
阅读量:0
Build Triton server without docker and deploy HuggingFace models on Google Colab platform
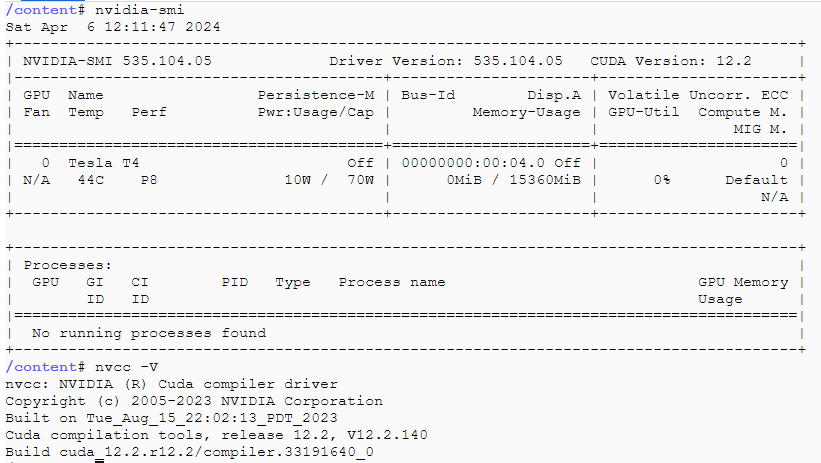
Environment
根据Triton 环境对应表 ,Colab 环境缺少 tensorrt-8.6.1,cudnn9-cuda-12,triton-server 版本应该选择 r23.10。
apt update && apt install -y --no-install-recommends \ ca-certificates autoconf automake build-essential docker.io git libre2-dev libssl-dev libtool libboost-dev \ libcurl4-openssl-dev libb64-dev patchelf python3-dev python3-pip python3-setuptools rapidjson-dev scons \ software-properties-common unzip wget zlib1g-dev libarchive-dev pkg-config uuid-dev libnuma-dev curl \ libboost-all-dev datacenter-gpu-manager cudnn9-cuda-12 pip3 install --upgrade pip && pip3 install --upgrade wheel setuptools tritonclient[all] diffusers>=0.27.0 transformers accelerate safetensors optimum["onnxruntime"] upgrade boost
wget https://boostorg.jfrog.io/artifactory/main/release/1.84.0/source/boost_1_84_0.tar.gz tar -zxvf boost_1_84_0.tar.gz cd boost_1_84_0 chmod -R 777 . ./bootstrap.sh --with-libraries=all --with-toolset=gcc ./b2 -j20 toolset=gcc ./b2 install install libarchive
wget https://github.com/libarchive/libarchive/releases/download/v3.6.2/libarchive-3.6.2.tar.gz tar -zxvf libarchive-3.6.2.tar.gz cd libarchive-3.6.2 ./configure make sudo make install install tensorrt-8.6.1
# 方法一 wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/8.6.1/tars/TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-12.0.tar.gz tar -xvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-12.0.tar.gz sudo mv TensorRT-8.6.1.6/ /usr/local/ vim ~/.bashrc export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/TensorRT-8.6.1.6/lib source ~/.bashrc # 方法二 wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/8.6.1/local_repos/nv-tensorrt-local-repo-ubuntu2204-8.6.1-cuda-12.0_1.0-1_amd64.deb sudo cp /var/nv-tensorrt-local-repo-ubuntu2204-8.6.1-cuda-12.0/nv-tensorrt-local-42B2FC56-keyring.gpg /usr/share/keyrings/ sudo dpkg -i nv-tensorrt-local-repo-ubuntu2204-8.6.1-cuda-12.0_1.0-1_amd64.deb Building Triton server
编译 Triton
git clone -b r23.10 https://github.com/triton-inference-server/server.git # enable-all 编译失败了,原因可能为编译某个 backend 导致的,解决方法未知 ./build.py -v --no-container-build --build-dir=`pwd`/build --enable-all # 自定义参数且只编译 python 后端,成功 ./build.py -v --no-container-build --build-dir=$(pwd)/build --enable-logging --enable-stats --enable-tracing --enable-gpu --endpoint http --endpoint grpc --backend python --extra-core-cmake-arg j=0 设置软链接
ln -s /content/server/build/opt/tritonserver /opt/tritonserver Deploying HuggingFace models
克隆 python_backend,因为我们要使用 python_backend 中的 triton_python_backend_utils
git clone https://github.com/triton-inference-server/python_backend.git -b r23.02 cd python_backend 配置模型库
部署非常能打的文生图大模型 playground-v2.5
mkdir -p models/playground-v2.5/1/ # 配置文件 touch models/playground-v2.5/config.pbtxt # 模型文件 touch models/playground-v2.5/1/model.py # 客户端文件 touch models/playground-v2.5/client.py config.pbtxt
name: "playground-v2.5" backend: "python" max_batch_size: 0 input [ { name: "prompt" data_type: TYPE_STRING dims: [-1, -1] } ] output [ { name: "generated_image" data_type: TYPE_FP32 dims: [-1, -1, -1] } ] instance_group [ { kind: KIND_GPU } ] model.py
import numpy as np import triton_python_backend_utils as pb_utils from transformers import ViTImageProcessor, ViTModel from diffusers import DiffusionPipeline import torch import time import os import shutil import json import numpy as np class TritonPythonModel: def initialize(self, args): self.model = DiffusionPipeline.from_pretrained( "playgroundai/playground-v2.5-1024px-aesthetic", torch_dtype=torch.float16, variant="fp16" ).to("cuda") def execute(self, requests): responses = [] for request in requests: inp = pb_utils.get_input_tensor_by_name(request, "prompt") prompt = inp.as_numpy()[0][0].decode() print(prompt) # prompt = "sailing ship in storm by Leonardo da Vinci, detailed, 8k" image = self.model(prompt=prompt, num_inference_steps=50, guidance_scale=3).images[0] pixel_values = np.asarray(image) inference_response = pb_utils.InferenceResponse( output_tensors=[ pb_utils.Tensor( "generated_image", pixel_values, ) ] ) responses.append(inference_response) return responses 启动 Triton 服务
/opt/tritonserver/bin/tritonserver --model-repository /content/python_backend/models 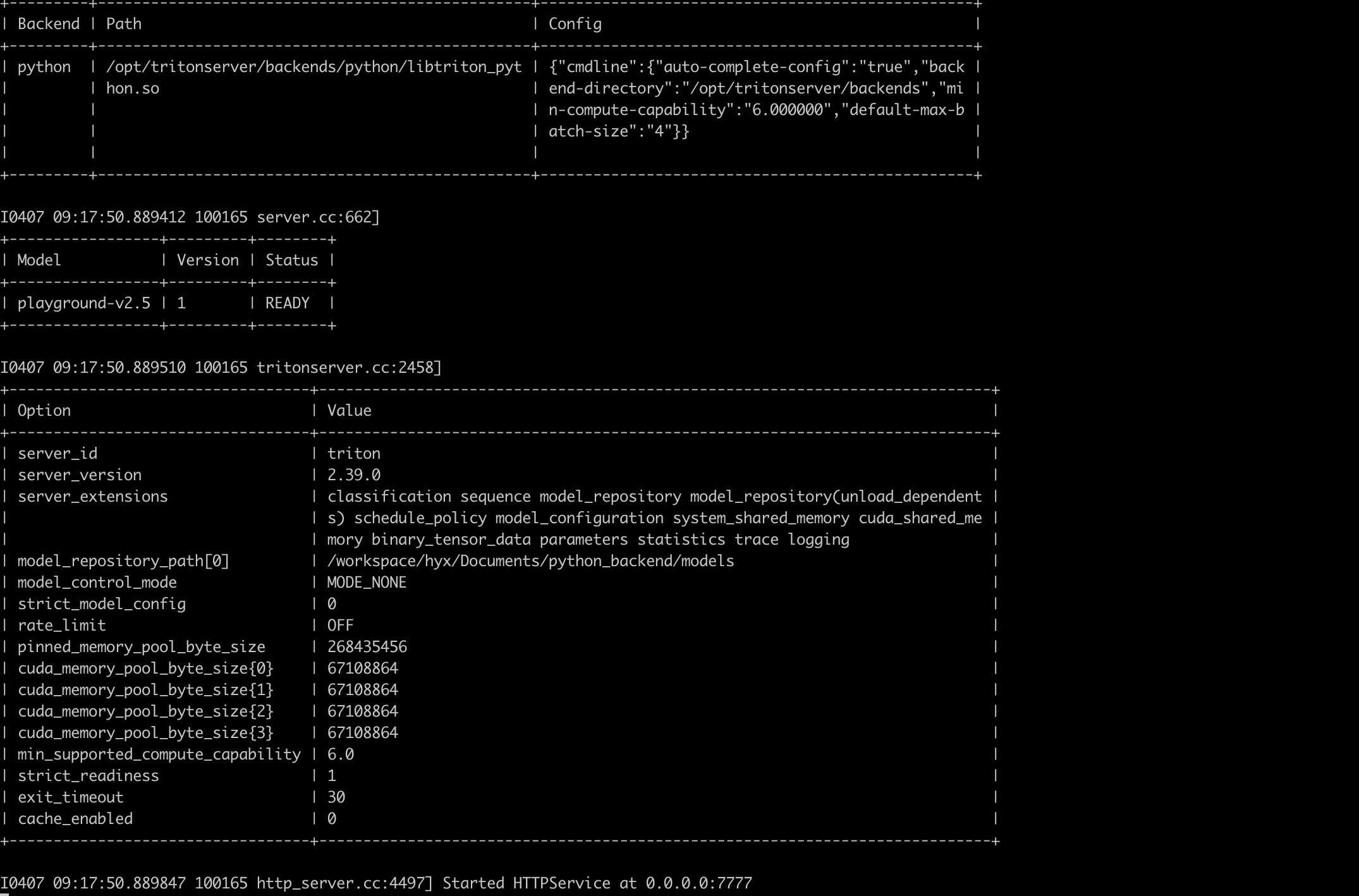
client.py
import time import os import numpy as np import tritonclient.http as httpclient from PIL import Image from tritonclient.utils import * IMAGES_SAVE_DIR = "/content/images/" def text2image(prompt): if not os.path.exists(IMAGES_SAVE_DIR): os.makedirs(IMAGES_SAVE_DIR) client = httpclient.InferenceServerClient(url="localhost:8000") text_obj = np.array([prompt], dtype="object").reshape((-1, 1)) input_text = httpclient.InferInput( "prompt", text_obj.shape, np_to_triton_dtype(text_obj.dtype) ) input_text.set_data_from_numpy(text_obj) output_img = httpclient.InferRequestedOutput("generated_image") timestamp = str(int(time.time())) filename = timestamp + ".png" output_path = IMAGES_SAVE_DIR + filename query_response = client.infer( model_name="playground-v2.5", inputs=[input_text], outputs=[output_img] ) image = query_response.as_numpy("generated_image") im = Image.fromarray(np.squeeze(image.astype(np.uint8))) im.save(output_path) return output_path if __name__ == '__main__': start = time.time() prompt = "A beautiful Asian girl is sitting in a rocking chair in a beautiful garden, holding a cute kitten, admiring the beautiful scenery, with willow trees and a river." image_path = text2image(prompt) end = time.time() print("Time taken:", end - start) 客户端
python client.py

更多示例
Space ship.

The West Lake
