
阅读量:1
处理SIGTETM信号
管理客户端资源
管理数据库的资源
执行被延迟的BGREWRITEAOF
检查持久化操作的运行状态
将AOF缓冲区中的内容写入AOF文件
关闭异步客户端
增加cronloops计数器的值
serverCron是Redis中的一个周期时间事件,Redis服务器中的serverCron函数是默认每隔100毫秒执行一次,该函数负责管理服务器的资源
更新服务器时间缓存
Redis服务器中有不少命令都是需要获取系统的当前时间的(比如服务器那边判断客户端执行命令的总时长),而每次获取系统的当前时间都需要执行一次系统调用,为了减少系统调用的执行次数,服务器状态中的unixtime属性和mstime属性被用作当前时间的缓存。
struct redisServer(
//…
//保存了秒级精度的系统当前UNIX时间戳
time_t unixtime;
//保存了毫秒级精度的系统当前unix时间戳
long long mstime;
//…
);
因为serverCron函数默认会每100毫秒一次的频率更新unixtime属性和mstime属性(即serverCron的周期),所以这两个属性的时间的精确度其实并不高。
所以Redis只会在一些对于时间精确度其实并不高的操作上会使用这两个属性,但正在一些对于精确很高的操作,还是会直接获取系统时间。
比如,在打印日记,更新服务器的LRU时钟,决定是否执行持久化操作(触发RDB需要判断时间)、计算服务器的上线时间,这一类对时间精确度要求不高的功能上,会使用unixtime或者mstime。
但如果,对于给键设置过期时间、慢添加查询日志这样需要高精度确切时间的功能来说,服务器还是会再次执行系统调用,从而获得最准确的系统当前时间。
更新LRU时钟
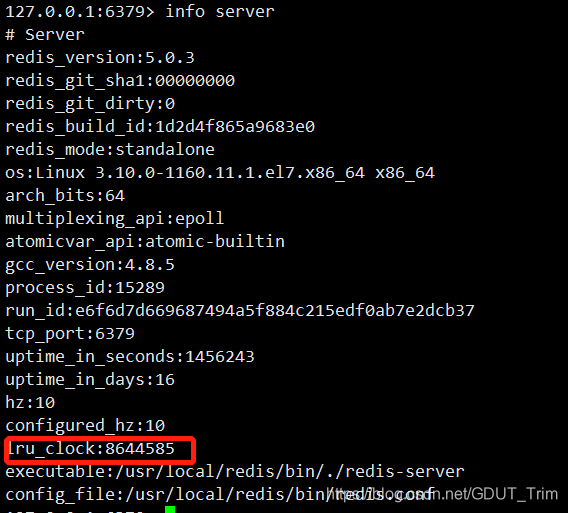
LRU时钟也是服务器时间缓存的一种,服务器状态使用lruclock属性对其进行保存
struct redisServer(
time_t unixtime;
long long mstime;
//lruclock
unsigned lruclock:22;
//。。。
);
每个Redis对象都会有一个lru属性,这个lru属性保存了对象最后一次被命令访问的时间
struct redisObject(
//…
unsigned lru:22;
);
当服务器要计算一个数据库键的空转时间(注意这里是数据库键,也就是对应的键值对对象的空转时间),程序会用服务器的lruclock属性减去对象的lru属性记录的时间,得出的计算结果就是该对象的空转时间。
serverCron函数默认会以每10秒一次的频率更新lruclock属性的值(serverCron函数是100ms执行一次,即0.1秒执行一次,所以执行100次ServerCron才会更新lruclock)。
这是因为lruclock时钟是不现实的,所以根据在这个属性计算出来的LRU时间,实际上只是一个模糊的估算值。
更新服务器每秒执行次数
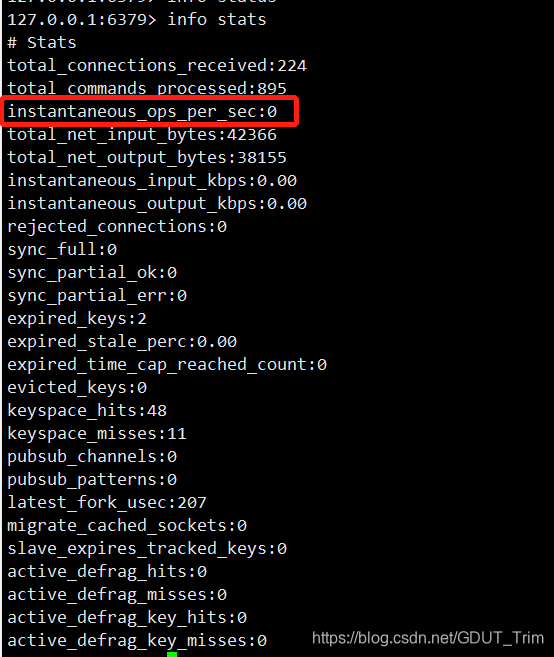
serverCron函数中的trackOperationsPerSecond函数会以每100毫秒一次的频率执行(即执行一次serverCron函数就发生一次),这个函数的功能是以抽样计算的方式,估算并记录服务器在每一秒钟处理的命令请求数量(这里是进行估算,并不一定准确)
该属性也是在服务器状态中的,属性名为ops_sec_last_sample_time
struct RedisServer(
//时间
time_t unixtime;
long long mstime;
//LRU时钟
unsigned lru:22;
//上一次的抽样时间
long long ops_sec_last_sample_time;
//上一次抽样时,服务器已经执行的命令个数
long long ops_sec_last_sample;
//REDIS_OPS_SEC_SAMPLES大小的环形数组(默认为16)
//数组中的每个元素都是一次抽样结果,即会保留前16次的抽样结果
long long ops_sec_samples[REDIS_OPS_SEC_SAMPLES]
//ops_sec_samples的当前最大索引值
//每次抽样后,该值自增1,然后将抽样结果放入ops_sec_samples数组中
//在值自增后等于16就要重置为0,注意此时并不会将后面的数据清0
//也就是保存了上一组的记录,形成了一个环形数组
int ops_sec_idx;
//。。。
);
trackOperationsPerSecond函数每次运行后,都会根据ops_sec_last_sample_time记录的上一次抽样时间和服务器的当前时间,以及ops_sec_last_sample_ops记录的上一次抽样的已执行命令数量和服务器当前的已执行命令数量,计算出两次trackOperationsPerSecond调用之间,服务器平均每一毫秒处理了多少个命令请求,然后将该平均值乘上1000,这就得到了服务器在一秒钟内能处理多少个命令请求的估计值
即通过服务器当前时间减去ops_sec_last_sample_time,得出了两次trackOperationsPerSecond的抽样时间差,然后使用服务器的已执行命令数量减去上一次抽样的已经执行命令数量,得出了两次调用trackOperationsPerSecond之间的时间间隔总共执行命令数量,然后就可以求出每一秒的平均执行次数了。然后将此次结果记录到ops_sec_samples环形数组中去。
那么在查询这个时候的值时,计算的方法是叠加所有ops_sec_samples里面的记录,然后进行求平均
比如当客户端执行info命令时,服务器就会调用getOperationsPerSecond函数,根据ops_sec_samples环形数组这种的抽样结果,计算出instantaneout_ops_per_sec属性的值
实现代码如下
long long getOperations(void){
int j;
long long sum = 0;
//REDIS_OPS_SEC_SAMPLES是ops_sec_samples数组大小,默认为16
for(j = 0;j < REDIS_OPS_SEC_SAMPLES;j++){
sum += server.sps_sec_samples[j];
}
return sum/REDIS_OPS_SEC_SAMPLES;
}
可以看出,每一秒执行次数,仅仅只是前REDIS_OPS_SEC_SAMPLES次的抽样记录的平均值,是一个估算值,结果并不是很准确。
更新服务器内存峰值记录
服务器状态中,有一个名为stat_peak_memory(peak:山峰)的属性会记录服务器的内存峰值大小
struct redisServer(
//时间
time_t unixtime;
long long ctime;
unsigned lruclock:22;
//服务器每秒执行次数的属性
//上一次抽样的时间
long long ops_sec_stc_samples_time;
//上一次抽样的记录
long long ops_sec_stc_sample;
//结果的存储
long long ops_sec_stc_samples[REDIS_OPS_SEC_SAMPLES];
//数组当前的最大索引
int opc_sec_idx;
//已经使用的内存峰值
size_t stat_peak_memory;
//…
);
每次执行serverCron函数时,程序都是会查看服务器当前使用的内存大小,并且与stat_peak_memory保存的数值进行比较,如果当前使用的内存数量比stat_peak_memory属性记录的值要大时,那么程序就会更新stak_peak_memory属性,更新为当前的使用的内存大小。
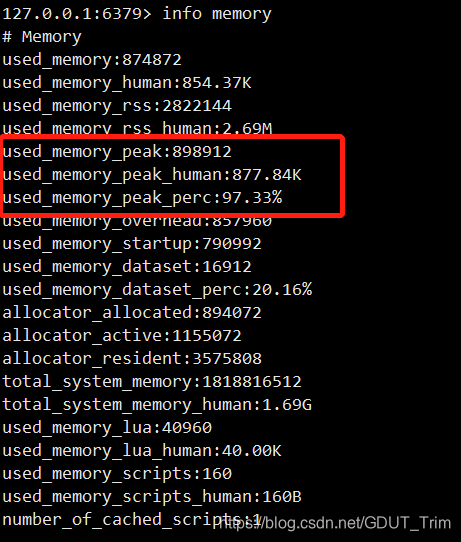
总共有三种形式表达内存峰值大小(b,kb,百分比)
处理SIGTETM信号
在启动服务器时,Redis会为服务器进程的SIGTETM信号关联处理器sigtermHandler函数,这个信号处理器负责在服务器接过SIGTERM信号时,打开服务器状态的shutdown_asap标识,该标识的作用是用来确认服务器是否关机的。
首先先来看看sigtermHandler函数
static void sigtermHandler(int sig){
//打印日志
redisLogFromHandler(REDIS_WARNING,“Received …,scheduling shut down …”);
//打开服务器的关闭标识
server.shutdown_asap = 1;
}
每次当severCron函数运行时,程序都会对服务器状态的shutdown_asap属性进行检查,并且会根据属性的值决定是否关闭服务器(如果为1就进行关闭)
typedef struct RedisServer(
//时间
time_t unixtime;
long long ctime;
unsigned lruclock:22;
//更新服务器每秒执行次数的属性
//上一次抽样的时间
long long opc_sec_stc_samples_time;
//上一次抽样的结果
long long opc_sec_stc_sample;
//前面的记录
long long opc_sec_stc_samples[REDIS_OPC_SEC_STC_SAMPLES];
//当前数组的最大索引
int opc_sec_idx;
//内存的使用峰值
size stat_peak_memory;
//shutdown_asap标识
int shutdown_asap;
);
用SIGTETM信号去触发关机,是让Redis可以有时间去进行持久化准备,假如关机不是通过这种方式,而是直接关闭,那么就无法执行持久化操作了。
管理客户端资源
serverCron函数每次执行都会去调用clientsCron函数,clientsCron函数会对一定数量的客户端进行以下两个检查
检查客户端与服务器的连接是否超时,这里的超时是指很长一段时间没有跟服务器进行互动,那么服务器将会释放这个客户端
检查客户端的缓冲区,如果客户端上一次执行命令时候,对输入缓冲区使用了太多空间,其实是超过了某一个限定的长度,那么程序会释放客户端当前的输入缓冲区,并重新创建一个默认大小的输入缓冲区,从而防止客户端的输入缓冲区耗费了过多的内存。
管理数据库的资源
主要是删除过期资源,serverCron函数每次执行都会去调用databasesCron函数,该函数会对服务器中的一部分数据进行检查,删除其中的过期键,并且在有需要的时候,对字典进行收缩操作(前面提到过,回看Redis的键删除策略)。
执行被延迟的BGREWRITEAOF
前面提到过,如果执行了BGSAVE,但此时又执行BGREWRITEAOF(重写AOF文件),会将BGREWRITEAOF延后,延后到BGSAVE执行完成。
服务器状态里面有一个名为aof_rewrite_scheduled标识记录了服务器是否延迟了BGREWRITEAOF命令
struct redisServer(
//时间
time_t unixtime;
long long ctime;
unsigned lruclock:22;
//服务器每秒钟执行次数的属性
//上一次抽样的时间
long long opc_sec_stc_samples_time;
//上一次抽样的结果
long long opc_sec_stc_sample;
//数组记录结果
long long opc_sec_stc_samples[REDIS_OPC_SEC_STC_SAMPLES];
//数组最大索引
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

写在最后
还有一份JAVA核心知识点整理(PDF):JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算…

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
nity.csdnimg.cn/images/e5c14a7895254671a72faed303032d36.jpg" alt=“img” style=“zoom: 33%;” />
写在最后
还有一份JAVA核心知识点整理(PDF):JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算…
[外链图片转存中…(img-fpJPMXTm-1713281236449)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
