
阅读量:2
安装nvidia
本文在ubuntu server 22.04上实验成功,其他版本仅供参考
注意,本文仅适用于ubuntu server,不需要图形界面,没有对图形界面进行特殊考虑和验证!依赖图形操作界面的读者慎用
查看是否安装了gcc
gcc -v 若没有安装,则输入下面的命令,直接把包括gcc在内很多开发工具包一同安装
sudo apt-get install build-essential 禁用nouveau驱动
编辑 /etc/modprobe.d/blacklist-nouveau.conf 文件,添加以下内容:
blacklist nouveau blacklist lbm-nouveau options nouveau modeset=0 alias nouveau off alias lbm-nouveau off 关闭nouveau:
echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf 注意,本文仅适用于ubuntu server,不需要图形界面,没有对图形界面进行特殊考虑和验证!依赖图形操作界面的读者慎用!
完成后,重新生成内核并重启:
sudo update-initramfs -u sudo reboot 重启后,执行:lsmod | grep nouveau。如果没有屏幕输出,说明禁用nouveau成功。否则,应重新执行第禁用nouveau驱动小节。
因为实验室服务器不方便重启,我没有重启,但执行:lsmod | grep nouveau,没有屏幕输出,说明禁用nouveau成功。
安装驱动
使用命令ubuntu-drivers devices获取可用驱动信息,如果命令不存在自己安装一下。
输出为:
== /sys/devices/pci0000:72/0000:72:00.0/0000:73:00.0 == modalias : pci:v000010DEd00002204sv00001028sd00003880bc03sc00i00 vendor : NVIDIA Corporation model : GA102 [GeForce RTX 3090] driver : nvidia-driver-525 - third-party non-free driver : nvidia-driver-525-open - distro non-free driver : nvidia-driver-525-server - distro non-free driver : nvidia-driver-470 - distro non-free driver : nvidia-driver-535-server-open - distro non-free driver : nvidia-driver-470-server - distro non-free driver : nvidia-driver-535 - distro non-free recommended driver : nvidia-driver-535-server - distro non-free driver : nvidia-driver-535-open - distro non-free driver : xserver-xorg-video-nouveau - distro free builtin 注意recommend的版本是535,加上是在服务器上安装,初步确定安装nvidia-driver-535-server
还可以查看内核中nvidia的版本:cat /proc/driver/nvidia/version
输出为:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 535.129.03 Thu Oct 19 18:56:32 UTC 2023 GCC version: gcc version 11.4.0 (Ubuntu 11.4.0-1ubuntu1~22.04) 可以看到版本是535
因此执行命令安装:sudo apt install nvidia-driver-535-server
等待安装完成后,执行nvidia-smi可以输出gpu监控界面,则驱动安装成功!
执行nvidia-smi的输出结果
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 3090 Off | 00000000:73:00.0 Off | N/A | | 55% 66C P2 163W / 350W | 1575MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 1331109 C python3 1562MiB | +---------------------------------------------------------------------------------------+ 上图显示的显卡信息,第一行是版本信息,第二行是标题栏,第三行是具体的显卡信息。如果有多个显卡,就会有多行对应标题栏的信息。例如我上面显示了共0~4号,共5个卡。
- GPU:显卡编号,从0开始。
- Fan:风扇转速,在0~100%之间变动。这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能就不会显示具体转速值。有的设备不会返回转速,因为它不依赖风扇冷却,而是通过其他外设保持低温,比如我们实验室的服务器是常年放在空掉房间里面的。
- Name:显卡名,以上都是Tesla。
- Temp:显卡内部的温度,以上分别是54、49、46、50、39摄氏度。
- Perf:性能状态,从P0到P12,P0性能最大,P12最小 。
- Persistence-M:持续模式的状态开关,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少。以上都是Off的状态。
- Pwr:能耗表示。
- Bus-Id:涉及GPU总线的相关信息。
- Disp.A:是Display Active的意思,表示GPU的显示是否初始化。
- Memory-Usage:显存的使用率。
- GPU-Util:GPU的利用率。
- Compute M.:计算模式。
- 下面的Process显示每块GPU上每个进程所使用的显存情况。
卸载显卡驱动
如果遇到Nvidia NVML Driver/library version mismatch的问题,又不方便重启实验室服务器,只能重装显卡驱动。因此将卸载显卡驱动的命令记录于此。
卸载显卡驱动:sudo apt-get remove --purge nvidia*
再执行:dpkg -l | grep nvidia
如果还有其他包,也全部卸载。
安装CUDA Toolkit
就安装nvidia-smi中适用于nvidia 535.129.03的最大的cuda版本:12.2
1、去官网选择要安装的版本
2、以cuda 12.2为例,选择系统配置。一定要选择runfile安装,因为使用runfile安装可以选择不安装nvidia驱动,而使用deb安装默认安装nvidia驱动,会出现driver/library version mismatch的问题

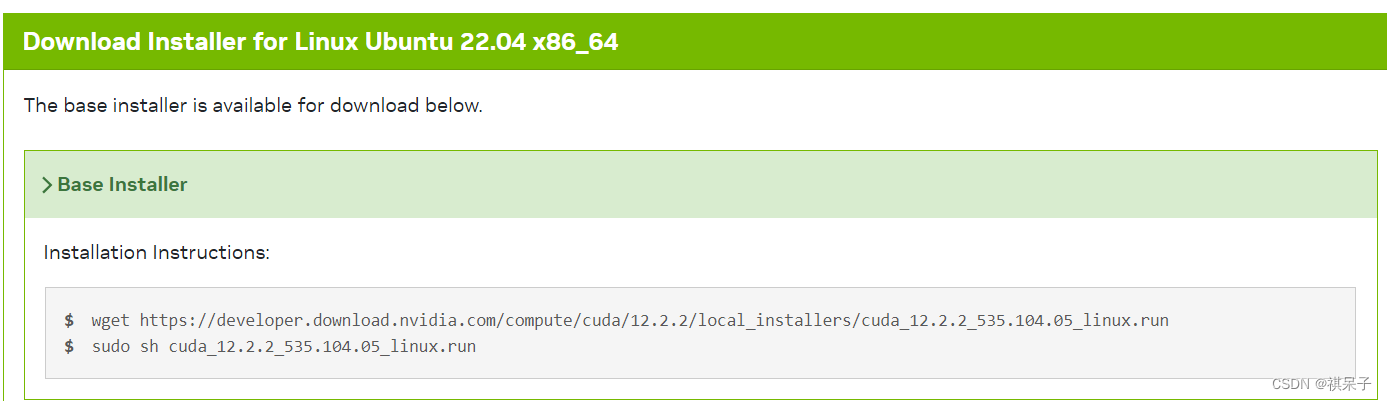
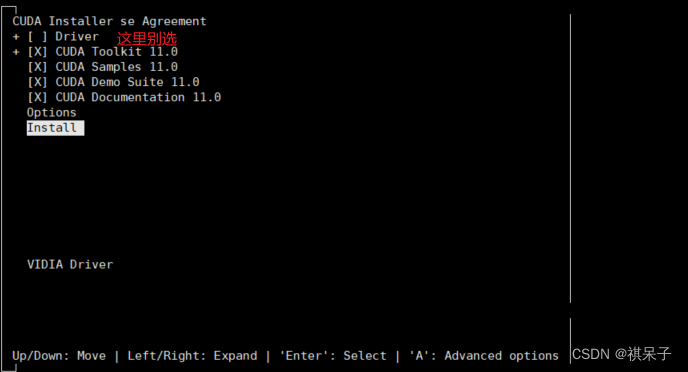
3、执行命令,由于前面已经安装了nvidia驱动,所以在安装选项里要取消Driver
4、将cuda写入环境变量,由于是多用户系统,在~/.bashrc文件(仅当前用户生效)的末尾写入
#####################cuda12.2####################### export PATH=$PATH:/usr/local/cuda-12.2/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.2/lib64 5、source刷新环境变量
source /etc/profile Anaconda虚拟环境配置
安装Anaconda
1、安装Anaconda
在使用服务器时,可以使用Anaconda来创建和管理多个虚拟环境,非常好用。安装步骤如下:
1、去官网下载安装文件
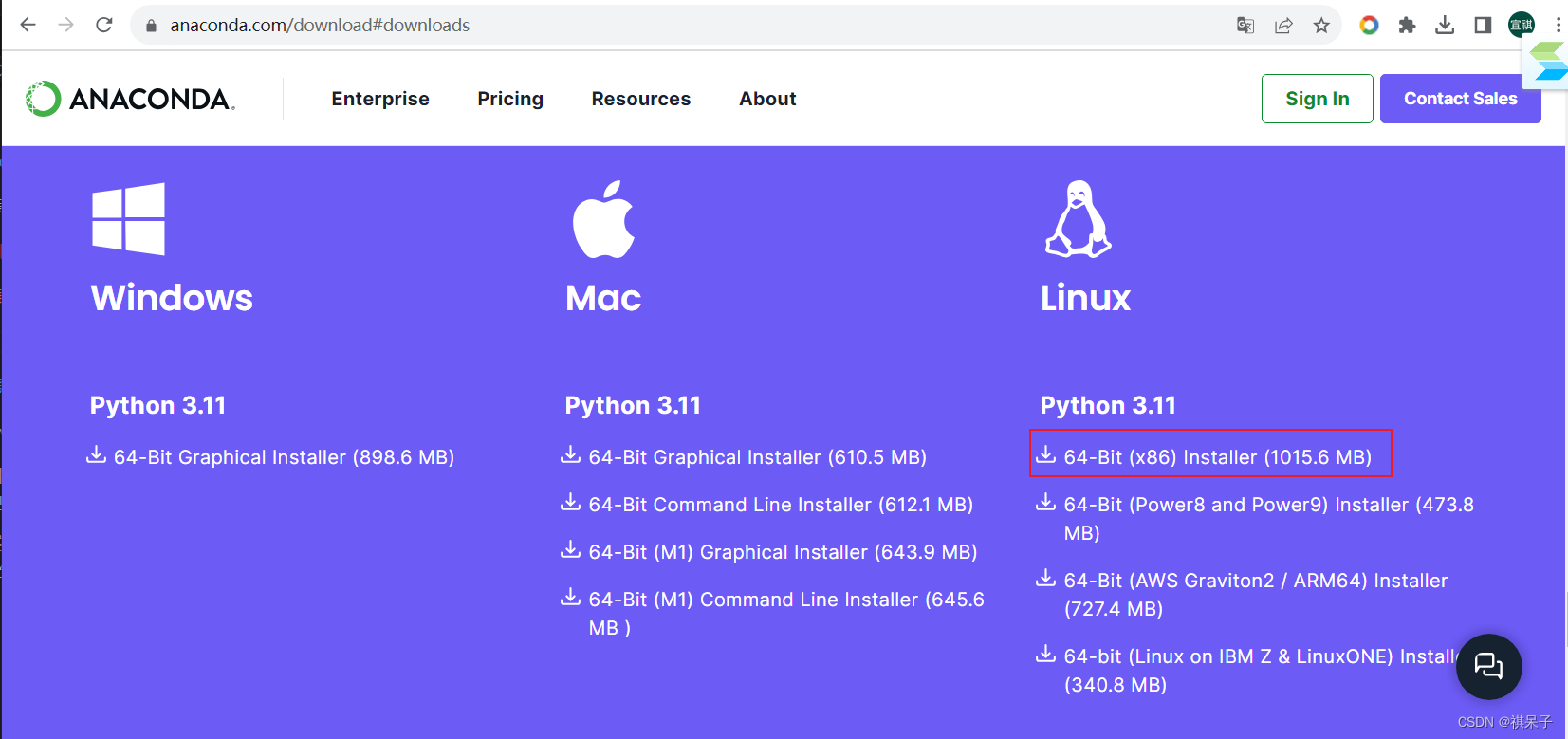
2、上传至服务器并赋予执行权限
chmod +x Anaconda3-2023.09-0-Linux-x86_64.sh 3、安装
sudo ./Anaconda3-2023.09-0-Linux-x86_64.sh 注意,安装路径默认是当前用户的home目录下的anaconda3,例如:~/anaconda3。在询问是否执行conda initialization时,选择yes,这样就不需要自己配置环境变量了(默认写入~/.bashrc文件)。
配置虚拟环境
1、新建一个Python环境
conda create -n test python=3.9 # 新建一个名为test的python3.9环境 conda activate test # 激活test环境 如果激活失败,可以先进入base环境再激活test环境,执行以下命令:
source activate conda activate test 2、在虚拟环境中配置conda和PyTorch-GPU
去官网查看对应版本的安装命令并执行
不幸的发现最高的pytorch只支持cuda12.1版本
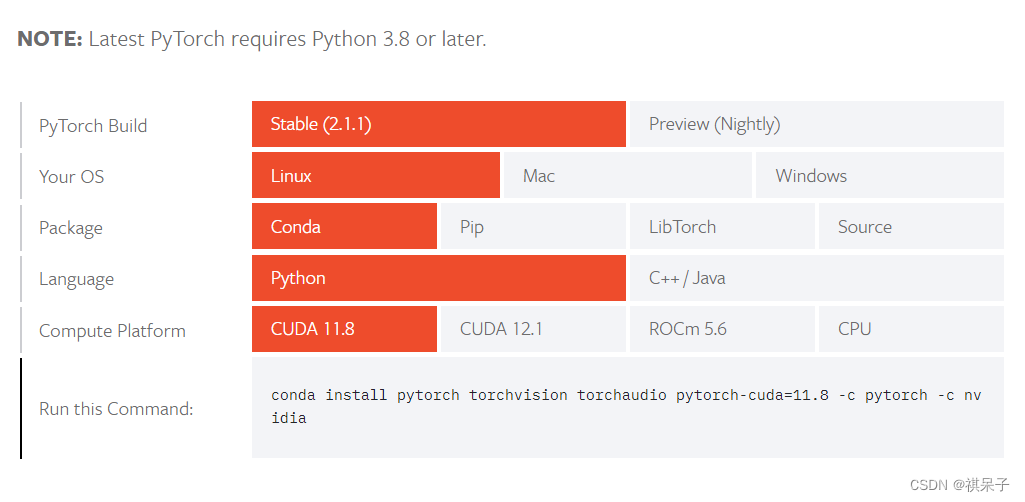
因此我们选择在虚拟环境中安装低版本cuda
conda install cuda=11.8 继续安装版本匹配的pytorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia 验证是否安装成功
import torch print(torch.__version__) print(torch.cuda.is_available()) 注意conda-forge这个通道会比较慢,所以安装pytorch的时候,最好选择不带conda-forge的命令
3、在虚拟环境中配置cudnn
去官网查看cudnn和cuda的版本对应关系

conda找不到对应版本的cudnn
输入命令: conda search cudnn -c conda-forge 然后出现了各个版本的cudnn:
选择一个合适的版本安装,这里选择cudnn 8.9.2.26
conda install cudnn=8.9.2.26 验证cudnn安装成功:conda list | grep cudnn
输出如下,安装成功
cudnn 8.9.2.26 cuda11_0 参考
[2] 【2022新教程】Ubuntu server 20.04如何安装nvidia驱动和cuda-解决服务器ssh一段时间后连不上的问题
