
阅读量:1
一、Scrapy框架
1、概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包
pip install scrapy
scrapy的组成结构如下图所示
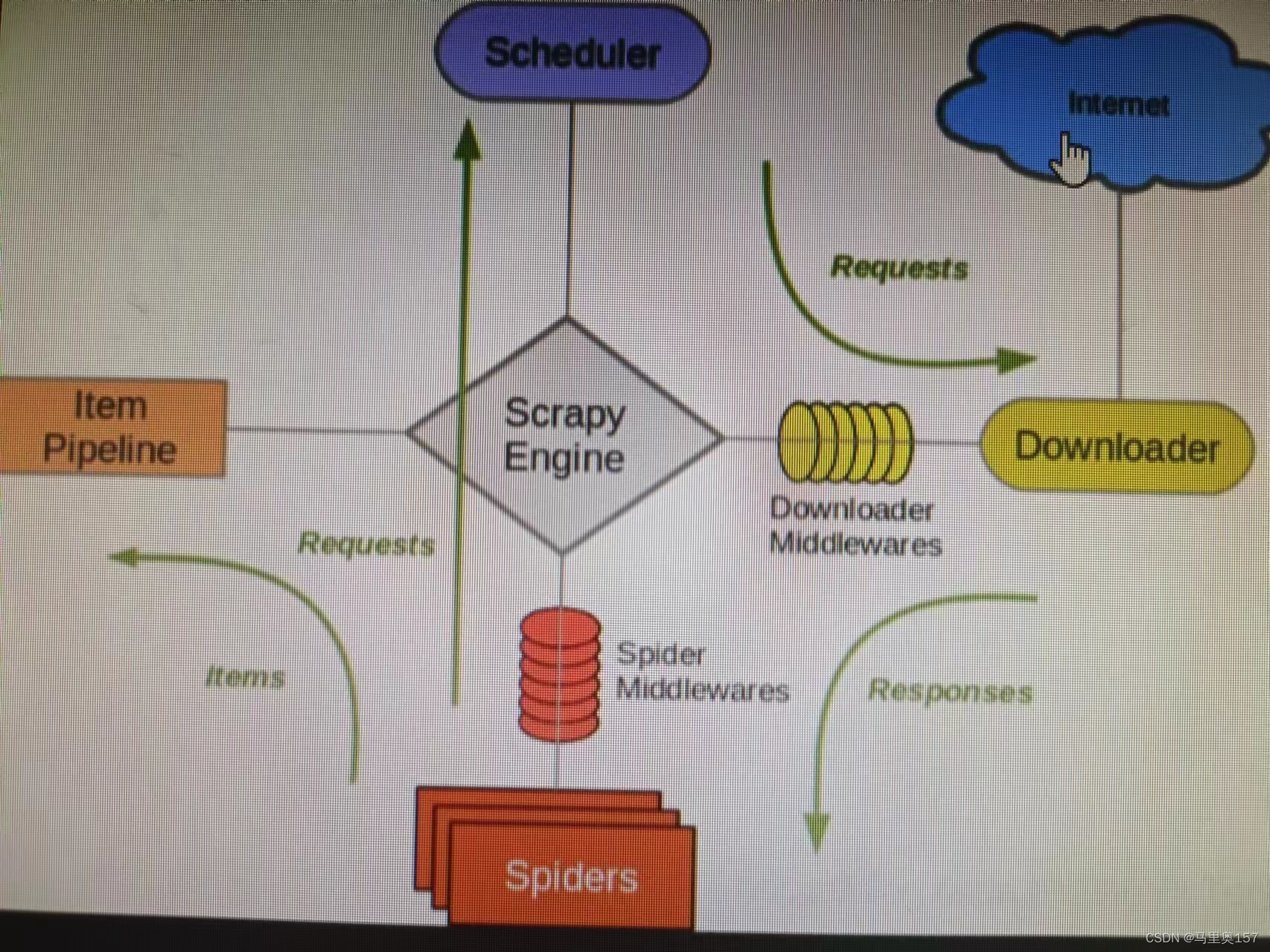
2. 概念和工作原理
在开始使用 Scrapy 构建爬虫之前,了解其核心概念和工作原理是非常重要的。Scrapy 的设计思想是基于一系列组件的协同工作,以实现高效的网络数据爬取和处理。在本部分,我们将介绍 Scrapy 的主要组成部分以及其工作流程。
2.1 组件介绍
Scrapy 主要由以下组件组成:
引擎(Engine): 负责控制整个爬虫系统的流程,包括调度器、下载器和爬虫之间的通信。它负责调度并协调各个组件的工作。
调度器(Scheduler): 负责接收引擎发送过来的请求,并按照一定的策略将这些请求排队,然后发送给下载器。
下载器(Downloader): 负责下载引擎发送过来的请求对应的页面,并将下载到的页面内容返回给引擎。
爬虫(Spiders): 爬虫是用户编写的一组类,用于定义如何爬取特定网站(或者一组网站)的数据。每个爬虫都包含了一些用于从网页中提取数据的解析规则。
管道(Pipeline): 管道负责处理爬虫从网页中抽取出来的数据,并进行后续的处理,比如数据清洗、存储等操作。
下载中间件(Downloader Middleware): 下载中间件是介于引擎和下载器之间的组件,它可以对请求和响应进行预处理或后处理。
爬虫中间件(Spider Middleware): 爬虫中间件是介于引擎和爬虫之间的组件,它可以对请求和数据进行预处理或后处理。
3. 创建新的 Scrapy 项目
首先在存放项目的文件夹内打开命令行,在命令行下输入scrapy startproject 项目名称,就会在当前文件夹自动创建项目所需的python文件,例如创建一个爬取豆瓣电影的项目douban,其目录结构如下:
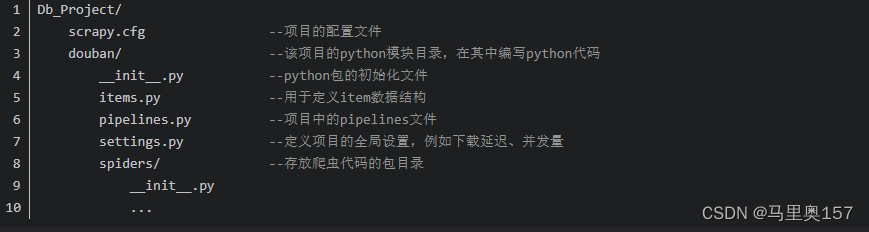
之后进入spiders目录下输入scrapy genspider 爬虫名 域名,就会生成爬虫文件douban.py文件,用于之后定义爬虫的爬取逻辑和正则表达式等内容
![]()
二、实践:使用 Scrapy 爬取豆瓣电影 Top250
1.定义数据模型
在 Scrapy 中,我们使用 Item 对象来表示爬取到的数据。为了清晰地组织数据,我们需要定义一个数据模型来描述我们感兴趣的信息。在这个项目中,我们主要关注豆瓣电影 Top250 页面中的电影信息,因此我们创建一个名为 MovieItem 的数据模型来存储这些信息。
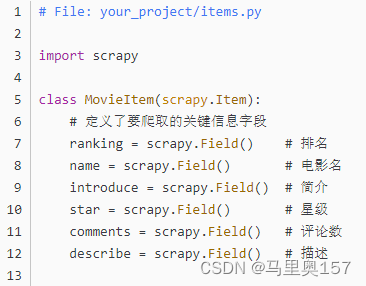
以上代码将这些信息定义为 Scrapy 的 Field 类型,这样可以方便后续爬取和处理。每个字段都对应了我们所感兴趣的电影信息,如排名、电影名、简介、星级、评论数和描述等。
2.中间件设置
有时为了应对网站的反爬虫机制,我们需要对 Scrapy 的下载中间件进行一些设置,以伪装请求并防止被识别为爬虫。在这个项目中,我们可以通过设置随机的 User-Agent 和使用 IP 代理来模拟不同的用户和 IP 地址发送请求。
首先,我们需要在中间件中添加随机 User-Agent 的设置。我们可以在 middlewares.py 文件中创建一个类,名为 RandomUserAgentMiddleware,用于为每个请求随机选择一个 User-Agent,并将其添加到请求头中。
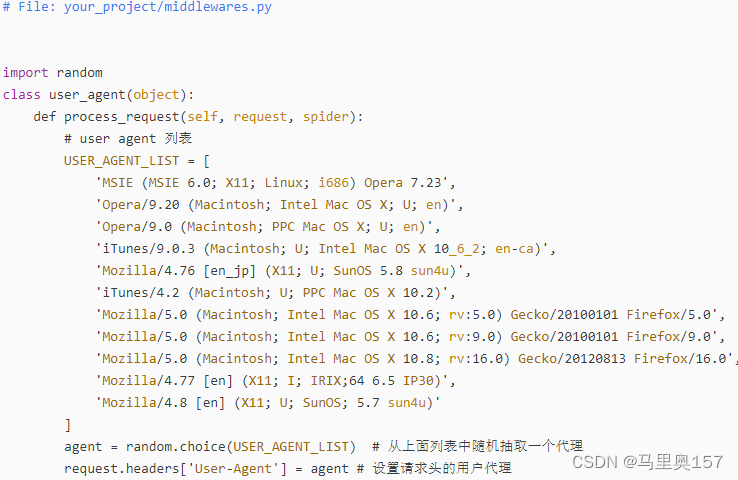
在上述代码中,我们创建了一个名为 RandomUserAgentMiddleware 的类,它的 process_request 方法用于处理每个请求,为每个请求随机选择一个 User-Agent,并将其添加到请求头中。其中 USER_AGENT_LIST 是在 settings.py 中定义的用户代理列表。
我们还可以添加一个 IP 代理的设置,以应对可能的 IP 封锁或限制。这里不再详细列举代码,你可以在 middlewares.py 中创建一个类来实现该功能,并在 settings.py 中设置相应的 IP 代理列表。
最后,我们需要在 settings.py 文件中启用这些中间件,并设置它们的优先级:
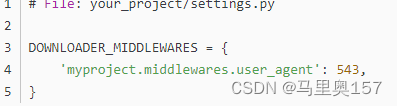
在上述代码中,我们将 RandomUserAgentMiddleware 设置为 DOWNLOADER_MIDDLEWARES 字典的值,并指定了优先级为 543。你也可以根据实际情况添加 IP 代理中间件,并设置相应的优先级。
这样,当我们运行 Scrapy 项目时,每个请求就会随机选择一个 User-Agent,并根据需要使用 IP 代理发送请求,以应对网站的反爬虫机制。
3.数据存储
当我们选择将数据存储到 CSV 文件中时,我们需要在 Scrapy 项目中编写一个专门的 Pipeline,负责将爬取到的数据写入 CSV 文件中。下面是一个示例:
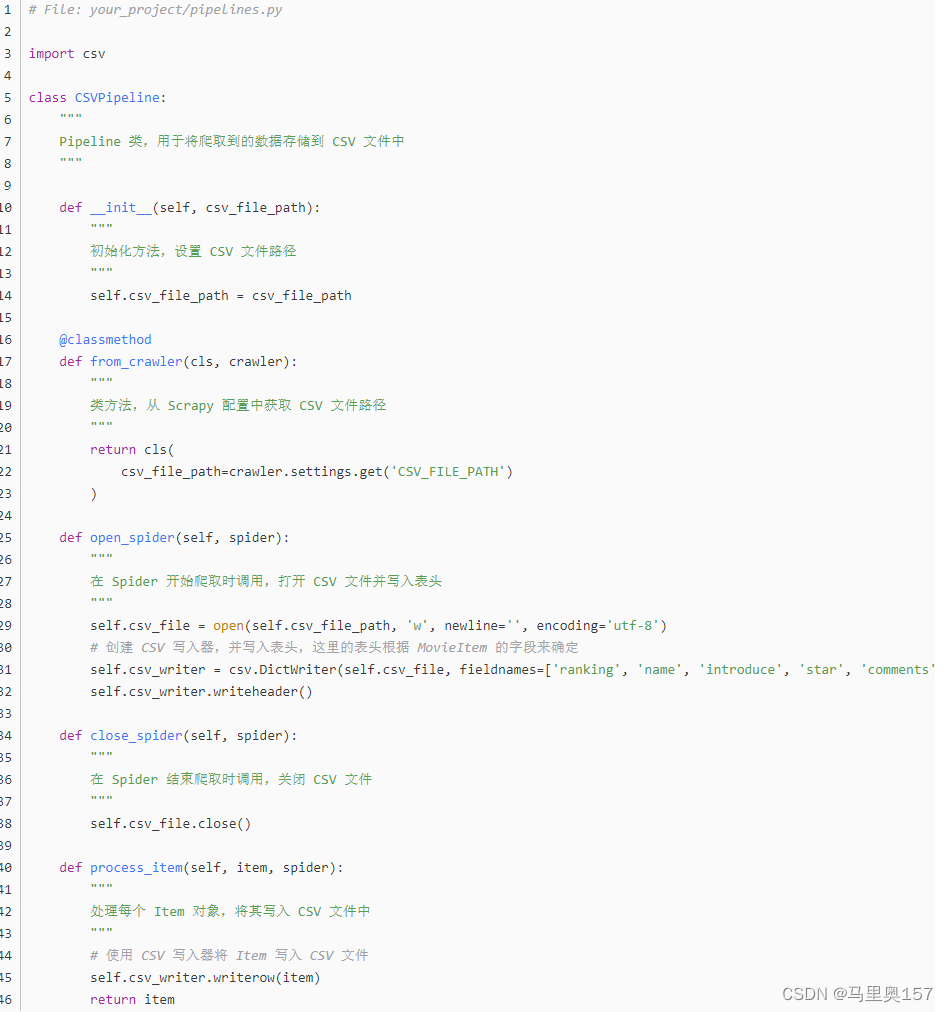
在上述代码中,我们定义了一个名为 CSVPipeline 的 Pipeline 类,它负责将爬取到的数据存储到 CSV 文件中。在该 Pipeline 中,我们实现了四个方法:

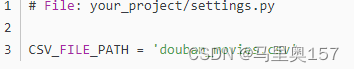
接下来,我们需要在 Scrapy 项目的 settings.py 文件中设置 CSV 文件的路径:
最后,我们需要在 settings.py 中启用该 Pipeline:
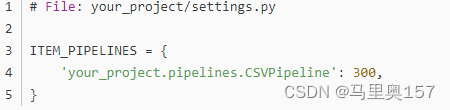
这样,当我们运行 Scrapy 项目时,爬取到的电影信息就会被存储到名为 douban_movies.csv 的 CSV 文件中了
4.启动Scrapy项目
4.1 使用命令行工具
Scrapy提供了命令行工具,可以让你直接在终端中启动项目。使用 scrapy crawl 命令,你可以指定要运行的Spider以及输出的文件格式和路径。例如:
![]()
4.2使用Scrapyd
Scrapyd是一个用于部署和管理Scrapy项目的工具,你可以将Scrapy项目部署到Scrapyd服务器上,并通过HTTP API来控制项目的启动和停止。
通过以上几种启动方法,你可以根据项目需求和个人偏好来选择最合适的方式。Scrapy提供了灵活而强大的工具来满足你的爬虫需求。
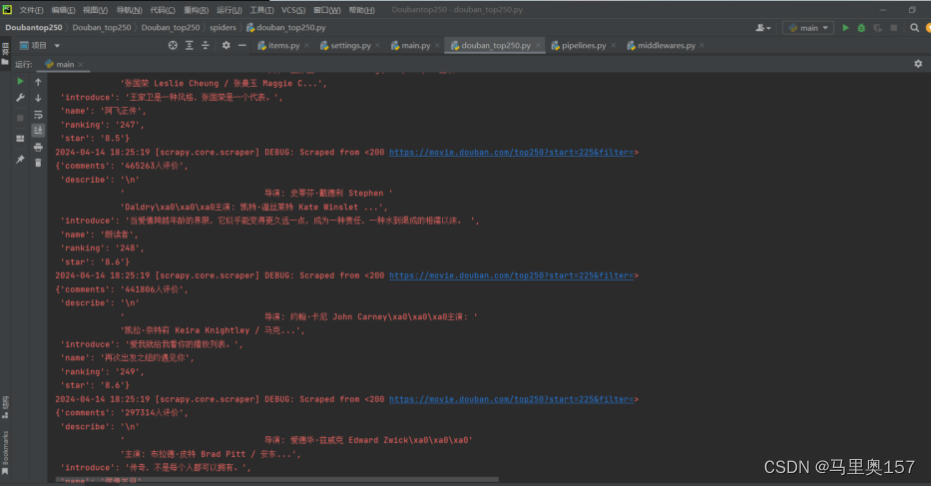
三、使用正则表达式从电影介绍详情中提取指定信息
在这个项目中,我们仍然可以套用第二部分的大致代码结构,但需要针对新的需求进行一些调整。主要区分点包括:
爬取的内容不同,需要重写 items 类:
由于我们要从电影详情页面提取的信息不同于之前的需求,我们需要重新定义 items.py 文件中的数据模型。这意味着我们需要修改数据模型中的字段,以便适应新的数据结构。例如,我们可能需要添加一个字段来存储电影简介中的括号内容。
根据网页具体情况重写 spider 文件:
鉴于我们现在要爬取的是豆瓣电影详情页面,而不是之前的 Top250 页面,我们需要对 spider.py 文件进行重写。这意味着我们需要更新爬取页面的 URL,修改解析函数以匹配电影详情页面的 HTML 结构,并调整数据提取逻辑以确保我们可以准确地提取电影简介中的括号内容。
除了这些主要区分点之外,我们的项目结构和工作流程将保持大致相同。我们仍然会使用 Scrapy 框架来构建我们的爬虫,利用其强大的功能来快速而高效地提取所需信息。
在下一步中,我们将详细讨论如何重写 items.py 和 spider.py 文件,以满足新的需求。
3.1 xpath选择器
/表示从当前位置的下一级目录进行寻找,//表示从当前位置的任意一级子目录进行寻找,
默认从根目录开始查找,. 代表从当前目录开始查找,@后跟标签属性,text()函数代表取出文字内容
//div[@id='wrapper']//li 代表先从根目录开始查找id为wrapper的div标签,然后取出其下的所有li标签
.//div[@class='pic']/em[1]/text() 代表从当前选择器目录开始查找所有class为pic的div之下的第一个em标签,取出文字内容
string(//div[@id='endText']/p[position()>1]) 代表选取id为endText的div下第二个p标签之后的所有文字内容
/bookstore/book[last()-2] 选取属于 bookstore 子元素的倒数第3个 book 元素。
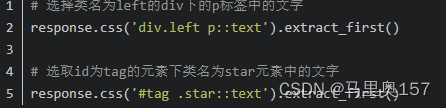
CSS选择器
还可以使用css选择器来选择页面内的元素,其通过CSS伪类的方式表达选择的元素,使用如下
3.2 正则表达式
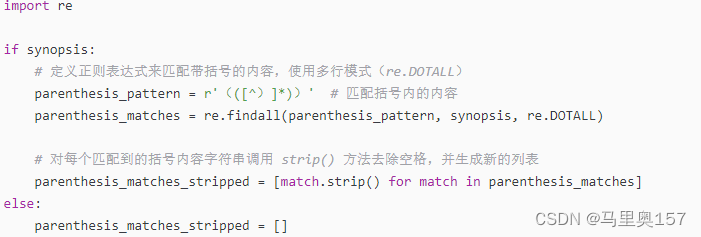
当提取电影简介中的括号内内容时,我们需要使用正则表达式来匹配括号中的文本。但是,并非所有电影简介都包含括号,因此我们需要处理这种情况,以避免出现错误。
代码解析:
解释:

最终爬虫文件如下:

