
阅读量:2
目录
1 代码感受
在正式讲程序地址空间前我们先来看一段简单的代码来分析分析:
1 #include<iostream> 2 #include<unistd.h> 3 using namespace std; 4 5 int g_val=100; 6 7 int main() 8 { 9 pid_t id=fork(); 10 if(id==0) 11 { 12 //child 13 while(true) 14 { 15 cout<<"我是一个子进程,我的pid是:"<<getpid()<<",我的ppid是:"<<getppid()<<",g_val:"<<g_val<<";&g_val:"<<&g_val<<endl; 16 g_val=200; 17 sleep(1); 18 } 19 } 20 else 21 { 22 //parent 23 while(true) 24 { 25 cout<<"我是一个父进程,我的pid是:"<<getpid()<<",我的ppid是:"<<getppid()<<",g_val:"<<g_val<<";&g_val:"<<&g_val<<endl; 26 sleep(1); 27 } 28 } 29 return 0; 30 } 31 大家可以自己先分析一下结果。
我们来运行一下结果:
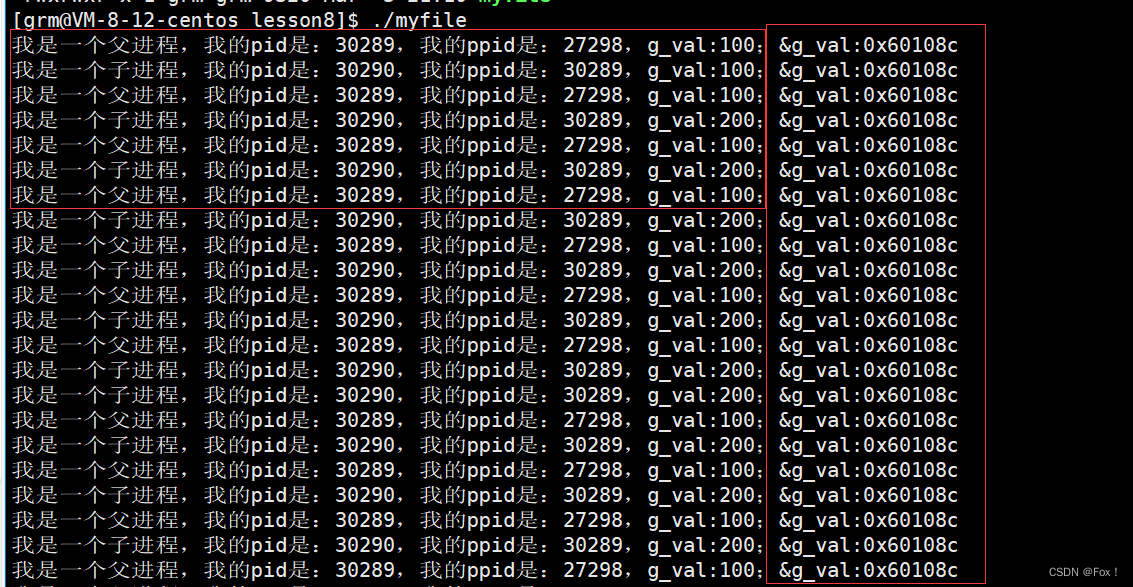
大家看前面几行可能就会立马发现问题:我们定义的g_val是全局变量,当子进程修改g_val的值时我们发现父进程的g_val是不受影响的,那么说明父子进程所用的g_val并不是同一个变量(这个很好理解,之前的我们说过父子进程是相互独立的,互相不受干扰的),但是问题出现在最后一列,我们惊奇的发现居然父子进程的g_val变量的地址居然是相同的,前面不是说父子进程的g_val不是同一个变量吗?这里为啥打印出来的地址会是相同的呢?
这里就说明我们打印出来的地址并不是真正的物理地址,我们语言层面打印出的地址叫做虚拟地址或者线性地址。我们在用C/C++语言所看到的地址,全部都是虚拟地址!而物理地址,用户一概看不到,由OS统一管理 。OS必须负责将虚拟地址转化成物理地址 。
2 进程地址空间
首先我们来讲一个故事:从前有一个企业家很有钱,他的家产大概有一亿美金左右的样子。他有4个私生子,并且这四个私生子互相并不知道对方的存在。第一个私生子是个学霸,在国内顶尖学校上学,这个富豪便对他说,你要好好读书,将来我这一亿美金全部都是你的;第二个私生子是一个三线演员,富豪便对他说,我帮你打开你红的渠道,你不要辜负了我对你的期望,好好努力,将来我这一亿美金都是你的;第3个私生子是个女儿,当的是小学老师,富豪便对他说,你也不用太过努力工作,我就你这一个女儿,等我老了这一亿美金就是你的了;第四个私生子是一个初中的小混混,富豪对他说,你只要好好听我的话,这一亿美金就是你的了。
富豪给每个私生子都做出了承诺要将一亿美金给他们,但是实际富豪并没有那么多的钱给每个私生子一亿美金,而这一亿美金就是富豪给私生子们画的一张大饼,但是它的私生子们却信以为真。

那这个故事与我们讲的知识有什么关系呢?其实操作系统就是那个富豪,私生子们就是一个一个的进程,而那一亿美金就是进程地址空间。
PS:我们在生活中要尽量少画饼。

操作系统给进程画了一张大饼,操作系统的资源是有限的,所以他就得要好好的把这张饼给管理起来,不让这些进程乱来,而如何管理呢?
那就要先描述,再组织,Linux中用的是一种叫做mm_struct的内核数据结构来管理的。
我们来用一张图带大家来看看程序地址空间:
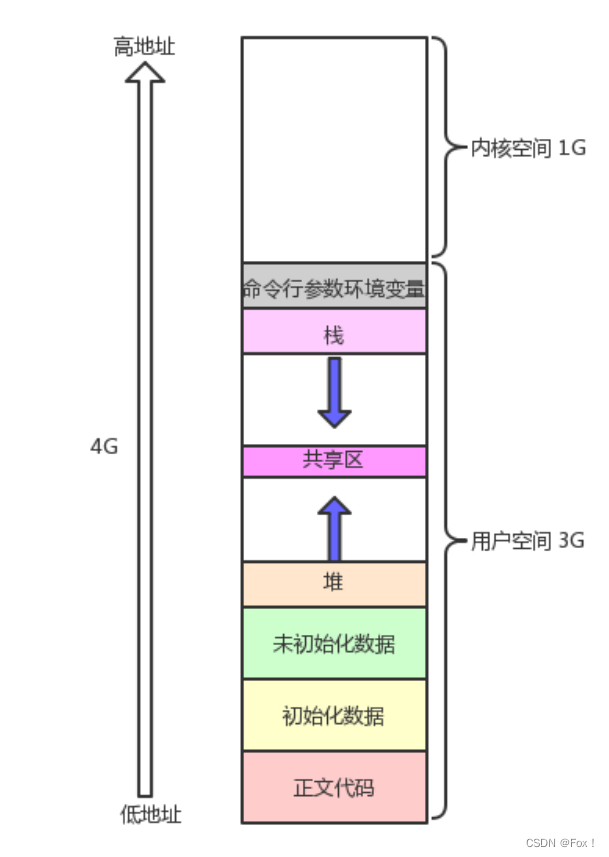
这张图相信大家多多少少也不会陌生,在C语言的学习中我们也见到了很多次。
那么程序地址空间如何编码的呢?(32位的平台下虚拟地址空间大概是4GB)
ps:下面图每个小空格代表着一个字节。
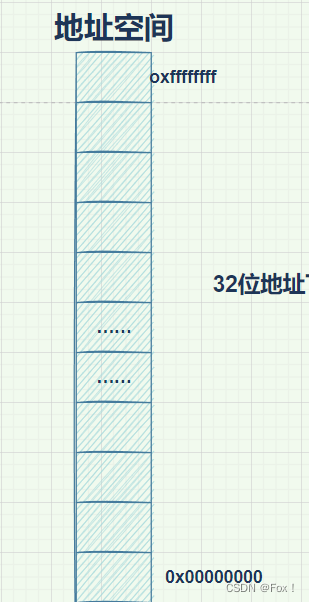
所以从这里我们也不难看出为啥虚拟地址也叫做线性地址。那么我们究竟是如何管理虚拟地址空间的每个区的呢?
我们可以用下面这种方式来描述管理:
struct mm_struct { long code _start; long code _end; long init _start; long init _end; ………… long brk _start; long brk _end; long stack _start; long stack _end; }而_start和_end限定的区域就是叫做虚拟地址(线性地址)
那么问题来了,既然上面我们讲了那么多虚拟地址,真正的物理地址又在哪里呢?
我们画一个图方便大家理解:
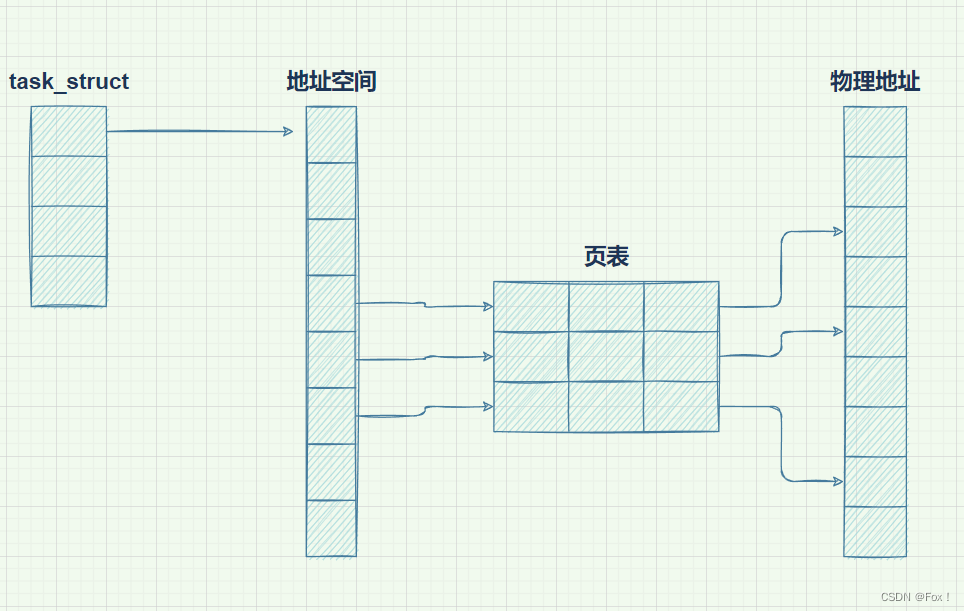
通过这张图大家并不难发现,我们在语言层面上的地址是地址空间的虚拟地址,而虚拟地址要与物理地址建立映射,就需要一张页表(页表的工作原理我们将放到后面来讲)。
我们在学习C语言时大家在书上看到这样的一句代码:const char* str="hello world";
这时书上会告诉大家这句str指向的内容是只读的,不可修改的,但是这时为什么呢?这时我们就可以自己来分析分析:str指向的内容是在常量字符区,当常量字符区通过页表与物理地址建立映射时在页表中就将该数据设置为只读,当我们后续有修改操作时就会直接报错。
有了上面的基础我们就可以来解释解释为啥开头我们的g_val是同一个地址,但是指向的内容却不相同的问题了:
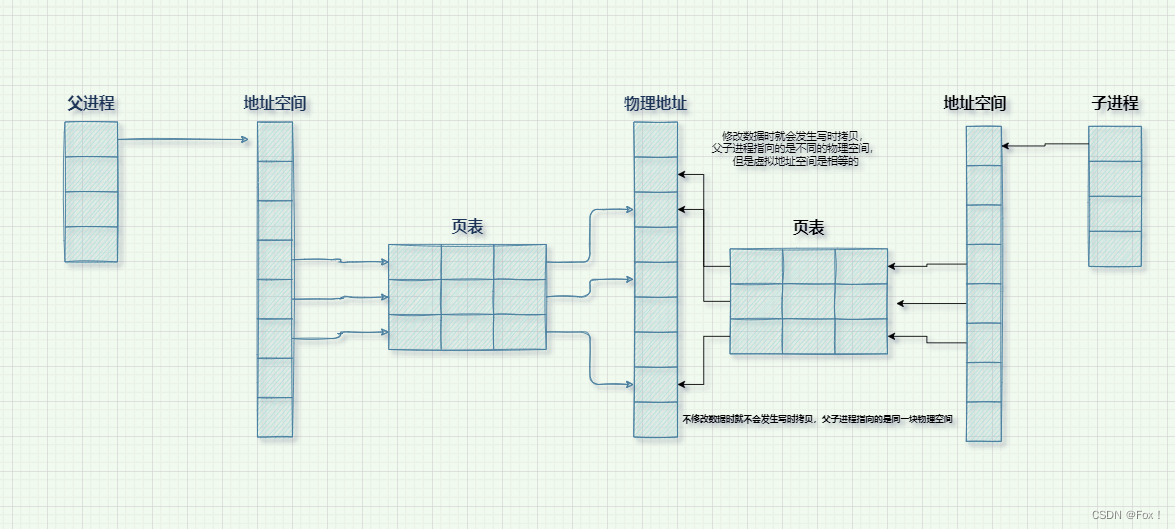
当不修改数据时就不会发生写时拷贝,父子进程指向的是同一块物理空间(为了节约资源);当要修改数据时就会发生写时拷贝,父子进程指向的是不同的物理空间,但是虚拟地址空间是相等的。
我们再来回答为啥fork会有两个返回值的问题就很容易了,就是因为父子进程的返回值是不同的,所以肯定会发生写时拷贝将不同的返回值用相同的虚拟地址来进行返回,虽然虚拟地址是相同的,但是他们通过页表建立映射的关系却是不一样的。
到目前为止,程序地址空间的基本内容已经ok,接下来给出一些扩展。
3 扩展
首先引出一个问题:假如没有程序地址空间,OS是如何工作的?
我们知道如果没有了地址空间,那么cpu将直接跟物理地址打交道,这样做的后果是什么?
我们不难知道假如cpu直接跟物理地址打交道的话那么当我们从cpu中读到非法地址时那就坏了,通过非法地址将我们程序中其他变量的值给修改了那不就扯淡了吗。所以我们要通过一层屏障来保护数据,而这一层保护就是通过程序地址空间来进行的,当我们访问的数据非法时通过页表的映射就会拒绝你的非法操作。
所以我们得出了程序地址空间的第一个好处:防止地址随意访问,保护物理内存和其他进程。
在向大家提出一个小问题:当我们在堆上new空间时OS是立马就把空间给你,还是等你需要的时候再给你?
这个问题大家应该都能够答对,与我们想得一样,OS会在我们需要该空间的时候再去在堆上申请。
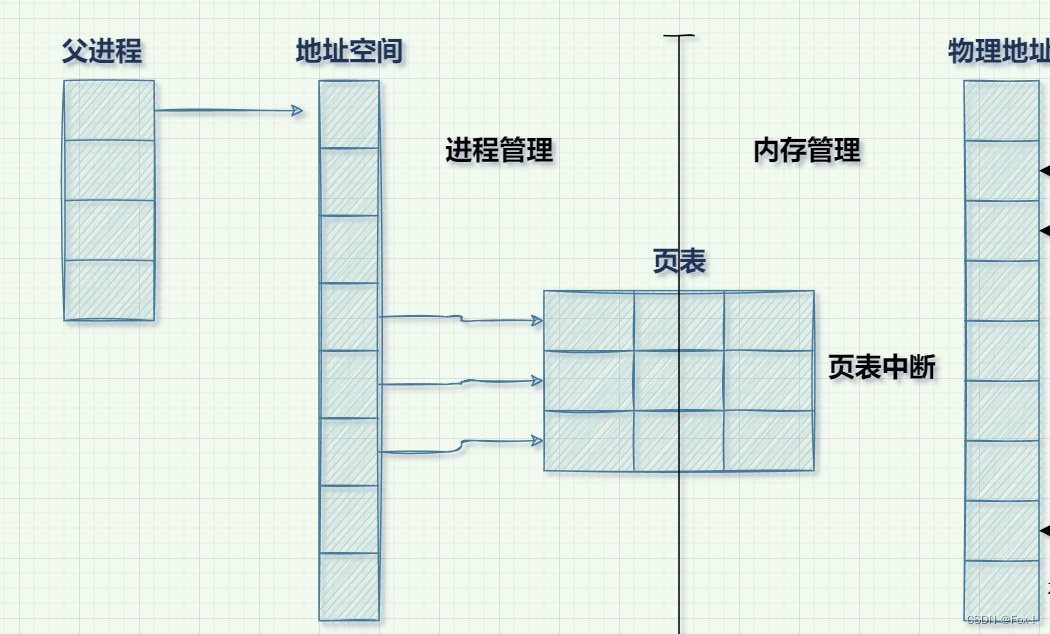
而页表暂时没有与物理内存建立映射关系称作页表中断,当我们需要空间的时候再与·物理内存建立映射。大家从这张图看出来没有,当我们通过页表建立映射时将进程管理与内存管理给解耦合了。我进程管理不需要关心你是怎样在内存上申请空间的,内存管理也不需要关心进程是如何管理起来的,这样下来维护成本就会变得更低,维护效率会更加高效一些。
所以我们得出了程序地址空间的第二个好处:将进程管理与内存管理进行解耦合。
再提出一个问题:程序在被编译的时候没有被加载到内存,那么程序内有没有地址呢?
答案是有的。源代码再被编译的时候就是按照虚拟地址空间的方式将对应的代码和数据进行编制,编译器也会遵守虚拟地址的规则。
当我们把程序加载到内存,程序里保存的地址(虚拟地址,并不是程序本身在内存中的物理地址)就会被cpu读取,cpu通过虚拟地址找到对应的虚拟地址空间,然后虚拟地址空间又通过页表映射到物理内存中,这样就将程序的整个运转给联系起来了。
所以我们得出了程序地址空间的第三个好处:可以让进程以统一的视角看待自己的代码和数据。
