
阅读量:2
多线程导入百万数据
一、如何开启多线程
1.继承Thread类
public class ThreadTask extends Thread{ @Override public void run() { System.out.println("成功运行"); } } public class ThreadDemo { public static void main(String[] args) { ThreadTask thread = new ThreadTask(); ThreadTask thread2 = new ThreadTask(); thread.start(); thread2.start(); } }2.实现Runnable接口
public class RunnableTask implements Runnable{ @Override public void run() { System.out.println("线程开启成功"); } } public class RunnableDemo { public static void main(String[] args) { RunnableTask task = new RunnableTask(); new Thread(task).start(); new Thread(task).start(); } }3.实现Callable接口
public class CallableTask implements Callable<String> { @Override public String call() throws Exception { String s = "线程开启成功"; return s; } } public class CallableDemo { public static void main(String[] args) throws ExecutionException, InterruptedException { CallableTask task = new CallableTask(); FutureTask<String> futureTask = new FutureTask<>(task); new Thread(futureTask).start(); String string = futureTask.get(); System.out.println(string); } }4.使用线程池
public class demo { public static void main(String[] args) { ExecutorService executor = Executors.newFixedThreadPool(5); //简化写法 executor.execute(() -> System.out.println("Hello World")); } } public class demo { public static void main(String[] args) { ExecutorService executor = Executors.newFixedThreadPool(5); //正常写法 executor.execute(new Runnable() { @Override public void run() { System.out.println("线程开启成功"); } }); } }阿里巴巴开发手册中写到不允许使用Executors开启线程池。
二、线程池介绍
1.Executor的UML图

executor包括Executor,Executors,ExecutorService,AbstractExecutorService,ScheduledExecutorService,ThreadPoolExecutor,ScheduledThreadPoolExecutor等。
2.Executor
Executor:一个接口,定义了一个接收Runnable对象的方法executor,里面有一个方法void execute(Runnable command);接收一个Runnable实例,用来执行一个任务。
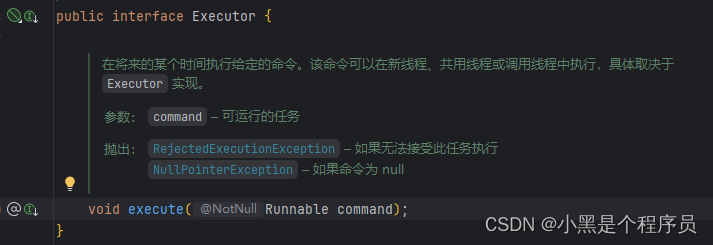
3.ExecutorService
ExecutorService:继承了Executor接口,提供了生命周期管理的方法,任务提交返回Future对象;提供了可以关闭ExecutorService的方法void shutdown();调用该方法后,将导致ExecutorService停止接受任何新的任务且等待已经提交的任务执行完成(已经提交的任务会分两类:一类是已经在执行的,另一类是还没有开始执行的),当所有已经提交的任务执行完毕后将会关闭ExecutorService。因此我们一般用该接口来实现和管理多线程。
4.Executors类
Executors:提供了一系列工厂方法用于创建线程池,返回的线程池都实现了ExecutorService接口。
1.public static ExecutorService newFixedThreadPool(int nThreads) 创建固定数目线程的线程池。
2.public static ExecutorService newCachedThreadPool() 创建一个可缓存的线程池,可以根据需要自动扩展,如果有可用的空闲线程,就会重用他们,如果没有可用的线程,就会创建一个新线程。
3.public static ExecutorService newSingleThreadExecutor() 创建一个单线程的线程池,串行执行任务。
4.public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) 创建一个固定大小的线程池,用于执行定时任务。
5.public static ScheduledExecutorService newSingleThreadScheduledExecutor() 创建一个单线程的定时执行线程池。只包含一个线程,用于串行定时执行任务。
6.public static ExecutorService newWorkStealingPool(int parallelism) 创建一个工作窃取线程池,根据cpu核心数动态调整。
5.自定义线程池
线程池七个参数:
1.corePoolSize:核心线程数。
2.maximumPoolSize:最大线程数。
3,keepAliveTime:持续时间。
4.unit:时间的单位。
5.workQueue:任务队列。
6.ThreadFactory:线程的创建工厂。
7.RejectedExecutionHandler :拒绝策略。
6.拒绝策略
所有的拒绝策略都是实现了RejectedExecutionHandler接口。
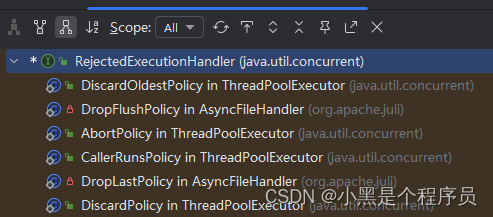
常见的拒绝策略
1.AbortPolicy:抛出异常,线程池默认的拒绝策略。
2.CallerRunsPolicy:使用调用线程执行任务。
3.DiscardPolicy:直接丢弃。
4.DiscardOldestPolicy:丢弃队列最老的任务,添加新任务。
7.阻塞队列
所有的阻塞队列都是继承了BlockingQueue<E>接口。
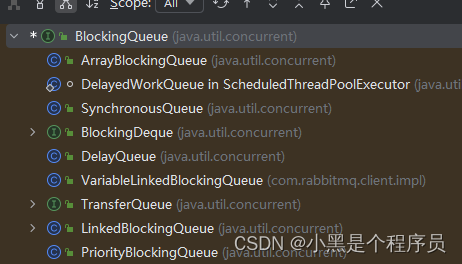
选择阻塞队列时根据需要选择合适的阻塞队列
1.ArrayBlockingQueue:一个有数组结构组成的有界阻塞队列。
2.LinkedBlockingQueue:由链表组成的有界(大小默认是integer.MAX_VALUE)阻塞队列。
3.DelayQueue:使用优先级队列实现的延迟无界阻塞队列。
4.PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
三、线程状态
查看源码发现线程一共有六中状态,分别是:
1.NEW:新建状态,新创建了一个线程对象,但还没有调用Start()方法。
2.RUNNABLE:运行状态,调用了start()方法,在获得CPU时间片之后变为运行状态RUNNING。
3.BLOCKED:阻塞状态。
4.WAITING:等待状态,调用了wait,join等方法,会进入等待状态。
5.TIMED_WAITING:定时等待状态,具有指定等待时间的等待线程的状态。
6.TERMINATED:终止状态,终止线程的状态,线程已经执行完成。

四、具体代码实现
业务介绍:
需要把一个100万数据的集合进行处理,插入到另一个新集合中,使用多线程。
代码实现:
public class ExecutorsDemo { public static void main(String[] args) throws InterruptedException { //定义一个线程池 ThreadPoolExecutor executor = new ThreadPoolExecutor( 10, 50, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(20), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy() ); List<String> list = new ArrayList<>(); for (int i = 0; i < 1000000; i++) { list.add("这是第" + i + "条"); } long begin = System.currentTimeMillis(); System.out.println(begin); List<String> newList = new CopyOnWriteArrayList<>(); //计算总共多少条数据 int countNumber = list.size(); //分页页码:每次读取数据2000条 int singleThreadDealCount = 2000; //分页页数:按照每次存储2000条数据,一共需要存储多少次,四舍五入的时候,小数后面不足5也得进一位 int threadSize = (int) Math.ceil(countNumber / singleThreadDealCount); //定义一个计数器 CountDownLatch count = new CountDownLatch(threadSize); Thread.State state = Thread.State.NEW; for (int i = 0; i < threadSize; i++) { if (executor.getQueue().size() == 20) { Thread.sleep(1000); } int finalI = i; executor.execute(() -> { //声明每次从list集合截取部分的开始索引和结束索引 int startIndex = finalI * singleThreadDealCount; //最后一个线程可能处理不到结尾,因为结尾索引需要设置为集合的最后一条数据 int endIndex = (finalI == threadSize - 1) ? countNumber : (finalI + 1) * singleThreadDealCount; //截取集合 List<String> strings = list.subList(startIndex, endIndex); newList.addAll(strings); count.countDown(); }); } count.await(); long end = System.currentTimeMillis(); System.out.println(newList.size()); System.out.println(end - begin); }注意事项:
在这里使用的接收的集合一定要是线程安全的集合,使用ArrayList会有线程不安全的问题,会导致索引越界异常。这只是一个小demo,具体的代码需要结合自己的业务需求实现。
