从而显著增强软件的整体安全性。
在技术实现上,AI安全智能体平台的核心是基于深度学习和自然语言处理技术,特别是采用了transformer架构。该架构的核心组件包括编码器和解码器,编码器负责处理输入数据,解码器则用于生成输出。AI安全智能体平台的训练过程分为预训练和微调两个阶段。预训练阶段在大量文本数据上进行,通过无监督学习任务,如掩码语言建模,使模型能够理解和生成自然语言。微调阶段则在特定任务的数据集上进行,通过有监督学习进一步优化模型在特定任务上的表现。
在处理语言能力方面,AI安全智能体平台通过词嵌入技术将文本转换为向量形式,这些向量能够反映词与词之间的关系和含义。同时,自注意力机制使模型能够理解词在不同上下文中的含义变化,从而生成或理解具有复杂依赖和语义的文本。为了优化模型性能,AI安全智能体平台采用了多种优化和训练技巧,包括损失函数的最小化、正则化技术以防止过拟合,以及使用高级优化器如Adam来提高学习效率。
实践显示,结合静态分析与大模型的语义分析能力,云起软件安全智能体的C/C++测试驱动生成率提升至70%+,代码检测准确率达到60%+,代码修复成功率达到60%+。这些技术和流程的结合,使得软件安全智能体能够高效地提升软件的整体安全性。

在软件测试领域,传统的测试驱动生成方法依赖于人工编写测试用例代码和收集动态运行环境数据,这不仅耗时耗力,而且成本高昂。相比之下,基于大语言模型(LLM-Based)的测试驱动生成方法能够直接从代码和文档中提取信息,生成测试驱动,具有更强的泛化能力和适应性。
谷歌开发了一种基于“提示词与评估框架”的测试驱动生成方法。该方法首先通过OSS-Fuzz和Fuzz introspector工具接收目标代码,进行构建和评估,生成原始编译日志。评估框架从这些日志中提取编译错误信息,并据此生成提示词,然后将这些提示词发送给大语言模型(LLM)。LLM根据这些提示词生成新的Fuzz测试目标,这些目标随后被评估框架接收并进行评估。通过这个循环过程,不断优化和改进Fuzz测试目标,从而提高测试的有效性和覆盖范围。
针对C/C++代码,云起无垠则采用了“微调代码模型+代码详细结构+反馈”的策略来生成测试驱动。首先通过静态分析提取函数信息,并自动提取被测函数相关的头文件、代码、注释、路径等信息,这些信息作为输入被输入到代码安全大模型中生成Fuzz驱动,驱动编译以及测试输出、测试覆盖率等信息又反馈到大模型中,进一步指导请驱动的生成,以提高驱动编译成功率、测试效果和代码覆盖率。
在Google benchmark的31个项目上进行的实验表明,谷歌的生成策略成功生成了14个测试驱动,而云起无垠的策略则成功生成了24个测试驱动,多生成了10个。实验结果表明,基于“微调代码模型+代码详细结构+反馈”的测试驱动生成方法更为有效,能够显著提高测试的效率和质量。
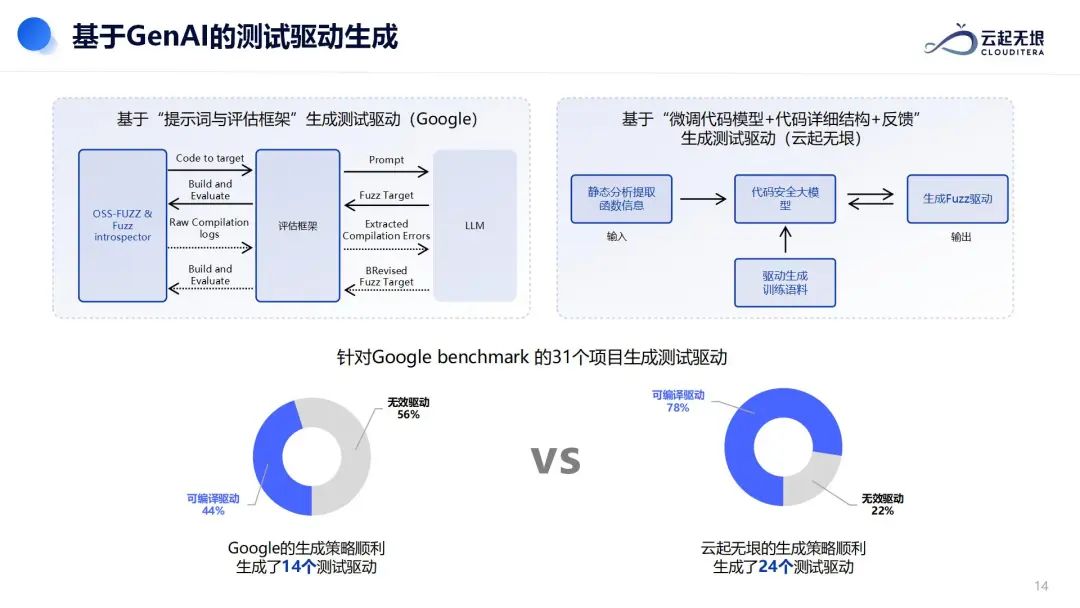
相比传统的静态分析测试驱动生成和代码修复方案,周鹏认为,云起无垠基于大模型的安全检测方案能够更有效地生成测试驱动,并针对安全缺陷进行智能分析与代码修复。
技术展望
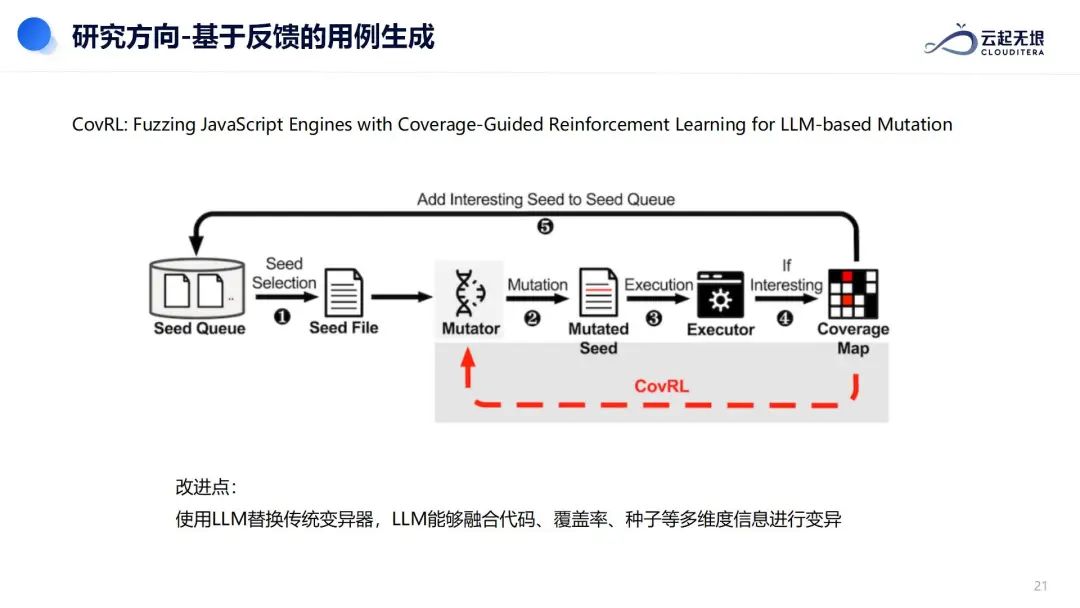
除此之外,周鹏在分享中表示,模糊测试智能体的未来研究方向包括基于反馈的用例生成和基于语法的用例生成。
技术展望一:利用大模型和覆盖引导强化学习,可以提高JavaScript引擎的测试效率和覆盖率。这种方法通过不断地选择、变异、执行、评估,并将新的有趣种子文件加入到队列中,循环迭代来提升测试效果。相比传统变异器,使用大语言模型(LLM)进行变异,可以更智能地融合代码、覆盖率和种子等多维度信息,从而实现更有效的变异过程。
技术展望二:利用大语言模型(LLM)直接从协议文档中学习并生成测试用例的新方法,相比传统需要手工编写模版的方法,通过模型自动生成测试用例,提高了生成的效率和覆盖率。这种新方法通过LLM直接学习协议文档生成测试用例,显著提升了协议模糊测试的效率和准确性。

总结
随着模糊测试技术的发展和大模型技术的不断演进,大模型赋能模糊测试取得了显著成就,进一步提升了模糊测试的自动化和智能化水平。实践表明,模糊测试技术在网络安全领域具有巨大的潜力,为未来技术发展指明了方向。通过持续优化模糊测试技术和结合大模型的智能能力,云起无垠在前沿技术探索上不断取得突破,为提升软件安全性做出了重要贡献。
安全极客是一个致力于信息安全知识共享与交流的专业社区平台,主要围绕GPTSecurity、智能模糊测试、软件供应链安全、红蓝攻防四大主题构建内容分享生态。云起无垠作为联合发起方,欢迎广大安全专家的加入,共同探讨前沿安全技术,促进行业内的知识分享与合作。
