
阅读量:3
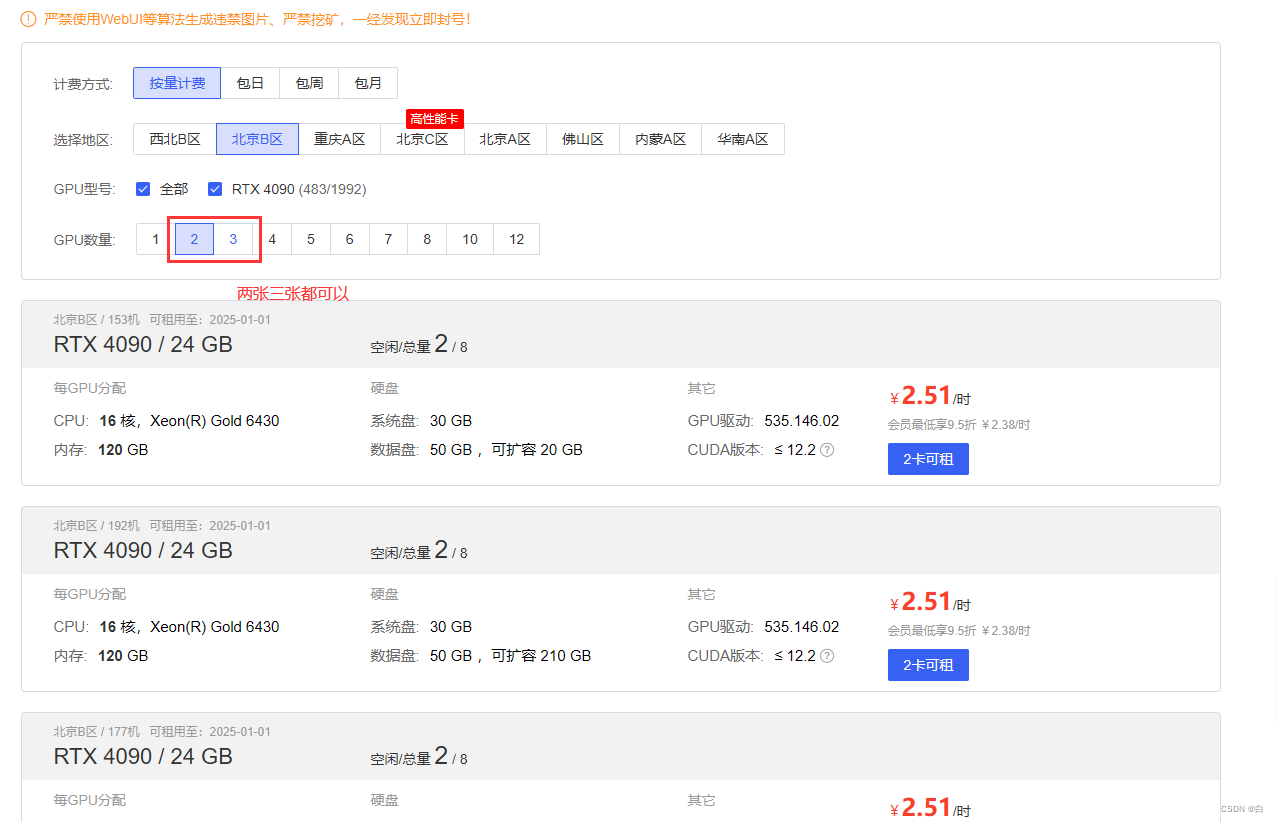
1.选择三张4090算力(两张4090需要扩数据盘)
我这里用的是算力云 选择的是两张4090 扩容是50G
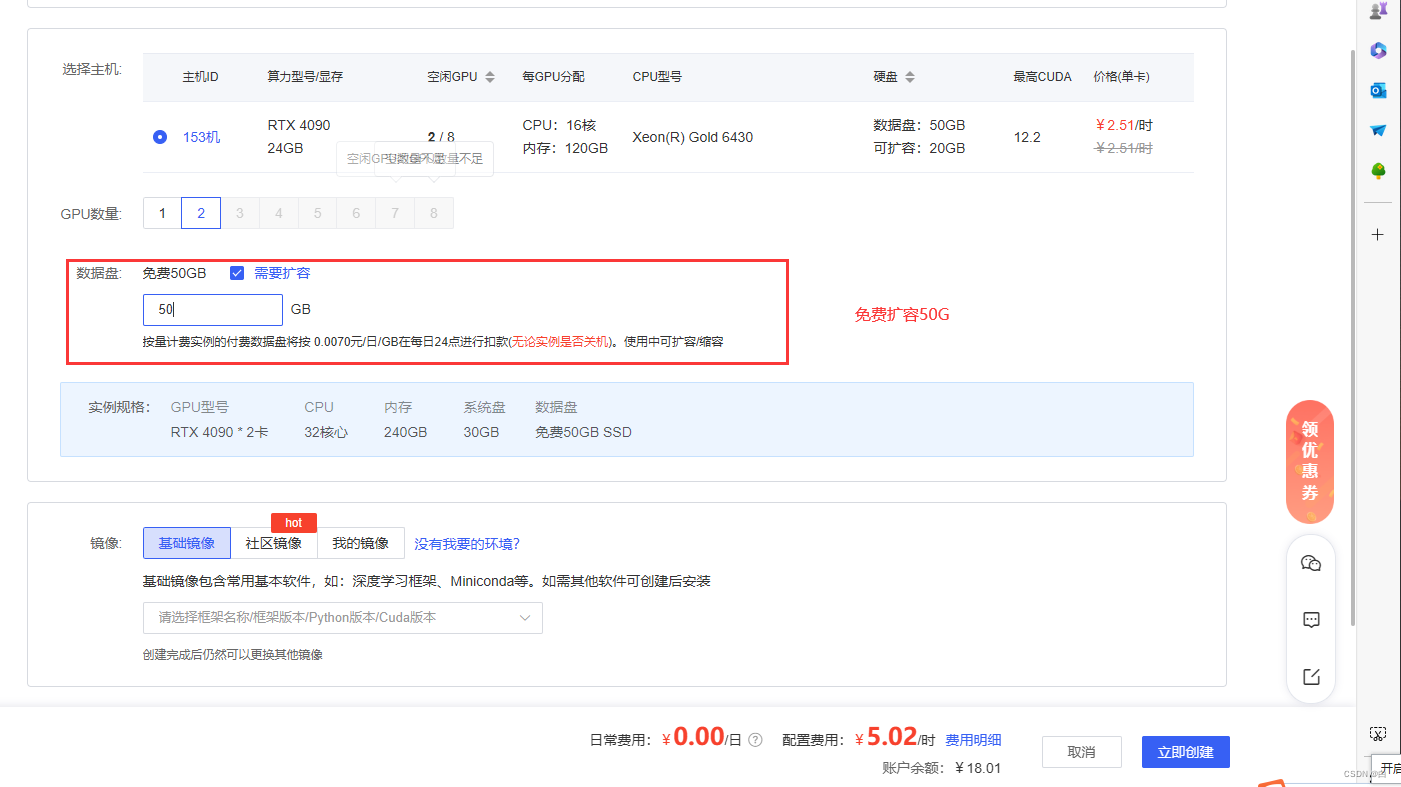
接着就是创建你需要使用的框架这里我选的是pytorch
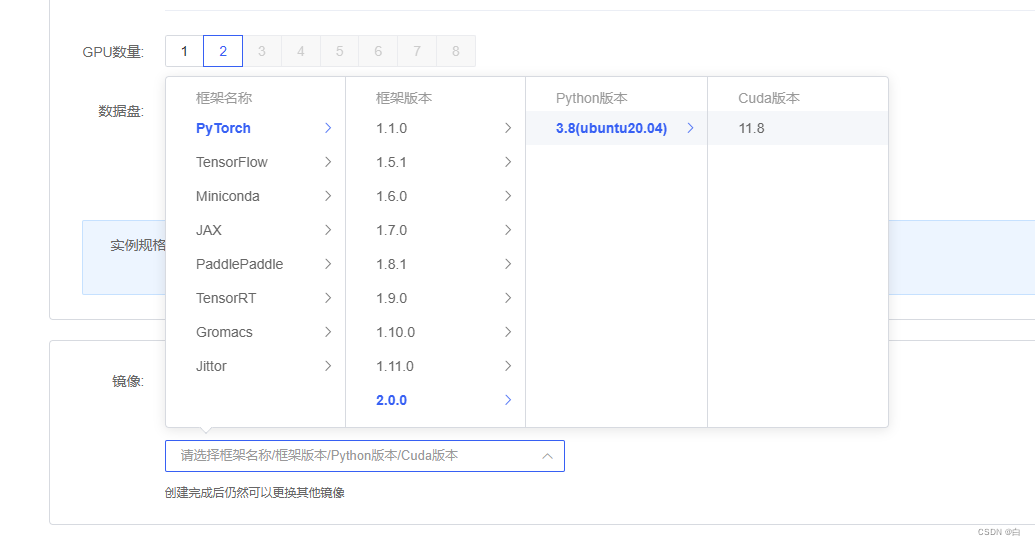
这是创建完之后的实例

2.获取模型(也可以先拉去代码框架)
这里我选择先拉取模型
进入终端输入命令切换文件 cd autodl-tmp
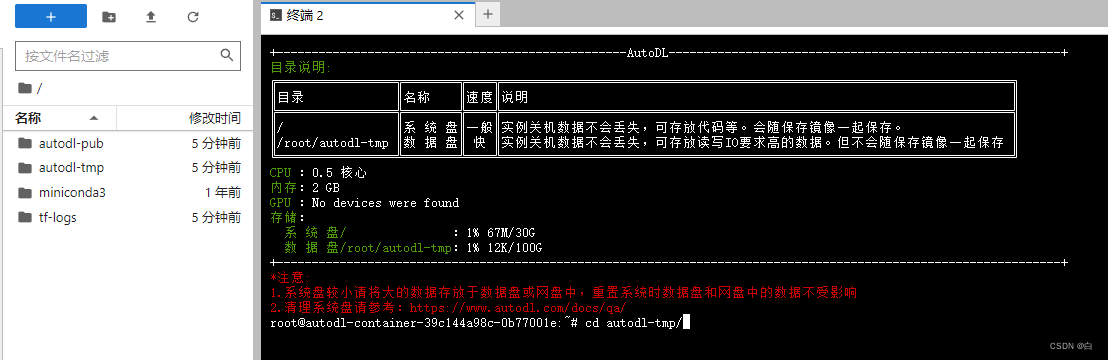
输入拉取模型命令 (三条)
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh
sudo apt-get update
sudo apt-get install git-lfs
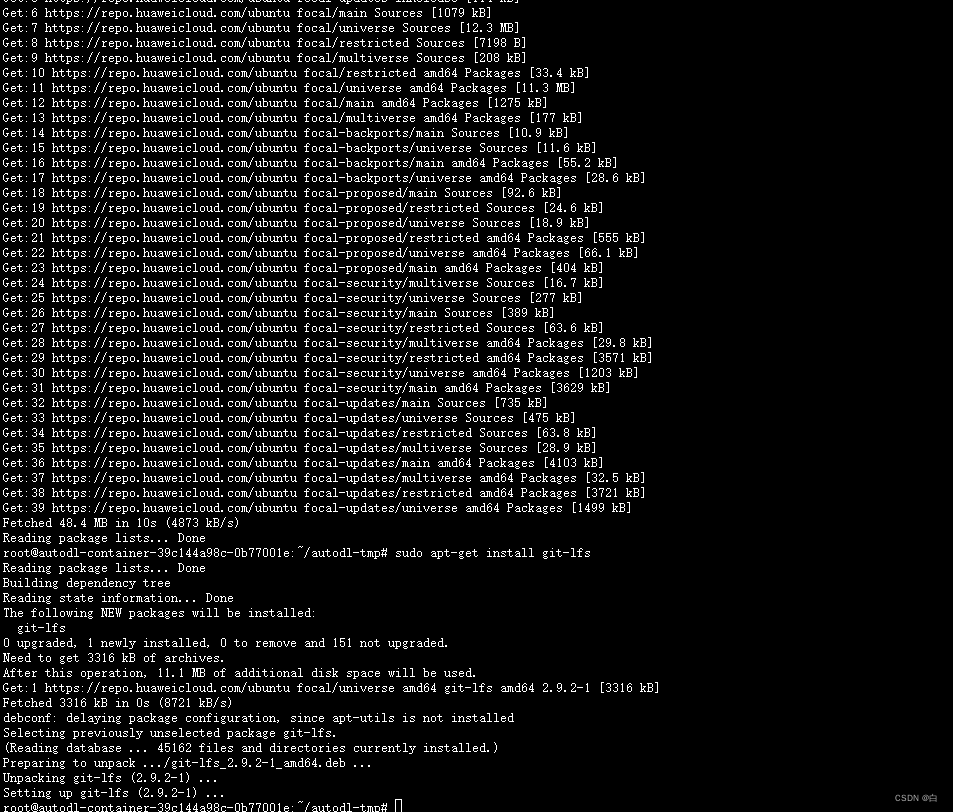 cd /autodl-tmp路径下,不创建环境,直接安包(两条命令)
cd /autodl-tmp路径下,不创建环境,直接安包(两条命令)
1.pip install "transformers>=4.32.0" accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
2.pip install auto-gptq optimum
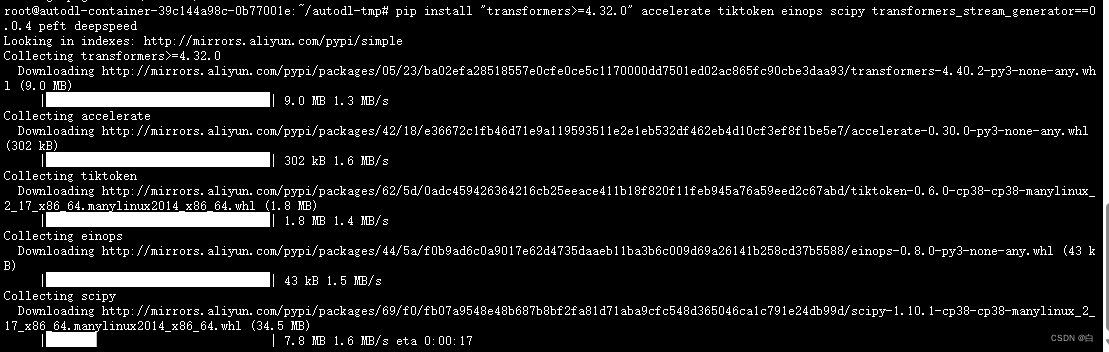

3.安装flash-attention库
cd /autodl-tmp路径下
学术加速,flash-attention和modelscope包不用学术加速很慢(一条)
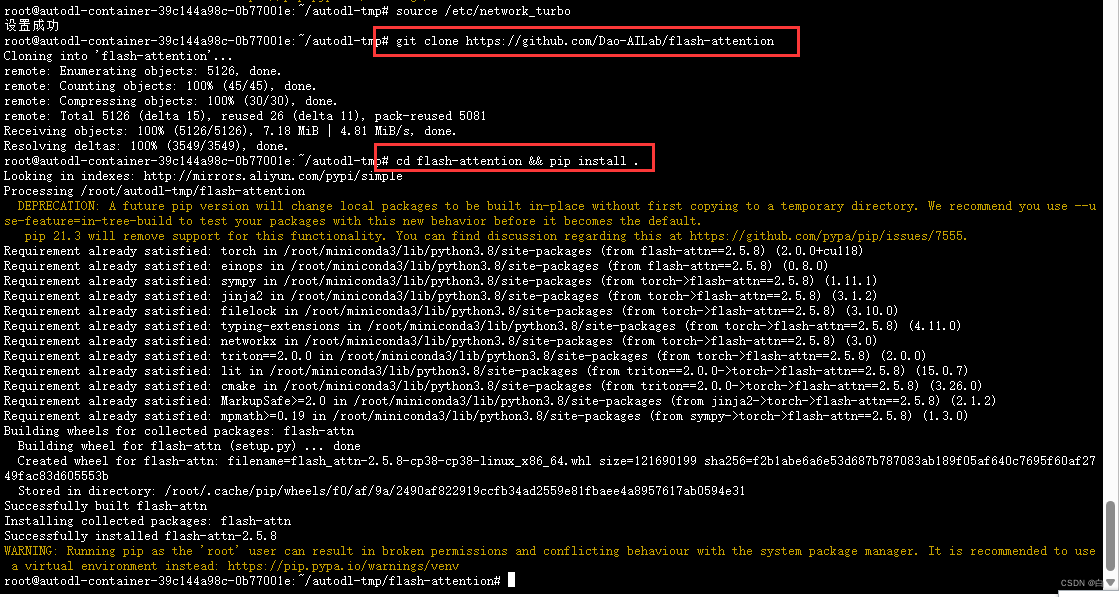
加速命令:source /etc/network_turbo

安装flash-attention库,实现更高的效率更低的显存占用(两条命令)
1.git clone https://github.com/Dao-AILab/flash-attention
2.cd flash-attention && pip install .(不要忘了这个点)
cd ..退出flash-attention文件,autodl-tmp路径下
安装模型时需要的modelscope包(一条命令)
pip install modelscope

取消加速(一条)
unset http_proxy && unset https_proxy

显示这样就取消成功了
4.久等了 接下来就开始下载模型咯
首先我们在cd/autodl-tmp路径下,新建笔记本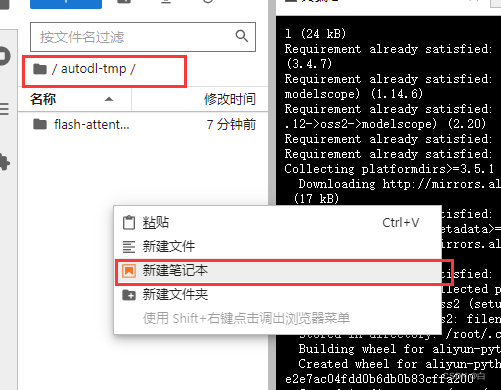
下载到cache_dir='/root/autodl-tmp'路径下(一条命令)
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-72B-Chat-Int4',cache_dir='/root/autodl-tmp')
详细步骤:先复制 粘贴模型下载命令 然后运行 (运行之后稍微等2-3分钟 就可以看到正在下载模型了 下载模型大概需要半个小时左右)
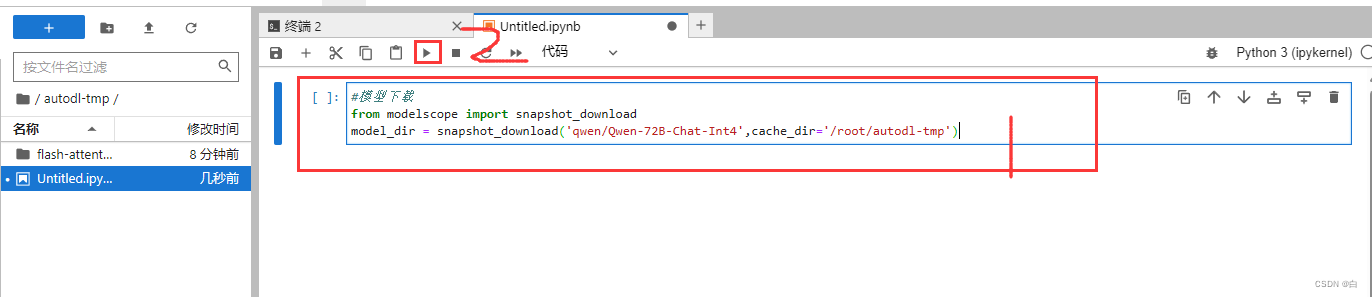
出现这样 说明模型正在下载中咯 稍等片刻~

5.模型下载完 我们需要新建一个测试文件 test.py (复制下面代码)
from modelscope import AutoTokenizer, AutoModelForCausalLM
# 加载本地模型的路径
local_model_path = '/root/autodl-tmp/qwen/Qwen-72B-Chat-Int4'
# 加载本地模型
tokenizer = AutoTokenizer.from_pretrained(local_model_path, local_files_only=True, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
local_files_only=True,
device_map="auto",
trust_remote_code=True
).eval()
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
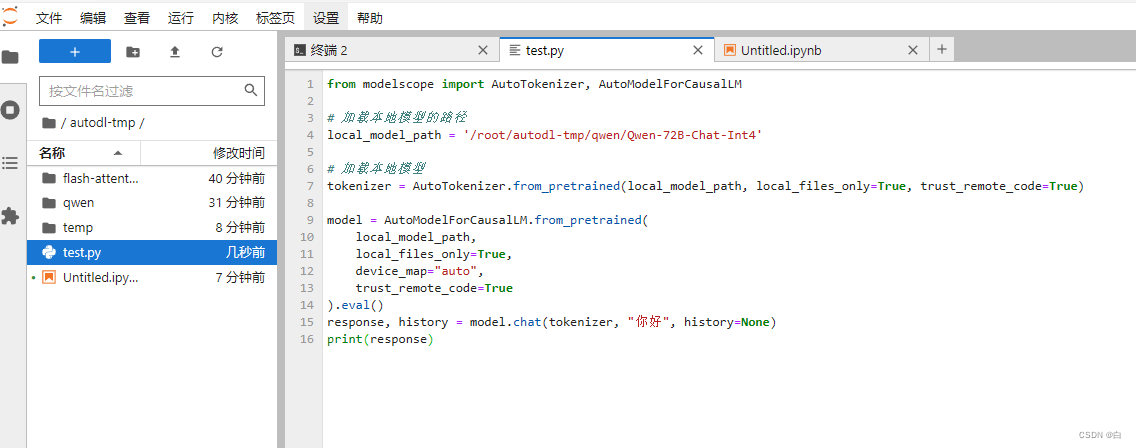
然后终端进行运行指令:
如果三张卡的话就是 显卡数量(3张) MLU_VISIBLE_DEVICES=0,1,2
如果是两张卡 (2张) MLU_VISIBLE_DEVICES=0,1
输入以下命令(一条 )
export MLU_VISIBLE_DEVICES=0,1,2 && python test.py
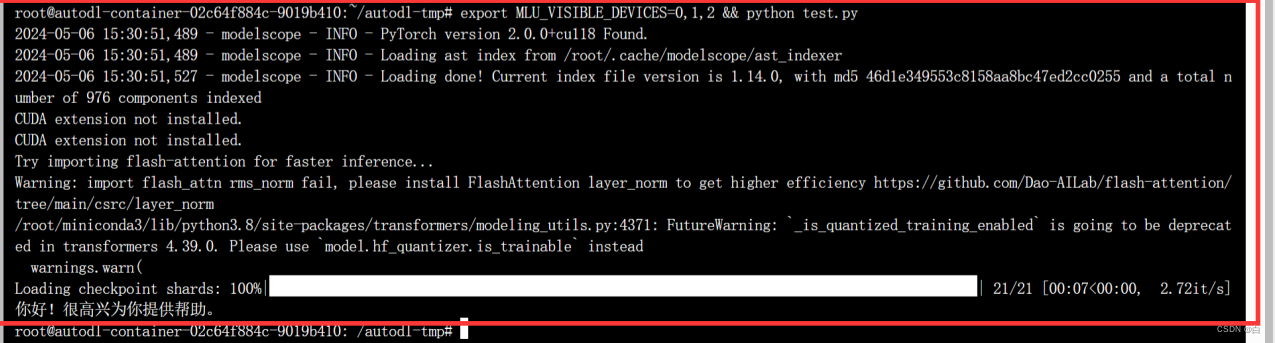
做到这里就可以在 服务器 访问 qwen72b模型了
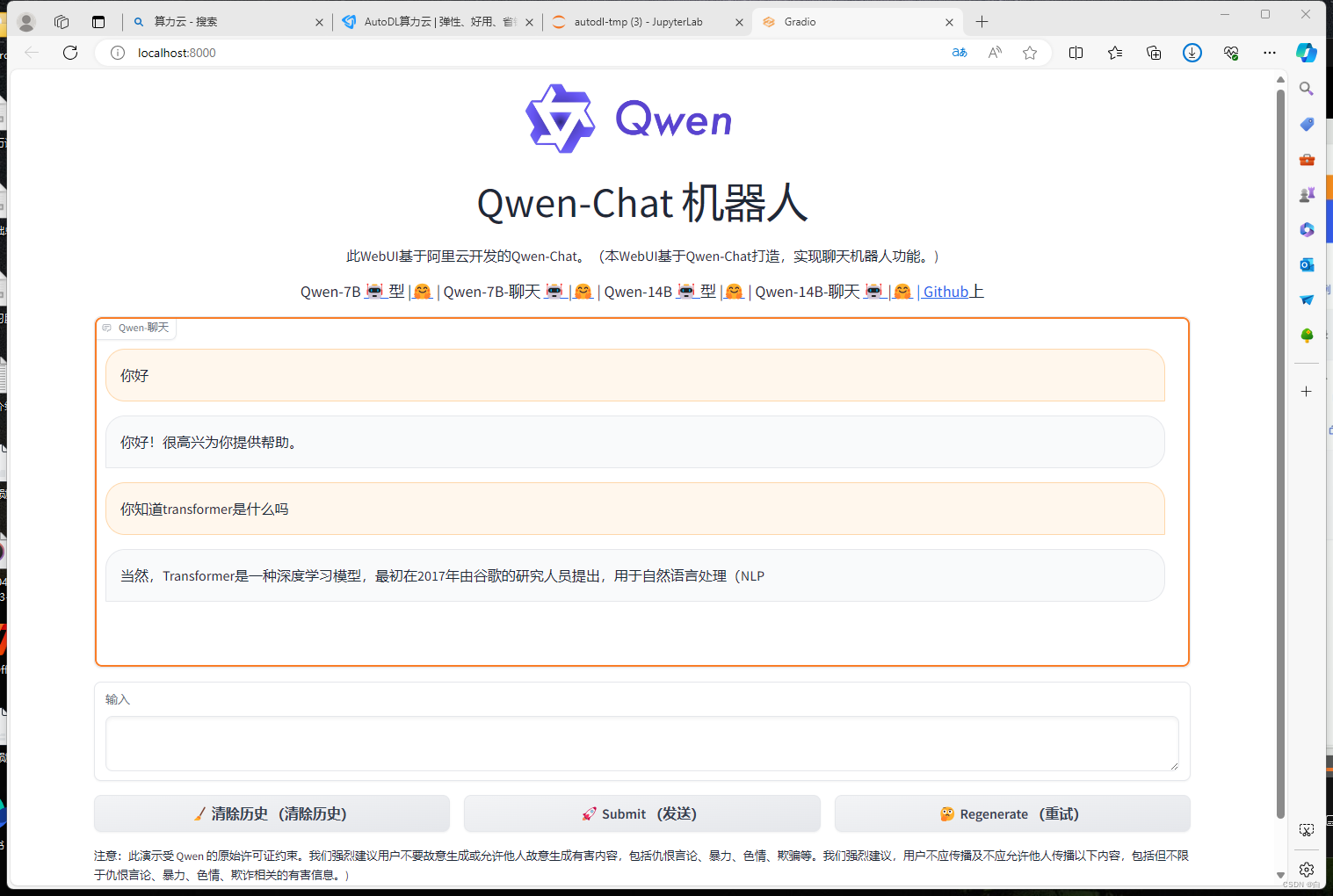
6.当然也可以进行web页面交互
以上拉取模型 步骤一致
首先获取 框架 (一条命令)
git clone https://github.com/QwenLM/Qwen.git
然后安装 依赖包(两条)
pip install -r requirements.txt
pip install -r requirements_web_demo.txt
然后找到web_demo.py文件进行更改
# 48行附近 找到device_map = "auto" 修改为如下指定内容
device_map={'transformer.wte': 0, 'transformer.drop': 0, 'transformer.rotary_emb': 0, 'transformer.h.0': 0,'transformer.h.1': 0, 'transformer.h.2': 0, 'transformer.h.3': 0, 'transformer.h.4': 0, 'transformer.h.5': 0, 'transformer.h.6': 0, 'transformer.h.7': 0, 'transformer.h.8': 0, 'transformer.h.9': 0, 'transformer.h.10': 0, 'transformer.h.11': 0, 'transformer.h.12': 0, 'transformer.h.13': 0, 'transformer.h.14': 0, 'transformer.h.15': 0, 'transformer.h.16': 0, 'transformer.h.17': 0, 'transformer.h.18': 0, 'transformer.h.19': 0, 'transformer.h.20': 0, 'transformer.h.21': 0, 'transformer.h.22': 0, 'transformer.h.23': 0, 'transformer.h.24': 0, 'transformer.h.25': 0, 'transformer.h.26': 0, 'transformer.h.27': 0, 'transformer.h.28': 0, 'transformer.h.29': 0, 'transformer.h.30': 0, 'transformer.h.31': 0, 'transformer.h.32': 0, 'transformer.h.33': 0, 'transformer.h.34': 0, 'transformer.h.35': 0, 'transformer.h.36': 0, 'transformer.h.37': 0, 'transformer.h.38': 0, 'transformer.h.39': 0, 'transformer.h.40': 1, 'transformer.h.41': 1, 'transformer.h.42': 1, 'transformer.h.43': 1, 'transformer.h.44': 1, 'transformer.h.45': 1, 'transformer.h.46': 1, 'transformer.h.47': 1, 'transformer.h.48': 1, 'transformer.h.49': 1, 'transformer.h.50': 1, 'transformer.h.51': 1, 'transformer.h.52': 1, 'transformer.h.53': 1, 'transformer.h.54': 1, 'transformer.h.55': 1, 'transformer.h.56': 1, 'transformer.h.57': 1, 'transformer.h.58': 1, 'transformer.h.59': 1, 'transformer.h.60': 1, 'transformer.h.61': 1, 'transformer.h.62': 1, 'transformer.h.63': 1, 'transformer.h.64': 1, 'transformer.h.65': 1, 'transformer.h.66': 1, 'transformer.h.67': 1, 'transformer.h.68': 1, 'transformer.h.69': 1, 'transformer.h.70': 1, 'transformer.h.71': 1, 'transformer.h.72': 1, 'transformer.h.73': 1, 'transformer.h.74': 1, 'transformer.h.75': 1, 'transformer.h.76': 1, 'transformer.h.77': 1, 'transformer.h.78': 1, 'transformer.h.79': 1, 'transformer.ln_f': 1, 'lm_head': 1}
模型路径进行更改
# 18行附近修改模型文件地址
DEFAULT_CKPT_PATH = '/root/autodl-tmp/Qwen/qwen72b/qwen/Qwen-72B-Chat-Int4'
接着 就是安装auto-gptq使用量化后的权重(一条)
pip install auto-gptq optimum
最后我们就可以在终端运行 代码了 (一条)
python web_demo.py
效果展示
如果对你有帮助的话 请点个关注吧~ 谢谢~
