
阅读量:1
提示:服务器卡顿、CPU飙升、接口负载剧增排查思路
服务器卡顿、CPU飙升、接口负载剧增
一、线上服务器CPU飙升,如何定位到Java代码?
解决这个问题的关键是要找到Java代码的位置。下面分享一下排查思路,以CentOS为例,总结为4步。
第1步,使用top命令找到占用CPU高的进程。
第2步,使用ps –mp命令找到进程下占用CPU高的线程ID。
第3步,使用printf命令将线程ID转换成十六进制数。
第4步,使用jstack命令输出线程运行状态的日志信息。
下面详细介绍每一步的操作。
第1步,在使用top命令之后,可以看到一个列表,其中包含PID(进程ID)、USER(操作用户)、CPU占用率、内存占用率、TIME+(运行时间)、COMMAND(运行命令)等信息。一般默认按CPU占用率从上到下降序排列,如下图所示。
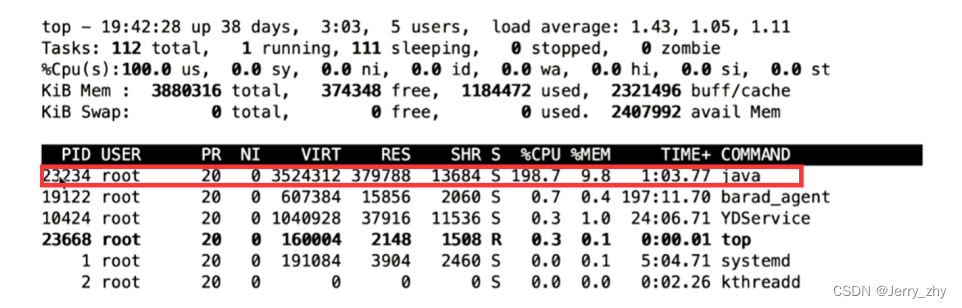
我们找到COMMAND列是java的这一行,说明这个程序就是用Java编写的。然后,用记事本记下这一行的PID,也就是进程ID。
第2步,使用ps -mp命令,输出这个PID下面的线程运行情况列表,如下图所示。
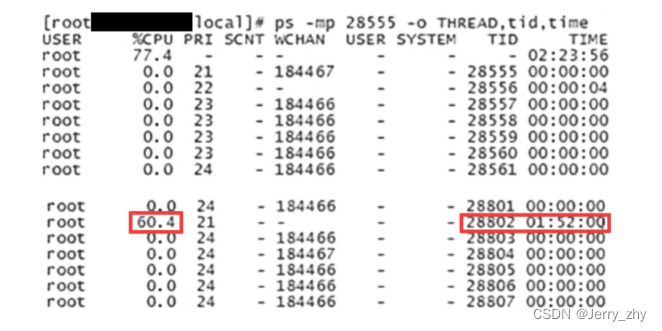
在这个列表中包含了几个关键字段,比如CPU占用率、TID(线程ID)、TIME(运行时间)等。在这个列表中找到CPU占用最高的线程,记下TID,也就是线程ID。前面记下的TID是一个十进制数,不能直接使用,需要转化为十六进制数。
第3步,使用 printf 命令将TID转换为十六进制数,如下图所示。

这样就得到了真正占用CPU过高的线程ID。
第4步,使用jstack命令输出线程的具体运行日志,如下图所示。
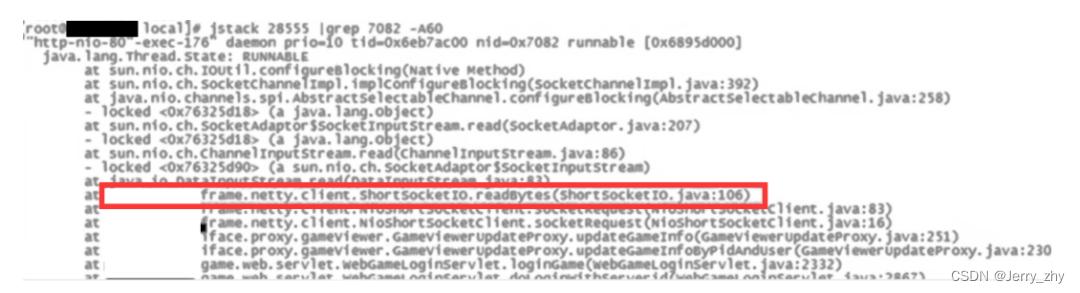
jstack有3个参数,第1个参数是前面记下的 PID,之后加上 grep,紧跟着是转成十六进制数的TID,最后加上 –A和一个数字,这个数字表示输出日志的行数,至此就可以直接打印出具体的异常信息了。
如果日志信息比较多,异常内容比较复杂,则可以把这些异常信息输出到一个 txt文件中,慢慢分析。只需要在 jstack命令的最后追加 txt 文件名就可以了。
jstack PID | grep TID -A60 >> error_log.txt 二、生产环境服务器变慢,如何诊断处理?
生产环境服务器变慢主要涉及3个维度:CPU利用率、磁盘I/O效率、内存瓶颈。
1. CPU利用率
CPU利用率过高或者CPU利用率过低,都会影响程序的处理效率。CPU利用率过高,说明当前服务器要处理的指令比较多,当CPU忙不过来的时候,指令的运行效率自然就会下降,用户的感受就是程序响应变慢了。
针对这个问题,我们可以使用top命令查询当前系统中占用CPU过高的进程,并定位到这个进程中比较活跃的线程。再通过jstack命令打印当前虚拟机的线程快照,根据快照日志排查问题代码。
如果CPU利用率过低,则说明程序资源使用不够,可以增加线程数量提升程序性能。
2. 磁盘I/O效率
在程序运行过程中会直接或者间接涉及一些与磁盘I/O相关的操作,比如程序直接读/写磁盘或者程序依赖的第三方组件对磁盘进行持久化存储,此时磁盘I/O效率就会对程序运行效率产生影响。
针对这种情况可以使用iostat命令查看,如果磁盘负载较高,可以针对性地进行优化。比如,借助缓存系统,减少磁盘I/O次数;用顺序写替代随机写入,减少寻址开销;使用mmap替代read/write,减少内存拷贝次数。另外,磁盘I/O效率可以通过CPU与负载的非线性关系体现出来。当负载增大时,系统吞吐量不能有效增大,CPU不能线性增长,则很可能是磁盘I/O出现阻塞。
3. 内存瓶颈
内存作为一块临时存储数据的组件,所有CPU运行的指令都需要从内存中去读/写。内存的合理使用可以减少应用和磁盘的I/O频率,减少网络I/O的频率,极大地提升I/O性能。
JVM对内存的合理分配,能够避免频繁的YGC和FULL GC。当内存使用率较高时,可以用dump命令查出JVM堆内存,用MAT工具进行分析,查出大对象或者占用内存最多的对象,以及排查是否存在内存泄漏的问题。如果用 dump 命令查出的堆内存文件正常,则可以考虑是堆外内存被大量使用导致出现问题,此时需要借助操作系统的pmap命令查出进程的内存分配情况。如果CPU和内存使用率都很正常,那么就需要进一步开启GC日志,分析用户线程暂停的时间、各部分内存区域GC次数和时间等指标,这里可以借助jstat命令或可视化工具GCEasy等。如果问题出在GC上,则考虑是不是内存不足,然后根据垃圾对象的特点进行参数调优,使用更适合的垃圾收集器,用jstack命令分析各个线程的状态。如果问题比较隐蔽,则考虑是否开启JMX,使用 visualmv 等可视化工具进行远程监控与分析
3、线上接口负载剧增,快扛不住了,你的首选方案是什么?
遇到这样的问题,我们的第一反应应该是增加缓存。因为,增加缓存是解决系统性能问题最快速、最高效的方案,它能够快速提升系统的线性吞吐量,效果也最为明显。这就相当于是用空间来换取时间。曾经有人说过,缓存是解决性能问题的万金油,哪里存在性能瓶颈,就往哪里加缓存。
但是程序都已经上线了,增加缓存还来得及吗?因为在增加缓存时需要改代码,所以,临时解决方案就是增加节点。随后,将程序紧急部署到新的节点上,在流量入口增加限流和分发。但是增加节点自然会增加成本,所以增加缓存才是最优的解决方案。
缓存的设计思想在架构设计中十分常见。比如我们每天用的操作系统,不管是Windows、Linux,还是Mac OS都有系统缓存、用户缓存。磁盘有磁盘缓存区、CPU有CPU缓存区。再比如,在我们常用的经典框架中,也经常使用到缓存,Spring有IoC缓存,MyBatis有一级缓存、二级缓存。在架构设计中,可以说缓存无处不在。因此,当并发量过高扛不住的时候,可以优先采用缓存来缓解负载压力。比如将读取频繁的数据写到缓存中,将动态页面静态化。在加上缓存之后,如果负载压力依然过大,则再考虑增加限流策略,比如消息队列;如果在增加限流后还是压力过大,则再考虑增加服务器节点。
总结
提示:这里只作为学习记录,感谢原文作者分享。
原文链接:https://mp.weixin.qq.com/s/zq8CZkSJxt_KW8MFgxYizw
