
阅读量:0
文章目录
- 基础命令
基础命令
MYSQL注释方式
-- 单行注释 /* 多行注释 哈哈哈哈哈 哈哈哈哈 */ 数据库连接
连接数据库
mysql -u root -p12345678 ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LCyXjZE5-1688559235379)(assets/1688556594985-16.png)]](/zb_users/upload/2024/csdn/4a2507a359044d4bac33db66d155b4ea.png)
退出数据库连接
使用exit;命令可以退出连接
修改用户密码

查询MYSQL版本
mysql> select version(); +-----------+ | version() | +-----------+ | 8.0.27 | +-----------+ 1 row in set (0.00 sec) 查看所有数据库
show databases; ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BrfI5JJ0-1688559235380)(assets/1688556594986-18.png)]](/zb_users/upload/2024/csdn/c179e81ad1eb4b17a2caaf816d1468fa.png)
使用数据库
如果想要操作数据库,需要使用use 数据库名;来选择要操作的数据库
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c1Bc6SSg-1688559235381)(assets/1688556594986-19.png)]](/zb_users/upload/2024/csdn/29f9de5125144c578cc2564cf99b506a.png)
查看所选择数据库的所有表
show tables; ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YjMDbbYV-1688559235381)(assets/1688556594986-20.png)]](/zb_users/upload/2024/csdn/9f7c7951e8a94c2e960cd4316a30c772.png)
查看表的具体信息
使用describe 表名;可以查看表中的字段信息
mysql> describe user; +--------------+---------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type | Null | Key | Default | Extra | +--------------+---------------+------+-----+-------------------+-----------------------------------------------+ | id | bigint | NO | PRI | NULL | auto_increment | | userName | varchar(256) | YES | | NULL | | | userAccount | varchar(256) | NO | UNI | NULL | | | userAvatar | varchar(1024) | YES | | NULL | | | gender | tinyint | YES | | NULL | | | userRole | varchar(256) | NO | | user | | | userPassword | varchar(512) | NO | | NULL | | | accessKey | varchar(512) | YES | | NULL | | | secretKey | varchar(512) | YES | | NULL | | | createTime | datetime | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED | | updateTime | datetime | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP | | isDelete | tinyint | NO | | 0 | | +--------------+---------------+------+-----+-------------------+-----------------------------------------------+ 12 rows in set (0.00 sec) 创建数据库
create database [if not exists] 数据库名称 character set 字符编码; mysql> create database practice character set utf8; Query OK, 1 row affected, 1 warning (0.01 sec) -- 已存在的数据库不能重复创建,不然会报错 mysql> create database practice character set utf8; ERROR 1007 (HY000): Can't create database 'practice'; database exists -- 使用if not exists,可以判断数据库不存在的时候才创建数据库,这样就不会报错 mysql> create database if not exists practice character set utf8; Query OK, 1 row affected, 2 warnings (0.01 sec) 如果数据库名字有短横杆,用``包住,不然可能会报错
create database `second-hand-market` character set utf8mb4; 查看创建数据库的语句
mysql> show create database practice; +----------+------------------------------------------------------------------------------------------------------+ | Database | Create Database | +----------+------------------------------------------------------------------------------------------------------+ | practice | CREATE DATABASE `practice` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */ | +----------+------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) 数据表管理
创建数据表
CREATE TABLE [IF NOT EXISTS] `表名`( '字段名'列类型[属性][索引][注释], '字段名'列类型[属性][索引][注释], '字段名'列类型[属性][索引][注释] )[表类型][字符集设置][注释] 如:
CREATE TABLE IF NOT EXISTS `student` ( `id` BIGINT NOT NULL auto_increment COMMENT '学号' PRIMARY KEY, `name` VARCHAR ( 30 ) NOT NULL DEFAULT '匿名' COMMENT '姓名' ) COMMENT '学生表' 字段类型
| 字段类型 | 描述 | 示例值 | 存储字节数 |
|---|---|---|---|
TINYINT | 小整型,有符号或无符号,通常用于存储小范围的整数值。 | -128 到 127 或 0 到 255 | 1 |
SMALLINT | 中整型,有符号或无符号,适用于存储中等范围的整数值。 | -32768 到 32767 或 0 到 65535 | 2 |
MEDIUMINT | 中等大小的整型,有符号或无符号。 | -8388608 到 8388607 或 0 到 16777215 | 3 |
INT / INTEGER | 标准整型,有符号或无符号,适用于大多数整数场景。 | -2147483648 到 2147483647 或 0 到 4294967295 | 4 |
BIGINT | 大整型,有符号或无符号,适用于需要存储非常大数字的情况。 | -9223372036854775808 到 9223372036854775807 或 0 到 18446744073709551615 | 8 |
FLOAT | 单精度浮点数,用于存储实数。 | 3.14, -123.45 | 4 |
DOUBLE | 双精度浮点数,提供比FLOAT更高的精度。 | 3.1415926535, -123456.789 | 8 |
DECIMAL | 定点数,用于存储精确的数值,如货币金额。 | 1234.56, -789.01 | 可变(取决于精度和标度) |
CHAR | 固定长度的字符串类型。 | 'hello' | 可变(取决于定义长度) |
VARCHAR | 可变长度的字符串类型。 | 'hello world' | 可变(取决于实际存储的字符数量) |
DATE | 日期类型,格式为 YYYY-MM-DD。 | '2023-03-01' | 3 |
TIME | 时间类型,格式为 HH:MM:SS。 | '12:34:56' | 3 |
DATETIME | 日期和时间组合类型。 | '2023-03-01 12:34:56' | 8 |
TIMESTAMP | 日期和时间类型,自动维护当前时间戳。 | '2023-03-01 12:34:56' | 4 |
TINYBLOB | 用于存储较小的二进制数据,最大长度为 255 字节。 | 图片缩略图,短音频片段 | 数据长度 + 1 |
BLOB | 用于存储中等大小的二进制数据,最大长度为 65,535 字节。 | 中等大小的图片,文档 | 数据长度 + 2 |
MEDIUMBLOB | 用于存储较大的二进制数据,最大长度为 16MB。 | 较大的图片,较长的音频或视频剪辑 | 数据长度 + 3 |
LONGBLOB | 用于存储非常大的二进制数据,最大长度为 4GB。 | 高清图片,完整的音频或视频文件 | 数据长度 + 4 |
TINYTEXT | 用于存储较小的文本数据,最大长度为 255 字符。 | 短文本消息,注释或标签 | 数据长度 + 1 |
TEXT | 用于存储中等大小的文本数据,最大长度为 65,535 字符。 | 长文本消息,文章摘要 | 数据长度 + 2 |
MEDIUMTEXT | 用于存储较大的文本数据,最大长度为 16MB。 | 长篇文章,用户评论或论坛帖子 | 数据长度 + 3 |
LONGTEXT | 用于存储非常大的文本数据,最大长度为 4GB。 | 长篇小说,大数据量的文本信息 | 数据长度 + 4 |
BOOLEAN / BOOL | 布尔类型,表示真或假。 | TRUE, FALSE | 1 |
ENUM | 枚举类型,允许在列表中选择一个值。 | 'apple', 'orange' | 可变 |
SET | 集合类型,允许在列表中选择多个值。 | 'apple, orange' | 可变 |
请注意,BLOB、TEXT、CHAR 和 VARCHAR 的实际存储大小会根据存储的数据量而变化,但它们的最大容量是固定的。例如,VARCHAR 的最大长度为 65,535 字符,而 BLOB 和 TEXT 类型的最大大小则更大。此外,DECIMAL 类型的存储大小取决于其定义的精度和标度。
数据约束
在MySQL中创建表或修改表时,可以应用多种数据约束以确保数据的完整性和一致性。以下是常见的数据约束类型:
主键约束(PRIMARY KEY):
- 指定一个或一组字段作为主键,用于唯一标识表中的每一行记录。
- 主键字段不允许有重复值,并且不能为NULL。
唯一约束(UNIQUE):
- 确保指定的字段或字段组合的值在表中是唯一的。
- 可以允许NULL值,但NULL值不会被视为重复。
非空约束(NOT NULL):
- 指定字段不能接受NULL值。
- 强制字段在插入新记录时必须提供值。
默认约束(DEFAULT):
- 为字段设定一个默认值,如果在插入新记录时未提供该字段的值,则自动使用默认值。
外键约束(FOREIGN KEY):
- 用于维护两个表之间的关系,确保外键字段的值与参照表的主键或唯一键相匹配。
- 外键可以防止删除或更改被其他表引用的记录。
检查约束(CHECK):
- MySQL直到版本8.0.16才引入了对检查约束的支持,但其功能可能有限。
- 用于定义字段值必须满足的条件。
除了这些标准的SQL约束,MySQL还支持一些额外的功能,如自增(AUTO_INCREMENT)和生成表达式列(GENERATED COLUMNS),虽然它们不是传统意义上的约束,但它们可以帮助维护数据的完整性。一个使用上述约束的建表sql如下:
-- 创建一个包含各种约束的用户表 CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, -- 主键约束 email VARCHAR(255) UNIQUE NOT NULL, -- 唯一约束和非空约束 password VARCHAR(255) NOT NULL, -- 非空约束 age TINYINT UNSIGNED CHECK (age >= 18 AND age <= 120), -- 检查约束,MySQL 8.0.16及以上支持 registration_date DATE DEFAULT CURRENT_DATE, -- 默认约束 address VARCHAR(255), gender ENUM('male', 'female') DEFAULT 'male', -- 本质上也是一种默认约束 FOREIGN KEY (address) REFERENCES addresses(address_id) -- 外键约束 ); 查看创建数据表的语句
mysql> use practice; Database changed mysql> show create table student; +---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Table | Create Table |+---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| student | CREATE TABLE `student` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '学号', `name` varchar(30) NOT NULL DEFAULT '匿名' COMMENT '姓名', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='学生表' | +---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec) 查看表的结构
mysql> desc student; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | +-------+-------------+------+-----+---------+----------------+ 2 rows in set (0.00 sec) 修改表
修改表名
alter table 旧表名 rename as 新表名;
mysql> alter table student rename as teacher; Query OK, 0 rows affected (0.02 sec) 在MySQL中,你可以使用ALTER TABLE语句来修改现有表的结构。这包括向表中添加字段、修改字段的类型以及删除字段。下面是这些操作的SQL语法以及一些示例:
给指定表增加字段
alter table 表名 add 字段名 列属性;
mysql> alter table teacher add gender bigint; Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc teacher; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | gender | bigint | YES | | NULL | | +--------+-------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec) mysql> alter table teacher add age int(11); Query OK, 0 rows affected, 1 warning (0.02 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> desc teacher; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | gender | bigint | YES | | NULL | | | age | int | YES | | NULL | | +--------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) 修改指定表的字段
修改列属性
alter table 表名 modify 字段名 列属性;
mysql> alter table teacher modify age varchar(11); Query OK, 0 rows affected (0.07 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc teacher; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | gender | bigint | YES | | NULL | | | age | varchar(11) | YES | | NULL | | +--------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) 同时修改字段名和字段属性
alter table 表名 change 旧字段名 新字段名 列属性;
mysql> desc teacher; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | gender | bigint | YES | | NULL | | | age | varchar(11) | YES | | NULL | | +--------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) mysql> alter table teacher change age age1 int(2); Query OK, 0 rows affected, 1 warning (0.07 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> desc teacher; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | gender | bigint | YES | | NULL | | | age1 | int | YES | | NULL | | +--------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) 删除指定表的字段
mysql> desc teacher; +--------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | gender | bigint | YES | | NULL | | | age1 | int | YES | | NULL | | +--------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) mysql> alter table teacher drop gender; Query OK, 0 rows affected (0.06 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc teacher; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | age1 | int | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec) 删除表
语法如下:
drop table [if exists] 表名; [测试]
mysql> show tables; +--------------------+ | Tables_in_practice | +--------------------+ | teacher | +--------------------+ 1 row in set (0.00 sec) mysql> drop table if exists teacher; Query OK, 0 rows affected (0.02 sec) mysql> show tables; Empty set (0.00 sec) 给表添加外键
创建表的时候增加外键
-- 创建专业表 CREATE TABLE IF NOT EXISTS `major` ( `id` BIGINT NOT NULL auto_increment COMMENT '专业id' PRIMARY KEY, `name` VARCHAR ( 30 ) NOT NULL COMMENT '专业名称' ) COMMENT '专业表' -- 创建学生表,并将学生表的major_id声明为外键,引用专业表的id字段 CREATE TABLE IF NOT EXISTS `student` ( `id` BIGINT NOT NULL auto_increment COMMENT '学号' PRIMARY KEY, `name` VARCHAR ( 30 ) NOT NULL DEFAULT '匿名' COMMENT '姓名', `major_id` BIGINT NOT NULL COMMENT '专业id', key `FK_majorId` (`major_id`), CONSTRAINT `FK_majorId` FOREIGN KEY (`major_id`) REFERENCES `major`(`id`) ) COMMENT '学生表' ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gA063Sls-1688559235382)(assets/1688556594986-23.png)]](/zb_users/upload/2024/csdn/2f8897ec9bb9489ea3277378318564a4.png)
给已有表添加外键
ALTER TABLE 表名 ADD CONSTRAINT 约束名 FOREIGN KEY(作为外键的列的字段名) REFERENCES 引用哪个表(哪个字段) 【案例】
ALTER TABLE `student` ADD CONSTRAINT `FK_majorId` FOREIGN KEY(`major_id`) REFERENCES `major`(`id`); 外键使用建议
当使用了外键时,如果需要删除被引用表的记录,需要先删除引用表的记录。如上面的例子所示,如果需要删除一个专业,需要先删除这个专业所对应的学生。
建议:使用外键约束会让开发者很痛苦,测试数据不方便,建议不使用外键
INSERT 数据插入语句
数据插入
insert into `表名` (`字段名1`,`字段名2`) values('字段值1','字段值2'); 一次性插入多条数据
insert into `表名` (`字段名1`,`字段名2`) values('字段值11','字段值12'),('字段值21','字段值22'),('字段值31','字段值32'); 把其他表查询到数据插入当前表
insert into `表名1`(`字段名1`,`字段名2`,`字段名3`) select `字段名4`,`字段名5`,`字段名6` from `表名2` where [查询条件]; 案例
mysql> desc student; +----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | 匿名 | | | major_id | bigint | NO | MUL | NULL | | +----------+-------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec) mysql> desc major; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | bigint | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | NULL | | +-------+-------------+------+-----+---------+----------------+ 2 rows in set (0.00 sec) -- insert into `表名` (`字段名`) values('字段值'); mysql> insert into `major` (`name`) values('计算机科学'); Query OK, 1 row affected (0.01 sec) mysql> insert into `major` (`name`) values('工业工程'); Query OK, 1 row affected (0.01 sec) mysql> select * from major; +----+-----------------+ | id | name | +----+-----------------+ | 1 | 计算机科学 | | 2 | 工业工程 | +----+-----------------+ 2 rows in set (0.00 sec) -- 插入多条数据 mysql> insert into `major` (`name`) values('自动化'),('机械工程'),('工业设计'); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from major; +----+-----------------+ | id | name | +----+-----------------+ | 1 | 计算机科学 | | 2 | 工业工程 | | 3 | 自动化 | | 4 | 机械工程 | | 5 | 工业设计 | +----+-----------------+ 5 rows in set (0.00 sec) mysql> insert into `student` (`name`,`major_id`) values('小明','1'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+--------+----------+ | id | name | major_id | +----+--------+----------+ | 1 | 小明 | 1 | +----+--------+----------+ 1 row in set (0.00 sec) -- 插入数据的时候,不一定要给表的所有字段赋值,只赋值部分字段也可以,前提是省略的字段可以为空 mysql> insert into `student` (`major_id`) values('1'); Query OK, 1 row affected (0.01 sec) -- 插入数据的时候,没有写入学生的名字,MYSQL会自动填入默认值“匿名” mysql> select * from student; +----+--------+----------+ | id | name | major_id | +----+--------+----------+ | 1 | 小明 | 1 | | 2 | 匿名 | 1 | +----+--------+----------+ 2 rows in set (0.00 sec) UPDATE 数据更新语句
没有指定匹配条件的话,会所有表的所有记录
mysql> select * from major; +----+-----------------+ | id | name | +----+-----------------+ | 1 | 计算机科学 | | 2 | 工业工程 | | 3 | 自动化 | | 4 | 机械工程 | | 5 | 工业设计 | +----+-----------------+ 5 rows in set (0.00 sec) mysql> update major set name='智能制造'; Query OK, 5 rows affected (0.01 sec) Rows matched: 5 Changed: 5 Warnings: 0 mysql> select * from major; +----+--------------+ | id | name | +----+--------------+ | 1 | 智能制造 | | 2 | 智能制造 | | 3 | 智能制造 | | 4 | 智能制造 | | 5 | 智能制造 | +----+--------------+ 5 rows in set (0.00 sec) 根据条件来修改记录
mysql> update major set name='智能科学与技术' where id = 1; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from major; +----+-----------------------+ | id | name | +----+-----------------------+ | 1 | 智能科学与技术 | | 2 | 智能制造 | | 3 | 智能制造 | | 4 | 智能制造 | | 5 | 智能制造 | +----+-----------------------+ 5 rows in set (0.00 sec) 一次性修改多个字段的值
mysql> select * from student; +----+--------+----------+ | id | name | major_id | +----+--------+----------+ | 1 | 小明 | 1 | | 2 | 匿名 | 1 | +----+--------+----------+ 2 rows in set (0.00 sec) mysql> update student set name='李华',major_id=2 where id = 1; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from student; +----+--------+----------+ | id | name | major_id | +----+--------+----------+ | 1 | 李华 | 2 | | 2 | 匿名 | 1 | +----+--------+----------+ 2 rows in set (0.00 sec) 稍微高级一点的使用
update load_product,product set load_product.product_id = product.id where load_product.code=product.code WHERE条件
常用操作符
where条件可以搭配UPDATE、DELETE、SELECT进行使用,可以使用的操作符如下
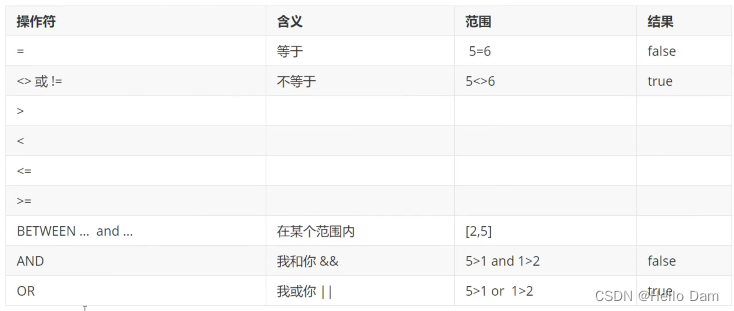
多个条件共同使用,使用and连接,如where id=1 and name=‘李华’
mysql> select id,name as 专业名称 from major; +----+-----------------------+ | id | 专业名称 | +----+-----------------------+ | 1 | 智能科学与技术 | | 2 | 智能制造 | | 3 | 智能制造 | | 4 | 智能制造 | | 5 | 智能制造 | +----+-----------------------+ 5 rows in set (0.00 sec) mysql> select id,name as 专业名称 from major where name='智能制造'; +----+--------------+ | id | 专业名称 | +----+--------------+ | 2 | 智能制造 | | 3 | 智能制造 | | 4 | 智能制造 | | 5 | 智能制造 | +----+--------------+ 4 rows in set (0.00 sec) mysql> select id,name as 专业名称 from major where name!='智能制造'; +----+-----------------------+ | id | 专业名称 | +----+-----------------------+ | 1 | 智能科学与技术 | +----+-----------------------+ 1 row in set (0.00 sec) mysql> select id,name as 专业名称 from major where not name='智能制造'; +----+-----------------------+ | id | 专业名称 | +----+-----------------------+ | 1 | 智能科学与技术 | +----+-----------------------+ 1 row in set (0.00 sec) mysql> select id,name as 专业名称 from major where name='智能制造' and id =2; +----+--------------+ | id | 专业名称 | +----+--------------+ | 2 | 智能制造 | +----+--------------+ 1 row in set (0.00 sec) mysql> select id,name as 专业名称 from major where id < 2; +----+-----------------------+ | id | 专业名称 | +----+-----------------------+ | 1 | 智能科学与技术 | +----+-----------------------+ 1 row in set (0.00 sec) mysql> select id,name as 专业名称 from major where id >= 2; +----+--------------+ | id | 专业名称 | +----+--------------+ | 2 | 智能制造 | | 3 | 智能制造 | | 4 | 智能制造 | | 5 | 智能制造 | +----+--------------+ 4 rows in set (0.00 sec) mysql> select id,name as 专业名称 from major where id >= 2 and id <= 4; +----+--------------+ | id | 专业名称 | +----+--------------+ | 2 | 智能制造 | | 3 | 智能制造 | | 4 | 智能制造 | +----+--------------+ 3 rows in set (0.00 sec) mysql> select id,name as 专业名称 from major where id = 2 or id = 4; +----+--------------+ | id | 专业名称 | +----+--------------+ | 2 | 智能制造 | | 4 | 智能制造 | +----+--------------+ 2 rows in set (0.00 sec) 判空
当然,还可以用来判空或者非空,并不是直接=null,而是is null和is not null
UPDATE sys_user SET avatar = concat( "https://hahaha/", FLOOR(RAND()*29+1), ".png" ) WHERE avatar IS NULL OR avatar = ""; and和or的使用
SELECT * FROM chat WHERE ( from_who = "admin" AND to_who = "user1" ) OR ( to_who = "admin" AND from_who = "user1" ) ORDER BY create_time DESC; 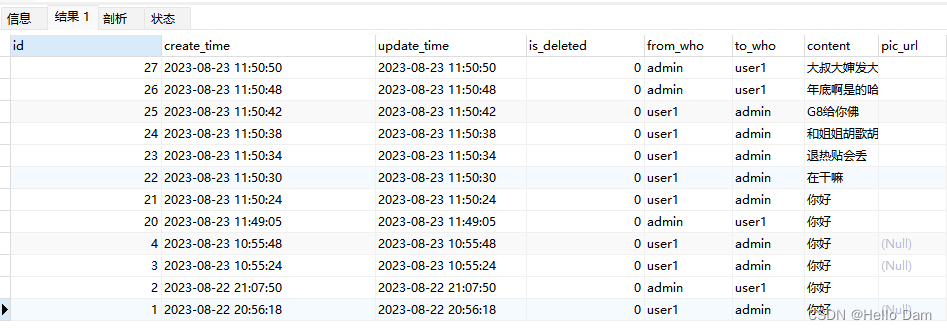
DELETE 数据删除
删除所有数据
delete from 表名; 使用delete删除所有数据,如果重启数据库,会出现如下现象
- InnoDB 自增列会从1开始(存在内存中,断电即失)
- MyISAM 自增列继续从上一个自增量开始(存在文件中,不会丢失)
删除指定数据
delete from 表名 where 条件; TRUNCATE 数据表清空
清空一个数据表的所有数据,自增id计数器重新恢复到1,表的结构和索引约束不会改变
truncate 表名 SELECT 数据查询语句
SELECT语法完整结构
查询的所有操作可以总结为如下套路,如果看不懂,可以先去查看下面的案例,再回来领悟这段内容:
SELECT [ALL DISTINCT] {* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]} FROM table_name [as table_alias] [left | right | inner join table_name2]--联合查询 [WHERE·.]--指定结果需满足的条件 [GROUP BY ... --指定结果按照哪几个字段来分组 [HAVING] --过滤分组的记录必须满足的次要条件 [ORDER BY...]--指定查询记录按一个或多个条件排序 [LIMIT {[offset,]row_count row_countoFFSET offset}]; --指定查询的记录从哪条至哪条 通俗点来讲,如下:
顺序很重要: select 要查询的字段 from 表(注意:表和字段可以取别名】 xxx join 要连接的表 on 等值判断 where(具体的值,子查间语句) Group By(通过哪个字段来分组) Having(过滤分组后的信息,条件和 where 是一样的,位置不同) Order By .. (通过哪个字段排序)升序/降序 Limit startIndex,pagesize 【注】[]:代表可选; {}:代表必选
查询一个表中的所有数据
select * from 表名; 查询指定字段的数据
select 字段1,字段2,字段3 from 表名; 注意:能查询部分字段的,千万不要查询*,这样会增加查询时间
给字段取别名
mysql> select name from major; +-----------------------+ | name | +-----------------------+ | 智能科学与技术 | | 智能制造 | | 智能制造 | | 智能制造 | | 智能制造 | +-----------------------+ 5 rows in set (0.00 sec) mysql> select name as 专业名称 from major; +-----------------------+ | 专业名称 | +-----------------------+ | 智能科学与技术 | | 智能制造 | | 智能制造 | | 智能制造 | | 智能制造 | +-----------------------+ 5 rows in set (0.00 sec) 给表取别名
mysql> select student.id as 学号,student.name as 姓名,major.name as 专业 from student left join major on student.major_id = major.id; +--------+--------+-----------------------+ | 学号 | 姓名 | 专业 | +--------+--------+-----------------------+ | 1 | 李华 | 智能制造 | | 2 | 匿名 | 智能科学与技术 | +--------+--------+-----------------------+ 2 rows in set (0.00 sec) mysql> select s.id as 学号,s.name as 姓名,m.name as 专业 from student as s left join major as m on s.major_id = m.id; +--------+--------+-----------------------+ | 学号 | 姓名 | 专业 | +--------+--------+-----------------------+ | 1 | 李华 | 智能制造 | | 2 | 匿名 | 智能科学与技术 | +--------+--------+-----------------------+ 2 rows in set (0.00 sec) 取别名可以更方便开发者编写sql语句
字符串拼接
mysql> select concat('专业名称:',name) from major; +--------------------------------------+ | concat('专业名称:',name) | +--------------------------------------+ | 专业名称:智能科学与技术 | | 专业名称:智能制造 | | 专业名称:智能制造 | | 专业名称:智能制造 | | 专业名称:智能制造 | +--------------------------------------+ 5 rows in set (0.00 sec) 查询结果数据去重
重复的数据只显示一条
mysql> select name as 专业名称 from major; +-----------------------+ | 专业名称 | +-----------------------+ | 智能科学与技术 | | 智能制造 | | 智能制造 | | 智能制造 | | 智能制造 | +-----------------------+ 5 rows in set (0.00 sec) mysql> select distinct name as 专业名称 from major; +-----------------------+ | 专业名称 | +-----------------------+ | 智能科学与技术 | | 智能制造 | +-----------------------+ 2 rows in set (0.00 sec) 查询时增加计算
mysql> select id,name as 专业名称 from major; +----+-----------------------+ | id | 专业名称 | +----+-----------------------+ | 1 | 智能科学与技术 | | 2 | 智能制造 | | 3 | 智能制造 | | 4 | 智能制造 | | 5 | 智能制造 | +----+-----------------------+ 5 rows in set (0.00 sec) -- 将所有数据的 id 增加 1 mysql> select id+1,name as 专业名称 from major; +------+-----------------------+ | id+1 | 专业名称 | +------+-----------------------+ | 2 | 智能科学与技术 | | 3 | 智能制造 | | 4 | 智能制造 | | 5 | 智能制造 | | 6 | 智能制造 | +------+-----------------------+ 5 rows in set (0.00 sec) 模糊查询
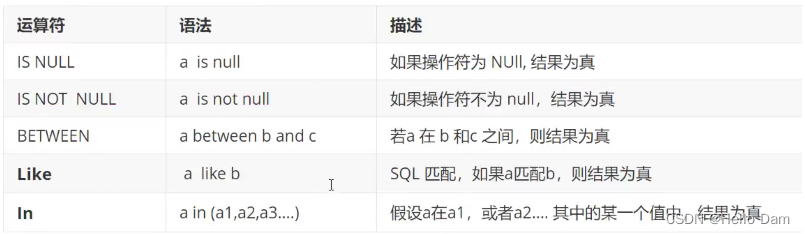
字符模糊查询:%(代表0到任意个字符)、_(一个字符)
-- 查询姓刘的同学 -- like结合 SELECT `studentNo`,`studentName` FROM student WHERE studentName LIKE '刘%'; -- 查询姓刘的同学,名字后面只有一个字的 SELECT `studentNo`,`studentName` FROM student WHERE studentName LIKE '刘_'; -- 查询姓刘的同学,名字后面只有两个字的 SELECT `studentNo`,`studentName` FROM student WHERE studentName LIKE '刘__'; -- 查询名字中间有嘉字的同学 %嘉% SELECT `studentNo`,`studentName` FROM student WHERE studentName LIKE '%嘉%'; -- 查询 1001,1002,1003 号学员 SELECT `StudentNo`,`StudentName` FROM student WHERE StudentNo IN (1001,1002,1003); -- 查询地址为空的学生null '' SELECT `StudentNo`,`StudentName` FROM student WHERE address='' OR address IS NULL; -- 查询有出生日期的同学 不为空 SELECT StudentNo,StudentName FROM student WHERE BornDate IS NOT NULL; -- 查询没有有出生日期的同学 为空 SELECT StudentNo,StudentName FROM student WHERE BornDate IS NULL; 连接查询
七种连接方式
https://blog.csdn.net/laodanqiu/article/details/131233741
自连接
用途:一个表同时存储了父类数据和子类数据,如省市区表同时存储了中国的所有省、市、区的数据,希望查询出广东省下面的所有城市
mysql> desc province_city_region; +-------------+-------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type | Null | Key | Default | Extra | +-------------+-------------+------+-----+-------------------+-----------------------------------------------+ | id | bigint | NO | PRI | NULL | auto_increment | | create_time | datetime | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED | | update_time | datetime | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP | | is_deleted | tinyint | YES | | 0 | | | name | varchar(50) | YES | | NULL | | | type | tinyint | YES | | NULL | | | parent_id | bigint | YES | | NULL | | +-------------+-------------+------+-----+-------------------+-----------------------------------------------+ 7 rows in set (0.00 sec) mysql> select a.id,a.name as 市名称,b.name as 省名称 from province_city_region as a,province_city_region as b where b.name="广东省" and a.parent_id=b.id; +------+-----------+-----------+ | id | 市名称 | 省名称 | +------+-----------+-----------+ | 4792 | 茂名市 | 广东省 | | 4798 | 湛江市 | 广东省 | | 4808 | 东莞市 | 广东省 | | 4809 | 江门市 | 广东省 | | 4817 | 清远市 | 广东省 | | 4826 | 佛山市 | 广东省 | | 4832 | 阳江市 | 广东省 | | 4837 | 汕头市 | 广东省 | | 4845 | 河源市 | 广东省 | | 4852 | 珠海市 | 广东省 | | 4856 | 汕尾市 | 广东省 | | 4861 | 深圳市 | 广东省 | | 4868 | 梅州市 | 广东省 | | 4877 | 揭阳市 | 广东省 | | 4883 | 韶关市 | 广东省 | | 4894 | 惠州市 | 广东省 | | 4900 | 潮州市 | 广东省 | | 4904 | 广州市 | 广东省 | | 4916 | 肇庆市 | 广东省 | | 4925 | 中山市 | 广东省 | | 4926 | 云浮市 | 广东省 | +------+-----------+-----------+ 21 rows in set (0.00 sec) 分页
【查询语句】limit 数据索引起始值 数据量的大小
limit 0,5:查询的是第0,1,2,3,4条数据
limit 2,5:查询的是第2,3,4,5,6条数据
排序
【查询语句】order by 字段 ASC / DESC
- ASC(升序)
- DESC(降序)
mysql> select * from province_city_region order by id asc limit 0,10; +------+---------------------+---------------------+------------+-----------+------+-----------+ | id | create_time | update_time | is_deleted | name | type | parent_id | +------+---------------------+---------------------+------------+-----------+------+-----------+ | 2928 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 山东省 | 0 | 0 | | 2929 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 莱芜市 | 1 | 2928 | | 2930 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 莱城区 | 2 | 2929 | | 2931 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 钢城区 | 2 | 2929 | | 2932 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 济南市 | 1 | 2928 | | 2933 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 历城区 | 2 | 2932 | | 2934 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 历下区 | 2 | 2932 | | 2935 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 长清区 | 2 | 2932 | | 2936 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 平阴县 | 2 | 2932 | | 2937 | 2023-02-10 20:38:54 | 2023-02-10 20:38:54 | 0 | 章丘市 | 1 | 2932 | +------+---------------------+---------------------+------------+-----------+------+-----------+ 10 rows in set (0.00 sec) mysql> select * from province_city_region order by id desc limit 0,10; +------+---------------------+---------------------+------------+--------------------------+------+-----------+ | id | create_time | update_time | is_deleted | name | type | parent_id | +------+---------------------+---------------------+------------+--------------------------+------+-----------+ | 5851 | 2023-02-10 20:39:11 | 2023-02-10 20:39:11 | 0 | 天峨县 | 2 | 5840 | | 5850 | 2023-02-10 20:39:11 | 2023-02-10 20:39:11 | 0 | 凤山县 | 2 | 5840 | | 5849 | 2023-02-10 20:39:11 | 2023-02-10 20:39:11 | 0 | 南丹县 | 2 | 5840 | | 5848 | 2023-02-10 20:39:11 | 2023-02-10 20:39:11 | 0 | 环江毛南族自治县 | 2 | 5840 | | 5847 | 2023-02-10 20:39:11 | 2023-02-10 20:39:11 | 0 | 巴马瑶族自治县 | 2 | 5840 | | 5846 | 2023-02-10 20:39:11 | 2023-02-10 20:39:10 | 0 | 东兰县 | 2 | 5840 | | 5845 | 2023-02-10 20:39:11 | 2023-02-10 20:39:10 | 0 | 金城江区 | 2 | 5840 | | 5844 | 2023-02-10 20:39:11 | 2023-02-10 20:39:10 | 0 | 罗城仫佬族自治县 | 2 | 5840 | | 5843 | 2023-02-10 20:39:11 | 2023-02-10 20:39:10 | 0 | 宜州市 | 1 | 5840 | | 5842 | 2023-02-10 20:39:11 | 2023-02-10 20:39:10 | 0 | 都安瑶族自治县 | 2 | 5840 | +------+---------------------+---------------------+------------+--------------------------+------+-----------+ 10 rows in set (0.00 sec) 子查询(嵌套查询)
注意:数据量大的时候,子查询的效率高于连表查询
查询数据库结构-1的所有考试结果(学号,科目编号,成绩),降序排列
-- 方式一:使用连接查询 SELECT r.StudentNo, r.SubjectNo, `StudentResult` FROM `result` r INNER JOIN `subject` sub ON r.SubjectNo = sub.SubjectNo WHERE SubjectName = '数据库结构-1' ORDER BY StudentResult DESC -- 方式二:使用子查询(由里及外) -- 查询所有数据库结构-1的学生学号 SELECT `StudentNo`, `SubjectNo`, `StudentResult` FROM result WHERE SubjectNo IN ( SELECT SubjectNo FROM subject WHERE SubjectName = '数据库结构-1' ) ORDER BY StudentResult DESC 高等数学-2且分数不小于80的同学的学号和姓名
-- 连表查询 SELECT s.StudentNo, s.StudentName FROM student s INNER JOIN result r ON s.StudentNo = r.StudentNo INNER JOIN subject sub ON r.SubjectNo = sub.SubjectNo WHERE SubjectName = '高等数学-2' AND StudentResult >= 80 -- 子查询 在改造 SELECT StudentNo, StudentName FROM student WHERE StudentNo IN ( SELECT StudentNo FROM result WHERE StudentResult > 80 AND SubjectNo = ( SELECT SubjectNo FROM `subject` WHERE `SubjectName` = '高等数学-2' ) ) in
in操作符主要用于在where子句中指定一个条件,该条件检查某一列的值是否在一个特定的值列表中或者是否由一个子查询返回的结果集所包含,如果在,则将数据返回
- 最简单的用法:检查某一列的值是否在一个特定的值列表中
select id from student where id in (1,2,3,4); - 检查某一列的值是否在子查询返回的结果集中:如查询和张三一个系的学生信息
select id, name, dept from student where dept in (select dept from student where name='张三'); in还可以多重嵌套使用,例如查询机电学院中选修了’数据库’课程的学生姓名
select name from student where dept=‘机电’ and student.id in ( select stu_id from student_course sc where course_id in ( select id from course where name='数据库'))); 注:student_course为选课表
not in
not in的作用和in刚好反过来,即数据列的值不在特定的值列表中时返回,用法如下,与in的用法相同
select id from student where id not in (1,2,3,4); exists
exists关键字主要用于检查子查询是否返回至少一行数据,如果子查询至少返回一行数据,则返回true。注意:子查询找到匹配项就会立即停止执行
- 如查询有挂科的学生姓名(注:student_course为选课表)
select name from student where exists (select * from student_course sc where student.id = sc.stu_id and grade < 60 ); 优化:因为子查询只需要有数据返回即可,不关心具体返回什么数据,因此直接返回1即可,效率更高
select name from student where exists (select 1 from student_course sc where student.id = sc.stu_id and grade < 60 ); not exists
not exists关键字主要用于检查子查询是否返回至少一行数据,如果子查询至少返回一行数据,则返回false。
- 如查询全部及格的学生姓名(注:student_course为选课表)
select name from student where not exists (select * from student_course sc where student.id = sc.stu_id and grade < 60 ); - 进阶用法:查询选修了全部课程的学生名单
select name from student where not exists (select 1 from course where not exists (select 1 from student_course sc where student.id = sc.stu_id and sc.course_id = course.id)); 可能直接看上面的sql比较绕,上面的sql可以近似理解为如下伪代码
// 初始化一个空的Set来存储选修了所有课程的学生及其信息 Set studentList = {} // 遍历所有的学生 for each student in 学生群体 { // 初始化一个空的Set来存储当前学生未选修的课程 Set courseList = {} // 遍历所有的课程 for each course in 课程列表 { // 检查学生是否没有选修当前课程 if (student没有选修course) { // 如果没有选修,则添加此课程到未选修课程列表 courseList.add(course); break; } } // 检查当前学生是否有未选修的课程 if (courseList.size() == 0) { // 如果没有未选修的课程,说明该学生选修了所有课程 // 将学生添加到已选修所有课程的学生列表中 studentList.add(student); } } // 打印或返回studentList,包含所有选修了所有课程的学生信息 in 和 exists 怎么选?
遵循小表驱动大表原则
- 如果B表数据量小于A表数据量,用in更优
select * from A where id in (select id from B); 相当于
for select id from B{ for select * from A where A.id = B.id; } - 如果A表数据量小于B表数据量,用exists更优
# 遍历A表数据,看B表是否有与当前Aid相同的数据,如果有,则查询出来 select * from A where exists (select 1 from B where B.id = A.id); 相当于
for select id from A{ for select * from B where B.id = A.id; } 查询常用函数
【数学运算】
SELECT ABS(-8)--绝对值 SELECT CEILING(9.4)--向上取整 SELECT FLOOR(9.4)--向下取整 SELECT RAND()一一返回一个0~1之间的随机数 SELECT SIGN (10)一一判断一个数的符号(负数返回-1,正数返回1,0返回0) 【字符串函数】
SELECT CHAR_LENGTH('即使再小的帆也能远航')--字符串长度 SELECT CONCAT('哈','哈','哈')--拼接字符串 SELECT INSERT('我爱编程helloworld',1,2,'超级热爱')--从某个位置开始替换某个长度 SELECT LOWER('Abc')--转化为小写字母 SELECT UPPER('Abc')--转化为大写字母 SELECT INSTR('Abc','bc')--返回第一次出现的子串的索引 SELECT REPLACE('你好','好','坏')--替换出现的指定字符串 SELECT SUBSTR('你吃饭了吗',1,3)--返回指定的子字符串(源字符串,截取的位置,截取的长度) SELECT REVERSE('我和你')--反转 -- 查询学生,将查询出来的数据姓氏进行替换 SELECT REPLACE(student_name,'王','玩')FROM student 【时间和日期函数】
SELECT CURRENT_DATE()--获取当前日期 SELECT CURDATE()-一获取当前日期 SELECT NOW()--获取当前的时间 SELECT LOCALTIME()--本地时间 SELECT SYSDATE()-一系统时间 SELECT YEAR(NOW()) SELECT MONTH(NOW()) SELECT DAY(NOW()) SELECT HOUR(NOW()) SELECT MINUTE(NOW()) SELECT SECOND(NOW()) 【数据库相关】
SELECT SYSTEM USER(); SELECT USER(); SELECT VERSION();--查询数据库版本 【统计相关】
都能够统计表中的数据(想查询一个表中有多少个记录,就使用这个cout()) SELECT COUNT(`BornDate`) FROM student;--Count(字段),会忽略所有的nul1值 SELECT COUNT(*) FROM student;--Count(*),不会忽略null值,本质计算行数 SELECT COUNT(1) FROM result;--Count(1),不会忽略忽略所有的nul1值,本质计算行数 SELECT SUM(`StudentResult`) AS 总和 FROM result; SELECT AVG(`StudentResult`) AS 平均分 FROM result; SELECT MAX(`StudentResult`) AS 最高分 FROM result; SELECT MIN(`StudentResult`) As 最低分 FROM result; 注意事项
UPDATE sys_user SET avatar = concat( "https://hahaha/", FLOOR(RAND()*29+1), ".png" ) WHERE avatar IS NULL OR avatar = ""; 使用函数可能导致字段的索引失效,造成效率下降,建议直接读出来,然后用java进行处理
分组、过滤
mysql> select name,gender from user limit 0,10; +-----------------+--------+ | name | gender | +-----------------+--------+ | 系统管理员 | 0 | | 企业管理员 | 0 | | 门店管理员 | 0 | | 郗淑 | 0 | | 柳之 | 1 | | 夏侯之 | 1 | | 吉滢 | 0 | | 独孤杰 | 1 | | 蒙飘 | 0 | | 卫柔 | 0 | +-----------------+--------+ 10 rows in set (0.00 sec) -- 根据 gender 进行分组 mysql> select name,gender from user group by gender limit 0,10; +-----------------+--------+ | name | gender | +-----------------+--------+ | 系统管理员 | 0 | | 柳之 | 1 | +-----------------+--------+ 2 rows in set (0.01 sec) -- 查询不同课程的平均分,最高分,最低分,平均分大于80。根据不同的课程分组 SELECT subjectName,AVG(StudentResult) AS 平均分,MAX(StudentResult) AS 最高分,MIN(StudentResult) AS 最低分 FROM result r INNER JOIN `subject` sub ON r.`SubjectNo` = sub.`SubjectNo` GROUP BY r.SubjectNo HAVING 平均分>80 能使用where,就不要使用having,不然可能导致索引失效
集合操作
Union(并集)
假设有employees(员工) 和 contractors(合同工),使用下列sql可以查询出所有员工和合同工,并将数据合并在一起。
SELECT id, name, job_title FROM employees UNION SELECT id, name, job_title FROM contractors; 测试
mysql> SELECT id, name, job_title FROM contractors; +----+-------+-----------+ | id | name | job_title | +----+-------+-----------+ | 1 | David | Developer | | 2 | Eve | Tester | | 3 | Frank | Designer | +----+-------+-----------+ 3 rows in set (0.00 sec) mysql> SELECT id, name, job_title FROM employees; +----+-------+-----------+ | id | name | job_title | +----+-------+-----------+ | 1 | Alice | Developer | | 2 | Bob | Designer | | 3 | Frank | Designer | +----+-------+-----------+ 3 rows in set (0.00 sec) mysql> SELECT id, name, job_title FROM employees UNION SELECT id, name, job_title FROM contractors; +----+-------+-----------+ | id | name | job_title | +----+-------+-----------+ | 1 | Alice | Developer | | 2 | Bob | Designer | | 3 | Frank | Designer | | 1 | David | Developer | | 2 | Eve | Tester | +----+-------+-----------+ 5 rows in set (0.00 sec) 从上面的执行结果可以发现,UNION操作符可以用于合并两个或更多SELECT语句的结果集,但会自动去除重复的行。
如果希望包含所有行,即使有重复,可以使用UNION ALL:
mysql> SELECT id, name, job_title FROM employees UNION ALL SELECT id, name, job_title FROM contractors; +----+-------+-----------+ | id | name | job_title | +----+-------+-----------+ | 1 | Alice | Developer | | 2 | Bob | Designer | | 3 | Frank | Designer | | 1 | David | Developer | | 2 | Eve | Tester | | 3 | Frank | Designer | +----+-------+-----------+ 6 rows in set (0.01 sec) Except(差集)
mysql> SELECT id, name, job_title FROM employees except SELECT id, name, job_title FROM contractors; +----+-------+-----------+ | id | name | job_title | +----+-------+-----------+ | 1 | Alice | Developer | | 2 | Bob | Designer | +----+-------+-----------+ 2 rows in set (0.00 sec) Intersect(交集)
mysql> SELECT id, name, job_title FROM employees intersect SELECT id, name, job_title FROM contractors; +----+-------+-----------+ | id | name | job_title | +----+-------+-----------+ | 3 | Frank | Designer | +----+-------+-----------+ 1 row in set (0.00 sec) 连接查询
【MySQL高级】MySQL表的七种连接方式【附带练习sql】
索引
准确地建立索引可以加快数据查询效率,详细的内容可以查看如下文章:
视图
视图是一种虚拟的表,它并不在数据库中以存储的数据值形式存在,而是基于一个或多个已存在的表(基表)的SQL查询结果。当你查询视图时,实际上是在执行视图所包含的SQL语句,获取并返回结果集。
视图的主要作用包括:
- 简化复杂查询:如果有一组复杂的查询,你可以将其封装成视图,这样在需要时只需查询视图即可,无需每次都编写复杂的SQL语句。
- 数据安全性:视图可以作为数据访问的过滤层,允许用户只看到他们应该看到的数据,隐藏敏感或不必要的信息。
- 逻辑数据独立性:即使底层表的结构发生变化,只要视图的定义得到相应的更新,应用程序仍然可以通过视图访问数据,无需修改代码。
- 数据重用:视图可以被多次使用,避免了重复编写相同的查询语句。
例子
假设有两个表:
- 员工表
employees(emp_id, first_name, last_name, dept_id) - 部门表
departments(dept_id, dept_name)
创建视图
语法:
CREATE VIEW EmployeeWithDepartment AS SELECT ... 我们可以创建一个视图来展示每个员工的全名和所在部门的名字,而不直接暴露部门ID或其他可能不相关的字段:
CREATE VIEW EmployeeWithDepartment AS SELECT e.first_name, e.last_name, d.dept_name FROM employees e JOIN departments d ON e.dept_id = d.dept_id; 查询视图
一旦视图创建完成,就可以像查询普通表一样查询这个视图:
SELECT * FROM EmployeeWithDepartment; 更新视图
还可以通过视图来更新基表的数据,但这要求视图的定义满足一定的条件,如下视图不能更新
包含聚合函数的视图:如果视图的定义中使用了聚合函数,如
SUM(),AVG(),MAX(),MIN()或COUNT(),那么这样的视图通常不能更新,因为聚合操作意味着数据已经被汇总或计算,更新单个记录没有意义。包含
DISTINCT关键字的视图:如果视图使用了DISTINCT来消除重复行,那么这样的视图也不能更新。包含
GROUP BY子句的视图:使用了GROUP BY进行分组的视图同样不能更新,因为分组后的每一行代表了一组数据的汇总信息。包含
HAVING子句的视图:HAVING子句用于筛选GROUP BY后的结果集,因此也会影响视图的可更新性。包含
UNION或UNION ALL的视图:使用了UNION或UNION ALL操作的视图不能更新,因为它们结合了多个查询的结果,这使得更新操作变得复杂。包含子查询的视图:如果视图的定义中包含子查询,特别是当子查询涉及到
FROM子句中的表时,这样的视图通常也是不可更新的。包含表达式或常量字段的视图:如果视图的字段是由表达式或常量生成的,那么这样的视图也不能更新。
包含函数调用的视图:如果视图的字段依赖于数据库函数,那么这种视图不能更新。
包含
JOIN的视图:如果视图基于多个表的联接,那么更新可能会影响到多个基表,这可能导致复杂的事务处理,因此这样的视图通常也不允许更新。嵌套视图:如果视图是从另一个不可更新的视图中派生出来的,那么这个视图本身也是不可更新的。
为了确保视图能够被更新,其定义必须简单,通常只包含简单的 SELECT 语句,从单一表中选择特定的列,且不包含上述任何复杂元素。如果视图需要被更新,那么在创建视图时,应该考虑其定义,确保它符合可更新视图的要求。此外,即使视图定义允许更新,也需要检查基表的约束和事务一致性,以保证数据的完整性。
例如,如果你想通过视图更新某个员工的部门,可以这样做:
UPDATE EmployeeWithDepartment SET dept_name = 'New Department' WHERE first_name = 'John'; 如上述更新语句违反了视图的定义规则,就不会执行成功。正确的做法通常是直接更新底层的employees表或者设计视图时考虑到更新的需求。
数据加密
【建表sql】
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id` BIGINT NOT NULL auto_increment COMMENT '主键' PRIMARY KEY, `create_time` datetime DEFAULT CURRENT_TIMESTAMP NOT NULL COMMENT '创建时间', `update_time` datetime DEFAULT CURRENT_TIMESTAMP NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', `is_deleted` TINYINT DEFAULT 0 NULL COMMENT '是否删除 0:未删除 1:已删除', `username` VARCHAR ( 50 ) DEFAULT NULL COMMENT '用户名', `password` VARCHAR ( 255 ) NOT NULL COMMENT '密码', `gender` TINYINT DEFAULT 0 NULL COMMENT '性别 0:男 1:女', `age` INT DEFAULT NULL COMMENT '年龄' ) COMMENT '用户表'; -- 插入数据 mysql> insert into user(`username`,`password`,`gender`,`age`) values('admin','123456',0,18),('hello','123456',0,28),('word','123456',1,17); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 【密码MD5加密操作】
mysql> select * from user; +----+---------------------+---------------------+------------+----------+----------+--------+------+ | id | create_time | update_time | is_deleted | username | password | gender | age | +----+---------------------+---------------------+------------+----------+----------+--------+------+ | 1 | 2023-07-05 10:16:16 | 2023-07-05 10:16:16 | 0 | admin | 123456 | 0 | 18 | | 2 | 2023-07-05 10:16:16 | 2023-07-05 10:16:16 | 0 | hello | 123456 | 0 | 28 | | 3 | 2023-07-05 10:16:16 | 2023-07-05 10:16:16 | 0 | word | 123456 | 1 | 17 | +----+---------------------+---------------------+------------+----------+----------+--------+------+ 3 rows in set (0.00 sec) -- 加密id=1的数据的密码 mysql> update user set password=MD5(password) where id=1; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from user; +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ | id | create_time | update_time | is_deleted | username | password | gender | age | +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ | 1 | 2023-07-05 10:16:16 | 2023-07-05 10:18:38 | 0 | admin | e10adc3949ba59abbe56e057f20f883e | 0 | 18 | | 2 | 2023-07-05 10:16:16 | 2023-07-05 10:16:16 | 0 | hello | 123456 | 0 | 28 | | 3 | 2023-07-05 10:16:16 | 2023-07-05 10:16:16 | 0 | word | 123456 | 1 | 17 | +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ 3 rows in set (0.00 sec) -- 加密所有数据的密码 mysql> update user set password=MD5(password); Query OK, 3 rows affected (0.01 sec) Rows matched: 3 Changed: 3 Warnings: 0 mysql> select * from user; +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ | id | create_time | update_time | is_deleted | username | password | gender | age | +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ | 1 | 2023-07-05 10:16:16 | 2023-07-05 10:19:01 | 0 | admin | 14e1b600b1fd579f47433b88e8d85291 | 0 | 18 | | 2 | 2023-07-05 10:16:16 | 2023-07-05 10:19:01 | 0 | hello | e10adc3949ba59abbe56e057f20f883e | 0 | 28 | | 3 | 2023-07-05 10:16:16 | 2023-07-05 10:19:01 | 0 | word | e10adc3949ba59abbe56e057f20f883e | 1 | 17 | +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ 3 rows in set (0.00 sec) -- 插入数据的时候就执行加密 mysql> insert into user(`username`,`password`,`gender`,`age`) values('md5',MD5('123456'),0,18); Query OK, 1 row affected (0.01 sec) mysql> select * from user; +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ | id | create_time | update_time | is_deleted | username | password | gender | age | +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ | 1 | 2023-07-05 10:16:16 | 2023-07-05 10:19:01 | 0 | admin | 14e1b600b1fd579f47433b88e8d85291 | 0 | 18 | | 2 | 2023-07-05 10:16:16 | 2023-07-05 10:19:01 | 0 | hello | e10adc3949ba59abbe56e057f20f883e | 0 | 28 | | 3 | 2023-07-05 10:16:16 | 2023-07-05 10:19:01 | 0 | word | e10adc3949ba59abbe56e057f20f883e | 1 | 17 | | 4 | 2023-07-05 10:19:46 | 2023-07-05 10:19:46 | 0 | md5 | e10adc3949ba59abbe56e057f20f883e | 0 | 18 | +----+---------------------+---------------------+------------+----------+----------------------------------+--------+------+ 4 rows in set (0.00 sec) 在存储密码这种数据时,一定要进行加密,直接使用MD5加密也还是不安全的,可以被暴力破解,可以使用更加安全的盐值加密
