
阅读量:2
目录
前言
该篇笔记主要是为了了解向量数据库的一些优化点,以及其中涉及到知识的学习,重点并不在于介绍腾讯云推出的向量数据库,如果对腾讯云向量数据库感兴趣的小伙伴欢迎去结尾参考文章听公开课并测试使用!
一、RAG介绍
1-0、引言-大语言模型的不足
2023年,大语言模型爆发元年,不管是CloseAI出品的GPT系列模型,还是LLAma系列开源模型、Google的Gemini等模型等,其表现能力都让人叹为观止,大语言模型在自然语言领域的表现都远超以往任何模型。但是大语言模型也存在很多不足:在处理一些专业领域的知识时,会表现出知识缺失,这时候大语言模型可能无法提供准确答案。在解决此类问题时,数据科学家们通常使用的方法是对模型进行微调来适应特定领域的知识,将知识参数化,尽管这种方法取得了卓越的效果,但是其缺点在于成本高昂,需要专业技术知识。
针对大语言模型的另一种解决方案:参数化知识(微调)存在极大局限性,难以保留训练语料库中的所有知识,每一次知识的更新都要消耗大量的计算资源去训练模型。模型参数无法动态更新,参数化知识会随时过时。但是相比较于参数化知识(即通过模型微调来适应专业知识),非参数化知识,即存储在外部的知识源。更加方便、易于扩展。这种方法使得开发人员无需为每一个特定任务重新训练整个庞大的模型。他们可以简单地给模型加上一个知识库,通过这种方式增加模型的信息输入,从而提高回答的精确性。为了融合两种方式的优缺点,模型可以采取半参数化的方法,将非参数化的语料库数据库与参数化模型相结合,这种方法被称为检索增强生成(Retrieval-Augmented Generation, RAG)。
下图为RAG与其他模型优化方法的比较: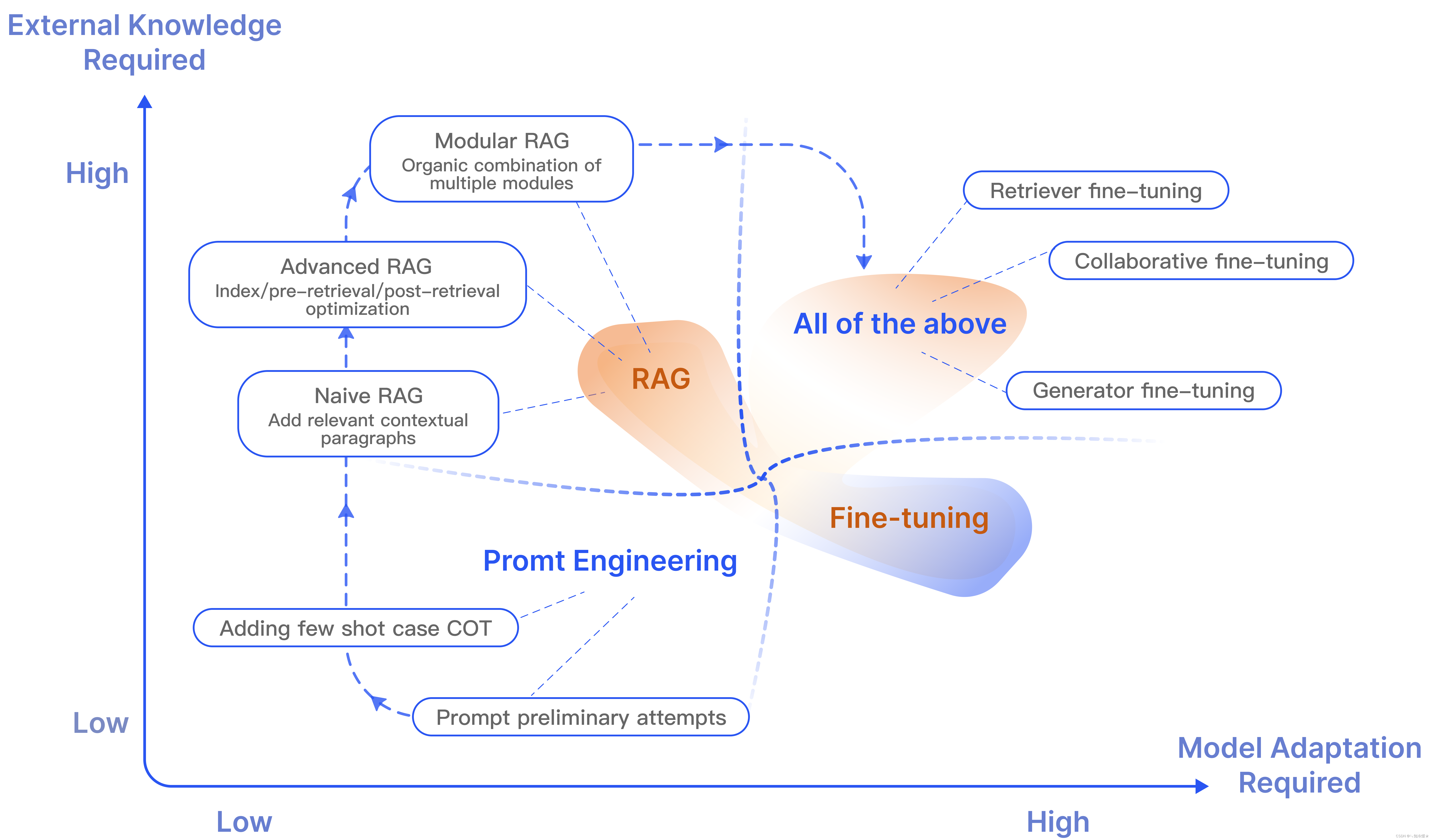
RAG工作流: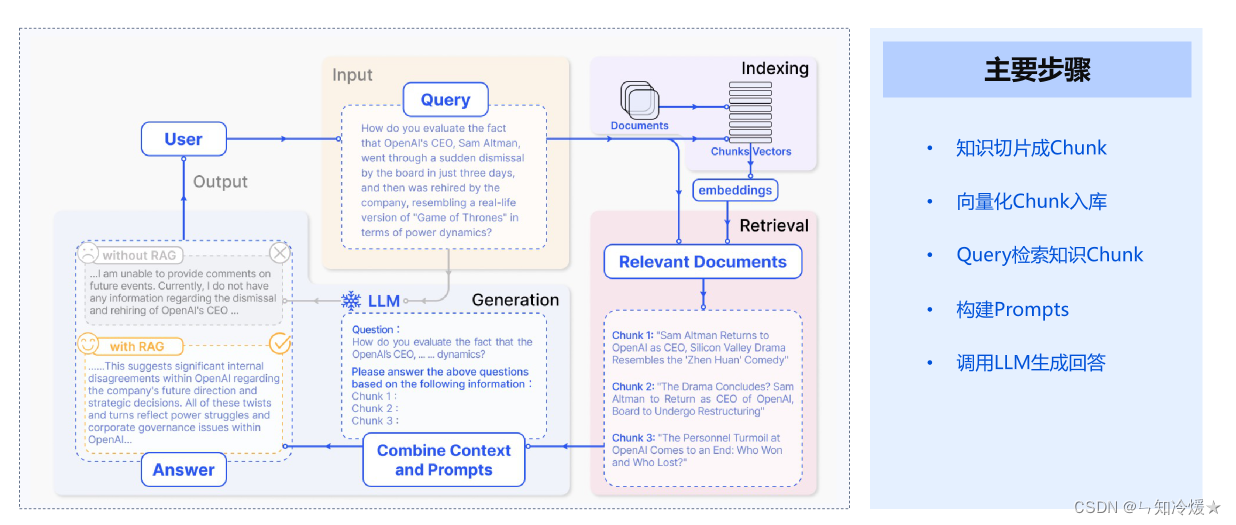
RAG工作流的主要步骤:
- 知识切片成Chunk
- 向量化Chunk入库
- Query检索知识Chunk
- 构建Prompts
- 调用LLM生成回答
以下为LangChain+ChatGLM的一个RAG工作流:
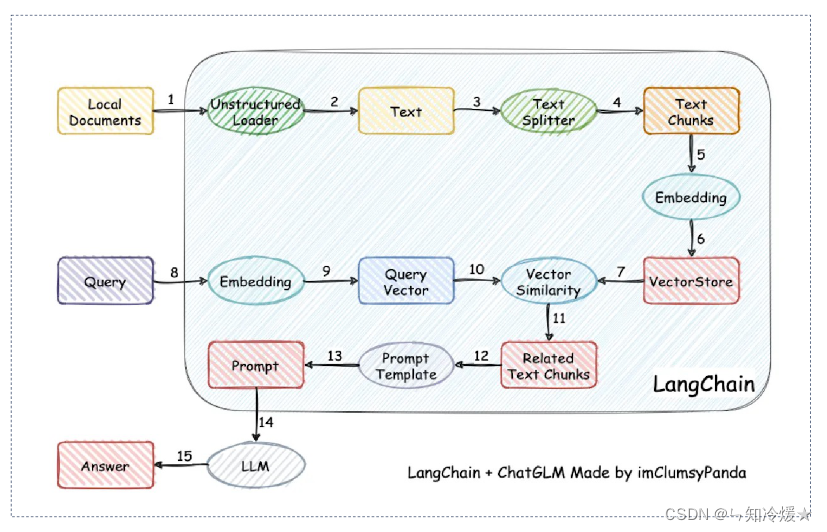
1-1、向量数据库定义
向量数据库: 是一种用于存储和检索以及分析大规模向量数据的数据库系统。它主要应用于图像检索、音频检索、文本检索等领域。向量数据库使用专门的数据结构和算法来处理向量之间的相似性计算和查询,通过构建索引结构,能够快速找到最相似的向量,满足各种应用场景中的查询需求。生成式模型容易产生幻觉,向量数据库可以弥补这一缺陷,为生成式人工智能聊天机器人提供外部知识库,确保提供值得信赖的信息。
1-2、工作原理
工作原理: 在向量数据库中,数据以向量的形式进行存储和处理,因此需要将原始的非向量型数据转化为向量表示。数据向量化是指将非向量型的数据转换为向量形式的过程。通过数据向量化,实现了在向量数据库中进行高效的相似性计算和查询。此外,向量数据库使用不同的检索算法来加速向量相似性搜索,如 KD-Tree、VP-Tree、LSH 以及倒排索引等。在实际应用中,需要根据具体场景进行算法的选择和参数的调优,具体选择哪种算法取决于数据集的特征、数据量和查询需求,以及对搜索准确性和效率的要求。
1-3、优点
优点:
- 相似性搜索: 向量数据库专注于处理向量数据,并采用专门的索引结构和相似性计算算法,能够高效地进行相似性搜索。它能够快速找到最相似的向量,适用于人脸识别、图像搜索、推荐系统等需要相似性匹配的应用。
- 复杂数据支持:向量数据库提供多种数据类型的支持,可通过数据向量化方法转换为向量形式。同时,向量数据库还能够支持各种复杂的查询操作,如范围查询、聚类分析、维度约减等。这使得它在不同应用场景下具备更丰富的数据分析和挖掘能力。
- 机器学习能力:向量数据库通常与机器学习算法和工具集成,能够进行自动的特征提取、聚类分析和分类等任务。它能够支持数据驱动的应用,从数据中学习并提取有价值的信息。例如,向量数据库构建相似度模型,从而实现根据向量之间的相似性度量进行快速的相似性匹配和搜索。
1-4、与传统数据库的区别
- 远超传统关系型数据库的规模:传统的关系型数据库管理1亿条数据已经是拥有很大的业务流量,而在向量数据库需求中,一张表千亿数据是底线,并且原始的向量通常比较大,例如512个float=2k,千亿数据需要保存的向量就需要200T的存储空间(不算多副本),单机显然不具备这种能力,可线性扩展的分布式系统才是正确的道路,这对系统的可扩展性,可靠性,低成本提出非常大的挑战。
- 查询方式不同:传统数据库查询通常为精确查询,结果一般为查到或者未查到,而向量数据库的查询是近似查询,即查找与查询条件相近的结果,所以查询到的结果是与输入条件最为相似的结果,这种查询方式对计算能力有非常高的要求。
- 低延时与高并发:与传统数据库相比,时延大大降低,高并发。
1-5、RAG应用痛点
尽管RAG有很多优点,但是不可避免的,也有很多缺点:
文档处理:
- 如何处理原始数据?
- 如何合理地切分Chunk?
- 如何处理不同格式的文档?
Embedding:
- 如何选择Embedding模型?
- 如何微调?
- Embedding的最佳实践?
Retrieval:
- 如何选择索引和参数?
- 多路召回、Rerank、无效结果处理、MMR?
- 如何处理Chunk上下文?
LLM:
- Prompts
- Query增强改写
- Query意图识别
- 话题切换
- 微调
其他问题:
- 用户的问题在知识库中如果未明确提到,则效果往往不尽如人意。
- 常见专业问题是否有QA文档引导? 在检索用户的问题时是否首先应该进行用户的意图识别?
二、数据处理的难点——解析和拆分
2-1、复杂文档格式-解析过程中的问题
如下图所示:PDF格式多种多样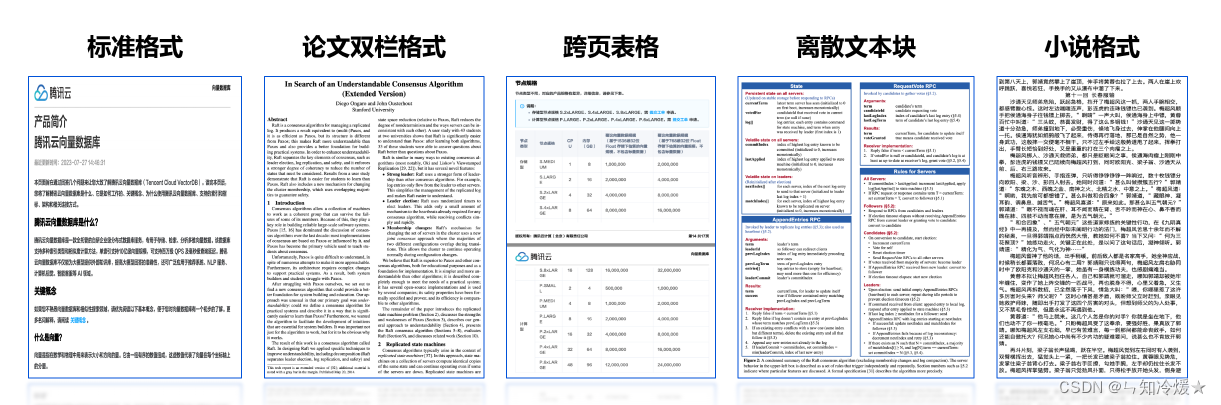
解析过程中容易遇到的问题如下:
内容不完整
- 文档整体内容被截断
- 文档页内部分内容丢失
- 格式无法判断导致缺失
内容错误
- 同页表格/文本/代码混合
- 同页不同段落格式不标准
文档格式多样
- Markdown/Text/JSON
- PDF/Word/PPT
- Image/CAD/Vieo/Audio
边界场景
- 跨页、双栏PDF跨栏
- 表格合并单元格、代码块
2-2、复杂文档解决流程
复杂文档格式解决流程: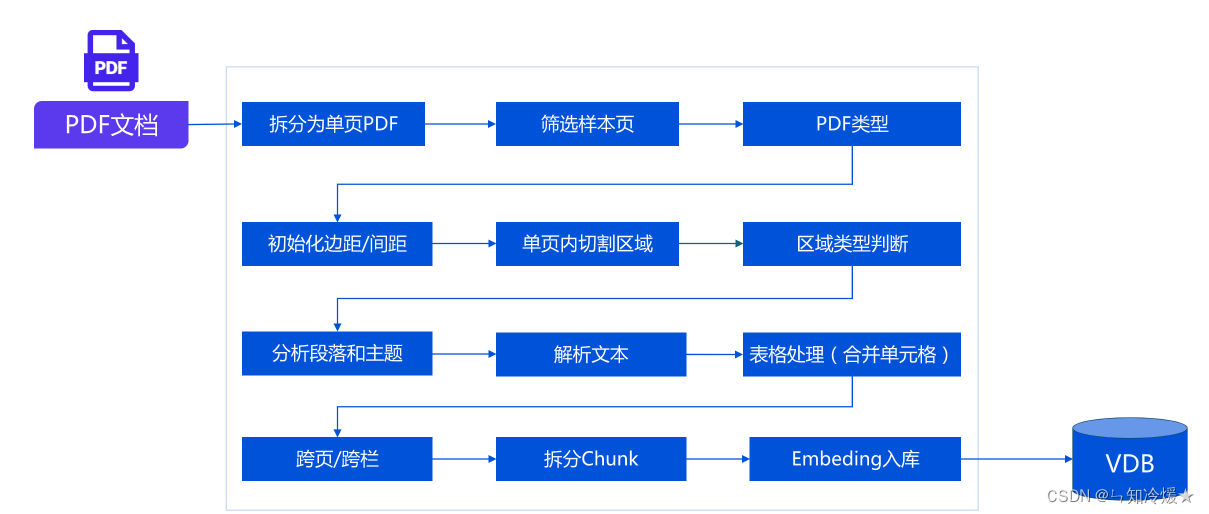
2-3、Chunk拆分的问题以及如何改进
Chunk拆分对最终效果的影响:
改进知识的拆分方案: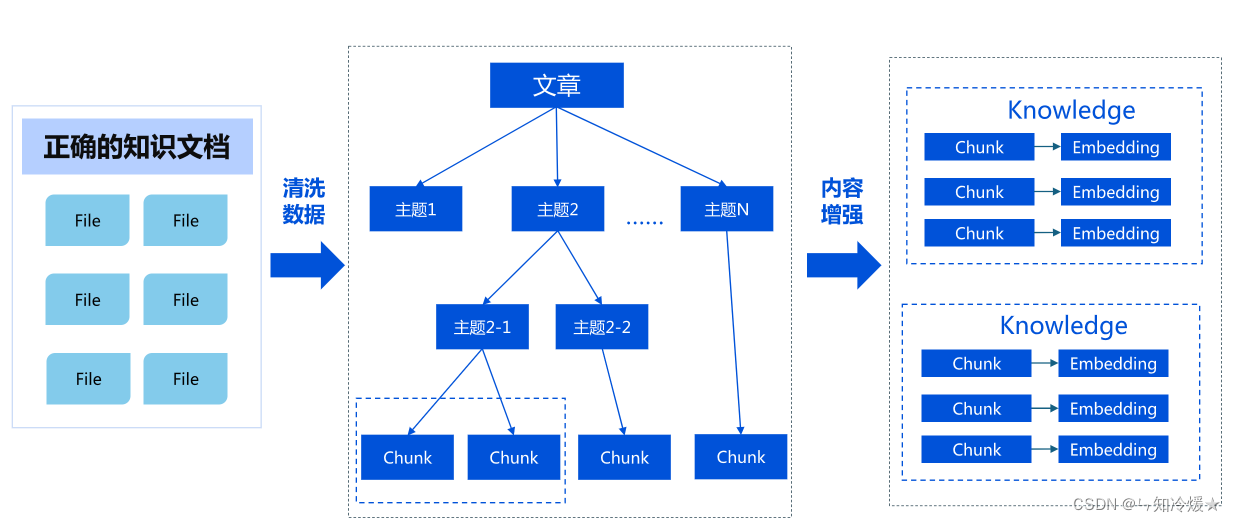
腾讯云向量数据库AI套件解决方案: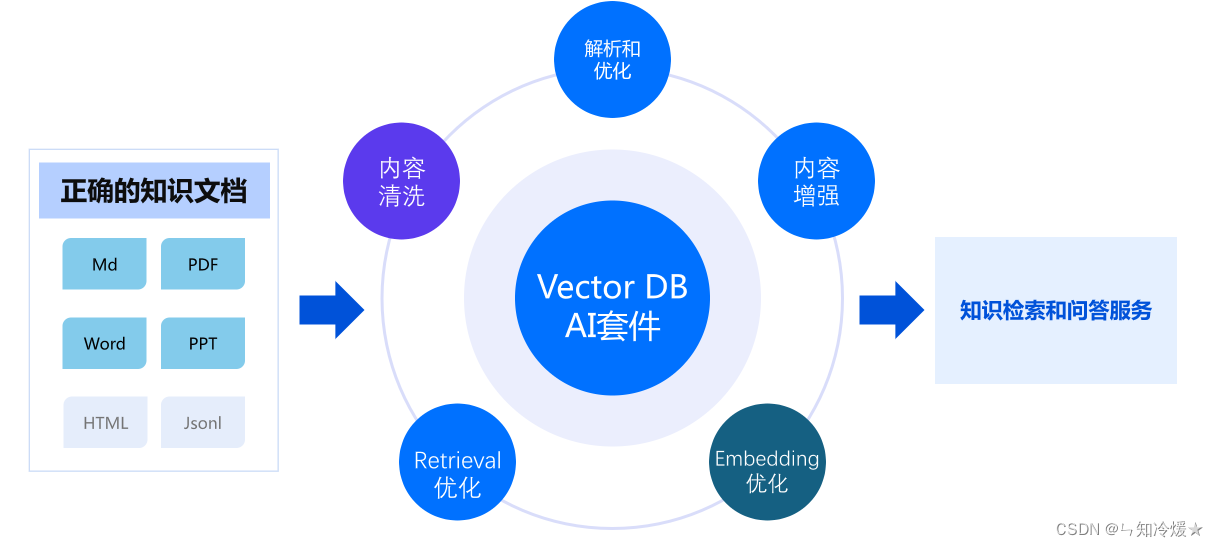
三、相似性检索的关键
3-1、文本Embedding技术
文本嵌入(Text Embedding)技术是自然语言处理(NLP)中的一种重要方法,它将文字转换成为机器学习算法可以理解的数值形式。这种转换通常涉及到将单词、短语或整个文档映射到一个高维空间的向量(即嵌入向量)中。文本嵌入技术背后的核心思想是:将文本编码为一系列数值,这些数值能够捕捉到文本的语义特征,如单词的意义、上下文关系等。
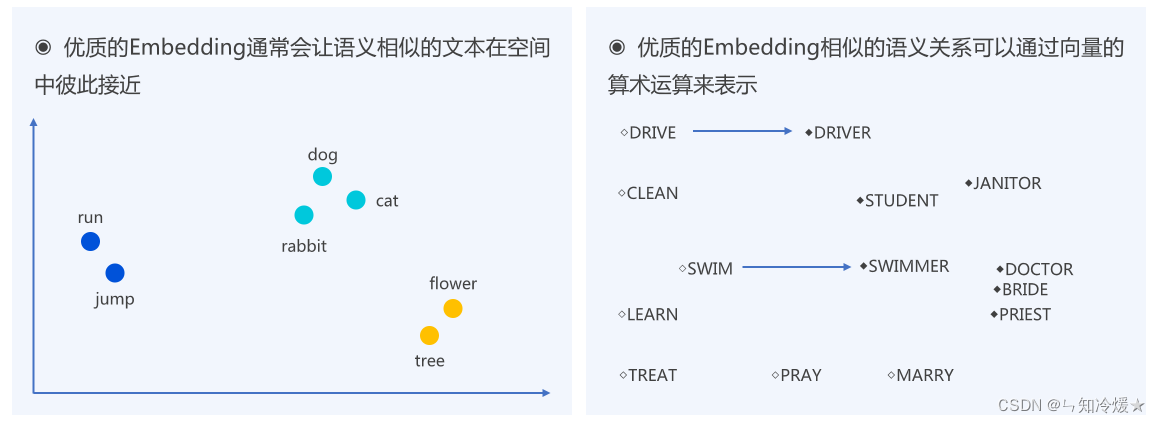
基本原理
在嵌入空间中,语义相似的词语或句子会被映射到距离相近的点上。这种数学表示使得计算机能够处理文本数据,并在此基础上进行机器学习任务,如文本分类、情感分析、语言模型等。
常见的文本嵌入方法
One-hot Encoding:
最简单的文本表示方法,为每个单词分配一个独一无二的索引,并使用一个全部为0且长度等于词汇表大小的向量来表示每个单词,该单词对应的索引位置为1,其余为0。这种方法简单直观,但是它忽略了单词之间的语义关系,并且向量维度随词汇量线性增长,造成维度灾难。TF-IDF(Term Frequency-Inverse Document Frequency):
一种用于信息检索与文本挖掘的常用加权技术。它反映了一个词对于一个文档集或一个语料库中的其中一份文档的重要性。它通过单词在文档中的出现频率和在语料库中的逆文档频率的乘积,来评估单词的重要性。Word2Vec:
Google开发的一种预测模型,用于生成词嵌入。它可以捕捉单词之间的多种语义关系,如语义相似性、类比关系等。Word2Vec有两种主要的训练架构:连续词袋(CBOW)和跳跃-格拉姆(Skip-Gram)。GloVe(Global Vectors for Word Representation):
一种基于全局词频统计的词嵌入技术。与Word2Vec不同,GloVe关注于单词共现(co-occurrence)的全局统计信息,结合了局部上下文窗口和全局统计特性的优点。BERT(Bidirectional Encoder Representations from Transformers):
Google于2018年提出的一种预训练语言表示模型。它通过预训练大量的文本数据来获取深层次的语言理解,然后可以将预训练的模型应用于下游的NLP任务。BERT的创新之处在于使用了双向Transformer,使模型能够更好地理解语言上下文。
3-2、文本Embedding模型的演进
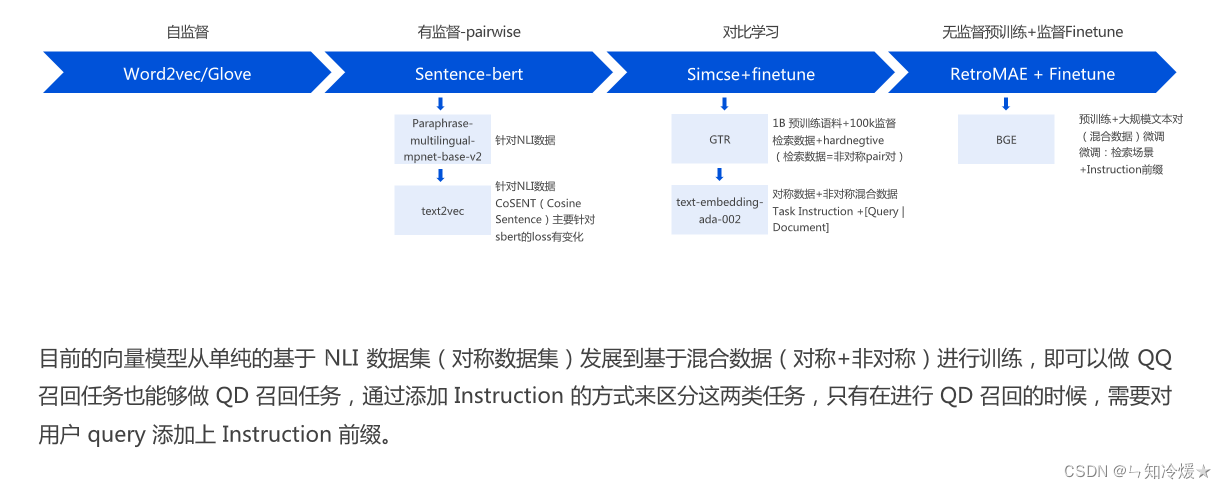
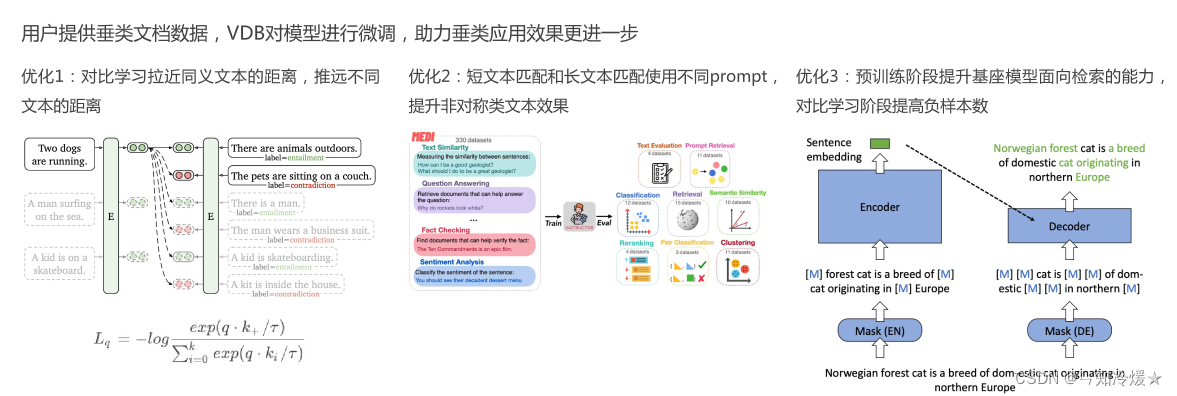
3-3、VDB垂类Embedding模型
四、RAG的核心——结果召回和重排序
4-1、完整RAG检索流程
完整RAG的检索流程如下:
- Query
- Query的预处理:标准化Query,提升检索效果
- 结果召回:从海量数据中找到N条相关数据
- 排序:对N条数据继续缩小数量并根据语义排序
- 检索结果
4-2、Query的预处理
1、意图识别
用户Query—意图识别模型—(LLM直接回答、RAG、诊断回答)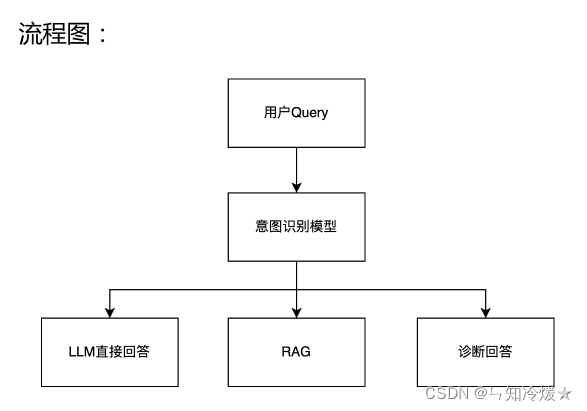
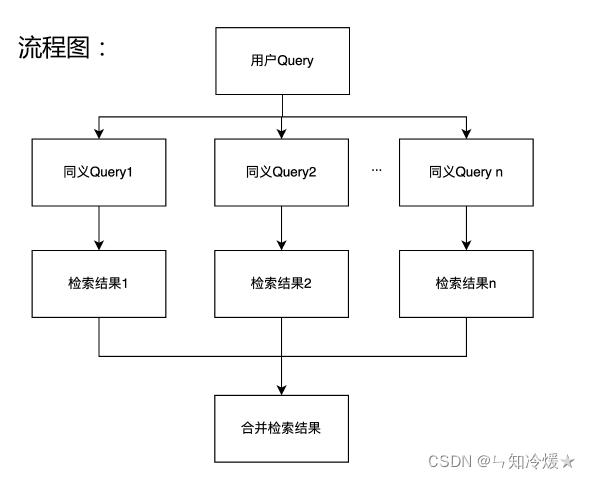
2、生成同义query
针对query生成同义句,不同的问法提高召回,检索结果做合并。
3、Query的标准化
针对query中的专有名词、简写、英文做标准化处理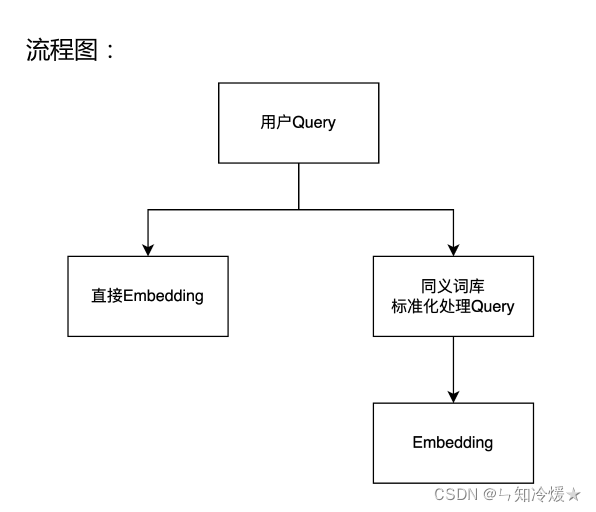
4-3、检索召回

4-4、排序


五、让LLM理解知识——Prompt
5-0、Prompt介绍

以下是几个使用Prompt的简单案例:
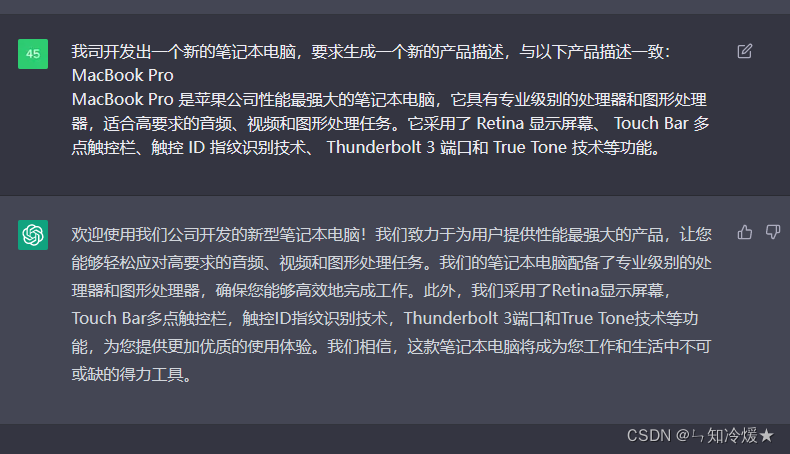
5-1、示例很少、或者没有示例——生成一个手机配置
定义:当特定任务的可用数据有限或任务是新的且定义不明确时,这些技术非常有用。
提示公式: 基于[数字]个案例生成文本
好的,以下是新型智能手机与最新的 iPhone(iPhone 13 Pro Max)的产品比较,基于您提供的信息,这款新型智能手机更为强大: 新型智能手机: 品牌:未知 操作系统:未知,但它可以运行多个操作系统,包括 Android 和 iOS 处理器:最新款的骁龙(Snapdragon)或苹果(Apple)A 系列处理器,比 iPhone 更快 存储容量:512GB 或更多 屏幕尺寸:6.8 英寸或更大,高清分辨率 屏幕分辨率:4000 x 2000 或更高 相机分辨率:48MP 后置相机,20MP 前置相机 电池容量:超过 5000mAh 无线充电:是,支持 Qi 无线充电和反向充电 其他特性:支持 5G、NFC、蓝牙 5.2、Wi-Fi 6E、人脸识别和指纹识别等高级功能 最新的 iPhone(iPhone 13 Pro Max): 品牌:苹果(Apple) 操作系统:iOS 15 处理器:A15 Bionic 存储容量:128GB、256GB、512GB、1TB 屏幕尺寸:6.7 英寸 Super Retina XDR 显示屏 屏幕分辨率:2778 x 1284 相机分辨率:12MP + 12MP + 12MP 后置相机、12MP 前置相机 电池容量:4352mAh 无线充电:是,支持 MagSafe 磁吸无线充电 基于以上规格,可以看出,新型智能手机在多个方面都比 iPhone 更为强大。它可以运行多个操作系统,拥有更快的处理器、更高的存储容量和更大的屏幕尺寸和分辨率。此外,它的相机分辨率更高,电池容量更大,并支持更多的高级功能,如 5G、NFC、蓝牙 5.2、Wi-Fi 6E、人脸识别和指纹识别等。 这项技术可以用于基于模型对任务或者案例的了解来生成文本
5-2、“Let’s think about this” 提示——有关于人工智能未来的探讨
Let’s think about this: 用于鼓励chatGPT生成极具创造性文本的技术,这种方式对于写散文、诗歌创作、或者创意生成等任务很有帮助
提示公式: 让我们想想这个+[主题/问题]
注意:这个提示是就某一个特定主题或者是想法进行探讨,该模型提供了一个对话或者文本生成的起点。
使用该提示的步骤:
1、定义一个你想讨论的主题或者想法
2、指定提示来清楚的陈述主题或者是想法
3、在发起讨论的过程,应该以”让我们思考一下“或者是”让我们讨论一下“作为提示。
5-3、保持一致提示
保持一致提示: 用于确保ChatGPT的输出与提供的输入一致的技术。
提示公式: 在提示中加入”确保与XX一致“
以上简单提到一些提示工程技巧,如果需要了解更多请参考我的另一篇文章:询问ChatGPT的高质量答案艺术——提示工程指南
5-4、Prompt进阶技巧Cot
一种prompt方法,对于复杂问题(尤其是复杂的数学题),大模型很难直接给出正确答案。COT通过要求模型在输出最终答案之前,显式输出中间逐步的推理步骤这一方法来增强大模型的算数、常识和推理能力。简单,但有效。(来源于结尾参考文章)
2022 年,在 Google 发布的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这一系列推理的中间步骤就被称为思维链(Chain of Thought)。区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。如果将使用 CoT 的 Prompt 进行分解,可以更加详细的观察到 CoT 的工作流程。

5-5、优化Prompt

六、向量搜索精度的优化
- 更好的分词分段:优化分词器,尽可能的保障每组数据的完整性。(当一段话的结构和语义是完整的,并且是单一的,那么搜索精度自然会提高)
- 精简Index的内容:减少向量内容的长度,当index的内容更少时,更准确时,搜索的精度自然会提高。但是与此同时,会牺牲一定的检索范围,适合答案较为严格的场景。
- 丰富index的数量: 可以为同一个chunk内容增加多组index,增加命中率。
- 优化检索词:在实际使用中,用户的问题通常是模糊的或者是缺失的,并不一定是完整清晰的问题。因此优化用户的问题(检索词)很大程度上也可以提高精度。
- 微调向量模型:由于市面上直接使用的向量模型都是通用型模型,在特定领域的检索精度并不高,因此微调向量模型可以很大程度上提高专业领域的检索效果。
- 知识库构建: 最有效的知识库构建方式是QA和手动构建。(并且Q的长度不宜过长)
参考文章:
课程学习入口.
一文读懂:大模型思维链 CoT(Chain of Thought)
RAG行业交流中发现的一些问题和改进方法
大模型RAG 场景、数据、应用难点与解决(四)
对于大模型RAG技术的一些思考
基于 Langchain 框架,分享3个提升大模型 RAG 检索效果的方法
LLM+Embedding构建问答系统的局限性及优化方案
Text-To-SQL:
大模型与数据科学:从Text-to-SQL 开始(一)
大模型+知识库/数据库问答实践过程的经验汇总(三)
总结
知识太多了,根本学不完啊学不完!😒😒😒
