阅读量:6
在机器学习领域,寻找最优模型参数是一个重要的步骤,它直接影响模型的泛化能力和预测准确性。本文将通过一个具体案例介绍如何使用支持向量机(SVM)和网格搜索(GridSearchCV)来预测学生的成绩,并通过调整参数来优化模型性能。
数据集:公众号“码银学编程”后台回复:学生成绩-SVM
引言
学生的成绩预测对于教育领域来说是一个重要的问题,它可以帮助教师更好地了解学生的学习情况,从而进行针对性的教学改进。在本案例中,我们将使用 SVM 作为分类器,并利用 GridSearchCV 对模型参数进行调优,以期获得更好的预测效果。
正文
1. 数据准备
首先,我们从 CSV 文件中加载学生成绩数据集。数据集包含了多门课程的成绩,我们将这些成绩转换为等级,并使用 LabelEncoder 将分类数据转换为数值形式,以便 SVM 模型能够处理。
stu_grade = pd.read_csv('student-mat.csv') print(stu_grade.head())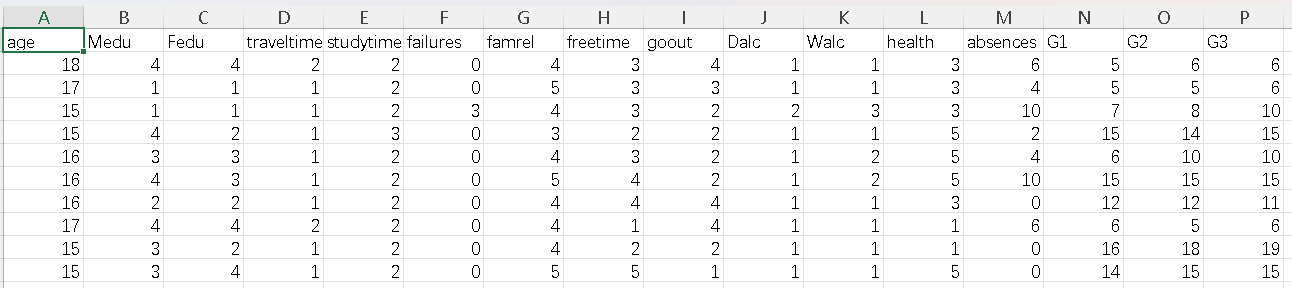
- age-学生年龄(数字:从15岁到22岁)
- Medu - 母亲教育(数字:0 -无,1 -小学教育(四年级),2 -" 5 - 9年级,3 -"中等教育或,4 -"高等教育)
- Fedu - 父亲教育(数字:0 -无,1 -小学教育(4年级),2 â€" 5 - 9年级,3 â€"中等教育或4 â€"高等教育)
- traveltime - 从家到学校的旅行时间(数字:1 - <15分钟,2 - 15 - 30分钟,3 - 30分钟到1小时,或4 - >1小时)
- studytime - 每周学习时间(数字:1 - <2小时,2 - 2 - 5小时,3 - 5 - 10小时,或4 - >10小时)
- failures - 过去班级失败的次数(数值:如果1<=n<3,则为n,否则为4)
- famrel - 家庭关系质量(数字:1 -非常差到5 -极好)
- freetime - 放学后的空闲时间(数字:从1 -非常少到5 -非常多)
- goout - 和朋友出去(数字:从1 -非常低到5 -非常高)
- Dalc - 工作日酒精消耗量(数字:1 -极低至5 -极高)
- Walc - 周末饮酒(数字:1 -极低至5 -极高)
- health - 当前健康状况(数字:从1-非常差到5-非常好)
- absences - 学校缺勤次数(数字:从0到93)
- G1 -第一阶段等级(数字:从0到20)
- G2 -第二阶段等级(数字:从0到20)
- G3 -最终等级(数字:从0到20,输出目标)
2. 模型选择与训练
SVM 是一种强大的分类算法,适用于各种类型的数据。在本案例中,我们选择了 SVC 类,它实现了支持向量分类算法。模型训练前,我们通过 train_test_split 将数据集划分为训练集和测试集。
X_train, X_test, Y_train, Y_test = train_test_split(stu_data.drop('G3', axis=1), # 特征 stu_data['G3'], # 目标变量 test_size=0.3, random_state=5) svm_model = SVC(random_state=6) # 训练模型 svm_model.fit(X_train, Y_train) # 使用训练好的模型进行预测 Y_pred = svm_model.predict(X_test) print(Y_pred)3. 模型评估
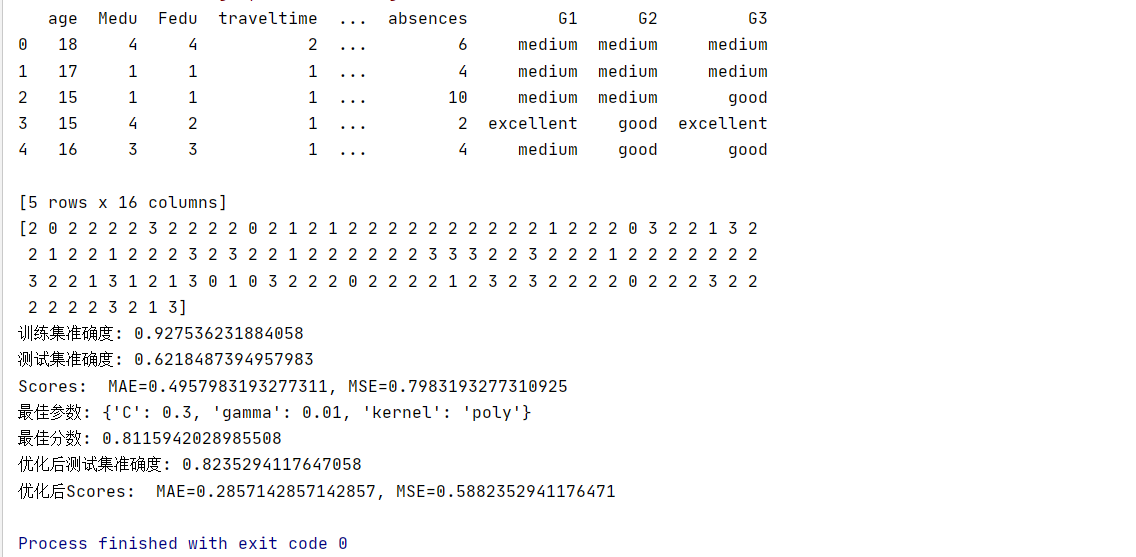
在初始模型训练完成后,我们使用准确度(accuracy_score)和均方误差(mean_squared_error, MSE)来评估模型性能。准确度是衡量分类模型性能的常用指标,而 MSE 则提供了模型预测值与实际值之间差异的量化度量。
A = mean_absolute_error(Y_test, Y_pred) S = mean_squared_error(Y_test, Y_pred) # 输出训练集和测试集的分数 print("训练集准确度:", accuracy_score(Y_train, svm_model.predict(X_train))) print("测试集准确度:", accuracy_score(Y_test, Y_pred)) print(f"Scores: MAE={A}, MSE={S}")4. 参数调优
为了进一步提升模型性能,我们采用了 GridSearchCV 进行参数调优。GridSearchCV 是 scikit-learn 提供的一个工具,它通过遍历给定的参数网格,使用交叉验证来寻找最佳的参数组合。在本案例中,我们调整了 SVM 的 `C`、`gamma` 和 `kernel` 参数。
# 参数网格,用于GridSearchCV寻找最佳参数 param_grid = { 'C': [0.01, 0.1, 0.2 , 0.3 , 0.4 , 0.5, 1, 10], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf', 'poly', 'sigmoid'] } # 创建GridSearchCV实例 grid_search = GridSearchCV(estimator=svm_model, param_grid=param_grid, cv=5, return_train_score=True)5. 最佳模型选择
经过 GridSearchCV 的搜索,我们得到了最佳的参数组合,并使用这些参数重新训练了 SVM 模型。再次使用准确度和 MSE 对优化后的模型进行评估,以验证参数调优的效果。
# 执行网格搜索找到最佳参数 grid_search.fit(X_train, Y_train) # 输出最佳参数和对应的最佳分数 print("最佳参数:", grid_search.best_params_) print("最佳分数:", grid_search.best_score_) # 使用最佳参数创建新的SVM模型 best_svm_model = grid_search.best_estimator_ # 使用最佳模型进行预测 best_Y_pred = best_svm_model.predict(X_test) # 计算并输出最佳模型的测试集准确度 print("优化后测试集准确度:", accuracy_score(Y_test, best_Y_pred)) MAE = mean_absolute_error(Y_test, best_Y_pred) MSE = mean_squared_error(Y_test, best_Y_pred) print(f"优化后Scores: MAE={MAE}, MSE={MSE}")6. 结果分析
通过比较优化前后的模型性能,我们可以得出参数调优是否有效的结论。在本案例中,我们发现通过调整参数,模型的准确度和 MSE 都有所改善,这表明 GridSearchCV 是一个有效的工具,可以帮助我们找到更好的模型参数。
小结
本案例展示了如何使用 SVM 和 GridSearchCV 对学生成绩进行预测,并优化模型参数。通过实验,我们证明了参数调优对于提升模型性能的重要性。
尽管本案例取得了一定的成果,但仍有改进的空间。例如,可以尝试更多的机器学习算法,或者使用更复杂的特征工程技术来进一步提升模型性能。此外,对于数据集的深入分析,如探索不同课程成绩之间的关联,也可能是一个有价值的研究方向。
参考文章
完整代码与运行结果
import pandas as pd from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.svm import SVC from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from sklearn.metrics import mean_absolute_error, mean_squared_error import warnings # 忽略警告 warnings.filterwarnings("ignore", category=DeprecationWarning) # 读取数据集 stu_grade = pd.read_csv('student.csv') print(stu_grade.head()) # 特征选取 new_data = stu_grade.iloc[:, :] #所有的行和列 print(new_data.head()) # 将成绩转换为等级 def convert(x): x = int(x) if x < 5: return 'bad' elif x >= 5 and x < 10: return 'medium' elif x >= 10 and x < 15: return 'good' else: return 'excellent' stu_data = new_data.copy() stu_data['G1'] = stu_data['G1'].map(lambda x: convert(x)) stu_data['G2'] = stu_data['G2'].map(lambda x: convert(x)) stu_data['G3'] = stu_data['G3'].map(lambda x: convert(x)) print(stu_data.head()) # 将分类特征转换为数值形式 label_encoders = {} for column in ['G1', 'G2', 'G3']: le = LabelEncoder() stu_data[column] = le.fit_transform(stu_data[column]) label_encoders[column] = le # 划分训练集和测试集 X_train, X_test, Y_train, Y_test = train_test_split(stu_data.drop('G3', axis=1), # 特征 stu_data['G3'], # 目标变量 test_size=0.3, random_state=5) # 创建SVM模型实例 svm_model = SVC(random_state=6) # 训练模型 svm_model.fit(X_train, Y_train) # 使用训练好的模型进行预测 Y_pred = svm_model.predict(X_test) print(Y_pred) A = mean_absolute_error(Y_test, Y_pred) S = mean_squared_error(Y_test, Y_pred) # 输出训练集和测试集的分数 print("训练集准确度:", accuracy_score(Y_train, svm_model.predict(X_train))) print("测试集准确度:", accuracy_score(Y_test, Y_pred)) print(f"Scores: MAE={A}, MSE={S}") # 参数网格,用于GridSearchCV寻找最佳参数 param_grid = { 'C': [0.01, 0.1, 0.2 , 0.3 , 0.4 , 0.5, 1, 10], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf', 'poly', 'sigmoid'] } # 创建GridSearchCV实例 grid_search = GridSearchCV(estimator=svm_model, param_grid=param_grid, cv=5, return_train_score=True) # 执行网格搜索找到最佳参数 grid_search.fit(X_train, Y_train) # 输出最佳参数和对应的最佳分数 print("最佳参数:", grid_search.best_params_) print("最佳分数:", grid_search.best_score_) # 使用最佳参数创建新的SVM模型 best_svm_model = grid_search.best_estimator_ # 使用最佳模型进行预测 best_Y_pred = best_svm_model.predict(X_test) # 计算并输出最佳模型的测试集准确度 print("优化后测试集准确度:", accuracy_score(Y_test, best_Y_pred)) MAE = mean_absolute_error(Y_test, best_Y_pred) MSE = mean_squared_error(Y_test, best_Y_pred) print(f"优化后Scores: MAE={MAE}, MSE={MSE}") 结果:
age Medu Fedu traveltime studytime ... health absences G1 G2 G3 0 18 4 4 2 2 ... 3 6 5 6 6 1 17 1 1 1 2 ... 3 4 5 5 6 2 15 1 1 1 2 ... 3 10 7 8 10 3 15 4 2 1 3 ... 5 2 15 14 15 4 16 3 3 1 2 ... 5 4 6 10 10 [5 rows x 16 columns] age Medu Fedu traveltime studytime ... health absences G1 G2 G3 0 18 4 4 2 2 ... 3 6 5 6 6 1 17 1 1 1 2 ... 3 4 5 5 6 2 15 1 1 1 2 ... 3 10 7 8 10 3 15 4 2 1 3 ... 5 2 15 14 15 4 16 3 3 1 2 ... 5 4 6 10 10 [5 rows x 16 columns] age Medu Fedu traveltime ... absences G1 G2 G3 0 18 4 4 2 ... 6 medium medium medium 1 17 1 1 1 ... 4 medium medium medium 2 15 1 1 1 ... 10 medium medium good 3 15 4 2 1 ... 2 excellent good excellent 4 16 3 3 1 ... 4 medium good good [5 rows x 16 columns] [2 0 2 2 2 2 3 2 2 2 2 0 2 1 2 1 2 2 2 2 2 2 2 2 2 2 1 2 2 2 0 3 2 2 1 3 2 2 1 2 2 1 2 2 2 3 2 3 2 2 1 2 2 2 2 2 2 3 3 3 2 2 3 2 2 2 1 2 2 2 2 2 2 2 3 2 2 1 3 1 2 1 3 0 1 0 3 2 2 2 0 2 2 2 2 1 2 3 2 3 2 2 2 2 0 2 2 2 3 2 2 2 2 2 2 3 2 1 3] 训练集准确度: 0.927536231884058 测试集准确度: 0.6218487394957983 Scores: MAE=0.4957983193277311, MSE=0.7983193277310925 最佳参数: {'C': 0.3, 'gamma': 0.01, 'kernel': 'poly'} 最佳分数: 0.8115942028985508 优化后测试集准确度: 0.8235294117647058 优化后Scores: MAE=0.2857142857142857, MSE=0.5882352941176471 Process finished with exit code 0