
阅读量:4
目录
一、使用场景
- 分片数变更:当你的数据量过大,而你的索引最初创建的分片数量不足,导致数据入库较慢的情况,此时需要扩大分片的数量,此时可以尝试使用Reindex。
- mapping字段变更:当数据的mapping需要修改,但是大量的数据已经导入到索引中了,重新导入数据到新的索引太耗时;但是在ES中,一个字段的mapping在定义并且导入数据之后是不能再修改的,所以这种情况下也可以考虑尝试使用Reindex。
- 分词规则修改,比如使用了新的分词器或者对分词器自定义词库进行了扩展,而之前保存的数据都是按照旧的分词规则保存的,这时候必须进行索引重建。
二、reindex介绍
reindex 为 ES 5.X 版本之后提供的数据迁移功能,不需要额外安装,支持同集群索引迁移和跨集群索引迁移。
使用 reindex,要注意两点:
- 要求源端索引的元字段 _source 是打开的,默认就是打开的。
- reindex 过程并不会自动将源端索引的设置拷贝到目标索引,所以需要事先在目标集群(源集群和目标集群可以是同一个集群)中按照源端索引的表结构建立好目标索引。
基础使用命令:
POST _reindex { "source": { "index": "old_index" }, "dest": { "index": "new_index" } }三、使用手册
1、覆盖更新
说明:"version_type": "internal",internal表示内部的,省略version_type或version_type设置为 internal 将导致 Elasticsearch 盲目地将文档转储到目标中,覆盖任何具有相同类型和 ID 的文件。
这也是最常见的重建方式。
POST _reindex { "source": { "index": "twitter" }, "dest": { "index": "new_twitter", "version_type": "internal" } }2、创建丢失的文档并更新旧版本的文档
说明:"version_type": "external",external表示外部的,将 version_type 设置为 external 将导致 Elasticsearch 保留源中的版本,创建任何丢失的文档,并更新目标索引中版本比源索引中版本旧的任何文档。
id不存在的文档会直接更新;id存在的文档会先判断版本号,只会更新版本号旧的文档。
POST _reindex { "source": { "index": "twitter" }, "dest": { "index": "new_twitter", "version_type": "external" } }3、仅创建丢失的文档
要创建的 op_type 设置将导致 _reindex 仅在目标索引中创建丢失的文档,所有存在的文档都会引起版本冲突。
只要两个索引中存在id相同的记录,就会引起版本冲突。
POST _reindex { "source": { "index": "twitter" }, "dest": { "index": "new_twitter", "op_type": "create" } }4、冲突处理
默认情况下,版本冲突会中止 _reindex 进程。 “冲突”请求正文参数可用于指示 _reindex 继续处理有关版本冲突的下一个文档。 需要注意的是,其他错误类型的处理不受“冲突”参数的影响。
当"conflicts": "proceed"在请求正文中设置时,_reindex 进程将继续处理版本冲突并返回遇到的版本冲突计数。
POST _reindex { "conflicts": "proceed", "source": { "index": "twitter" }, "dest": { "index": "new_twitter", "op_type": "create" } }5、source中添加查询条件
POST _reindex { "source": { "index": "twitter", "query": { "term": { "user": "kimchy" } } }, "dest": { "index": "new_twitter" } }6、source中包含多个源索引
源中的索引可以是一个列表,允许您在一个请求中从多个源中复制。 这将从 twitter 和 blog 索引中复制文档:
POST _reindex { "source": { "index": ["twitter", "blog"] }, "dest": { "index": "all_together" } } 也支持*号来匹配多个索引。 POST _reindex { "source": { "index": "twitter*" }, "dest": { "index": "all_together" } }7、限制处理的记录数
通过设置size大小来限制处理文档的数量。
POST _reindex { "size": 10000, "source": { "index": "twitter", "sort": { "date": "desc" } }, "dest": { "index": "new_twitter" } }8、从远程ES集群中重建索引
注意:要保证源索引与目的索引的表结构信息一致,否则可能导致源索引与目的索引字段类型等信息不一致 例如:1、查询出源索引的表结构信息,并根据此表结构提前在目的集群中创建出目的索引 2、若源索引有对应的索引模版,可提前将该索引模版在目的集群中创建出 在目的 es 集群中配置上源 es 集群的白名单信息
vim elasticsearch.yml # 在目的集群的elasticsearch.yml文件中增加源es集群的白名单配置 reindex.remote.whitelist: “otherhost:9200”POST _reindex?wait_for_completion=false { "source": { "remote": { "host": "http://otherhost:9200", "username": "user", "password": "password" }, "size":5000 "index": "source" }, "dest": { "index": "dest" } }9、提取随机子集
说明:从源索引中随机取10条数据到新索引中。
POST _reindex { "size": 10, "source": { "index": "twitter", "query": { "function_score" : { "query" : { "match_all": {} }, "random_score" : {} } }, "sort": "_score" }, "dest": { "index": "random_twitter" } }10、修改字段名称
原索引 POST test/_doc/1?refresh { "text": "words words", "flag": "foo" } 重建索引,将原索引中的flag字段重命名为tag字段。 POST _reindex { "source": { "index": "test" }, "dest": { "index": "test2" }, "script": { "source": "ctx._source.tag = ctx._source.remove(\"flag\")" } } 结果: GET test2/_doc/1 { "found": true, "_id": "1", "_index": "test2", "_type": "_doc", "_version": 1, "_seq_no": 44, "_primary_term": 1, "_source": { "text": "words words", "tag": "foo" } }11、reindex超时情况
es中的请求超时时间默认是1分钟,当重建索引的数据量太大时,经常会出现超时。这种情况可以增大超时时间,也可以添加wait_for_completion=false参数将请求转为异步任务。
POST _reindex?wait_for_completion=false { "source": { "index": "twitter" }, "dest": { "index": "new_twitter" } }四、性能优化
常规的如果我们只是进行少量的数据迁移利用普通的reindex就可以很好的达到要求,但是当我们发现我们需要迁移的数据量过大时,我们会发现reindex的速度会变得很慢。数据量几十个G的场景下,elasticsearch reindex速度太慢,从旧索引导数据到新索引,当前最佳方案是什么?
原因分析:
reindex的核心做跨索引、跨集群的数据迁移。
慢的原因及优化思路无非包括:
- 批量大小值可能太小。需要结合堆内存、线程池调整大小;
- reindex的底层是scroll实现,借助scroll并行优化方式,提升效率;
- 跨索引、跨集群的核心是写入数据,考虑写入优化角度提升效率。
可行方案:
- 提升批量写入的大小值size
- 通过设置sliced提高写入的并行度
- 提升写入速度,ES副本数设置为0、增加refresh间隔、index.translog.durability设置为async
1、提升批量写入大小值
默认情况下 _reindex 使用 1000 的滚动批次。可以使用源元素source中的 size 字段更改批次大小:
POST _reindex { "source": { "index": "source", "size": 5000 }, "dest": { "index": "dest" } }2、提高scroll的并行度
Reindex 支持 Sliced Scroll 来并行化重新索引过程。 这种并行化可以提高效率并提供一种将请求分解为更小的部分的便捷方式。
每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,利用Scroll重建或者遍历要快很多倍。
slicing的设定分为两种方式:手动设置分片、自动设置分片。
自动设置分片如下:
POST _reindex?slices=5&refresh { "source": { "index": "twitter" }, "dest": { "index": "new_twitter" } }slices大小设置注意事项:
1)slices大小的设置可以手动指定,或者设置slices设置为auto,auto的含义是:针对单索引,slices大小=分片数;针对多索引,slices=分片的最小值。
2)当slices的数量等于索引中的分片数量时,查询性能最高效。slices大小大于分片数,非但不会提升效率,反而会增加开销。
3)如果这个slices数字很大(例如500),建议选择一个较低的数字,因为过大的slices 会影响性能。
3、ES副本数设置为0
如果要进行大量批量导入,请考虑通过设置index.number_of_replicas来禁用副本:0。
主要原因在于:
- 复制文档时,将整个文档发送到副本节点,并逐字重复索引过程。 这意味着每个副本都将执行分析,索引和潜在合并过程。
- 相反,如果您使用零副本进行索引,然后在提取完成时启用副本,则恢复过程本质上是逐字节的网络传输。 这比复制索引过程更有效。
PUT /my_logs/_settings { "number_of_replicas": 1 }4、增加refresh间隔
如果你的搜索结果不需要接近实时的准确性,考虑先不要急于索引刷新refresh。可以将每个索引的refresh_interval到30s。
如果正在进行大量数据导入,可以通过在导入期间将此值设置为-1来禁用刷新。完成后不要忘记重新启用它!
设置方法:
PUT /my_logs/_settings { "refresh_interval": -1 }5、异步刷新translog
translog默认的持久化策略为:request。这个非常影响 ES 写入速度。但是这样写操作比较可靠。如果系统可以接受一定概率的数据丢失(例如:数据写入主分片成功,尚未复制到副分片时,主机断电。由于数据既没有刷到Lucene,translog也没有刷盘,恢复时translog中没有这个数据,数据丢失),则调整translog持久化策略。
在每一个索引,删除,更新或批量请求之后是否进行fsync和commit操作。此设置接受以下参数:
- request:(默认)在每次请求后fsync并commit。如果发生硬件故障,所有已确认的写入将已经提交到磁盘。
- async:每隔sync_interval段时间进行fsync并commit。如果发生故障,则自上次自动提交以来所有已确认的写入将被丢弃。
PUT /my_logs/_settings { "index.translog.durability": "async" }五、查看&取消任务
1、获取reindex任务列表
GET _tasks?actions=*reindex*&detailed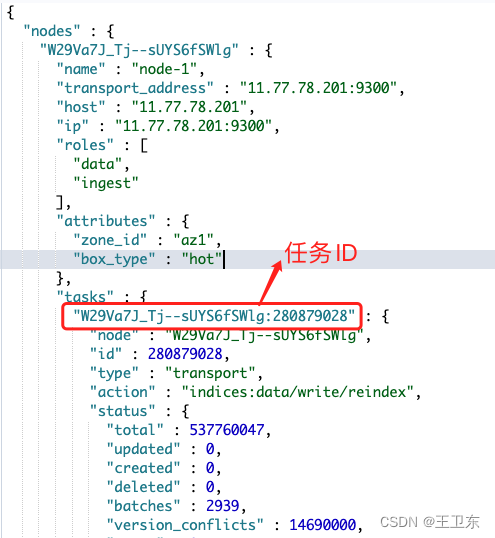
2、根据任务id查看任务
GET /_tasks/W29Va7J_Tj--sUYS6fSWlg:280879028其中task.status.total表示源数据总行数,task.status.created表示已同步的行数
3、取消任务
POST _tasks/W29Va7J_Tj--sUYS6fSWlg:280879028/_cancel
