
阅读量:1
 爆笑教程《看表情包学Linux》👈 猛戳订阅!
爆笑教程《看表情包学Linux》👈 猛戳订阅! 💭 写在前面:本章我们主要讲解进程的创建与终止。首先讲解进程创建,fork 函数是我们早在讲解 "进程的概念" 章节就提到过的一个函数,在上个章节我们讲解了 "进程地址空间" 后,我们解释了 fork 函数有两个返回值的问题,本章我们要学习进程的创建,所以我们要正式介绍一下 fork 函数。随后讲解进程终止,我们需要对终止有一个正确的认识,在本章我们会详细探讨 主函数 return 0 到底是个什么情况,从而引发进程退出码和错误码的概念。再探讨一下进程退出的常见方法,最后引出内存数据结构缓冲池,简单介绍一下 slab 分派器。
💭 写在前面:本章我们主要讲解进程的创建与终止。首先讲解进程创建,fork 函数是我们早在讲解 "进程的概念" 章节就提到过的一个函数,在上个章节我们讲解了 "进程地址空间" 后,我们解释了 fork 函数有两个返回值的问题,本章我们要学习进程的创建,所以我们要正式介绍一下 fork 函数。随后讲解进程终止,我们需要对终止有一个正确的认识,在本章我们会详细探讨 主函数 return 0 到底是个什么情况,从而引发进程退出码和错误码的概念。再探讨一下进程退出的常见方法,最后引出内存数据结构缓冲池,简单介绍一下 slab 分派器。
 本篇博客全站热榜排名:未上榜
本篇博客全站热榜排名:未上榜
Ⅰ. 进程创建(Process creation)
0x00 分叉函数 fork
 在
在 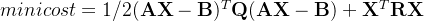 中,
中, fork 函数是非常重要的函数,它从已存在进程中创建一个新的进程。
#include <unistd.h> pid_t fork(void);新进程为子进程 (child process) ,而原进程为父进程 (father process)
返回值:子进程中返回 0,父进程返回子进程 id,出错返回 -1
❓ 进程调用 fork,当控制转移到内核中的 fork代码后,操作系统会做什么?
① 将给子进程分配新的内存块和内核数据结构
- 创建
task_struct和进程地址空间mm_struct
② 将父进程部分数据结构内容拷贝至子进程
- 以父进程为模板,设置子进程的相关数据结构和父进程相关字段保持一致。
task_struct、地址空间、区域划分很多东西都是一样的。- 但不是无脑拷贝!比如累计调度的时间片是不一样的。
③ 添加子进程到系统进程列表当中
- 取决于你进程是要做什么,创建后如果状态没问题就会直接链入运行队列中。
④ fork 返回,开始调度器调度
- 当准备返回时,上面三个工作都有了,父进程继续执行开始
return,子进程也可能执行fork的返回值,然后就会得到两次返回。
第一次返回的本质:通过寄存器向接收变量进行写入,写入的本质就是进行修改,所以就会发生写时拷贝,进而让同一个变量出现不同的值。至此就解释了 fork的返回值为什么会有两个的问题。
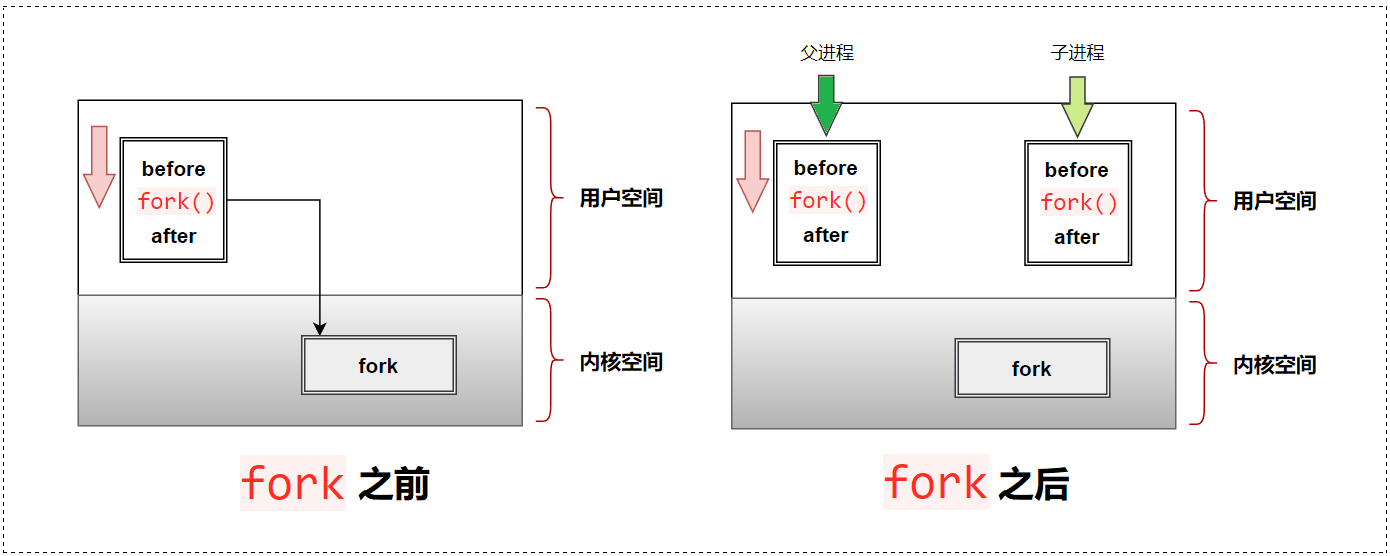
当一个进程调用 fork之后,就有两个二进制代码相同的进程,并且它们都运行到相同的地方。
但每个进程都可以开始它们自己的旅程,我们来看下面的代码:
💬 代码演示:
#include <stdio.h> #include <unistd.h> #include <stdlib.h> int main(void) { printf("Before -> pid: %d\n", getpid()); fork(); printf("After -> pid: %d\n", getpid()); sleep(1); return 0; }🚩 运行结果如下:

我们看到有三行输出,一行 Before,两行 After,进程 27303 先打印 Before 信息,然后它又打印了 Afrer。另一个 After 是 27304 打印的。进程 27304 并没有打印 before,这是为什么呢?
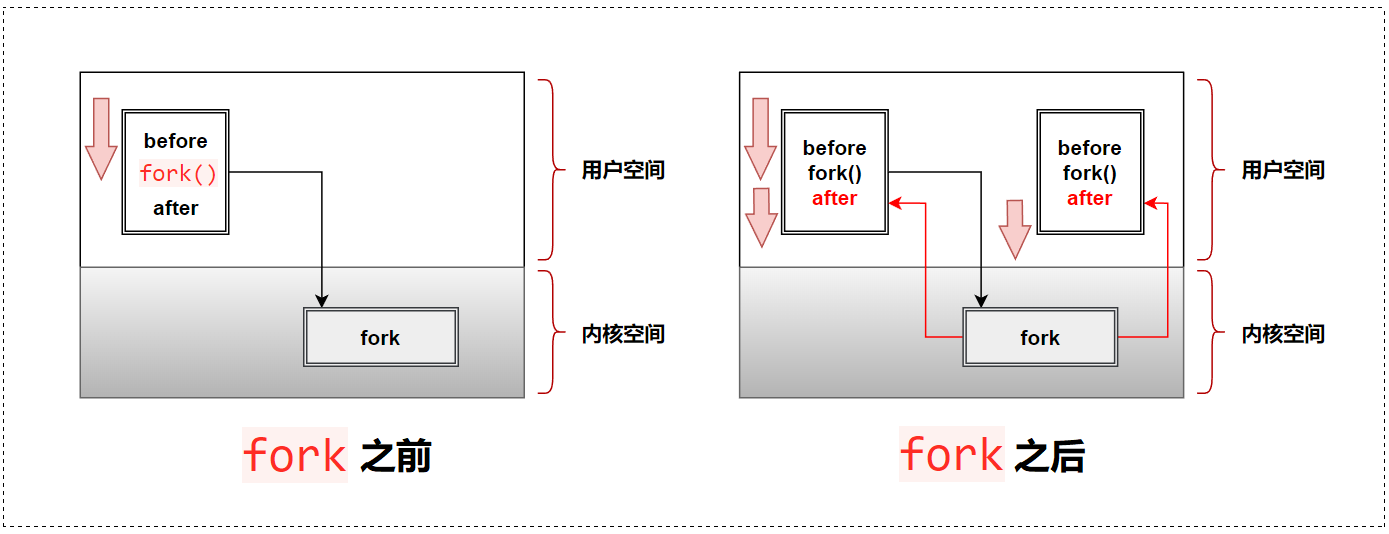
fork之前:父进程独立执行(因为只有父进程)。fork之后:父子分道扬镳,父子两个执行流分别执行(因为fork之后有两个进程了)。
📌 注意:fork 之后,谁先执行谁后执行完全由调度器决定!
 那么
那么 fork之后,是否只有 fork之后的代码是被父子进程共享的?
实际上,fork 之后代码共享这样的说法并不准确。一般情况 fork 之后,父子共享所有的代码
子进程执行的后续代码 != 共享的所有代码,只不过子进程只能从这里开始执行!
 它是怎么知道的呢?没关系,
它是怎么知道的呢?没关系,eip 程序计数器会出手!
eip 叫做 程序计数器,用来保存当前正在执行的指令的下一条指令。
eip 程序计数器会拷贝给子进程,子进程便从该 eip 所指向的代码处开始执行。
我们再来重新思考一下 fork 之后操作系统会做什么:
" 进程 = 进程的数据结构 + 进程的代码和数据 "
创建子进程的内核数据结构:
(struct task_struct + struct mm_struct + 页表)+ 代码继承父进程,数据以写时拷贝的方式来进行共享或者独立。
🔺 结论:fork 之后创建一批结构,代码以共享的方式,数据以写时拷贝的方式,两个进程必须保证 "独立性",做到互不影响。在这种共享机制下子进程或父进程任何一方挂掉,不会影响另一个进程。
0x01 写时拷贝(copy-on-write)
我们知道,进程具有独立性,代码和数据必须是独立的,代码只能读取 → 写时拷贝
写时拷贝技术,我们在上一章把这个名词提了出来,但是没有深入讲解,今天我们就要探究为什么要写时拷贝。通常,父子代码共享,父子在不让写入时数据也是共享的。当任意一方试图写入,就会按照写时拷贝的方式各自拷贝一份副本出来。写时拷贝本身由操作系统的内存管理模块完成的。
 操作系统为什么要写时拷贝?创建子进程的时候就把数据分开不行吗?
操作系统为什么要写时拷贝?创建子进程的时候就把数据分开不行吗?
- 有浪费空间之嫌:父进程的数据,子进程不一定全用;即便使用,也不一定全部写入。
- 最理想的情况,只有会被父子修改的数据,进行分离拷贝。不需要修改的数据,共享即可。但是从技术角度实现复杂。
- 如果
fork的时候,就无脑拷贝数据给子进程,会增加fork的成本(内存和时间)
最终采用写时拷贝:只会拷贝父子修改的、变相的,就是拷贝数据的最小成本。拷贝的成本依旧存在。
写时拷贝实际上以一种 延迟拷贝策略,延迟拷贝最大的价值:只有真正使用的时候才给你拷。
其最大的意义在于,你想要,但是不立马使用的空间,先不给你,那么也就意味着可以先给别人。
反正拷贝的成本总是要有,早给你晚给你都是一样。万一我现在给你你又不用,那其实不很浪费
所以我选择暂时先不给你,等你什么时候要用什么时候再给。这就变相的提高了内存的使用情况。
0x03 fork 常规用法
 我们一般不会
我们一般不会 fork 之后让父子执行同样的代码,那样没什么意义。
我们 fork 之后只为了让父子执行不同的代码,所以当你希望创建一个子进程,和父亲做类似的事情时(注意是类似,不是相同),fork 便可以出手了。
最简单的方式就是 fork 之后利用 if-else 进行分流, 让父子执行不同的代码块。刚才通过实验我们也知道了,实际上 if-else 代码也是父进程,只不过子进程执行了父进程的代码罢了。所以,我们在 fork 之后让父子执行不同的代码段,这就是典型地 fork 创建出来让子进程执行类似的事。
一个父进程希望复制自己,使父子进程同时执行不同的代码段。我们做网络写服务器的时候会经常采用这样的编码方式,例如父进程等待客户端请求,生成子进程来处理请求。
还有一种用法就是 fork 之后创建子进程想做和父亲完全不一样的事情,比如子进程从 fork 返回后,调用 exec 函数。(我们本章下面会讲解的 "程序地址替换" 就和这个有关)
0x04 fork 调用失败的情况

fork 肯定不是永远都成功的,fork 也是有可能调用失败的。
系统中有太多进程,导致内存资源不足,fork 不出。
一般 系统中规定每一个用户能起的进程数是有限制的,所以也能够导致失败。
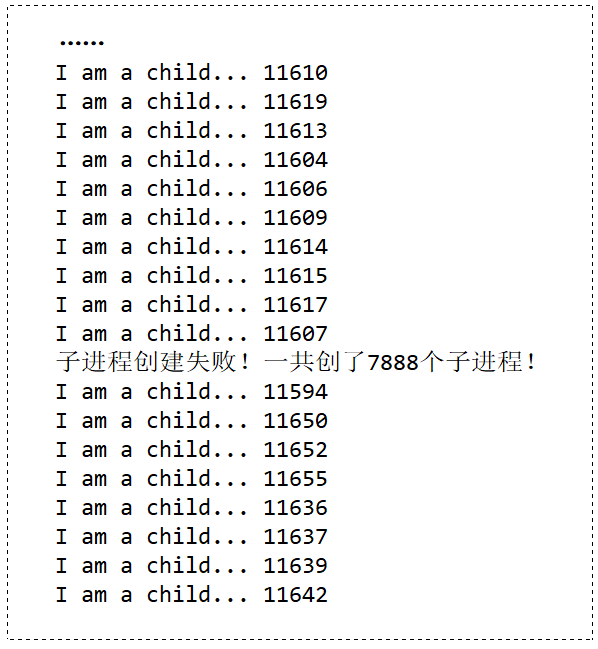
💬 代码演示:我们可以手动演示一下 fork 失败的场景
#include <stdio.h> #include <unistd.h> #include <stdlib.h> int main(void) { for (;;) { pid_t id = fork(); if (id < 0) { printf("子进程创建失败!\n"); break; } if (id == 0) { printf("I am a child... %d\n", getpid()); sleep(2); // 给它活2秒后 exit exit(0); // 成功就退出 } } return 0; }🚩 运行结果如下:
Ⅱ. 进程终止(Process Termination)
0x00 终止的正确认识
 我们一开始是如何学习 C++ 的呢?C/C++ 的时侯,
我们一开始是如何学习 C++ 的呢?C/C++ 的时侯,main 函数就是所谓的 入口函数。
#include <stdio.h> int main() { printf("Hello,World!\n"); return 0; }大家对 Hello,World!想必是再熟悉不过了,但是不知道大家是否关注过这个return?
下面我们思考两个问题:
① 这个 return 0 究竟给谁 return?
② 为何是 0 ?其他值可以吗?
常见的进程退出:
① 代码跑完,结果正确。
② 代码跑完,结果不正确。
③ 代码没跑完,程序异常了。
返回值为 0,表示进程代码跑完,结果是否正确,我们用 0 表示成功,非 0 表示失败。
 所以,写代码无脑写
所以,写代码无脑写 0 是不正确的,准确来说应该要给不同的值。
0x01 进程退出码
 我们最想知道的当时是失败的原因了!所以用非零表示不用的原因。
我们最想知道的当时是失败的原因了!所以用非零表示不用的原因。
我们把 main 函数的 return
进程退出码是非常重要的,进程退出码表征了进程推出的信息,它是要给父进程读取的。
我们通过内置命令 echo,我们让 自己执行内部的函数来打印:
$ echo $?我们先运行一下刚才的 mytest (刚才演示 fork 的程序):

这里之所以会第一次执行 echo $? 得到130,第二次得到 0,原因如下:
$? 表示在 中,最近一次执行完毕时,对应进程的退出码。
所以我们来试试 ls 指令后输入 echo $?:

此时如果我们让 ls 显示一个完全不存在的文件,ls 会报错,再 echo $? 退出码就不再是 0 了:

再反观我们之前学 C 时,代码都是无脑 return 0 的……
而这些指令代码的 return 都是设计好了的!
实际上,即使不会也没有关系,你无脑 return 0,return 都没有问题。
但是我们继续往下看!
0x02 错误码
 好,现在我们想变成懂哥,不再是随便无脑
好,现在我们想变成懂哥,不再是随便无脑 return 了,我该怎么办呢?
一般而言,失败的非零值我该如何设置呢?非零值默认表达的含义又是什么呢?
首先,失败的非零值是可以自定义的,我们可以看看系统对于不同数字默认的 错误码 是什么含义。C 语言当中有个的 string.h 中有一个 strerror 接口,是最经典的、将错误码表述打印出来的接口,这在我们的 《维生素C语言》 专栏中的字符串章节也对它有做过说明和讲解。我们现在对它再进行一次介绍!
📜 头文件: string.h
🔍 链接: strerror - C++ Reference
📚 说明:返回错误码,返回错误码所对应的错误信息
![]() 如果感兴趣可以看看 2.6.32 的内核代码中的 /usr/include/asm-generic/errno.h 及
如果感兴趣可以看看 2.6.32 的内核代码中的 /usr/include/asm-generic/errno.h 及 errno-base.h,输出错误原因定义归纳整理如下:
#define EPERM 1 /* Operation not permitted */ #define ENOENT 2 /* No such file or directory */ #define ESRCH 3 /* No such process */ #define EINTR 4 /* Interrupted system call */ #define EIO 5 /* I/O error */ #define ENXIO 6 /* No such device or address */ #define E2BIG 7 /* Argument list too long */ #define ENOEXEC 8 /* Exec format error */ #define EBADF 9 /* Bad file number */ #define ECHILD 10 /* No child processes */ #define EAGAIN 11 /* Try again */ #define ENOMEM 12 /* Out of memory */ #define EACCES 13 /* Permission denied */ #define EFAULT 14 /* Bad address */ #define ENOTBLK 15 /* Block device required */ #define EBUSY 16 /* Device or resource busy */ #define EEXIST 17 /* File exists */ #define EXDEV 18 /* Cross-device link */ #define ENODEV 19 /* No such device */ #define ENOTDIR 20 /* Not a directory */ #define EISDIR 21 /* Is a directory */ #define EINVAL 22 /* Invalid argument */ #define ENFILE 23 /* File table overflow */ #define EMFILE 24 /* Too many open files */ #define ENOTTY 25 /* Not a typewriter */ #define ETXTBSY 26 /* Text file busy */ #define EFBIG 27 /* File too large */ #define ENOSPC 28 /* No space left on device */ #define ESPIPE 29 /* Illegal seek */ #define EROFS 30 /* Read-only file system */ #define EMLINK 31 /* Too many links */ #define EPIPE 32 /* Broken pipe */ #define EDOM 33 /* Math argument out of domain of func */ #define ERANGE 34 /* Math result not representable */ #define EDEADLK 35 /* Resource deadlock would occur */ #define ENAMETOOLONG 36 /* File name too long */ #define ENOLCK 37 /* No record locks available */ #define ENOSYS 38 /* Function not implemented */ #define ENOTEMPTY 39 /* Directory not empty */ #define ELOOP 40 /* Too many symbolic links encountered */ #define EWOULDBLOCK EAGAIN /* Operation would block */ #define ENOMSG 42 /* No message of desired type */ #define EIDRM 43 /* Identifier removed */ #define ECHRNG 44 /* Channel number out of range */ #define EL2NSYNC 45 /* Level 2 not synchronized */ #define EL3HLT 46 /* Level 3 halted */ #define EL3RST 47 /* Level 3 reset */ #define ELNRNG 48 /* Link number out of range */ #define EUNATCH 49 /* Protocol driver not attached */ #define ENOCSI 50 /* No CSI structure available */ #define EL2HLT 51 /* Level 2 halted */ #define EBADE 52 /* Invalid exchange */ #define EBADR 53 /* Invalid request descriptor */ #define EXFULL 54 /* Exchange full */ #define ENOANO 55 /* No anode */ #define EBADRQC 56 /* Invalid request code */ #define EBADSLT 57 /* Invalid slot */ #define EDEADLOCK EDEADLK #define EBFONT 59 /* Bad font file format */ #define ENOSTR 60 /* Device not a stream */ #define ENODATA 61 /* No data available */ #define ETIME 62 /* Timer expired */ #define ENOSR 63 /* Out of streams resources */ #define ENONET 64 /* Machine is not on the network */ #define ENOPKG 65 /* Package not installed */ #define EREMOTE 66 /* Object is remote */ #define ENOLINK 67 /* Link has been severed */ #define EADV 68 /* Advertise error */ #define ESRMNT 69 /* Srmount error */ #define ECOMM 70 /* Communication error on send */ #define EPROTO 71 /* Protocol error */ #define EMULTIHOP 72 /* Multihop attempted */ #define EDOTDOT 73 /* RFS specific error */ #define EBADMSG 74 /* Not a data message */ #define EOVERFLOW 75 /* Value too large for defined data type */ #define ENOTUNIQ 76 /* Name not unique on network */ #define EBADFD 77 /* File descriptor in bad state */ #define EREMCHG 78 /* Remote address changed */ #define ELIBACC 79 /* Can not access a needed shared library */ #define ELIBBAD 80 /* Accessing a corrupted shared library */ #define ELIBSCN 81 /* .lib section in a.out corrupted */ #define ELIBMAX 82 /* Attempting to link in too many shared libraries */ #define ELIBEXEC 83 /* Cannot exec a shared library directly */ #define EILSEQ 84 /* Illegal byte sequence */ #define ERESTART 85 /* Interrupted system call should be restarted */ #define ESTRPIPE 86 /* Streams pipe error */ #define EUSERS 87 /* Too many users */ #define ENOTSOCK 88 /* Socket operation on non-socket */ #define EDESTADDRREQ 89 /* Destination address required */ #define EMSGSIZE 90 /* Message too long */ #define EPROTOTYPE 91 /* Protocol wrong type for socket */ #define ENOPROTOOPT 92 /* Protocol not available */ #define EPROTONOSUPPORT 93 /* Protocol not supported */ #define ESOCKTNOSUPPORT 94 /* Socket type not supported */ #define EOPNOTSUPP 95 /* Operation not supported on transport endpoint */ #define EPFNOSUPPORT 96 /* Protocol family not supported */ #define EAFNOSUPPORT 97 /* Address family not supported by protocol */ #define EADDRINUSE 98 /* Address already in use */ #define EADDRNOTAVAIL 99 /* Cannot assign requested address */ #define ENETDOWN 100 /* Network is down */ #define ENETUNREACH 101 /* Network is unreachable */ #define ENETRESET 102 /* Network dropped connection because of reset */ #define ECONNABORTED 103 /* Software caused connection abort */ #define ECONNRESET 104 /* Connection reset by peer */ #define ENOBUFS 105 /* No buffer space available */ #define EISCONN 106 /* Transport endpoint is already connected */ #define ENOTCONN 107 /* Transport endpoint is not connected */ #define ESHUTDOWN 108 /* Cannot send after transport endpoint shutdown */ #define ETOOMANYREFS 109 /* Too many references: cannot splice */ #define ETIMEDOUT 110 /* Connection timed out */ #define ECONNREFUSED 111 /* Connection refused */ #define EHOSTDOWN 112 /* Host is down */ #define EHOSTUNREACH 113 /* No route to host */ #define EALREADY 114 /* Operation already in progress */ #define EINPROGRESS 115 /* Operation now in progress */ #define ESTALE 116 /* Stale NFS file handle */ #define EUCLEAN 117 /* Structure needs cleaning */ #define ENOTNAM 118 /* Not a XENIX named type file */ #define ENAVAIL 119 /* No XENIX semaphores available */ #define EISNAM 120 /* Is a named type file */ #define EREMOTEIO 121 /* Remote I/O error */ #define EDQUOT 122 /* Quota exceeded */ #define ENOMEDIUM 123 /* Nomedium found */ #define EMEDIUMTYEP 124 /*Wrongmedium found */ #define ECANCELED 125 /* Operation Canceled */ #define ENOKEY 126 /* Required key not available */ #define EKEYEXPIRED 127 /* Key has expired */ #define EKEYREVOKED 128 /* Key has been revoked */ #define EKEYREJECTED 129 /* Key was rejected by service */ #define EOWNERDEAD 130 /* Owner died */ #define ENOTRECOVERABLE 131 /* State not recoverable */ #define ERFKILL 132 /* Operation not possible due to RF-kill */ #define EHWPOISON 133 /* Memory page has hardware error */我们可以在 下写个程式去把这些错误码给打印出来:
#include <stdio.h> #include <string.h> int main(void) { int i = 0; for (i = 0; i < 100; i++) { printf("%d: %s\n", i, strerror(i)); } }🚩 运行结果如下:

 其中,
其中,0 表示 success,1 表示权限不允许,2 找不到文件或目录。
我们刚才 ls 一个不存在的,再 echo $? 显示对应的错误码就是 2:

🔺 总结:错误码退出码可以对应不同的错误原因,方便我们定位问题出在哪里。
0x03 进程终止的常见方法
 正常终止(可以通过
正常终止(可以通过 echo $? 查看进程退出码)
① 从 main 函数返回 ② 调用 exit ③ _exit
我们先思考两个问题:
1. 在 main 函数中的 return(为什么其他函数不行)?
2. 在自己的代码任意地点中,调用exit() 都可以做到进程退出。
该函数想必大家并不陌生,exit 并不是一个系统调用,而是用 C 写的。
💬 代码演示:我们来用一下这个 exit 函数:
#include <stdio.h> #include <stdlib.h> void func() { printf("hello func\n"); exit(111); } int main(void) { func(); return 10; }🚩 运行结果如下:

 从
从main 函数调了 func 函数,进去打印后执行了 exit,最后进程没有返回直接在函数内部直接终止进程,这就叫调 exit 直接终止进程。此时我们 echo $? 得到的结果是 111 。
exit 当然也是可以在 main 函数中使用的,这里就不演示了。
如果你以后想终止一个进程,只需要在任意地点调用 exit 去 "代表" 进程退出。
![]() 注意,只有在 main 函数调
注意,只有在 main 函数调 return 才叫做 进程退出,其他函数调 return 叫做 函数返回。
下面我们再来讲解一下 _exit 函数,_exit 也是一个系统调用,也是可以用来终止进程的。
exit 和 _exit 是调用和被调用的关系,exit 是调用了 _exit 的。
💬 代码演示:_exit 函数
#include <stdio.h> #include <stdlib.h> int main(void) { _exit(222); return 10; }🚩 运行结果如下:
🔍 区别:exit 会清理缓冲区,关闭流等操作,而 _exit 什么都不干,直接终止。
0x04 内核数据结构缓冲池
 我们知道: 进程 = 内核结构
我们知道: 进程 = 内核结构 + 进程代码和数据 。
内核结构最典型的就是 task_struct 和 mm_struct,定义对象后以此充当进程的内核结构。
对于操作系统,可能并不会释放该进程的内核数据结构!
注意,这里说的是 "可能",释不释放取决于内存里的空间是否充盈。
我们来谈论一下不会释放的情况会发生什么,既然不会释放,那岂不是会一直占用?
实际上,创建进程我们从零开始构建对象,创建对象分为两个步骤,即开辟空间与初始化。
无论是开辟空间还是初始化都是要花费时间的,存在 cost 的……那该怎么办?
"没关系,Linux 会出手"
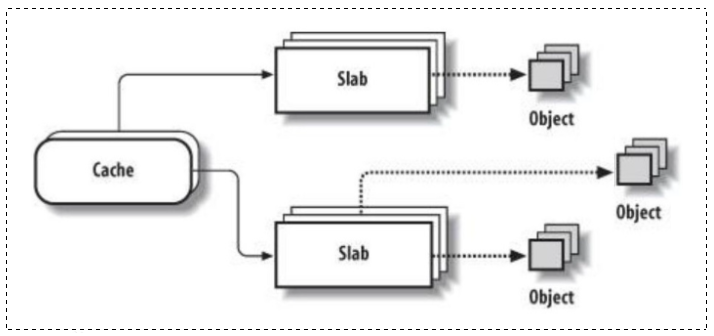
会维护一张废弃的数据结构链表,我们称之为 ,它是我们链表的数据结构结点。
当进程1释放后,进程的相关数据结构会维护进链表中,该数据结构是已经被操作系统释放掉了,但是并没有把它把它空间释放掉,而是设置其为 "无效"。当你再次创建进程时,它会从该队列中把相应的 task_struct 和 mm_struct 取出来,这就节省了开辟空间所花费的时间,要做的也只是把新进程的代码和空间进行初始化,可谓非常的轻松。
 这种做法我们称之为 内核的数据结构缓冲池,该策略在操作系统中称为
这种做法我们称之为 内核的数据结构缓冲池,该策略在操作系统中称为 slab 分派器 。
由于内核数据结构高频地使用,创建一个进程释放一个进程是特别高频率的事情。
每次开辟空间再初始化难免有些累,既然频率高,那么索性不再对结构进行重新申请。
直接把数据结构缓存起来,要就拿,不要就再放回去(便利店借雨伞),这就是 slab 分配器。
slab 是 Linux 操作系统的一种内存分配机制,slab 分配算法采用 cache 存储内核对象。slab 缓存、从缓存中分配和释放对象然后销毁缓存的过程必须要定义一个 kmem_cache 对象,然后对其进行初始化,这个特定的缓存包含 32 字节的对象。
🔗 链接:百度百科
(该分配器在内核中是一个非常名正言顺并且非常非常大一坨,这里我们就不看源码了,就现阶段而言其逻辑也非常复杂,这里只需要知道它的原理即可)


📌 [ 笔者 ] 王亦优 📃 [ 更新 ] 2023.3.1 ❌ [ 勘误 ] /* 暂无 */ 📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免, 本人也很想知道这些错误,恳望读者批评指正!📜 参考资料 C++reference[EB/OL]. []. http://www.cplusplus.com/reference/. Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/. 比特科技. Linux[EB/OL]. 2021[2021.8.31 x |
