
阅读量:1
[mysqld]innodb_force_recovery = 1
如果innodb_force_recovery = 1不生效,则可尝试2——6几个数字
然后重启mysql,重启成功。然后使用mysqldump或 pma 导出数据,执行修复操作等。修复完成后,把该参数注释掉,还原默认值0。
配置文件的参数:innodb_force_recovery
innodb_force_recovery影响整个InnoDB存储引擎的恢复状况。默认为0,表示当需要恢复时执行所有的恢复操作(即校验数据页/purge undo/insert buffer merge/rolling back&forward),当不能进行有效的恢复操作时,mysql有可能无法启动,并记录错误日志;
innodb_force_recovery可以设置为1-6,大的数字包含前面所有数字的影响。当设置参数值大于0后,可以对表进行select,create,drop操作,但insert,update或者delete这类操作是不允许的。
(SRV_FORCE_IGNORE_CORRUPT):忽略检查到的corrupt页。
(SRV_FORCE_NO_BACKGROUND):阻止主线程的运行,如主线程需要执行full purge操作,会导致crash。
(SRV_FORCE_NO_TRX_UNDO):不执行事务回滚操作。
(SRV_FORCE_NO_IBUF_MERGE):不执行插入缓冲的合并操作。
(SRV_FORCE_NO_UNDO_LOG_SCAN):不查看重做日志,InnoDB存储引擎会将未提交的事务视为已提交。
(SRV_FORCE_NO_LOG_REDO):不执行前滚的操作。
主库解决方案
一般修复方法参考:
第一种方法
建立一张新表:
create table demo_bak #和原表结构一样,只是把INNODB改成了MYISAM。
把数据导进去
insert into demo_bak select * from demo;
删除掉原表:
drop table demo;
注释掉 innodb_force_recovery 之后,重启。
重命名:
rename table demo_bak to demo;
最后改回存储引擎:
alter table demo engine = innodb
第二种方法
另一个方法是使用mysqldump将表格导出,然后再导回到InnoDB表中。这两种方法的结果是相同的。
备份导出(包括结构和数据):
mysqldump -uroot -p123 test > test.sql
还原方法1:
use test;source test.sql
还原方法2(系统命令行):
mysql -uroot -p123 test < test.sql;
注意,CHECK TABLE命令在InnoDB数据库中基本上是没有用的。
第三种方法
(1)配置my.cnf
配置innodb_force_recovery = 1或2——6几个数字,重启MySQL
(2)导出数据脚本
mysqldump -uroot -p123 test > test.sql
导出SQL脚本。或者用Navicat将所有数据库/表导入到其他服务器的数据库中。
注意:这里的数据一定要备份成功。然后删除原数据库中的数据。
(3)删除ib_logfile0、ib_logfile1、ibdata1
备份MySQL数据目录下的ib_logfile0、ib_logfile1、ibdata1三个文件,然后将这三个文件删除
(4)配置my.cnf
将my.cnf中innodb_force_recovery = 1或2——6几个数字这行配置删除或者配置为innodb_force_recovery = 0,重启MySQL服务
(5)将数据导入MySQL数据库
mysql -uroot -p123 test < test.sql; 或者用Navicat将备份的数据导入到数据库中。
此种方法下要注意的问题:
ib_logfile0、ib_logfile1、ibdata1这三个文件一定要先备份后删除;
一定要确认原数据导出成功了
当数据导出成功后,删除原数据库中的数据时,如果提示不能删除,可在命令行进入MySQL的数据目录,手动删除相关数据库的文件夹或者数据库文件夹下的数据表文件,前提是数据一定导出或备份成功。
这里,我使用的是第三种方法恢复了主数据库的数据。
接下来,我们再来看看从数据库数据的恢复。
主从复制原理
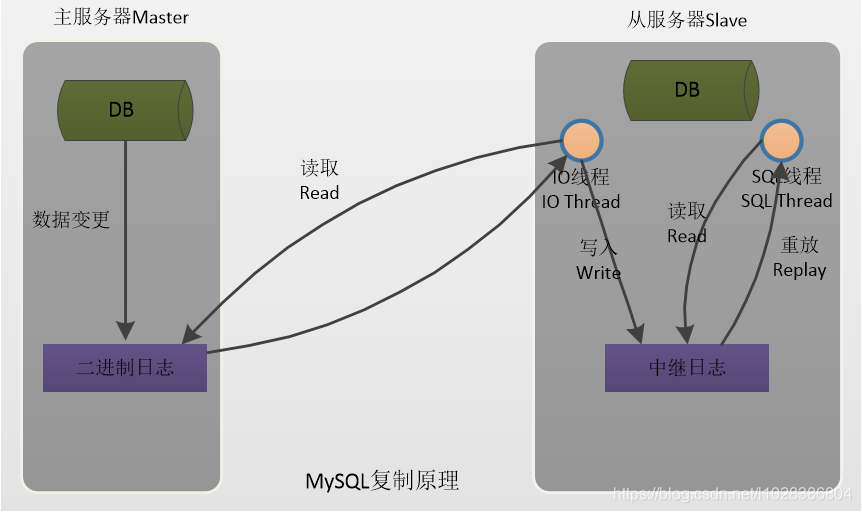
这里,我就简单的说下MySQL数据库的主从复制原理。
MySQL主从复制原理,也称为A/B原理。
(1) Master 将数据改变记录到二进制日志(binary log)中,也就是配置文件 log-bin 指定的文件, 这些记录叫做二进制日志事件(binary log events);
(2) Slave 通过 I/O 线程读取 Master 中的 binary log events 并写入到它的中继日志(relay log);
(3) Slave 重做中继日志中的事件,把中继日志中的事件信息一条一条的在本地执行一次,完 成数据在本地的存储,从而实现将改变反映到它自己的数据(数据重放)。
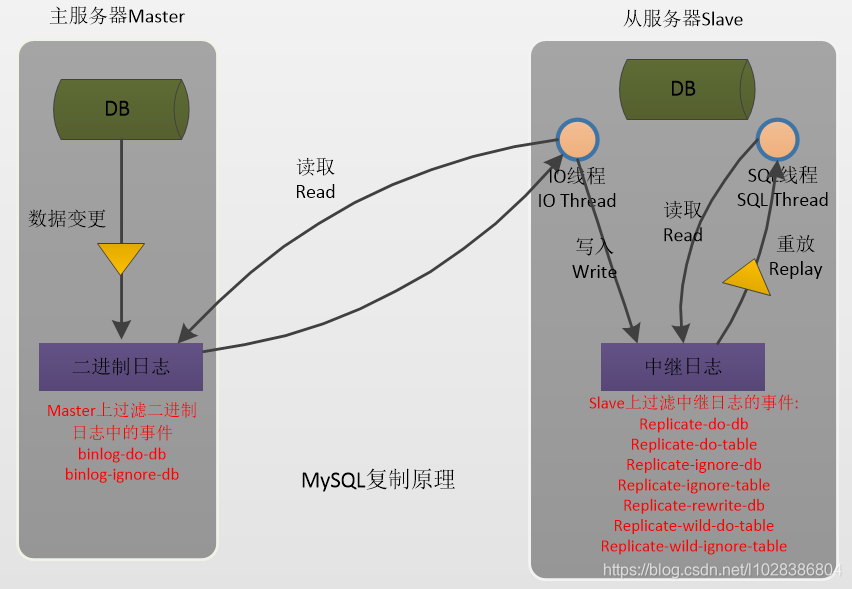
复制过滤可以让你只复制服务器中的一部分数据,有两种复制过滤:
(1) 在 Master 上过滤二进制日志中的事件;
(2) 在 Slave 上过滤中继日志中的事件。如下:
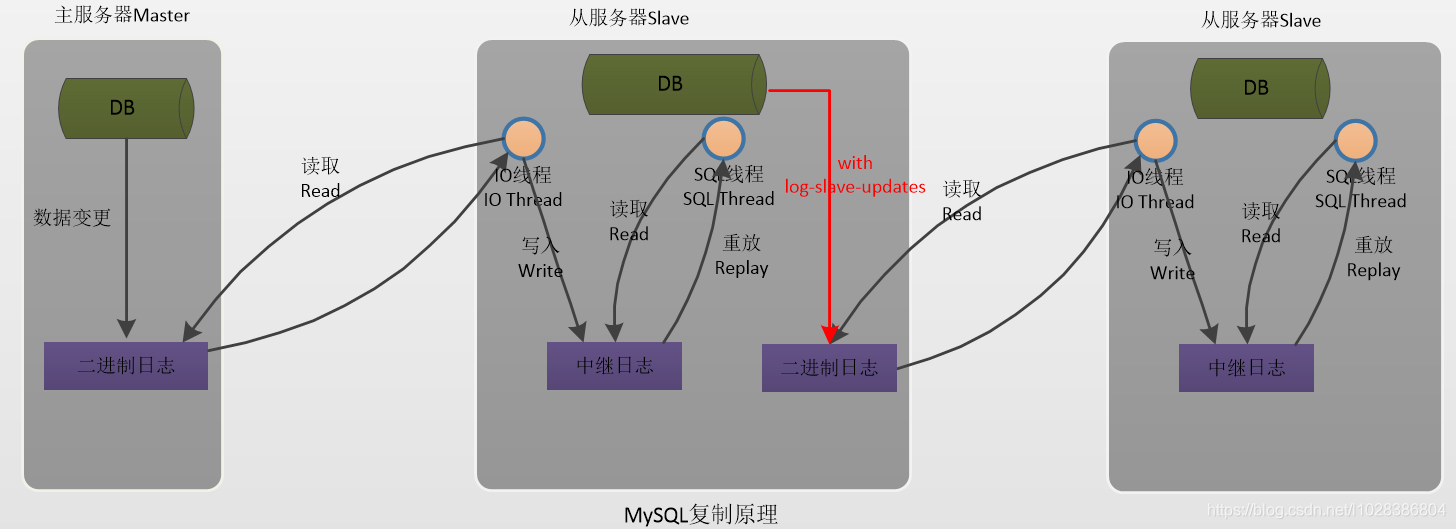
relay_log配置中继日志,log_slave_updates表示slave将复制事件 写进自己的二进制日志.当设置log_slave_updates时,你可以让slave扮演其它slave的master.此时,slave把sql线程执行的事件写进自己的二进制日志(binary log)然后,它的slave可以获取这些事件并执行它。如下图所示(发送复制事件到其它的Slave):
从库问题重现
恢复主库的数据后,向主库中插入了一批测试数据,大概有1000条,但是插入数据后,从库迟迟没有将数据同步过来。于是我先登录主库,执行如下命令。
mysql>show processlist;
查看下进程是否Sleep太多。发现很正常。
再查看下主库的状态。
show master status;
也正常。
mysql> show master status;
±------------------±---------±-------------±------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
±------------------±---------±-------------±------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
±------------------±---------±-------------±------------------------------+
1 row in set (0.00 sec)
再到从库上查看从库的状态。
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
发现是Slave不同步了。这里,如果主从数据库版本一致或不一致又会存在两种解决方案。
主从版本一致解决方案
下面介绍两种解决方法
方法一:忽略错误后,继续同步
该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况
解决:
stop slave;
#表示跳过一步错误,后面的数字可变
set global sql_slave_skip_counter =1;
start slave;
之后再用mysql> show slave status\G 查看
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
ok,现在主从同步状态正常了。。。
方式二:重新做主从,完全同步
该方法适用于主从库数据相差较大,或者要求数据完全统一的情况
解决步骤如下:
(1)先进入主库,进行锁表,防止数据写入
使用命令:
mysql> flush tables with read lock;
注意:该处是锁定为只读状态,语句不区分大小写
(2)进行数据备份
#把数据备份到mysql.bak.sql文件
mysqldump -uroot -p -hlocalhost > mysql.bak.sql
这里注意一点:数据库备份一定要定期进行,可以用shell脚本或者python脚本,都比较方便,确保数据万无一失。
(3)查看master 状态
mysql> show master status;
±------------------±---------±-------------±------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
±------------------±---------±-------------±------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
±------------------±---------±-------------±------------------------------+
1 row in set (0.00 sec)
(4)把mysql备份文件传到从库机器,进行数据恢复
scp mysql.bak.sql root@192.168.128.101:/tmp/
(5)停止从库的状态
mysql> stop slave;
(6)然后到从库执行mysql命令,导入数据备份
mysql> source /tmp/mysql.bak.sql
(7)设置从库同步,注意该处的同步点,就是主库show master status信息里的| File| Position两项
change master to master_host = ‘192.168.128.100’, master_user = ‘rsync’, master_port=3306, master_password=‘’, master_log_file = ‘mysqld-bin.000001’, master_log_pos=3260;
(8)重新开启从同步
mysql> start slave;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后总结我的面试经验
2021年的金三银四一眨眼就到了,对于很多人来说是跳槽的好机会,大厂面试远没有我们想的那么困难,摆好心态,做好准备,你也可以的。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
BAT面试经验
实战系列:Spring全家桶+Redis等
其他相关的电子书:源码+调优
面试真题:
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
54671a72faed303032d36.jpg" alt=“img” style=“zoom: 33%;” />
最后总结我的面试经验
2021年的金三银四一眨眼就到了,对于很多人来说是跳槽的好机会,大厂面试远没有我们想的那么困难,摆好心态,做好准备,你也可以的。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
[外链图片转存中…(img-yxxsNHkc-1713600959409)]
BAT面试经验
实战系列:Spring全家桶+Redis等
[外链图片转存中…(img-Fg8jP4xf-1713600959410)]
其他相关的电子书:源码+调优
[外链图片转存中…(img-LDQVadYj-1713600959410)]
面试真题:
[外链图片转存中…(img-6KV8dMGC-1713600959410)]
[外链图片转存中…(img-bxwJ9dE9-1713600959411)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
