
阅读量:0
前言
在当今的招聘市场中,数据成为企业决策和个人求职的重要依据。Boss直聘作为国内知名的在线招聘网站,其海量的职位信息为求职者提供了丰富的选择,同时也为企业招聘提供了便利。这篇文章是个简单用scrapy爬取Boss直聘的网站信息的文章,其中可能出现一些不合理的地方或错误,希望对你们有所帮助。
一、Scrapy的框架简介
Scrapy是一个基于Python的开源网络爬虫框架,提供了简单、高效的API来下载和解析网页数据。Scrapy不仅能够处理大规模的网页数据,还提供了多种输出方式,如CSV等,方便后续处理和分析。
本篇文章Scrapy爬虫工程核心工程组成部分包括以下几个关键组件:
Scrapy项目的文件结构:
Scrapy.cfg :Scrapy 项目的配置文件。
_init_.py :Scrapy项目的Python模块,你将在这里定义你的爬虫(如项目路径、模块路径)
items.py :定义你要抓取的数据结构(Item类)。它可以定义了你想要从网页中提取的数据字段
middlewares.py :可选中间件文件,可以在这里定义自己的中间件来修改Scrapy的请求和相应处 理数据
pipelines.py :数据处理管道,比如清洗、验证和存储数据,例如,你可以将数据写入数据 库、csv文件或JSON文件
seetting.py : Scrapy项目的设置文件,在这里可以配置这种设置,如并发请求数、超时时间、代 理设置等
Spiders : 包含你的爬虫目录,定义了如何从一个或多个网页中提取数据
二、所用相关介绍
1、Selenium的介绍
Selenium是一个用于Web应用程序测试的开源工具。其主要功能实模拟用户在浏览器中的行为,如点击、输入、打开页面等,从而测试Web应用程序的功能和性能。Selenium支持多种浏览器,包括IE、Mozia Firefox、Safari、Google Chrome、Opera、Edge等,以及多种编程语言,如Java、Python等。通过Selenium,开发者可以编写自动化测试脚本,从终端用户的角度来测试应用程序,确保其在各种浏览器和操作系统上的兼容性和稳定性。
Selenium的核心功能包括浏览器兼容性测试、系统功能测试、自动录制动作和生成测试脚本等。此外,Selenium还具有简单易用、开源免费、支持分布式测试等优点,使其成为Web应用程序测试领域的重要工具。
2、Chrome Driver的介绍 :
Chrome Driver是一个独立的服务器程序,它作为客户端库与Google Chrome浏览器之间的桥梁,允许对浏览器进行编程控制。
三、开发环境和相关环境的安装和驱动下载
pycharm 2020、python3.9、Chrome124.0.6367.62
安装:Scrapy2.6.2、requests2.28.1、selenium3.141.0、lxml4.9.1
驱动链接:https://blog.csdn.net/mingfeng4923/article/details/130989513
四、实现步骤
导入相关库
实例化一个浏览器对象

搜索框定位
(1)进入浏览器,按F12进入开发者模式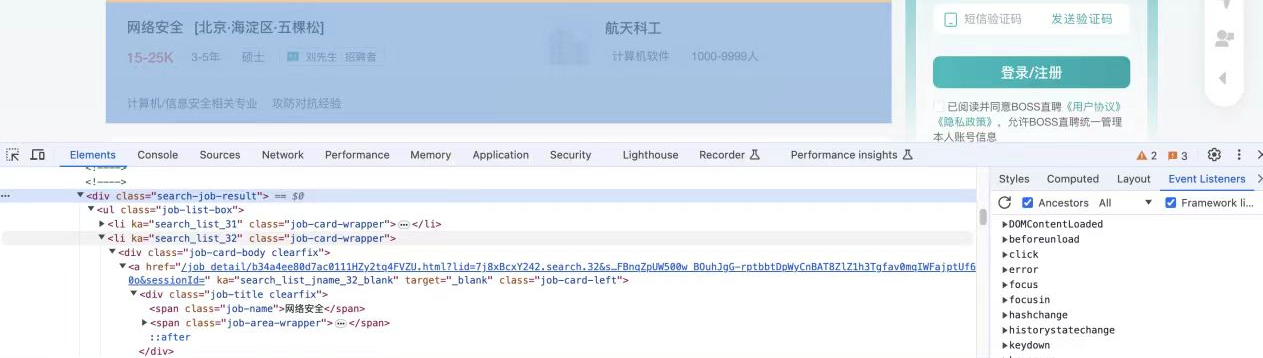
(2)定位详情页
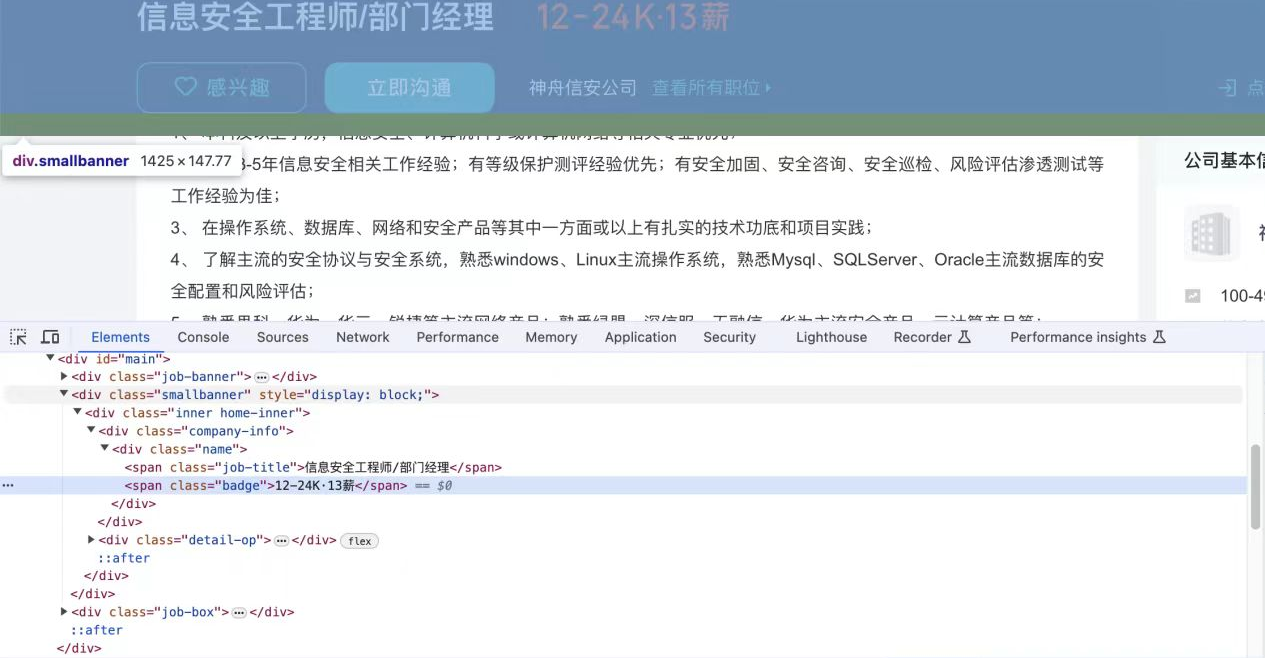
解析代码
创建CSV文件
五、总结
本文整体的思路就是先利用Selenium打开模拟浏览器以便访问Boss直聘首页;再定位搜索按钮输入某职位,点击搜索;然后在搜索结果页面,解析出现的职位信息,并保存;最后获取多个页面,可以定位跳转至下一页的按钮。
使用Scrapy框架爬取Boss直聘网站信息需要应对其烦爬虫策略。通过使用代理IP、限制请求频率等策略,我们可以降低被封禁的风险。同时,在编写爬虫时,我们要尊重网站的行为合法合规。同时,我们也应该尊重网站的版权和隐私政策,不要过度依赖爬虫技术来获取数据。
